【第四周】Scrapy爬虫框架——python爬虫慕课笔记
文章目录
- 第十单元:Scrapy爬虫框架
-
- 框架介绍
- 框架解析
- requests库和scrapy库的比较
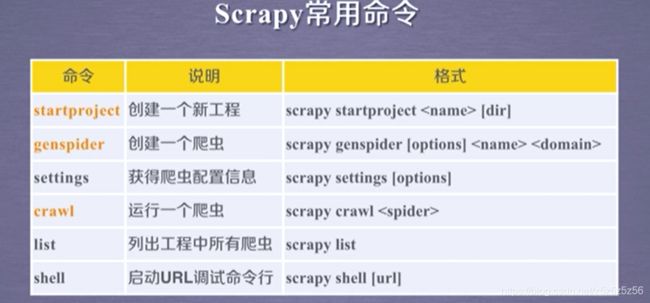
- scrapy爬虫的常用命令
- 第十一单元:Scrapy爬虫基本使用
-
- 第一个实例
- yield关键字的使用
- Scrapy爬虫的基本使用
-
- Request类
- Response类
- Item类
- 第十二单元:实例:股票数据Scrapy爬虫(见PPT,现不可用)
第十单元:Scrapy爬虫框架
框架介绍

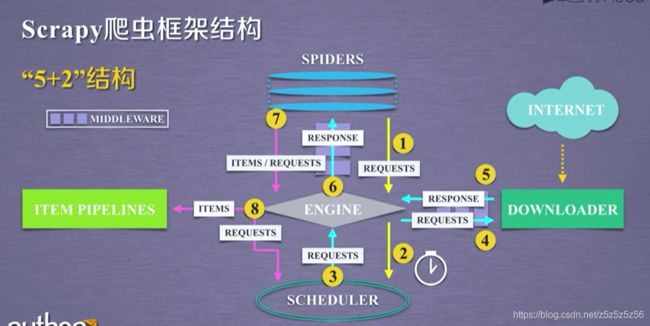
入口:SPIDERS(提供要访问的url连接,提取访问内容)
出口:ITEM PIPLINES(提取后处理)
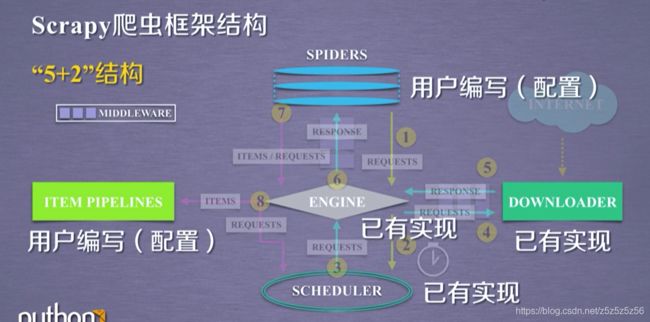
框架解析
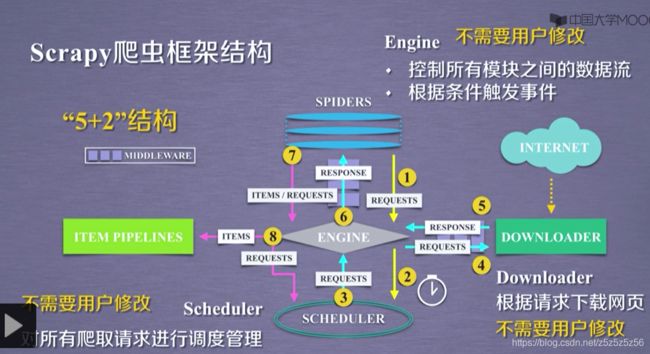


requests库和scrapy库的比较



scrapy爬虫的常用命令


第十一单元:Scrapy爬虫基本使用
第一个实例

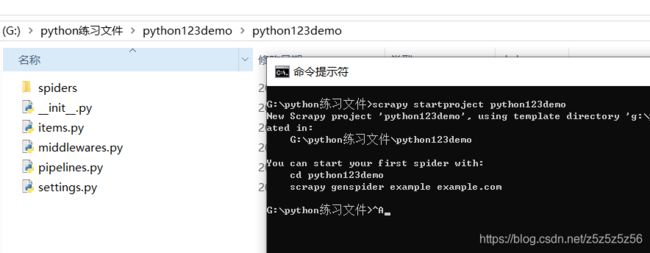

创建一个爬虫

然后需要配置demo.py文件
parse函数就是爬取函数,需要我们写具体功能
从网页爬取内容对应的对象response存储在文件中
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['demo.io']
start_urls = ['https://python123.io/ws/demo.html']
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % name)
然后执行scrapy crawl demo
即可在目录下获得抓取的网站页面

yield关键字的使用
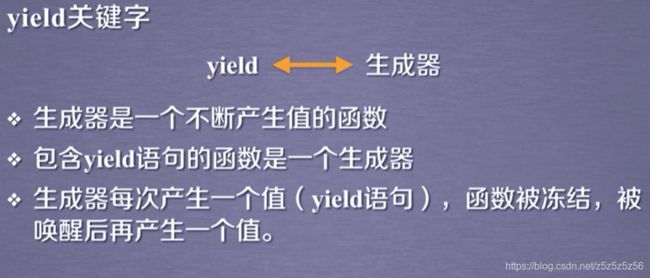

在gen函数的for循环中,每次调用生成器会返回一个值

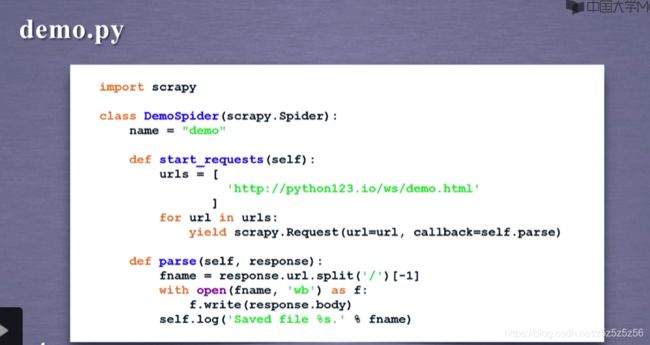
使用for循环每次提交urls列表中的一个url请求,这是一种生成器写法,每次返回一个url连接
Scrapy爬虫的基本使用

Request类


Response类


Item类

键值对封装

第十二单元:实例:股票数据Scrapy爬虫(见PPT,现不可用)


下面是stocks.py文件源代码
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['https://quote.eastmoney.com/stocklist.html']
def parse(self, response):
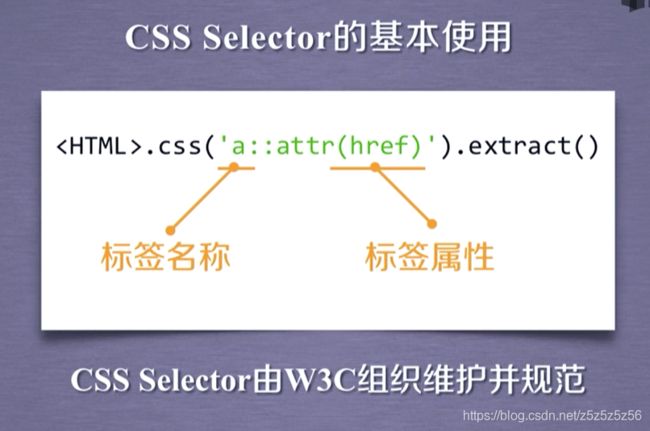
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}", href)[0]
url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
def parse_stock(self, response):
infoDict = {
}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*', keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key]=val
infoDict.update(
{
'股票名称': re.findall('\s.*\(',name)[0].split()[0] + \
re.findall('\>.*\<', name)[0][1:-1]})
yield infoDict


下面是pipelines.py文件源代码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
def open_spider(self, spider):
self.f = open('BaiduStockInfo.txt', 'w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item

下面是settings.py文件中被修改的区域:
# Configure item pipelines
# See https://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}

完结散花~