深度学习 第三章 tensorflow手写数字识别
深度学习入门视频-唐宇迪 (笔记加自我整理)
深度学习 第三章 tensorflow手写数字识别
1.tensorflow常见操作
这里使用的是tensorflow1.x版本,tensorflow基本构成单位是张量tensor,区别在于不同阶。零阶张量,也叫标量,就是一个数值;一阶张量,可以理解为一维向量,比如列向量或者行向量;二阶张量,可以理解为二维矩阵;还可以有多阶张量,最简单的区分方法是看中括号"[",有多少个中括号,是几阶的张量。
tensorflow也有固定的语法套路,有三步,第一步定义变量或者常量,第二步初始化参数,第三步把定义的变量放到session中真正执行起来。session可以理解为一个容器,使用sess.run() 真正执行代码,得到结果。
- session定义
输入的数据有两种,一种是变量,定义方式是tf.Variable(), 一种是常量,tf.constant(). 定义输入之后,tf.global_variable_initializer()表示初始化所有定义的变量和常量,一定要有这一步。然后采用with tf.Session()的结构,定义一个session,把所有数据放入sess.run()中,执行输出。
变量和常量赋值有两种方式,一种是定义的时候直接复制,一种是定义的时候先占位置,使用的时候再赋值。下面这种方式是声明的变量的时候直接给值,类似于到图书馆直接找位置坐下来看书。

还有一种方式类似延迟加载,就是定义变量或者常量的时候,先不执行具体数值,而是先指定输入的类型,在真正执行代码的时候,把变量对应真正的值传入再进行计算。关键组合是placeholder(占位)+ feed_dict={}。类似于去图书馆的占座,需要先想清楚占几个位置,但是具体是谁坐哪个位置,要等到人来之后才能定。
placeholder用来占位置,feed_dict={}格式需要是字典的形式,把变量和对应值传入到容器中,执行得到具体结果。

- 常用操作
tensorflow有大量对矩阵的运算,通常会涉及到矩阵的初始化,一般有三种方式,第一种所有数据全赋值为0,第二种所有数据全赋值为1,第三种所有数据根据正态分布随机生成数值。初始化的时候需要执行要生成矩阵的维度,矩阵中数据的类型不是必须的,如果不传入则使用默认值。一般矩阵数值类型范围主要是,整型,浮点型,布尔型,字符串类型。
-
- zeros :
- x1= tf.zeros([3,4], dtype=tf.int32) ,
- 生成3行4列的二阶张量,类型为int32,值全部为0
- ones:
- x2 = tf.ones([3,4], dtype=tf.int32),
- 生成3行4列的二阶张量,类型为int32,值全部为1
- random_normal:
- x3 = tf.random_normal([2,3], mean=0,stddev=4),
- 生成2行3列的二阶张量,这里默认类型为float32,这里生成的生态分布式均值为0,标准差为4的随机数据。
- shuffle:
- x4 = tf.random_shuffle(c) , 对数据进行打乱操作,
- 一般在切分训练集和测试集的时候,先打乱再切分,比较常用。
- conver_to_tensor:
- a = numpy.zeros((3,3))
- ta = tf.conver_to_tensor(a),将numpy数组转换成tensor张量
- 一定要注意,tenforflow中可以用于计算结构是张量,其他都不可以用于计算,但是numpy数组和tensor张量有很多操作相似,可以进行类型转换

- zeros :
2.tenforflow实现线性回归
使用tensorflow实现线性回归,为简单起见,随机构造这一组数据使其符合线性关系y=w*x+b,这里x只有一维,即一个特征。构造输入数据后,要构造训练代码。首先初始化参数,这里权重W矩阵,采用random_uniform生成一维矩阵,数值介于[-1,1]之间的随机数;偏置项B矩阵,初始化为全0的一维矩阵。定义得分函数y,定义损失函数loss,这里采用均方误差作为优化目标,采用随机梯度下降法来优化损失函数,让loss朝最小值方向更新,最后每20次训练打印一次损失值loss,直到执行完迭代次数,损失值收敛。
- 训练代码

3.手写字体识别
数据采用的是开源mnist数据集,输入数据是手写数字的图片,需要判断每个图片上的数字是哪个,输出结果有10个类别,分别对应0-9的10个手写数字,所以输出结果为10个类别。采用dataset的形式读入文件内容,mnist= input.read_data_sets("xx", onehot=True)。
一般神经网络多分类任务通常采用softmax分类器,对应的10个类别需要编码转换成计算机识别的方式,这里采用one-hot编码方式。one-hot也叫独热编码,是对于离散类别数据常用的编码方式,这里一共有10个类别,用10个数字表示,每个位置上的数字代表一个类别,比如数字图片类别是0,那么代表0类别的对应位置上的数值为1,其他类别对应位置都为0,所以叫独热编码,可以理解为只有一个类别是热的,其他的都是凉的。比如这里数字0可以表示为[ 1, 0, 0, 0, 0, 0, 0, 0, 0, 0] , 数字7可以表示为 [ 0, 0, 0, 0, 0, 0, 0, 1, 0, 0],其中一张图片大概是这样子。
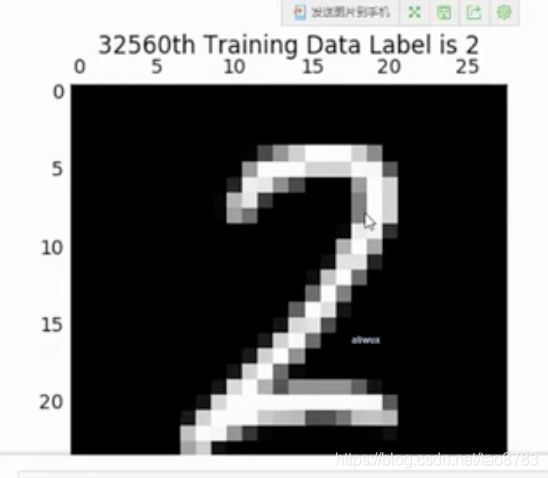
接下来需要定义神经网络的层次,以及各参数的维度大小。通常情况下,神经网络模型很少自己定义层次,比如需要几层网络,每一层有多少个神经元,一般都是采用现成的模型,一般是于论文证明并且工业界使用效果不错的模型。这里是为了实现手写识别的例子,注意实际中很少采用自定义模型即可。
这里涉及采用4层模型,输入层是32*32的图片,可以采用批处理方式一次输入多张图片,但是要指定每次使用几张图片,图片大小和批处理的个数是固定不能改变的。中间隐含层设定为2层,隐含层1的神经元采用256个,隐含层2的神经元采用128个,最后的输出层采用softmax分类器,这里的类别是10种,所以输出类别为10。 下面就开始计算矩阵参数的大小了。输入层到隐含层1中间的权重参数W1 = 784* 256, 隐含层1到隐含层2的权重参数W2= 256*128, 隐含层2到输出层的权重参数W3 = 128* 10, 还要注意每个权重矩阵都要对应一个偏置项。
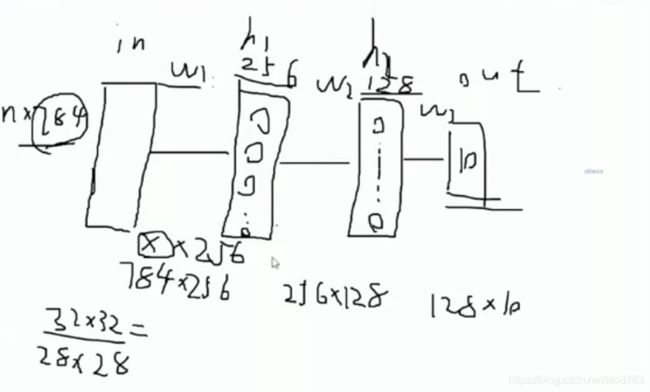
大体代码如下:
- 定义各参数,执行维度
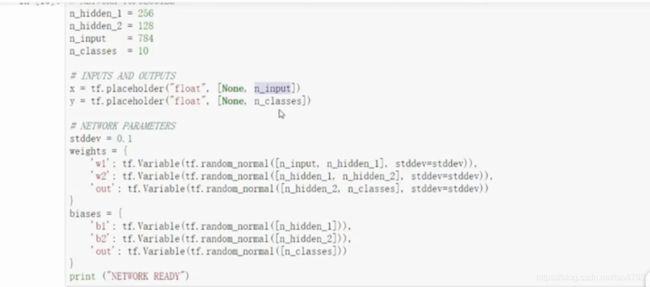
- 定义两个隐含层,这里采用sigmoid作为激活函数,用于去线性化。

- 定义程序主代码,即得分函数,损失函数,优化方式,评估方式。并初始代码

- 执行程序,并设定中间打印训练集结果和测试集结果
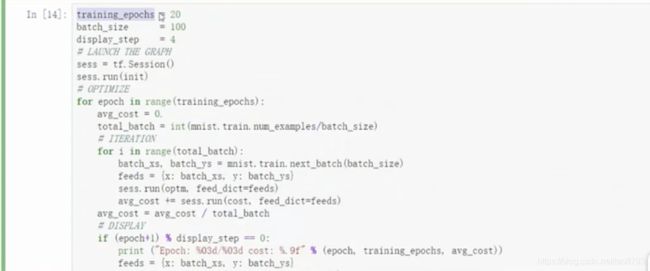
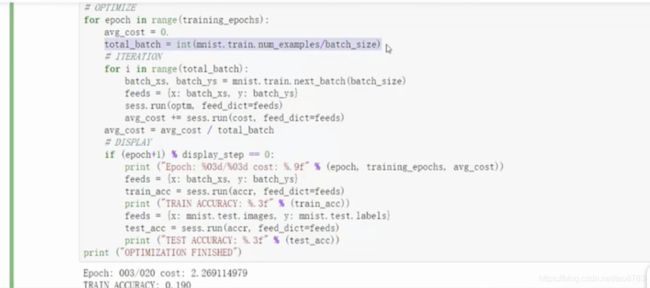
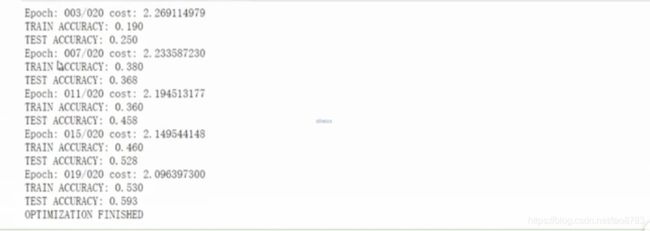
- 打印结果如下: