爬虫(9)-python爬虫爬取电子书存储在txt文件中
文章目录
-
- 1.分析主页面
- 2.分析电子书主页面
- 3.分析正文界面
- 4.存储
- 5.全部代码+解析
- 6结果展示
- 7.总结
本文以笔趣阁网站为例,爬取网站上的电子书并存储在本地记事本中。
网站地址:https://www.biqukan.com/
认为有用的话请点赞,码字不易,谢谢。
其他爬虫实战请查看:https://blog.csdn.net/qq_42754919/category_10354544.html
1.分析主页面
打开网址,F12查看网页源代码,我们发现四部比较火的电子书的节点属性是< hot >,本文主要爬取四部比较火的电子书。

我们从class=item节点提取电子书的地址,源代码给的URL需要加上原始代码。
items = html.xpath(
'//div[@class="wrap"]//div[@class="hot"]//div//div[@class="item"]//div//div//a/@href')
for item in items:
novel_url = url+str(item)
2.分析电子书主页面
在电子书的主页面我们发现所有的URL都在< class="listmain’>节点中,并且分为最新章节列表和正文卷,我们提取出所有< dd >节点,选取从12开始之后的链接作为爬取主要目标,如果需要爬取全部章节,包括最新章节,则不需要从第12个节点开始。提取的URL也是需要添加基础url,补全URL。
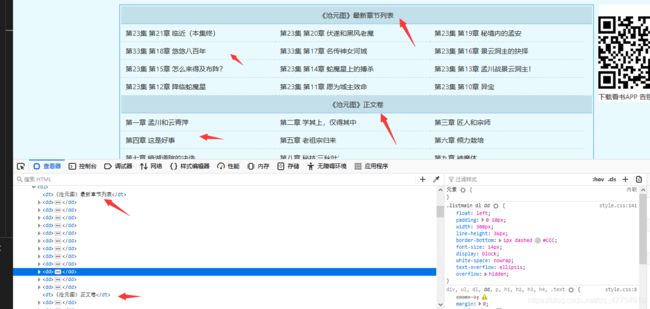
novels = soup.find_all(name="dd")
head = soup.find(attrs={
'class': 'info'}).h2.string
for i in range(12, len(novels)):
base_url = novels[i].a.attrs['href']
title = novels[i].a.string
content_url = url+base_url
3.分析正文界面
正文内容全部在< class=“showtxt”>内,因此直接提取文本即可。但是提取文本中包含read2();等无关信息,我们使用字符串切片去除。
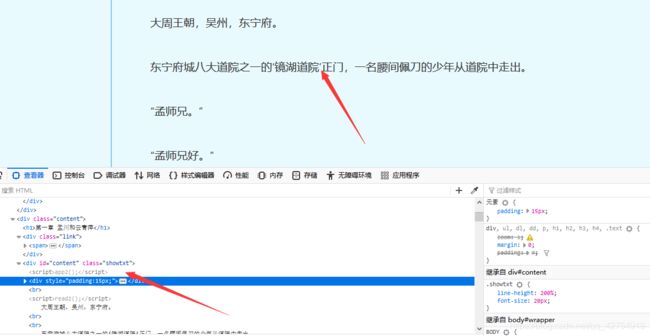
content = soup.find(attrs={
'class': 'showtxt'}
).text.replace(" ", "")[17:]
4.存储
综上已经将全部内容提取出来,下面我们将按照章节进行存储在记事本中。
为了更好提高阅读体验,我们按照一行存储最大字节原则,不需要横向滑动。
with open(file_path, 'w', encoding='utf-8')as f:
print('已爬取'+str(clock)+'章 '+'正在存储:'+head+' '+title)
for i in range(len(content)//88):
f.write(content[i*88:(i+1)*88]+'\n')
5.全部代码+解析
- 在提取页面代码时,页面内容编码是:Content-Typetext/html;,因此在提取时我们进行了转码
- 将提取的所有章节都在保存在以电子书名称命名的文件夹。
- 每行最大存储88个字节,有的记事本每行并没有达到最大字节数,可以修改数字。最大貌似是95个字节。
- 使用replcae函数将前面无关信息截取掉。
- 如果想要提取最新全部章节,将for i in range(12, len(novels)):改为从0开始遍历,或者采用迭代方式,for novel in novels:此外还需要更改。
base_url = novel.a.attrs['href'] title = novel.a.string
import requests
import re
import os
from bs4 import BeautifulSoup
from hashlib import md5
from lxml import etree
def gethtml(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'gb2312' # 转码
return response.text
else:
return None
def geturl(html):
html = etree.HTML(html)
items = html.xpath(
'//div[@class="wrap"]//div[@class="hot"]//div//div[@class="item"]//div//div//a/@href')
for item in items:
novel_url = url+str(item)
getnovel(novel_url)
def getnovel(urls):
html = gethtml(urls)
soup = BeautifulSoup(html, 'lxml')
novels = soup.find_all(name="dd")
head = soup.find(attrs={
'class': 'info'}).h2.string
for i in range(12, len(novels)):
base_url = novels[i].a.attrs['href']
title = novels[i].a.string
content_url = url+base_url
clock = i-11
writenovel(content_url, title, head, clock)
def writenovel(content_url, title, head, clock):
html = gethtml(content_url)
soup = BeautifulSoup(html, 'lxml')
novel_path = '电子书'+os.path.sep+head
if not os.path.exists(novel_path):
os.makedirs(novel_path)
file_path = novel_path+os.path.sep + \
'{0}.{1}'.format(title.replace(' ', ''), 'txt')
content = soup.find(attrs={
'class': 'showtxt'}
).text.replace(" ", "")[17:]
if not os.path.exists(file_path):
with open(file_path, 'w', encoding='utf-8')as f:
print('已爬取'+str(clock)+'章 '+'正在存储:'+head+' '+title)
for i in range(len(content)//88):
f.write(content[i*88:(i+1)*88]+'\n')
else:
print('OK', file_path)
url = 'https://www.biqukan.com'
if __name__ == '__main__':
html = gethtml(url)
geturl(html)
6结果展示
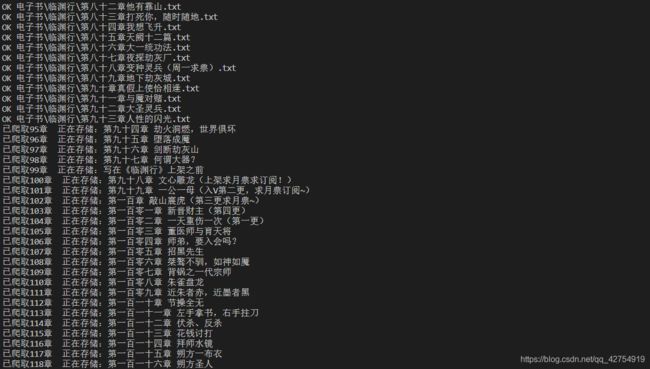
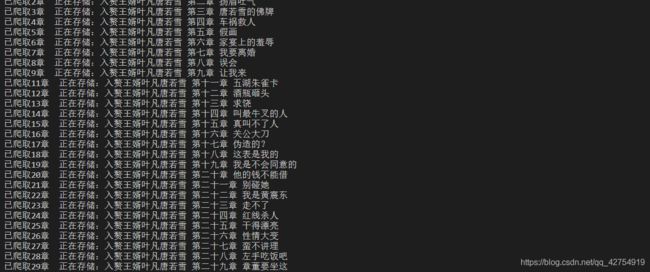
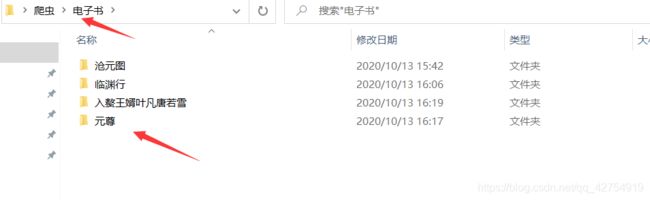
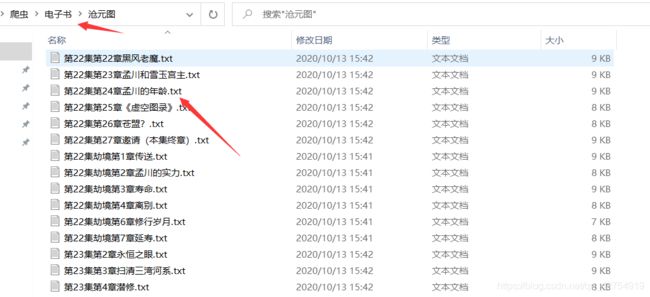

7.总结
综上即为电子书的全部爬取过程,认为有作用的请点赞,码字不易,谢谢。