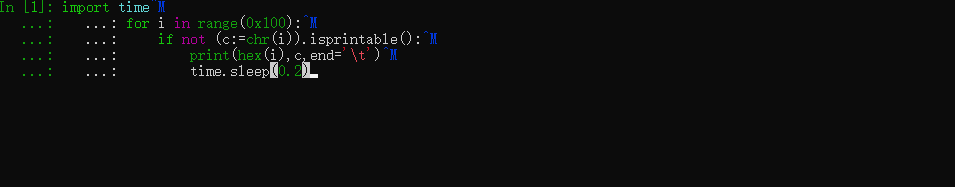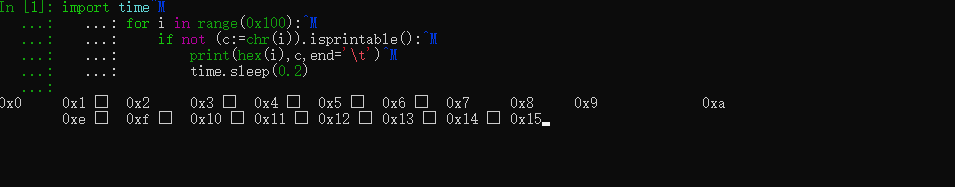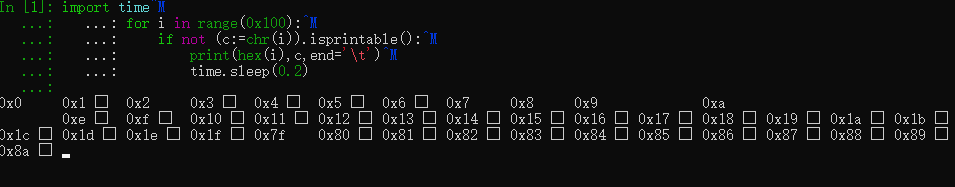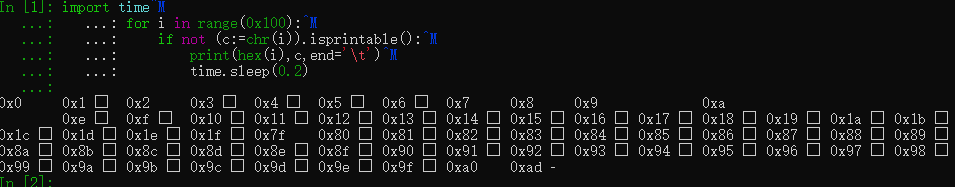Python 转义字符
| input | repr | hex | Name | 名称 | 应用 | |
|---|---|---|---|---|---|---|
| \" | " | " | 22 | Quotation Mark | 引号 | |
| \’ | ’ | ’ | 27 | Apostrophe | 撇号 | |
| \N | - | - | - | \N{name} | 字符 | 按照unicode name显示字符 |
| \U | - | - | - | \UXXXXXXXX | 字符 | Unicode : 0XFFF~0X110000 |
| \\ | \\ | \ | 2F | Solidus | 斜线号 | |
| \a | \x07 | - | 7 | 同\7 | 同\7 | |
| \b | \x08 | - | 8 | Backspace | 退格 | 键盘Backspace |
| \f | \x0c | - | C | Form Feed | 换页 | 在某些环境下,进入下一页 |
| \n | \n | - | A | New Line | 换行 | 键盘Enter |
| \r | \r | - | D | Carriage Return | 回车 | 回车不换行 |
| \t | \t | - | 9 | Horizontal Tabulation | 横向制表 | 键盘Tab |
| \u | - | - | - | \uXXXX | 字符 | Unicode : 0xFF~0xFFFF |
| \v | \x0b | - | B | Vertical Tabulation | 纵向制表 | |
| \x | - | - | - | \xXX | 字符 | Unicode : 0x00~0xFF |
| \000 | ||||||
| \0 | \x00 | - | 0 | Null | 空 | 停止复制 |
| \1 | \x01 | 1 | Start of Heading | 头标开始 | ||
| \2 | \x02 | - | 2 | Start of Text | 正文开始 | 段首缩进两个字符 |
| \3 | \x03 | 3 | End of Text | 正文结束 | ||
| \4 | \x04 | 4 | End of Transmission | 传输结束 | ||
| \5 | \x05 | 5 | Enquiry | 询问 | ||
| \6 | \x06 | 6 | Acknowledge | 确认 | ||
| \7 | \x07 | 7 | Bell | 响铃 | 系统提示音 | |
| \ | - | - | - | - | 续行符 | 代码行尾 |
1、简单的\ + ascii的组合,实现常用的非字符编辑,如回车、退格、制表等
2、响铃,程序提示用
3、因为语法的原因而必须的操作,斜杠、引号
4、输入unicode字符,对应的十六进制:\xFF \uFFFF \UFFFFFFFF
5、输入unicode字符,对应的name,\N{Bell} 【注】
6、输入unicode字符,对应的八进制,\000 \0 \00
\a、\x07、\007、\7、\07、\N{BEL}
这几个都是响铃的意思,但是要注意后面两个,如果后接字符,不能使八进制字符(0~7)
\N{Bell},我本想输出\a,但是,他输出的是,我是从网上查的,网上写错了
Bell
(BEL)
我想找一个查询字符的name的方法,没有找到,网上通用的namereplace,仅能编码ascii范围以外的。而且python的encode最终都是建立在内核上的,少数的少量codepage,只是一个简单的映射。
一番折腾后,还是自己写一个吧!
Python 转义字符\N{…}
'a'.encode('name',errors='namereplace')
UnicodeEncodeError: 'charmap' codec can't encode character '\x61' in position 0: character maps to <undefined>
'香'.encode('ascii',errors='namereplace')
Out[94]: b'\\N{CJK UNIFIED IDEOGRAPH-9999}'
b'\\N{CJK UNIFIED IDEOGRAPH-9999}'.decode('unicode_escape')
Out[95]: '香'
if 1:print('1\
2')
12
if 1:print('1\
2')
1 2
if 1:print\
('12')
12
if 1:print('''1
2''')
1
2
if 1:print('''1\
2''')
12
if 1:print(r'''1\
2''')
1\
2
for i in range(0x80):
if (c:=chr(i)).isprintable():
try:s=eval("'\%s'"%c)
except:print(c,'Error')
else:
if s!='\\'+c:
print(c,repr(s))
" '"'
' "'"
0 '\x00'
1 '\x01'
2 '\x02'
3 '\x03'
4 '\x04'
5 '\x05'
6 '\x06'
7 '\x07'
N Error
U Error
\ '\\'
a '\x07'
b '\x08'
f '\x0c'
n '\n'
r '\r'
t '\t'
u Error
v '\x0b'
x Error
从简单的理解上,转义字符就是使用\开启后,连着后面的字节代替一个不能打印或者有其他意思的字符。
是Python语法中的一种,既然是\带一个打印字符,那肯定是键盘上能敲出来的,于是我把所有的可打印的ascii用\开头,如果他的字面量表达式和他的生成值不一样,那他就是一个转义字符。
C0控制
上面0~7,对应ascii的C0控制。
for i in range(0x100):
... c=chr(i)
... print(repr(c),end=' ')
‘\x00’ ‘\x01’ ‘\x02’ ‘\x03’ ‘\x04’ ‘\x05’ ‘\x06’ ‘\x07’ ‘\x08’ ‘\t’ ‘\n’ ‘\x0b’ ‘\x0c’ ‘\r’ ‘\x0e’ ‘\x0f’ ‘\x10’ ‘\x11’ ‘\x12’ ‘\x13’ ‘\x14’ ‘\x15’ ‘\x16’ ‘\x17’ ‘\x18’ ‘\x19’ ‘\x1a’ ‘\x1b’ ‘\x1c’ ‘\x1d’ ‘\x1e’ ‘\x1f’ ’ ’ ‘!’ ‘"’ ‘#’ ‘$’ ‘%’ ‘&’ “’” ‘(’ ‘)’ ‘*’ ‘+’ ‘,’ ‘-’ ‘.’ ‘/’ ‘0’ ‘1’ ‘2’ ‘3’ ‘4’ ‘5’ ‘6’ ‘7’ ‘8’ ‘9’ ‘:’ ‘;’ ‘<’ ‘=’ ‘>’ ‘?’ ‘@’ ‘A’ ‘B’ ‘C’ ‘D’ ‘E’ ‘F’ ‘G’ ‘H’ ‘I’ ‘J’ ‘K’ ‘L’ ‘M’ ‘N’ ‘O’ ‘P’ ‘Q’ ‘R’ ‘S’ ‘T’ ‘U’ ‘V’ ‘W’ ‘X’ ‘Y’ ‘Z’ ‘[’ ‘\’ ‘]’ ‘^’ ‘_’ ‘`’ ‘a’ ‘b’ ‘c’ ‘d’ ‘e’ ‘f’ ‘g’ ‘h’ ‘i’ ‘j’ ‘k’ ‘l’ ‘m’ ‘n’ ‘o’ ‘p’ ‘q’ ‘r’ ‘s’ ‘t’ ‘u’ ‘v’ ‘w’ ‘x’ ‘y’ ‘z’ ‘{’ ‘|’ ‘}’ ‘~’ ‘\x7f’ ‘\x80’ ‘\x81’ ‘\x82’ ‘\x83’ ‘\x84’ ‘\x85’ ‘\x86’ ‘\x87’ ‘\x88’ ‘\x89’ ‘\x8a’ ‘\x8b’ ‘\x8c’ ‘\x8d’ ‘\x8e’ ‘\x8f’ ‘\x90’ ‘\x91’ ‘\x92’ ‘\x93’ ‘\x94’ ‘\x95’ ‘\x96’ ‘\x97’ ‘\x98’ ‘\x99’ ‘\x9a’ ‘\x9b’ ‘\x9c’ ‘\x9d’ ‘\x9e’ ‘\x9f’ ‘\xa0’ ‘¡’ ‘¢’ ‘£’ ‘¤’ ‘¥’ ‘¦’ ‘§’ ‘¨’ ‘©’ ‘ª’ ‘«’ ‘¬’ ‘\xad’ ‘®’ ‘¯’ ‘°’ ‘±’ ‘²’ ‘³’ ‘´’ ‘µ’ ‘¶’ ‘·’ ‘¸’ ‘¹’ ‘º’ ‘»’ ‘¼’ ‘½’ ‘¾’ ‘¿’ ‘À’ ‘Á’ ‘Â’ ‘Ã’ ‘Ä’ ‘Å’ ‘Æ’ ‘Ç’ ‘È’ ‘É’ ‘Ê’ ‘Ë’ ‘Ì’ ‘Í’ ‘Î’ ‘Ï’ ‘Ð’ ‘Ñ’ ‘Ò’ ‘Ó’ ‘Ô’ ‘Õ’ ‘Ö’ ‘×’ ‘Ø’ ‘Ù’ ‘Ú’ ‘Û’ ‘Ü’ ‘Ý’ ‘Þ’ ‘ß’ ‘à’ ‘á’ ‘â’ ‘ã’ ‘ä’ ‘å’ ‘æ’ ‘ç’ ‘è’ ‘é’ ‘ê’ ‘ë’ ‘ì’ ‘í’ ‘î’ ‘ï’ ‘ð’ ‘ñ’ ‘ò’ ‘ó’ ‘ô’ ‘õ’ ‘ö’ ‘÷’ ‘ø’ ‘ù’ ‘ú’ ‘û’ ‘ü’ ‘ý’ ‘þ’ ‘ÿ’
其实以上带\的全是转义字符,他们的转义目标只有一个字符长度,只是无法打印出来。
以上也是encode的unicode_escape和raw_unicode_escape编码不一样的地方。unicode_escape会把字符串中的转义字符以字符串对待。
'ÿ'.encode('unicode_escape')
Out[24]: b'\\xff'
'ÿ'.encode('raw_unicode_escape')
Out[25]: b'\xff'
'香'.encode('raw_unicode_escape')
Out[26]: b'\\u9999'
'\n'.encode('raw_unicode_escape')
Out[27]: b'\n'
'\n'.encode('unicode_escape')
Out[28]: b'\\n'
‘\t’、’\n’、’\r’被定义为字面量和内容一样的
‘\a’、’\b’、’\f’、’\v’,可以输入,但内容转化成对应的\x
\、’、",因为语法的需要,必须转义才能正确输出
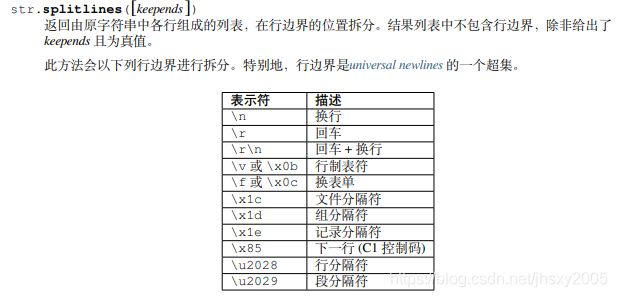
在str.splitlines()中,支持多种字符
print('1\x852')
1
2
print('1\x1c2')
1
2
print('1\x1d2')
1
2
print('1\x1e2')
1
2

在剪贴板上,都变成了回车换行,

但在Qt中,ascii部分显示为白块,不在ascii的部分显示为黑块。a0是一种空格,ad是一种连字符
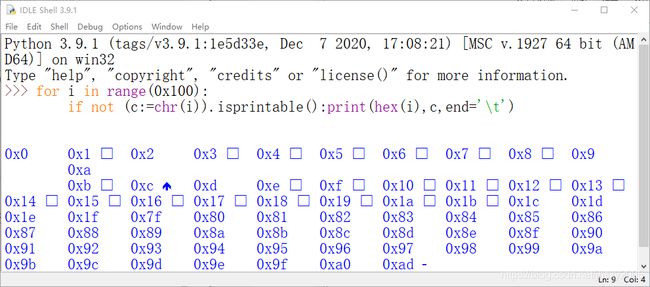
Tk中
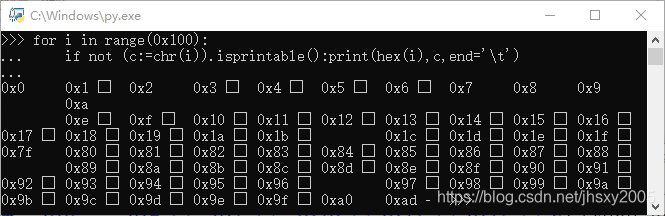
cmd
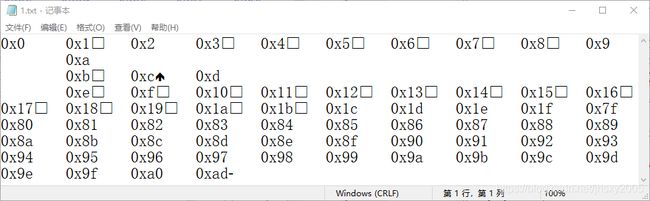
l=[]
for i in range(0x100):
if not (c:=chr(i)).isprintable():l.append(hex(i)+chr(i))
s='\t'.join(l)
open('a:/1.txt','w',encoding='utf-8').write(s)
Out[16]: 385