- ESP32开发日记4-来讲讲ESP32之外的东西(Valgrind 工具的使用)
我在武汉上早八
开发工具笔记物联网linuxc语言c++
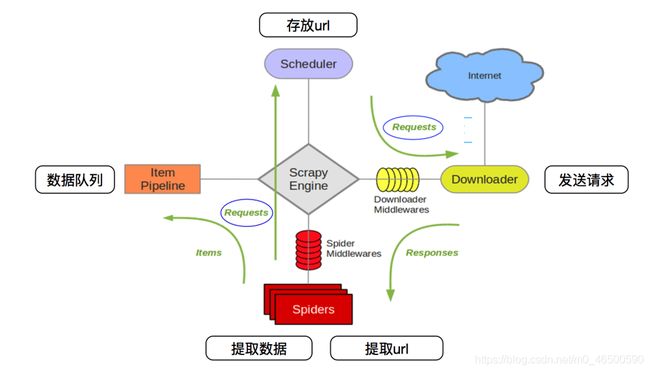
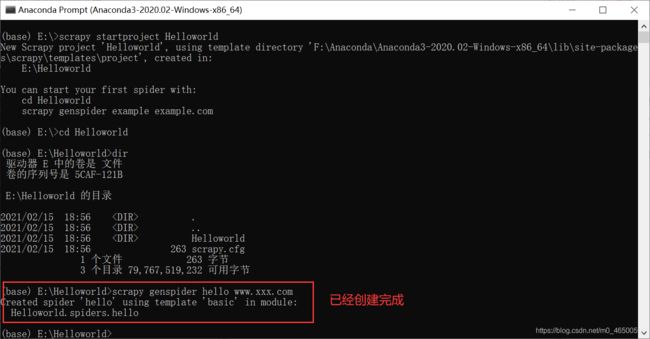
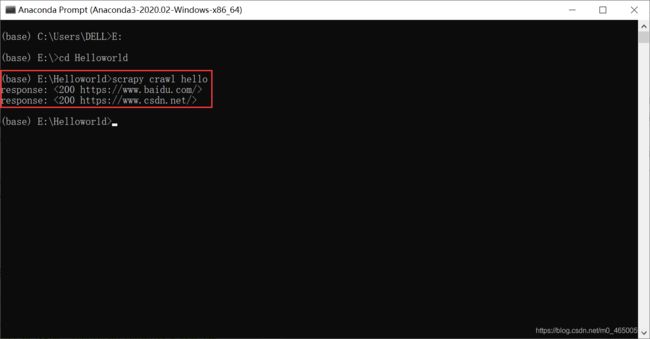
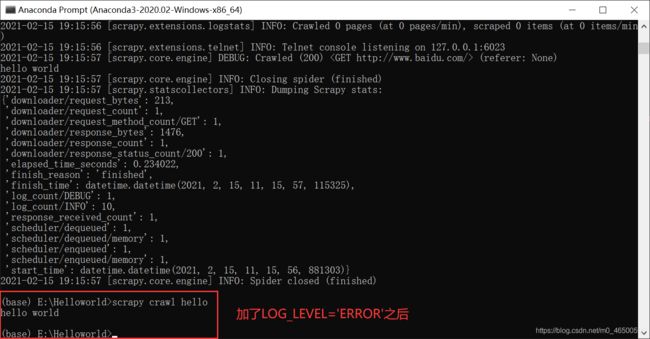
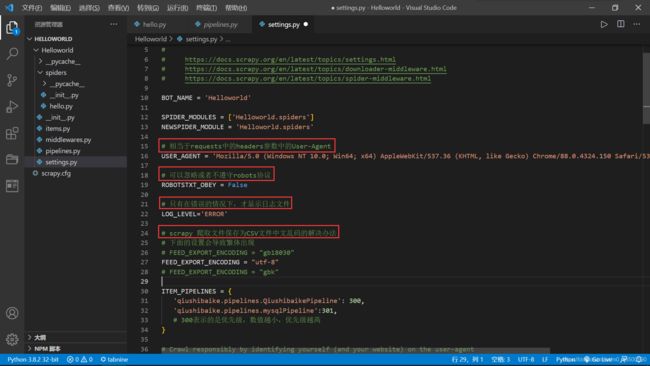
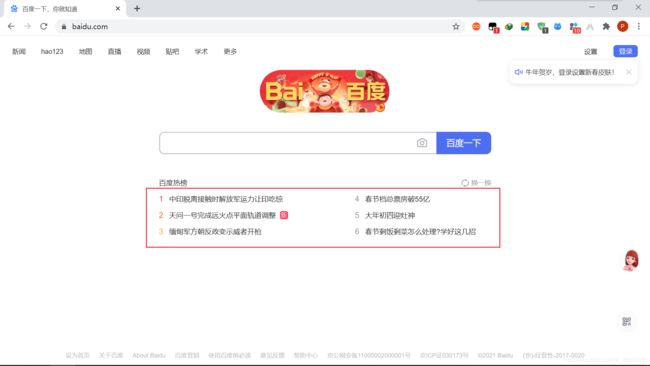
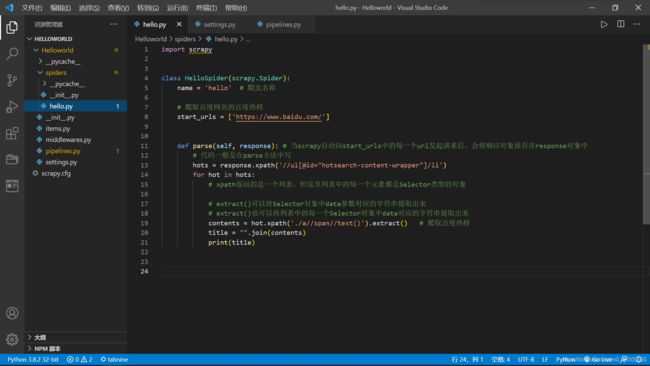
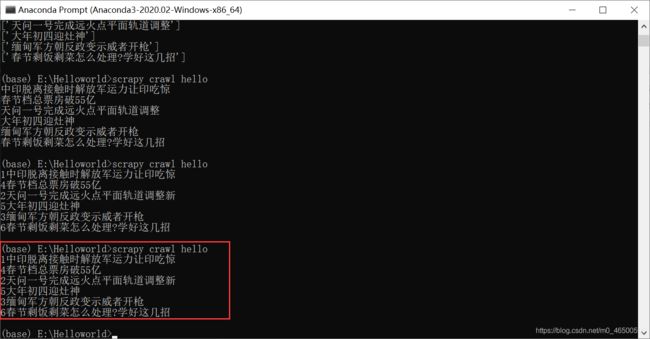
目录简介安装Valgrind基本使用总结简介从第一篇文章我们知道,乐鑫官方给集成了一个调试工具,能够在程序异常时分层追踪到导致异常的地方。这个功能实际上很像Valgrind,她是一个在Linux环境下广泛使用的编程工具套件,主要用于内存调试、内存泄漏检测以及性能分析。它对于识别程序中的内存和线程问题非常有用,特别适用于C和C++程序的开发和调试。在实际的开发过程当中如果遇到不好找的问题特别是崩溃内
- Java 生成 PDF 文档 如此简单
五行星辰
业务系统应用技术pdfjavamaven
嘿,朋友!在Java里实现PDF文档生成那可真是个挺有意思的事儿,今儿个就来好好唠唠这个。咱有不少好用的库可以选择,下面就给你详细讲讲其中两个超实用的库,一个是iText,另一个是ApachePDFBox。用iText库生成PDF思路先把iText库给引入进来,这就好比给咱的Java项目装上了一个生成PDF的“神器”。创建一个Document对象,这个对象就像是一张白纸,咱要在上面绘制PDF的内容
- 【前端高频面试题--ES6篇】
码上有前
前端es6学习javascript
作者:“码上有前”文章简介:前端高频面试题欢迎小伙伴们点赞、收藏⭐、留言前端高频面试题--ES6篇往期精彩内容ES6ES6概念let和constletConst解构赋值模板字符串对象简化箭头函数形参赋初始值Rest参数扩展运算符扩展运算符的应用Symbol的基本使用对象添加Symbol类型的属性Symbol内置值迭代器生成器PromiseSetMapclass类数值扩展对象扩展模块化往期精彩内容【
- python面试情景题_50道python笔试面试真题大集合
我是史迪仔
python面试情景题
Python爬虫人工智能100GBweb爬虫数据分析人工智能视频免费领题目后面有50道题答案领取方式哦1、一行代码实现1--100之和利用sum()函数求和2、如何在一个函数内部修改全局变量利用global修改全局变量3、列出5个python标准库os:提供了不少与操作系统相关联的函数sys:通常用于命令行参数re:正则匹配math:数学运算datetime:处理日期时间4、字典如何删除键和合并两
- 花费上万元的 RTX4090,普通人真的需要它的性能吗?
显卡
众所周知,RTX4090是当之无愧的显卡界卡皇。但对于普通人来说,花费上万元甚至更多去拥有它,真的值得吗?01RTX4090的性能规格它拥有超多的CUDA核心,数量高达16384个。这就好比有一支庞大的计算大军,能够快速处理各种复杂的图形计算任务。无论是玩高画质的3A大作游戏,还是进行专业的图形设计、视频编辑等工作,都能轻松应对。再说说它的显存,容量达到了惊人的24GB。这就像一个巨大的仓库,可以
- JavaScript语法特性篇-动态导入 import()
前端后花园
JS学习资料javascript前端开发语言动态导入静态导入import
1、基本使用import()语法,通常被称为动态导入,是一个类似函数的表达式,它允许异步和动态地将ECMAScript模块加载到一个可能不是模块的环境中。与声明式的导入相对应,动态导入只在需要时进行计算,并且允许更大的语法灵活性。简单来说,使用import()语法,你可以在运行时(而不是在编译时)决定要导入哪个模块,并且这种导入是异步的,不会阻塞代码的执行。awaitimport('/module
- Jetpack架构组件学习——使用Glance实现桌面小组件
工业甲酰苯胺
架构学习gitee
基本使用1.添加依赖添加Glance依赖://ForAppWidgetssupportimplementation"androidx.glance:glance-appwidget:1.1.0"//ForinteropAPIswithMaterial3implementation"androidx.glance:glance-material3:1.1.0"//ForinteropAPIswith
- MATLAB 代码的主要功能是基于功能连接(FC)数据,利用支持向量机(SVM)进行分类,并通过留一法交叉验证、特征选择、超参数寻优、一致性特征分析以及置换检验等步骤,评估分类性能和特征的显著性
max500600
MATLAB开发语言算法matlab支持向量机分类
clear;clcNumROI=37;%ROI数目NumCon=605;%连接数目%选择病人组数据文件夹%path1=spm_select(1,'dir','pleaseselectpatientsdir');path1='D:\siying\42ML_day3\nnnnnn\FC\Patient';%和第7行用一个即可,为手动改路径file1=dir([path1,filesep,'*.txt'
- react路由
一个好好的程序员
react.js
第一部分:路由基本使用基本步骤安装yarnaddreact-router-domreact-router-dom这个包提供了三个核心的组件import{HashRouter,Route,Link}from'react-router-dom'使用HashRouter包裹整个应用,一个项目中只会有一个Router//…省略页面内容使用Link指定导航链接页面一 页面2使用Rout
- Python的输入函数input()
蜗牛_Chenpangzi
Python学习笔记总集python字符串编程语言
前言此篇文章是我在B站学习时所做的笔记,部分为亲自动手演示过的,方便复习用。此篇文章仅供学习参考。提示:以下是本篇文章正文内容,下面案例可供参考input函数input函数的基本使用#输入函数inputpresent=input('大圣想要什么礼物呢?')print(present,
- python爬虫报错日记
雁于飞
笔记经验分享其他python爬虫网络爬虫
python爬虫报错日记类未定义原因:代码检查没有问题**,位置错了**,测试代码包含在类里……UnicodedecodeError错误原因:字符没有自动转换成utf-8格式KeyError:“href”原因:前面运行正常,有异常路由,加个判断写入文件乱码原因:获取正常,写入时encoding异常,不会自动转换成“utf-8”同上3
- WPF 自定义布局面板详解:5步轻松掌握
墨瑾轩
一起学学C#【一】wpf
关注墨瑾轩,带你探索编程的奥秘!超萌技术攻略,轻松晋级编程高手技术宝库已备好,就等你来挖掘订阅墨瑾轩,智趣学习不孤单即刻启航,编程之旅更有趣引言WPF(WindowsPresentationFoundation)是一个强大的用户界面框架,提供了丰富的布局控件。然而,有时候内置的布局控件可能无法满足特定的需求。这时,自定义布局面板就显得尤为重要。本文将详细介绍如何在WPF中自定义布局面板,并通过具体
- ODBC的基本使用
种花的人_
开发工具数据库
前言在工作中,使用POWERBI做数据分析报表的时候用到ODBC,对于POWERBI语义模式实现连接数据库必须使用到ODBC,那什么是ODBC?1.ODBC的基本概念1.1ODBC驱动程序每种数据库都有相应的ODBC驱动程序,这些驱动程序负责处理与数据库的通信。驱动程序将ODBC调用转换为数据库特定的调用,并将结果返回给应用程序。1.2数据源名称(DSN)DSN是一个配置名称,用于保存连接到数据库
- python爬取电影天堂beautiful_Python爬虫 -- 抓取电影天堂8分以上电影
carafqy
看了几天的python语法,还是应该写个东西练练手。刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来。做完花了两三个小时,撸了这么一个程序。反正蛮简单的,思路和之前用nodejs写爬虫一样。爬虫的入口从分页的列表开始,比如美剧的列表第一页地址这样:http://www.ygdy8.net/html/gndy/oumei/list_7_1.html,
- 【图像复原】论文精读:Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration
十小大
超分辨率重建(理论+实战科研+应用)深度学习人工智能计算机视觉图像修复图像处理论文阅读论文笔记
第一次来请先看这篇文章:【超分辨率(Super-Resolution)】关于【超分辨率重建】专栏的相关说明,包含专栏简介、专栏亮点、适配人群、相关说明、阅读顺序、超分理解、实现流程、研究方向、论文代码数据集汇总等)文章目录前言Abstract1.Introduction2.RelatedWork3.Method3.1.ModelScalingUp3.2.ScalingUpTrainingData3
- 架构学习第四周--高可用与NoSQL数据库
Mr.王835
nosqllinux
目录一、HAProxy介绍二、HAProxy基本使用2.1,HAProxy调度算法2.2,HAProxy高级用法三、高可用Keepalived介绍3.1,Keepalived介绍3.2,Keepalived单主架构实现3.3,脑裂四、Keepalived实例--实现单主架构的LVS-DR模型五、实例--通过Keepalived实现HAProxy高可用六、NoSQL数据库Redis6.1,Redis
- TRELLIS文本或图像生3d模型一键整合包win版本,省去繁琐安装、效果超Wonder3D,对硬件要求更低速度更快16g N卡可流畅运行
struggle2025
计算机视觉人工智能深度学习图像处理集成学习AI作画
一、介绍:TRELLIS文生、图生3d模型软件介绍,目前只开放了图生3D(文末提供整合包下载)TRELLIS是一个大型3D资产生成模型。它接受文本或图像提示,并生成各种格式的高质量3D资产,如辐射场、3D高斯和网格。TRELLIS的基石是一种统一的结构化LATent(SLAT)表示法,允许解码到不同的输出格式,以及为SLAT定制的校正流变换器作为强大的后端。我们提供大规模预训练模型,参数高达20亿
- 【超详细】深入解析Kali Linux:常见指令大全,助你成为安全专家
wit_@
chrome前端linuxkail网络安全
深入解析KaliLinux:常见指令大全,助你成为安全专家KaliLinux是网络安全领域最受欢迎的操作系统之一,专为渗透测试、数字取证和网络安全研究而设计。无论你是网络安全新手,还是经验丰富的安全专家,掌握KaliLinux的常见指令都是必不可少的。本文将详细介绍KaliLinux中的一些常见指令,帮助你更好地利用这个强大的工具。1.基本系统指令1.1apt-get包管理KaliLinux基于D
- centos下安装python3详细教程_centos python
m0_60635321
2024年程序员学习centospythonlinux
yum-yinstalllibffi-devel#安装pipyuminstallpython-pip*####4.用pip装wgetpipinstallwget*####5.用wget下载python3的源码包(评论区网友提供了淘宝镜像,替换了官网下载python3,提高下载速度)wgethttp://npm.taobao.org/mirrors/python/3.7.5/Python-3.7.5
- iOS App 上架App Store及提交审核详细教程
鹅肝手握高V五色
cocoamacosobjective-c
上架AppStore审核分7步进行:目录一、上传ipa到AppStore二、设置APP各项信息提交审核1、安装iOS上架辅助软件Appuploader2、申请iOS发布证书(p12)3、申请iOS发布描述文件(mobileprovision)4、打包ipa5、上传ipa到iTunesConnect6、TestFlight方式安装到苹果手机测试7、设置APP各项信息提交审核前四布我们之前都做了,详见
- 2025 年夸克网盘免费扩容1TB空间指引,超详细教程(建议收藏)
chusheng1840
夸克网盘夸克网盘免费扩容‘夸克网盘领取空间夸克网盘扩容
2025年夸克网盘免费扩容1TB空间指引(保姆级教程)哈喽大家好,这里是专注于挖掘各种实用福利的小助手!你有没有遇到过这样的烦恼——网盘存储空间不够用,想存的电影、照片、文件全都放不下?今天我就来给大家安利一个宝藏福利,夸克网盘新用户免费领取1TB存储空间,不仅不限速,还不需要开会员!是不是听着就很心动?别急,今天的教程全程手把手带你走流程,分分钟搞定超大空间!在手机APP登陆操作,电脑端是不能领
- 强化学习代码实践1.DDQN:在CartPole游戏中实现 Double DQN
洪小帅
游戏pythongympytorch深度学习
强化学习代码实践1.DDQN:在CartPole游戏中实现DoubleDQN1.导入依赖2.定义Q网络3.创建Agent4.训练过程5.解释6.调整超参数在CartPole游戏中实现DoubleDQN(DDQN)训练网络时,我们需要构建一个使用两个Q网络(一个用于选择动作,另一个用于更新目标)的方法。DoubleDQN通过引入目标网络来减少Q-learning中过度估计的偏差。下面是一个基于PyT
- 深入解析:使用 Python 爬虫获取苏宁商品详情
数据小爬虫@
python爬虫开发语言
在当今数字化时代,电商数据已成为市场分析、用户研究和商业决策的重要依据。苏宁易购作为国内知名的电商平台,其商品详情页包含了丰富的信息,如商品价格、描述、评价等。这些数据对于商家和市场研究者来说具有极高的价值。本文将详细介绍如何使用Python爬虫获取苏宁商品的详细信息,并提供完整的代码示例。一、爬虫简介爬虫是一种自动化程序,用于从互联网上抓取网页内容。Python因其简洁的语法和强大的库支持,成为
- 网络安全法详细介绍——爬虫教程
小知学网络
网络安全web安全爬虫安全
目录@[TOC](目录)一、网络安全法详细介绍1.网络安全法的主要条款与作用2.网络安全法与爬虫的关系3.合法使用爬虫的指南二、爬虫的详细教程1.准备环境与安装工具2.使用`requests`库发送请求3.解析HTML内容4.使用`robots.txt`规范爬虫行为5.设置请求间隔6.数据清洗与存储三、实战示例:爬取一个公开的新闻网站小知学网络一、网络安全法详细介绍1.网络安全法的主要条款与作用《
- 【网络安全 | Python爬虫】URL、HTTP基础必知必会
秋说
爬虫http网络安全
文章目录URL概念及组成结构HTTP概念简述浏览器接收资源HTTP协议的结构请求结构请求行请求头请求体请求差异及参数说明响应结构状态行响应头响应体推广URL概念及组成结构在开始爬虫的开发实战前,需要了解的是URL的概念及组成结构,这具有基础性和必要性。URL(UniformResourceLocator,统一资源定位符)是用于在互联网上定位和标识资源的字符串。它提供了一种标准的方式来指示资源的位置
- 什么是网络爬虫?Python爬虫到底怎么学?
糯米导航
文末下载资源python
最近我在研究Python网络爬虫,发现这玩意儿真是有趣,干脆和大家聊聊我的心得吧!咱们都知道,网络上的信息多得就像大海里的水,而网络爬虫就像一个勤劳的小矿工,能帮我们从这片浩瀚的信息海洋中挖掘出需要的内容。接下来,我就带你们一步步看看该怎么用Python搞定网络爬虫。为啥选择Python写爬虫?说到Python,简直是写爬虫的最佳选择!它有许多现成的库,就像拥有了各种好用的工具,使得我们的工作变得
- AQ录制V1.7.8--录制工具安装与部署
你爱吃金坷垃吗
开源软件
文章目录一、AQ录制是什么?二、软件情况1.软件功能2.软件实测3.软是件安装配置三、下载地址一、AQ录制是什么?AQ录制软件是一款桌面录制软件,可以直播,录游戏,录网课,录教程,录素材,录课件,支持1080P全时长超清输出二、软件情况【软件功能】【录制】可以录制游戏高光时刻自动合并【视频编辑】可以对录制视频进行编辑【软件实测】【安装配置】下载安装包,解压后双击运行,出现安装向导界面,点击【Nex
- 【HAL库】STM32CubeMX开发----STM32F407----USB实验(CDC虚拟串口)
根号五
#嵌入式开发stm32单片机HAL库STM32CubeMXUSB
STM32CubeMX下载和安装详细教程【HAL库】STM32CubeMX开发----STM32F407----目录STM32F407-HAL库:USB实验(CDC虚拟串口)-程序源码前言本次实验以STM32F407VET6芯片为MCU,使用25MHz外部时钟源。USB通信引脚与MCU引脚对应关系如下:USB通信引脚MCU引脚DM(D-)PA11DP(D+)PA12原理图
- Linux系统中安装Git(详细教程)
wujiada001
云服务部署linuxgit
在Linux系统中安装Git,可以通过多种方式来实现,主要包括使用包管理器安装和从源代码编译安装。以下是详细的安装步骤:一、使用包管理器安装(不建议该方式)大多数Linux发行版都提供了包管理器,如Debian/Ubuntu的apt、CentOS/RHEL的yum/dnf等,通过这些包管理器可以方便地安装Git。1.Debian/Ubuntu及其衍生版打开终端,执行以下命令:sudoaptupda
- Python爬虫项目合集:200个Python爬虫项目带你从入门到精通
人工智能_SYBH
爬虫试读2025年爬虫百篇实战宝典:从入门到精通python爬虫数据分析信息可视化爬虫项目大全Python爬虫项目合集爬虫从入门到精通项目
适合人群无论你是刚接触编程的初学者,还是已经掌握一定Python基础并希望深入了解网络数据采集的开发者,这个专栏都将为你提供系统化的学习路径。通过循序渐进的理论讲解、代码实例和实践项目,你将获得扎实的爬虫开发技能,适应不同场景下的数据采集需求。专栏特色从基础到高级,内容体系全面专栏内容从爬虫的基础知识与工作原理开始讲解,逐渐覆盖静态网页、动态网页、API数据爬取等实用技术。后续还将深入解析反爬机制
- Linux的Initrd机制
被触发
linux
Linux 的 initrd 技术是一个非常普遍使用的机制,linux2.6 内核的 initrd 的文件格式由原来的文件系统镜像文件转变成了 cpio 格式,变化不仅反映在文件格式上, linux 内核对这两种格式的 initrd 的处理有着截然的不同。本文首先介绍了什么是 initrd 技术,然后分别介绍了 Linux2.4 内核和 2.6 内核的 initrd 的处理流程。最后通过对 Lin
- maven本地仓库路径修改
bitcarter
maven
默认maven本地仓库路径:C:\Users\Administrator\.m2
修改maven本地仓库路径方法:
1.打开E:\maven\apache-maven-2.2.1\conf\settings.xml
2.找到
- XSD和XML中的命名空间
darrenzhu
xmlxsdschemanamespace命名空间
http://www.360doc.com/content/12/0418/10/9437165_204585479.shtml
http://blog.csdn.net/wanghuan203/article/details/9203621
http://blog.csdn.net/wanghuan203/article/details/9204337
http://www.cn
- Java 求素数运算
周凡杨
java算法素数
网络上对求素数之解数不胜数,我在此总结归纳一下,同时对一些编码,加以改进,效率有成倍热提高。
第一种:
原理: 6N(+-)1法 任何一个自然数,总可以表示成为如下的形式之一: 6N,6N+1,6N+2,6N+3,6N+4,6N+5 (N=0,1,2,…)
- java 单例模式
g21121
java
想必单例模式大家都不会陌生,有如下两种方式来实现单例模式:
class Singleton {
private static Singleton instance=new Singleton();
private Singleton(){}
static Singleton getInstance() {
return instance;
}
- Linux下Mysql源码安装
510888780
mysql
1.假设已经有mysql-5.6.23-linux-glibc2.5-x86_64.tar.gz
(1)创建mysql的安装目录及数据库存放目录
解压缩下载的源码包,目录结构,特殊指定的目录除外:
- 32位和64位操作系统
墙头上一根草
32位和64位操作系统
32位和64位操作系统是指:CPU一次处理数据的能力是32位还是64位。现在市场上的CPU一般都是64位的,但是这些CPU并不是真正意义上的64 位CPU,里面依然保留了大部分32位的技术,只是进行了部分64位的改进。32位和64位的区别还涉及了内存的寻址方面,32位系统的最大寻址空间是2 的32次方= 4294967296(bit)= 4(GB)左右,而64位系统的最大寻址空间的寻址空间则达到了
- 我的spring学习笔记10-轻量级_Spring框架
aijuans
Spring 3
一、问题提问:
→ 请简单介绍一下什么是轻量级?
轻量级(Leightweight)是相对于一些重量级的容器来说的,比如Spring的核心是一个轻量级的容器,Spring的核心包在文件容量上只有不到1M大小,使用Spring核心包所需要的资源也是很少的,您甚至可以在小型设备中使用Spring。
- mongodb 环境搭建及简单CURD
antlove
WebInstallcurdNoSQLmongo
一 搭建mongodb环境
1. 在mongo官网下载mongodb
2. 在本地创建目录 "D:\Program Files\mongodb-win32-i386-2.6.4\data\db"
3. 运行mongodb服务 [mongod.exe --dbpath "D:\Program Files\mongodb-win32-i386-2.6.4\data\
- 数据字典和动态视图
百合不是茶
oracle数据字典动态视图系统和对象权限
数据字典(data dictionary)是 Oracle 数据库的一个重要组成部分,这是一组用于记录数据库信息的只读(read-only)表。随着数据库的启动而启动,数据库关闭时数据字典也关闭 数据字典中包含
数据库中所有方案对象(schema object)的定义(包括表,视图,索引,簇,同义词,序列,过程,函数,包,触发器等等)
数据库为一
- 多线程编程一般规则
bijian1013
javathread多线程java多线程
如果两个工两个以上的线程都修改一个对象,那么把执行修改的方法定义为被同步的,如果对象更新影响到只读方法,那么只读方法也要定义成同步的。
不要滥用同步。如果在一个对象内的不同的方法访问的不是同一个数据,就不要将方法设置为synchronized的。
- 将文件或目录拷贝到另一个Linux系统的命令scp
bijian1013
linuxunixscp
一.功能说明 scp就是security copy,用于将文件或者目录从一个Linux系统拷贝到另一个Linux系统下。scp传输数据用的是SSH协议,保证了数据传输的安全,其格式如下: scp 远程用户名@IP地址:文件的绝对路径
- 【持久化框架MyBatis3五】MyBatis3一对多关联查询
bit1129
Mybatis3
以教员和课程为例介绍一对多关联关系,在这里认为一个教员可以叫多门课程,而一门课程只有1个教员教,这种关系在实际中不太常见,通过教员和课程是多对多的关系。
示例数据:
地址表:
CREATE TABLE ADDRESSES
(
ADDR_ID INT(11) NOT NULL AUTO_INCREMENT,
STREET VAR
- cookie状态判断引发的查找问题
bitcarter
formcgi
先说一下我们的业务背景:
1.前台将图片和文本通过form表单提交到后台,图片我们都做了base64的编码,并且前台图片进行了压缩
2.form中action是一个cgi服务
3.后台cgi服务同时供PC,H5,APP
4.后台cgi中调用公共的cookie状态判断方法(公共的,大家都用,几年了没有问题)
问题:(折腾两天。。。。)
1.PC端cgi服务正常调用,cookie判断没
- 通过Nginx,Tomcat访问日志(access log)记录请求耗时
ronin47
一、Nginx通过$upstream_response_time $request_time统计请求和后台服务响应时间
nginx.conf使用配置方式:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_r
- java-67- n个骰子的点数。 把n个骰子扔在地上,所有骰子朝上一面的点数之和为S。输入n,打印出S的所有可能的值出现的概率。
bylijinnan
java
public class ProbabilityOfDice {
/**
* Q67 n个骰子的点数
* 把n个骰子扔在地上,所有骰子朝上一面的点数之和为S。输入n,打印出S的所有可能的值出现的概率。
* 在以下求解过程中,我们把骰子看作是有序的。
* 例如当n=2时,我们认为(1,2)和(2,1)是两种不同的情况
*/
private stati
- 看别人的博客,觉得心情很好
Cb123456
博客心情
以为写博客,就是总结,就和日记一样吧,同时也在督促自己。今天看了好长时间博客:
职业规划:
http://www.iteye.com/blogs/subjects/zhiyeguihua
android学习:
1.http://byandby.i
- [JWFD开源工作流]尝试用原生代码引擎实现循环反馈拓扑分析
comsci
工作流
我们已经不满足于仅仅跳跃一次,通过对引擎的升级,今天我测试了一下循环反馈模式,大概跑了200圈,引擎报一个溢出错误
在一个流程图的结束节点中嵌入一段方程,每次引擎运行到这个节点的时候,通过实时编译器GM模块,计算这个方程,计算结果与预设值进行比较,符合条件则跳跃到开始节点,继续新一轮拓扑分析,直到遇到
- JS常用的事件及方法
cwqcwqmax9
js
事件 描述
onactivate 当对象设置为活动元素时触发。
onafterupdate 当成功更新数据源对象中的关联对象后在数据绑定对象上触发。
onbeforeactivate 对象要被设置为当前元素前立即触发。
onbeforecut 当选中区从文档中删除之前在源对象触发。
onbeforedeactivate 在 activeElement 从当前对象变为父文档其它对象之前立即
- 正则表达式验证日期格式
dashuaifu
正则表达式IT其它java其它
正则表达式验证日期格式
function isDate(d){
var v = d.match(/^(\d{4})-(\d{1,2})-(\d{1,2})$/i);
if(!v) {
this.focus();
return false;
}
}
<input value="2000-8-8" onblu
- Yii CModel.rules() 方法 、validate预定义完整列表、以及说说验证
dcj3sjt126com
yii
public array rules () {return} array 要调用 validate() 时应用的有效性规则。 返回属性的有效性规则。声明验证规则,应重写此方法。 每个规则是数组具有以下结构:array('attribute list', 'validator name', 'on'=>'scenario name', ...validation
- UITextAttributeTextColor = deprecated in iOS 7.0
dcj3sjt126com
ios
In this lesson we used the key "UITextAttributeTextColor" to change the color of the UINavigationBar appearance to white. This prompts a warning "first deprecated in iOS 7.0."
Ins
- 判断一个数是质数的几种方法
EmmaZhao
Mathpython
质数也叫素数,是只能被1和它本身整除的正整数,最小的质数是2,目前发现的最大的质数是p=2^57885161-1【注1】。
判断一个数是质数的最简单的方法如下:
def isPrime1(n):
for i in range(2, n):
if n % i == 0:
return False
return True
但是在上面的方法中有一些冗余的计算,所以
- SpringSecurity工作原理小解读
坏我一锅粥
SpringSecurity
SecurityContextPersistenceFilter
ConcurrentSessionFilter
WebAsyncManagerIntegrationFilter
HeaderWriterFilter
CsrfFilter
LogoutFilter
Use
- JS实现自适应宽度的Tag切换
ini
JavaScripthtmlWebcsshtml5
效果体验:http://hovertree.com/texiao/js/3.htm
该效果使用纯JavaScript代码,实现TAB页切换效果,TAB标签根据内容自适应宽度,点击TAB标签切换内容页。
HTML文件代码:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"
- Hbase Rest API : 数据查询
kane_xie
RESThbase
hbase(hadoop)是用java编写的,有些语言(例如python)能够对它提供良好的支持,但也有很多语言使用起来并不是那么方便,比如c#只能通过thrift访问。Rest就能很好的解决这个问题。Hbase的org.apache.hadoop.hbase.rest包提供了rest接口,它内嵌了jetty作为servlet容器。
启动命令:./bin/hbase rest s
- JQuery实现鼠标拖动元素移动位置(源码+注释)
明子健
jqueryjs源码拖动鼠标
欢迎讨论指正!
print.html代码:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv=Content-Type content="text/html;charset=utf-8">
<title>发票打印</title>
&l
- Postgresql 连表更新字段语法 update
qifeifei
PostgreSQL
下面这段sql本来目的是想更新条件下的数据,可是这段sql却更新了整个表的数据。sql如下:
UPDATE tops_visa.visa_order
SET op_audit_abort_pass_date = now()
FROM
tops_visa.visa_order as t1
INNER JOIN tops_visa.visa_visitor as t2
ON t1.
- 将redis,memcache结合使用的方案?
tcrct
rediscache
公司架构上使用了阿里云的服务,由于阿里的kvstore收费相当高,打算自建,自建后就需要自己维护,所以就有了一个想法,针对kvstore(redis)及ocs(memcache)的特点,想自己开发一个cache层,将需要用到list,set,map等redis方法的继续使用redis来完成,将整条记录放在memcache下,即findbyid,save等时就memcache,其它就对应使用redi
- 开发中遇到的诡异的bug
wudixiaotie
bug
今天我们服务器组遇到个问题:
我们的服务是从Kafka里面取出数据,然后把offset存储到ssdb中,每个topic和partition都对应ssdb中不同的key,服务启动之后,每次kafka数据更新我们这边收到消息,然后存储之后就发现ssdb的值偶尔是-2,这就奇怪了,最开始我们是在代码中打印存储的日志,发现没什么问题,后来去查看ssdb的日志,才发现里面每次set的时候都会对同一个key