论文阅读之DIEN模型
目录
- 总体介绍
- 模型介绍
-
- 兴趣提取层
- 兴趣演化层
-
- GRU with attentional input (AIGRU)
- Attention based GRU(AGRU)
- GRU with attentional update gate (AUGRU)
- 实验
总体介绍
提升点击率(CTR),毋庸置疑,现已经成为广告系统中的核心任务之一,而提高点击率就离不开商品个性化推荐。但目前的大多数模型都直接将行为表示为兴趣,缺乏针对具体行为背后潜在兴趣进行建模,比如已经有的DIN模型,它强调用户兴趣是多样的,并使用基于注意力模型来捕获目标项目的相对兴趣。但是用户的兴趣是不断进化的,而DIN抽取的用户兴趣之间是独立无关联的,没有捕获到兴趣的动态进化性;而且通过用户的显式的行为来表达用户隐含的兴趣,这一准确性也无法得到保证。
根据原文,这个模型主要有以下几点贡献
- 关注电子商务系统中的用户兴趣演变现象,并提出一种新的网络结构来模拟兴趣演化过程。
- 设计了兴趣抽取层,并通过计算一个辅助loss,来提升兴趣表达的准确性。
- 设计了兴趣进化层,来更加准确的表达用户兴趣的动态变化性。
模型介绍
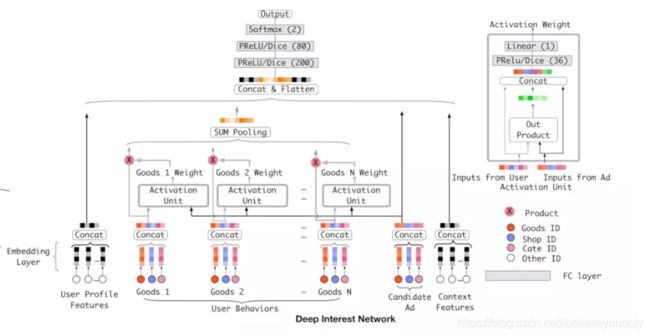
上面这个是DIN的结构图。
接下来是这个DIEN的结构图
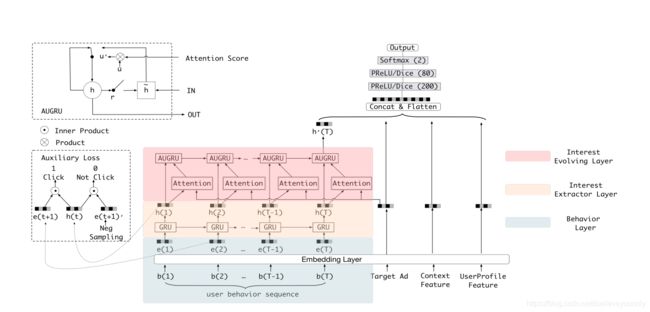
首先,可以看到,DIN和DIEN的最底层都是Embedding Layer,User profile, target AD和context feature的处理方式是一致的。但是,DIEN将user behavior组织成了序列数据的形式,并把简单的使用外积完成的activation unit变成了一个attention-based GRU网络。
而且,因为用户并未明确表达其意图,所以DIEN致力于捕捉用户兴趣并模拟兴趣发展过程。DIEN采取两个步骤:兴趣提取层基于行为序列提取兴趣序列;;兴趣演化模型层模拟兴趣变化过程。 然后连接其余的信息(Target id context feature等等)并最后送入MLP进行最终预测。
兴趣提取层
由于这个电子商务系统中用户的点击行为丰富,历史行为序列的长度即使在短时间内也很长。故RNN有一定缺陷,而克服RNN缺陷的有LSTM与GRU,但本文认为GRU训练更快,故采取了GRU。
首先了解一下这个 GRU,大概是这个图。


下面是文章中关于GRU的公式
这个ut应该就是更新门(帮助模型确定需要将多少过去信息(来自前一时间步骤)进行传递)
rt应该是重置门(决定忘记过去的信息量)
我理解的是,原本这个GRU的公式里没有这个偏移量b,应该和用户行为有关,是GRU更加准确。
u t = σ ( W u i ⃗ t + U u h t − 1 + b u ) r t = σ ( W r i ⃗ t + U r h t − 1 + b r ) h t ^ = tanh ( W h i ⃗ t + r t ∘ U h h t − 1 + b h ) h t = ( 1 − u t ) ∘ h t − 1 + u t ∘ h t ^ \begin{array}{c}{u_{t}=\sigma\left(W^{u} \vec{i}_{t}+U^{u} h_{t-1}+b^{u}\right)} \\ {r_{t}=\sigma\left(W^{r} \vec{i}_{t}+U^{r} h_{t-1}+b^{r}\right)} \\ {\hat{h_{t}}=\tanh \left(W^{h} \vec{i}_{t}+r^{t} \circ U^{h} h_{t-1}+b^{h}\right)} \\ {h_{t}=\left(1-u_{t}\right) \circ h_{t-1}+u_{t} \circ \hat{h_{t}}}\end{array} ut=σ(Wuit+Uuht−1+bu)rt=σ(Writ+Urht−1+br)ht^=tanh(Whit+rt∘Uhht−1+bh)ht=(1−ut)∘ht−1+ut∘ht^
但是,文中也注意到了,仅使用历史行为之间的依赖关系的隐藏状态并不能完全的代表用户兴趣。所以文中别出心裁的增加了一个辅助loss,来提升兴趣表达的准确性。
L a u x = − 1 N ( ∑ i = 1 N ∑ t log ( σ ( h t i , e b i [ t + 1 ] ) ) + log ( 1 − σ ( h t i , e b i [ t + ^ + 1 ] ) ) ) L_{a u x}=-\frac{1}{N}\left(\sum_{i=1}^{N} \sum_{t} \log \left(\sigma\left(h_{t}^{i}, e_{b}^{i}[t+1]\right)\right)+\log \left(1-\sigma\left(h_{t}^{i}, e_{b}^{i}[t \hat{+}+1]\right)\right)\right) Laux=−N1(i=1∑Nt∑log(σ(hti,ebi[t+1]))+log(1−σ(hti,ebi[t+^+1])))
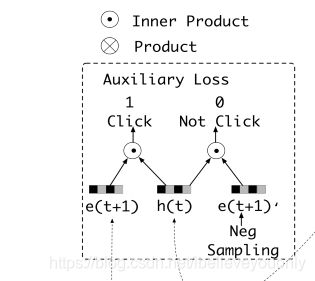
大概就是把用户下一时刻真实的行为e(t+1)作为正例,负采样得到的行为作为负例e(t+1)’,分别与抽取出的兴趣h(t)结合输入到设计的辅助网络中。
而原来采用的损失函数为
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ L_{\text {targ…
所 以 , 全 局 损 失 函 数 L = L target + α ∗ L a u x α 为 参 数 所以,全局损失函数L=L_{\text {target}}+\alpha * L_{a} u x \\ \alpha为参数 所以,全局损失函数L=Ltarget+α∗Lauxα为参数
兴趣演化层
由于外部环境和内部认知的共同影响,不同类型的用户兴趣随着时间的推移而不断发展。 以兴趣是衣服为例,随着人口趋势和用户品味的变化,用户对衣服的偏好也在不断变化。 用户对衣服的兴趣的演变过程将直接决定候选衣服的CTR预测。 所以对不断演化的过程进行建模显然是很有必要的。
并且,兴趣在发展过程中,有以下几个特征:
- 由于兴趣的多样性,兴趣可能会转移,例如用户可能在一段时间内对各种书籍感兴趣,并且在另一时间需要衣服。
- 虽然兴趣可能相互影响,但每种兴趣都有自己不断发展的过程
所以,为了利用这两个时序特征,我们需要再增加一层GRU的变种,并加上attention机制以找到与target AD相关的interest。文章使用的注意力模型为:
a t = exp ( h t W e a ) ∑ j = 1 T exp ( h j W e a ) a_{t}=\frac{\exp \left(\mathbf{h}_{t} W \mathbf{e}_{a}\right)}{\sum_{j=1}^{T} \exp \left(\mathbf{h}_{j} W \mathbf{e}_{a}\right)} at=∑j=1Texp(hjWea)exp(htWea)
其中这个ea为不同广告嵌入向量的连接。注意力分数(Attention score)可以反映广告ea与输入ht的关系,并且他们之间的相关性强度会影响这个Attention score。
接下来,文章介绍几种将注意力机制和GRU结合起来模拟兴趣进化过程的算法。
GRU with attentional input (AIGRU)
这种方式将attention直接作用于输入,无需修改GRU的结构:
i t ′ = h t ∗ a t \mathbf{i}_{t}^{\prime}=\mathbf{h}_{t} * a_{t} it′=ht∗at
在AIGRU中,注意力得分可以降低较少相关兴趣的规模。 理想情况下,较少相关兴趣的输入值可以减少到零。但是,AIGRU有一定局限性, 因为即使零输入也可以改变GRU的隐藏状态。
Attention based GRU(AGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:
h t ′ = ( 1 − a t ) ∗ h t − 1 ′ + a t ∗ h ~ t ′ \mathbf{h}_{t}^{\prime}=\left(1-a_{t}\right) * \mathbf{h}_{t-1}^{\prime}+a_{t} * \tilde{\mathbf{h}}_{t}^{\prime} ht′=(1−at)∗ht−1′+at∗h~t′
原来公式为:
h t = ( 1 − u t ) ∘ h t − 1 + u t ∘ h ~ t \mathbf{h}_{t}=\left(\mathbf{1}-\mathbf{u}_{t}\right) \circ \mathbf{h}_{t-1}+\mathbf{u}_{t} \circ \tilde{\mathbf{h}}_{t} ht=(1−ut)∘ht−1+ut∘h~t
AGRU使用Attention score来代替GRU的ut(更新们),AGRU利用Attention score直接控制隐藏状态的更新。 并且在兴趣变化期间削弱了相关兴趣减少的影响。但是它使用标量(注意力分数at )来替换矢量(更新门ut),这忽略了不同维度之间的重要性差异。
GRU with attentional update gate (AUGRU)
因为前面几种方式都有不同的缺陷,所以又提出了一种更好的:
u ~ t ′ = a t ∗ u t ′ h t ′ = ( 1 − u ~ t ′ ) ∘ h t − 1 ′ + u ~ t ′ ∘ h ~ t ′ \begin{aligned} \tilde{\mathbf{u}}_{t}^{\prime} &=a_{t} * \mathbf{u}_{t}^{\prime} \\ \mathbf{h}_{t}^{\prime} &=\left(1-\tilde{\mathbf{u}}_{t}^{\prime}\right) \circ \mathbf{h}_{t-1}^{\prime}+\tilde{\mathbf{u}}_{t}^{\prime} \circ \tilde{\mathbf{h}}_{t}^{\prime} \end{aligned} u~t′ht′=at∗ut′=(1−u~t′)∘ht−1′+u~t′∘h~t′
在AUGRU中,我们保留ut的原始信息, AUGRU可以更有效地避免兴趣转移的干扰,并推动相对兴趣的顺利演化。
实验
在AUGRU中,我们保留ut的原始信息, AUGRU可以更有效地避免兴趣转移的干扰,并推动相对兴趣的顺利演化。
文章最后进行了一系列实验,使用了公共数据集与工业数据集,并做了A/B实验,证明这个DIEN确实挺好。