爬虫笔记(四)——Scrapy爬虫框架
文章目录
-
- 写在前面
- 一、Scrapy爬虫框架
-
- 1.Scrapy爬虫框架介绍
- 2.Scrapy爬虫框架解析
- 3.Requests库和Scrapy框架的比较
- 4.Scrapy爬虫常用命令
- 二、Scrapy爬虫基本使用
-
- 1.简单实例
- 2.yield关键字
- 3.基本使用
- 三、课程实例
- 引用源自
写在前面
因为最近在中国大学MOOC网上学习嵩天老师(北京理工大学)的爬虫课程,所以为了方便自己以后编程时查找相关内容,也为了方便各位小伙伴们学习,整理这篇关于爬虫中Scrapy框架的基本知识点。本篇涉及图的地方,我会截取课程内容的截图(因为我实在是懒得画图了),涉及表的地方我会重新制作,一是为了美观,二是为了加深印象,因为函数和方法太多不常用的话就会遗忘。好了。话不多说,开干!
一、Scrapy爬虫框架
1.Scrapy爬虫框架介绍
(1)Scrapy的安装
Win+R输入cmd进入command命令行模式输入如下代码
pip install scrapy
(2)Scrapy安装测试
命令行键入
scrapy -h
(3)Scrapy爬虫框架结构(5+2)
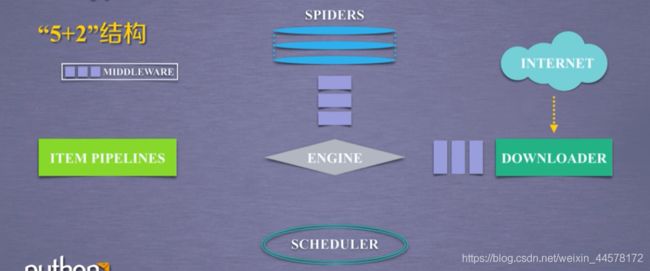
其中包含三条主要的数据流:
a:Spiders->Engine->Scheduler
b:Scheduler->Engine->Downloader->Engine->Spiders
c:Spiders->Engine->Scheduler(Item pipelines)

2.Scrapy爬虫框架解析
| 使用 | 模块 | 功能 |
|---|---|---|
| 不需要用户修改 | Engine | 框架核心,控制所有模块之间的数据流;根据条件触发事件 |
| 不需要用户修改 | Downloader | 根据请求下载网页 |
| 不需要用户修改 | Scheduler | 对所有爬取请求进行调度管理 |
| 需要用户修改 | Downloader Middleware | 实施Engine、Scheduer和Downloader之间进行用户可配置的控制:修改、丢弃、新增请求或响应 |
| 需要用户修改 | Spider | 解析Downloader返回的响应(Response)产生爬取项,产生额外的爬取请求 |
| 需要用户修改 | Item Piplines | 以流水线方式处理Spider产生的爬取项操作包括:清理,检验,查重,存储数据 |
| 需要用户修改 | Spider Middleware | 对请求和爬取项再处理 |
3.Requests库和Scrapy框架的比较
(1)相同点

(2)不同点
| Requests | Scrapy |
|---|---|
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手十分简单 | 入门稍难 |
(3)如何选用

4.Scrapy爬虫常用命令
(1)Scrapy命令行格式
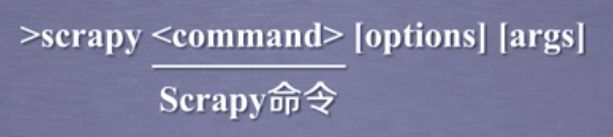
(2)常用命令
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject[dir] |
| genspider | 创建一个爬虫 | scrapy genspider [options] |
| settings | 获得爬虫配置信息 | scrapy settings [options] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调试命令行 | scrapy shell [url] |
(3)Scrapy爬虫的命令行逻辑

二、Scrapy爬虫基本使用
1.简单实例
步骤
(1)建立一个Scrapy爬虫工程:scrapy startproject python123demo
(2)在工程中产生一个Scrapy爬虫:scrapy genspider demo python123.io
(3)配置产生的spider爬虫demp.py
简化版
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname, 'wb') as f:
f.write(response.body)
self.log("Save file %s." % fname)
完整版
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
def start_requests(self):
urls = [
'http://python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname, 'wb') as f:
f.write(response.body)
self.log("Save file %s." % fname)
(4)运行爬虫:scrapy crawl demo
2.yield关键字

(1)生成器实例:求一组数的平方值

(2)为什么要有生成器

3.基本使用
(1)使用步骤
a.创建一个工程和Spider模板
b.编写Spider
c.编写Item Pipleline
d.优化配置策略
(2)涉及到的三个类
a.Request类
class scrapy.http.Request(): 表示一个http请求,由Spider生成,由Downloader执行
| 属性或方法 | 说明 |
|---|---|
| .url | Request对应的请求的URL地址 |
| .method | 对应的请求方法,‘GET’,‘POST’等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容主体,字符串风格 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 |
| .copy() | 复制该请求 |
b.Response类
class. scrapy.http.Response():表示一个http响应。由Downloader生成,由Spider处理
| 属性或方法 | 说明 |
|---|---|
| .url | Response对应的URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头信息 |
| .body | Response 对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Request对象 |
| .copy() | 复制该响应 |
c.Item类
class scrapy.item.Item(): Item对象表示一个从HTML中提取的信息内容,由Spider生成,由Item Pipeline处理。类似字典类型,可以按照字典类型操作
(3)信息提取方法
a.Beautiful Soup
b.lxml
c.re
d.XPath Selector
e.CSS Selector
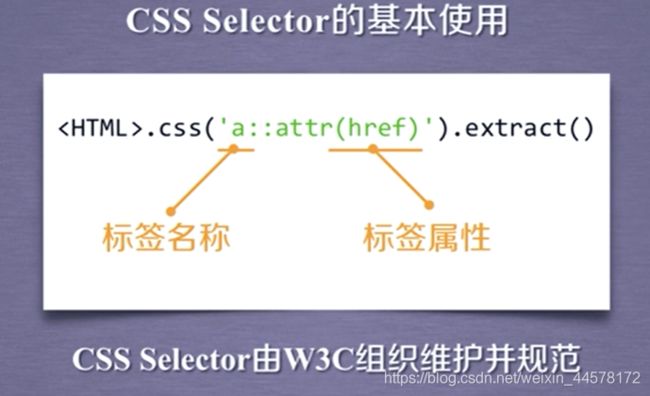
三、课程实例
这部分的课程实例我在昨天的博客中已经写过了,有需要的小伙伴可以参考。
股票数据Scrapy爬虫: https://blog.csdn.net/weixin_44578172/article/details/109521481
本篇完,如有错误欢迎指出~
引用源自
中国大学MOOC Python网络爬虫与信息提取
https://www.icourse163.org/course/BIT-1001870001
CSDN博客
https://blog.csdn.net/songhui1024/article/details/84575575