【开发实录】基于YOLOv5+DeepSort的行人监控电子围栏系统
【开发实录】基于YOLOv5+DeepSort的行人监控电子围栏系统
- 1. 项目目标:
- 2. 项目演示:
- 3. YOLOv5目标检测+DeepSort目标追踪:
- 4. UI界面开发:
-
- 4.1 登录界面:
- 4.2 加载界面:
- 4.3 主界面:
- 4.4 美化界面:
- 5. UI功能开发:
-
- 5.1 绑定槽函数:
- 5.2 在UI中显示视频:
- 5.3 相应鼠标绘制区域:
- 5.4 其他细节:
- 6. 部署方案:
-
- 6.1 端侧视频推流:
- 6.2 Flask部署:
- 7. 联系作者:
- 关注我的公众号:
1. 项目目标:
本项目目标为开发基于YOLOv5+DeepSort的行人监控电子围栏系统,功能包括:
- 行人检测和追踪;
- 危险区域鉴定;
- 爬墙检测;
- 长时间逗留检测;
- 行人聚集检测;
项目使用PyQt5进行软件界面开发。
2. 项目演示:
Bilibili:
基于YOLOv5+DeepSort的行人监控电子围栏系统 V2.0
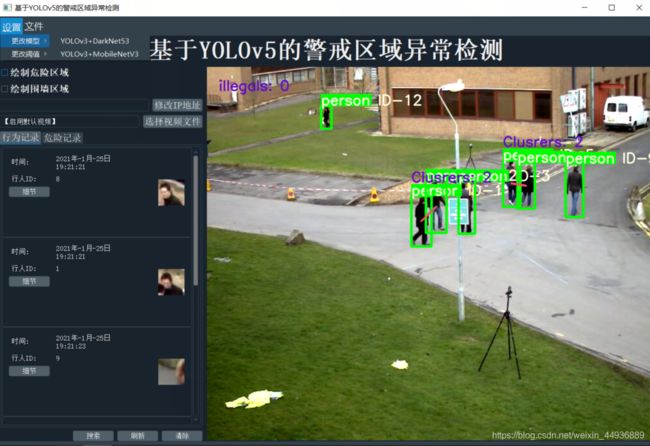
软件截图:
3. YOLOv5目标检测+DeepSort目标追踪:
代码地址:
https://github.com/Sharpiless/Yolov5-deepsort-inference
如何使用YOLOv5训练自己的数据集请看这篇:
【小白CV】手把手教你用YOLOv5训练自己的数据集(从Windows环境配置到模型部署)
训练好后,放到weights文件夹下:
编写检测类:
- 基础检测器
from .tracker_deep import update_tracker
import cv2
class baseDet(object):
def __init__(self, tracker_type):
self.img_size = 640
self.threshold = 0.4
self.max_frame = 160
self.stride = 2
self.illegal_num = 0
self.tracker_type = tracker_type
def build_config(self):
self.faceTracker = {
}
self.illegals = []
self.faceClasses = {
}
self.faceregister = {
}
self.faceLocation1 = {
}
self.faceLocation2 = {
}
self.frameCounter = 0
self.currentCarID = 0
self.recorded = []
self.font = cv2.FONT_HERSHEY_SIMPLEX
def feedCap(self, im, isChecked, region_bbox2draw=None):
retDict = {
'frame': None,
'faces': None,
'list_of_ids': None,
'face_bboxes': []
}
self.frameCounter += 1
im, faces, face_bboxes = update_tracker(
self, im, region_bbox2draw, isChecked)
retDict['frame'] = im
retDict['faces'] = faces
retDict['face_bboxes'] = face_bboxes
return retDict
def init_model(self):
raise EOFError("Undefined model type.")
def preprocess(self):
raise EOFError("Undefined model type.")
def detect(self):
raise EOFError("Undefined model type.")
- YOLOv5检测器:
import torch
import numpy as np
from models.experimental import attempt_load
from utils.general import non_max_suppression, scale_coords, letterbox
from utils.torch_utils import select_device
from .BaseDetector import baseDet
class Detector(baseDet):
def __init__(self, tracker_type):
super(Detector, self).__init__(tracker_type)
self.init_model()
self.build_config()
def init_model(self):
self.weights = 'weights/final.pt'
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.half()
# torch.save(model, 'test.pt')
self.m = model
self.names = model.module.names if hasattr(
model, 'module') else model.names
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half() # 半精度
img /= 255.0 # 图像归一化
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.3)
pred_boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(
img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
if not lbl == 'person':
continue
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
pred_boxes.append(
(x1, y1, x2, y2, lbl, conf))
return im, pred_boxes
检测效果:
4. UI界面开发:
4.1 登录界面:
这里写一个简单的登录界面:
import sys
from PyQt5.QtCore import Qt
from PyQt5.QtGui import QPixmap, QFont, QIcon
from PyQt5.QtWidgets import QWidget, QApplication, QLabel, QDesktopWidget, QHBoxLayout, QFormLayout, \
QPushButton, QLineEdit, QMainWindow
class LoginForm(QMainWindow):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
"""
初始化UI
:return:
"""
self.setObjectName("loginWindow")
self.setStyleSheet('#loginWindow{background-color:white}')
self.setFixedSize(650, 300)
self.setWindowTitle("登录")
self.setWindowIcon(QIcon('data/logo.png'))
# 登录表单内容部分
login_widget = QWidget(self)
login_widget.move(0, 0)
login_widget.setGeometry(0, 0, 650, 260)
hbox = QHBoxLayout()
# 添加左侧logo
logolb = QLabel(self)
logopix = QPixmap("web/logo.png")
logolb.setPixmap(logopix)
logolb.setAlignment(Qt.AlignCenter)
hbox.addWidget(logolb, 1)
# 添加右侧表单
fmlayout = QFormLayout()
lbl_workerid = QLabel("用户名")
lbl_workerid.setFont(QFont("Microsoft YaHei"))
led_workerid = QLineEdit()
led_workerid.setFixedWidth(270)
led_workerid.setFixedHeight(38)
lbl_pwd = QLabel("密码")
lbl_pwd.setFont(QFont("Microsoft YaHei"))
led_pwd = QLineEdit()
led_pwd.setEchoMode(QLineEdit.Password)
led_pwd.setFixedWidth(270)
led_pwd.setFixedHeight(38)
self.btn_login = QPushButton("登录")
self.btn_login.setFixedWidth(270)
self.btn_login.setFixedHeight(40)
self.btn_login.setFont(QFont("Microsoft YaHei"))
self.btn_login.setObjectName("login_btn")
self.btn_login.setStyleSheet(
"#login_btn{background-color:#2c7adf;color:#fff;border:none;border-radius:4px;}")
self.btn_login.clicked.connect(
lambda : self.close_logui(led_workerid.text(), led_pwd.text())
)
fmlayout.addRow(lbl_workerid, led_workerid)
fmlayout.addRow(lbl_pwd, led_pwd)
fmlayout.addWidget(self.btn_login)
hbox.setAlignment(Qt.AlignCenter)
# 调整间距
fmlayout.setHorizontalSpacing(20)
fmlayout.setVerticalSpacing(12)
hbox.addLayout(fmlayout, 2)
login_widget.setLayout(hbox)
self.center()
self.show()
def close_logui(self, user, password):
print('-[INFO] User:{} Password:{}'.format(user, password))
self.close()
def center(self):
qr = self.frameGeometry()
cp = QDesktopWidget().availableGeometry().center()
qr.moveCenter(cp)
self.move(qr.topLeft())
if __name__ == "__main__":
app = QApplication(sys.argv)
ex = LoginForm()
sys.exit(app.exec_())
效果:

4.2 加载界面:
由于 yolov5 模型加载较慢,所以我们需要写一个加载进度界面,核心代码:
def load_data(self, sp):
for i in range(1, 11): # 模拟主程序加载过程
time.sleep(0.5) # 加载数据
sp.showMessage("加载... {0}%".format(
i * 10), QtCore.Qt.AlignHCenter | QtCore.Qt.AlignBottom, QtCore.Qt.black)
QtWidgets.qApp.processEvents() # 允许主进程处理事件
def main(opt):
'''
启动PyQt5程序,打开GUI界面
'''
app = QApplication(sys.argv)
splash = QtWidgets.QSplashScreen(QtGui.QPixmap("data/logo.png"))
splash.showMessage("加载... 0%", QtCore.Qt.AlignHCenter, QtCore.Qt.black)
splash.show() # 显示启动界面
QtWidgets.qApp.processEvents() # 处理主进程事件
main_window = MainWindow(opt)
main_window.load_data(splash) # 加载数据
# main_window.showFullScreen() # 全拼显示
app.setStyleSheet(qdarkstyle.load_stylesheet_pyqt5())
splash.close()
main_window.show()
sys.exit(app.exec_())
效果:

4.3 主界面:
主界面首先使用Qt Designer进行布局设计:

完成后导出为 .ui 文件:
然后完成另外一些部件,如左侧行人信息栏、详细信息模块等:

然后使用 PyQt5 加载这些文件到代码中,例如:
from PyQt5 import QtWidgets
from PyQt5.QtWidgets import QMainWindow
from PyQt5.uic import loadUi
class DetailLogWindow(QMainWindow):
def __init__(self, data, parent=None):
super(DetailLogWindow, self).__init__(parent)
loadUi("./data/UI/DetailLog.ui", self)
self.data = data
self.face_image.setScaledContents(True)
# self.license_image.setScaledContents(True)
self.ticket_button.clicked.connect(self.ticket)
self.initData()
def ticket(self):
self.destroy()
def initData(self):
self.cam_id.setText(str(self.data['CARID']))
self.behavior.setText(self.data['CARCOLOR'])
if self.data['CARIMAGE'] is not None:
self.face_image.setPixmap(self.data['CARIMAGE'])
if self.data['LICENSEIMAGE'] is not None:
self.license_image.setPixmap(self.data['LICENSEIMAGE'])
self.preson_id.setText(self.data['LICENSENUMBER'])
self.face_name.setText(self.data['LOCATION'])
self.rule.setText(self.data['RULENAME'])
self.close_button.clicked.connect(self.close)
self.delete_button.clicked.connect(self.deleteRecord)
def close(self):
self.destroy()
def deleteRecord(self):
qm = QtWidgets.QMessageBox
prompt = qm.question(self, '', "确定要删除吗?", qm.Yes | qm.No)
if prompt == qm.Yes:
self.destroy()
else:
pass
即使用:
loadUi(".ui", self)
4.4 美化界面:
现在界面是这样的:
我们可以用一些CSS语句来装饰部件,当然也可以用别人设计好的。
这里使用qdarkstyle来美化界面:
app.setStyleSheet(qdarkstyle.load_stylesheet_pyqt5())
美化后的效果:
5. UI功能开发:
5.1 绑定槽函数:
信号和槽是PyQt编程对象之间进行通信的机制。每个继承自QWideget的控件都支持信号与槽机制。信号发射时(发送请求),连接的槽函数就会自动执行(针对请求进行处理)。
以下为绑定文件选择按钮的槽函数的示例:
- 点击事件绑定:
self.file_btn.clicked.connect(
lambda: self.getFile(self.file_edit)) # 文件选择槽函数绑定
- 文件选择函数:
def getFile(self, lineEdit):
file_path = QFileDialog.getOpenFileName()[0]
lineEdit.setText(file_path) # 获取文件路径
self.updateCamInfo(file_path)
这样的话点击 file_btn 按钮就会发出信号,从而运行绑定的函数:

5.2 在UI中显示视频:
这里主要是将图像逐帧放置到 QLabel 部件上。
首先我们需要将opencv的图像转为QImage:
def toQImage(self, img, height=800):
if not height is None:
img = imutils.resize(img, height=height)
qformat = QImage.Format_Indexed8
if len(img.shape) == 3:
if img.shape[2] == 4:
qformat = QImage.Format_RGBA8888
else:
qformat = QImage.Format_RGB888
outImg = QImage(
img.tobytes(), img.shape[1], img.shape[0], img.strides[0], qformat)
outImg = outImg.rgbSwapped()
return outImg
定义刷新时执行的函数:
def update_image(self, pt='face.jpg'):
_, frame = self.vs.read()
if frame is None:
return
frame = imutils.resize(frame, height=800)
isChecked = {
'region': self.region_checkbtn.isChecked(),
'wall': self.wall_checkbtn.isChecked()
}
packet = self.processor.getProcessedImage(frame, isChecked, region_bbox2draw=self.region_bbox2draw)
qimg0 = self.toQImage(packet['frame'], height=None)
self.live_preview.setPixmap(QPixmap.fromImage(qimg0))
然后绑定计时器,规定每 50ms 刷新一次:
self.timer = QTimer(self)
self.timer.timeout.connect(self.update_image)
self.timer.start(50)
5.3 相应鼠标绘制区域:
这里使用PyQt5预置的响应函数:
def mouseReleaseEvent(self, event): # 鼠标键释放时调用
# 参数1:鼠标的作用对象;参数2:鼠标事件对象,用来保存鼠标数据
self.unsetCursor()
n = event.button() # 用来判断是哪个鼠标健触发了事件【返回值:0 1 2 4】
if n == 1:
if self.region_checkbtn.isChecked() or self.wall_checkbtn.isChecked():
x = event.x() # 返回鼠标相对于窗口的x轴坐标
y = event.y() # 返回鼠标相对于窗口的y轴坐标
这样就可以获取到鼠标点击完释放时的位置,从而用来绘制危险区:
5.4 其他细节:
- 添加menu:
def add_setting_menu(self, settingsMenu):
speed_menu = QMenu("更改模型", self)
settingsMenu.addMenu(speed_menu)
act = QAction('YOLOv3+DarkNet53', self)
act.setStatusTip('YOLOv3+DarkNet53')
speed_menu.addAction(act)
act = QAction('YOLOv3+MobileNetV3', self)
act.setStatusTip('YOLOv3+MobileNetV3')
speed_menu.addAction(act)
direct_menu = QMenu("更改阈值", self)
settingsMenu.addMenu(direct_menu)
act = QAction('阈值+0.05', self)
act.setStatusTip('阈值+0.05')
direct_menu.addAction(act)
act = QAction('阈值-0.05', self)
act.setStatusTip('阈值-0.05')
direct_menu.addAction(act)
绑定细节框:
self.details_button.clicked.connect(self.showDetails)
def showDetails(self):
window = DetailLogWindow(self.data, self)
window.show()
from PyQt5 import QtWidgets
from PyQt5.QtWidgets import QMainWindow
from PyQt5.uic import loadUi
class DetailLogWindow(QMainWindow):
def __init__(self, data, parent=None):
super(DetailLogWindow, self).__init__(parent)
loadUi("./data/UI/DetailLog.ui", self)
self.data = data
self.face_image.setScaledContents(True)
# self.license_image.setScaledContents(True)
self.ticket_button.clicked.connect(self.ticket)
self.initData()
def ticket(self):
self.destroy()
def initData(self):
self.cam_id.setText(str(self.data['CARID']))
self.behavior.setText(self.data['CARCOLOR'])
if self.data['CARIMAGE'] is not None:
self.face_image.setPixmap(self.data['CARIMAGE'])
if self.data['LICENSEIMAGE'] is not None:
self.license_image.setPixmap(self.data['LICENSEIMAGE'])
self.preson_id.setText(self.data['LICENSENUMBER'])
self.face_name.setText(self.data['LOCATION'])
self.rule.setText(self.data['RULENAME'])
self.close_button.clicked.connect(self.close)
self.delete_button.clicked.connect(self.deleteRecord)
def close(self):
self.destroy()
def deleteRecord(self):
qm = QtWidgets.QMessageBox
prompt = qm.question(self, '', "确定要删除吗?", qm.Yes | qm.No)
if prompt == qm.Yes:
self.destroy()
else:
pass
6. 部署方案:
6.1 端侧视频推流:
可以放在端侧设备上:
import cv2
import subprocess as sp
import subprocess as sp
rtmpUrl = "接收视频的服务器"
camera_path = 0
cap = cv2.VideoCapture(0)
# Get video information
fps = int(cap.get(cv2.CAP_PROP_FPS))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# ffmpeg command
command = ['ffmpeg',
'-y',
'-f', 'rawvideo',
'-vcodec', 'rawvideo',
'-pix_fmt', 'bgr24',
'-s', "{}x{}".format(width, height),
'-r', str(fps),
'-i', '-',
'-c:v', 'libx264',
'-pix_fmt', 'yuv420p',
'-preset', 'ultrafast',
'-f', 'flv',
rtmpUrl]
# 管道配置
p = sp.Popen(command, stdin=sp.PIPE)
# read webcamera
while (cap.isOpened()):
ret, frame = cap.read()
# print("running......")
if not ret:
print("Opening camera is failed")
break
p.stdin.write(frame.tostring())
return_value, frame = cap.read()
6.2 Flask部署:
注意下面并非本项目代码,而是一个图像分类模型Flask部署的代码:
import datetime
import logging as rel_log
import os
import shutil
from datetime import timedelta
from paddlex import deploy
from flask import *
import core.main
UPLOAD_FOLDER = r'./uploads'
ALLOWED_EXTENSIONS = set(['png'])
app = Flask(__name__)
app.secret_key = 'secret!'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
werkzeug_logger = rel_log.getLogger('werkzeug')
werkzeug_logger.setLevel(rel_log.ERROR)
# 解决缓存刷新问题
app.config['SEND_FILE_MAX_AGE_DEFAULT'] = timedelta(seconds=1)
# 添加header解决跨域
@app.after_request
def after_request(response):
response.headers['Access-Control-Allow-Origin'] = '*'
response.headers['Access-Control-Allow-Credentials'] = 'true'
response.headers['Access-Control-Allow-Methods'] = 'POST'
response.headers['Access-Control-Allow-Headers'] = 'Content-Type, X-Requested-With'
return response
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
@app.route('/')
def hello_world():
return redirect(url_for('static', filename='./index.html'))
@app.route('/upload', methods=['GET', 'POST'])
def upload_file():
file = request.files['file']
print(datetime.datetime.now(), file.filename)
if file and allowed_file(file.filename):
src_path = os.path.join(app.config['UPLOAD_FOLDER'], file.filename)
file.save(src_path)
shutil.copy(src_path, './tmp/ct')
image_path = os.path.join('./tmp/ct', file.filename)
print(src_path, image_path)
pid, image_info = core.main.c_main(image_path, current_app.model)
return jsonify({
'status': 1,
'image_url': 'http://127.0.0.1:5003/tmp/ct/' + pid,
'draw_url': 'http://127.0.0.1:5003/tmp/draw/' + pid,
'image_info': image_info
})
return jsonify({
'status': 0})
@app.route("/download", methods=['GET'])
def download_file():
# 需要知道2个参数, 第1个参数是本地目录的path, 第2个参数是文件名(带扩展名)
return send_from_directory('data', 'testfile.zip', as_attachment=True)
# show photo
@app.route('/tmp/' , methods=['GET'])
def show_photo(file):
if request.method == 'GET':
if not file is None:
image_data = open(f'tmp/{file}', "rb").read()
response = make_response(image_data)
response.headers['Content-Type'] = 'image/png'
return response
if __name__ == '__main__':
with app.app_context():
current_app.model = deploy.Predictor(
'./core/net/inference_model', use_gpu=True)
app.run(host='127.0.0.1', port=5003, debug=True)
7. 联系作者:

关注我的公众号:
感兴趣的同学关注我的公众号——可达鸭的深度学习教程:
