机器学习----keras 设计一个CNN卷积神经网络花卉分类器进行花卉的分类
同学自己分组,上网收10类花的图片1100张,按{牡丹,月季,百合,菊花,荷花,紫荆花,梅花,…}标注,其中1000张作为训练样本,100张作为测试样本,设计一个CNN卷积神经网络花卉分类器进行花卉的分类,完成模型学习训练后,进行分类测试,并做误差分析,检查模型的泛化性。
额,这里我们在网上找了10类花朵的数据,将数据进行分类,放在各个文件夹,文件名是花朵的标签,然后对图片大小统一为256*256。
将数据集分成训练集(train)、验证集(validation)、测试集(test)
分别为训练集800张,验证集100张,测试集100张,训练集和验证集的需要进行灰度处理,测试集不需要。

训练集:顾名思义指的是用于训练的样本集合,主要用来训练神经网络中的参数.
验证集:从字面意思理解即为用于验证模型性能的样本集合.不同神经网络在训练集上训练结束后,通过验证集来比较判断各个模型的性能.这里的不同模型主要是指对应不同超参数的神经网络,也可以指完全不同结构的神经网络.
测试集:对于训练完成的神经网络,测试集用于客观的评价神经网络的性能.

(一)数据预处理
1.批量重命名文件名:
# -*- coding:utf8 -*-
import os
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = r'C:\Users\admin\Desktop\Machine Learning\flowers\9' #表示需要命名处理的文件夹
self.label = 9
def rename(self):
#os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。这个列表以字母顺序
filelist = os.listdir(self.path)
total_num = len(filelist) #获取文件夹内所有文件个数
i = 1 #表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.jpg'):
#初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的即可)
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path),str(self.label) + '_'+str(i) + '.jpg')
#处理后的格式也为jpg格式的,当然这里可以改成png格式
#dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg')
#这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式
try:
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()2.修改图片大小尺寸,256*256
#提取目录下所有图片,更改尺寸后保存到另一目录
from PIL import Image
import os.path
import glob
def convertjpg(jpgfile,outdir,width=256,height=256):
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(jpgfile)))
except Exception as e:
print(e)
save_file_path = r"C:\Users\admin\Desktop\Machine Learning\flowers\0_cut"
try:
os.mkdir(save_file_path)
except Exception as e:
print(e)
for jpgfile in glob.glob(r"C:\Users\admin\Desktop\Machine Learning\flowers\0\*.jpg"):
convertjpg(jpgfile,save_file_path)
3.将RGB图片转成灰度图片
import os
import cv2
import numpy as np
def convert2gray(filename): # 将彩色图转灰度图的函数
img = cv2.imread(file_path+'/'+filename, 1) # 1是以彩色图方式去读
print(img)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imwrite(out_path + '/' + filename, gray_img) # 保存在新文件夹下,且图名中加GRAY
file_path = r"C:\Users\admin\Desktop\Machine Learning\flowers\9_cut" # 输入文件夹
Gray_path = r"C:\Users\admin\Desktop\Machine Learning\flowers\9_GRAY"
try:
os.mkdir(Gray_path) # 建立新的目录
except Exception as e:
print(e)
out_path = Gray_path # 设置为新目录为输出文件夹
for filename in os.listdir(file_path): # 遍历输入路径,得到图片名
print(filename)
convert2gray(filename)

(二)CNN模型训练
1.小编使用的是CPU跑的,首先跑1600次, 可以达到98%多的准确率,收敛速度有点慢
#! -- coding: utf-8 --*--
import tensorflow as tf
# import keras.backend.tensorflow_backend as ktf
# 设定 GPU 显存占用比例为 0.3
# config = tf.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.7
# session = tf.Session(config=config)
# ktf.set_session(session )
from keras.preprocessing import image#图像预处理工具得模块
from keras.preprocessing.image import img_to_array
from keras import models
from keras import layers
from keras import optimizers
from keras.models import load_model
train_dir=r'C:\Users\admin\Desktop\Machine Learning\flowers\Gray\train'
validation_dir=r'C:\Users\admin\Desktop\Machine Learning\flowers\Gray\validation'
#定义一个包含dropout的新卷积神经网络
# model=models.Sequential()
model = load_model('flower_model.h5')
model.summary()
model.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(256,256,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Dropout(0.25))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512,activation='relu'))
# model.add(layers.Dense(256,activation='relu'))
model.add(layers.Dense(10,activation='sigmoid'))
model.compile(loss='categorical_crossentropy',optimizer=optimizers.RMSprop(lr=1e-4),metrics=['acc'])
#利用数据增强生成器训练卷积神经网络
train_datagen=image.ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,
shear_range=0.2,zoom_range=0.2,horizontal_flip=True)
# train_datagen=img_to_array(train_datagen)
#注意,不能增强验证数据集
test_datagen=image.ImageDataGenerator(rescale=1./255)
#将所有图像的大小调整为150*150
#因为使用了binary_crossentropy损失,所以需要用二进制标签
train_generator=train_datagen.flow_from_directory(train_dir,target_size=(256,256),batch_size=16,class_mode='categorical')
validation_generator=test_datagen.flow_from_directory(validation_dir,target_size=(256,256),batch_size=16,class_mode='categorical')
history=model.fit_generator(train_generator,steps_per_epoch=25,epochs=600,validation_data=validation_generator,validation_steps=25)
#模型保存
model.save('flower_model.h5')得到模型flower_model.h5

2.可以在原先跑出来的模型的基础上继续跑,加载模型继续训练
from keras import layers
from keras import models
from keras.models import load_model
# 绘制训练过程中的损失函数曲线和精度曲线
import matplotlib.pyplot as plt
# 使用ImageDataGenerator从目录中读取图像
from keras.preprocessing.image import ImageDataGenerator
import os
from PIL import Image
import numpy as np
# keras.preprocessing.image能够将硬盘上的图像文件自动转换为预处理的张量批量
model = load_model('flower_model.h5')
train_datagen = ImageDataGenerator(rescale=1. / 255, #归一化
rotation_range=10, #旋转角度
width_shift_range=0.1, #水平偏移
height_shift_range=0.1, #垂直偏移
shear_range=0.1, #随机错切变换的角度
zoom_range=0.1, #随机缩放的范围
horizontal_flip=True, #随机将一半图像水平翻转
vertical_flip=True, #垂直翻转
fill_mode='nearest') #填充像素的方法
test_datagen = ImageDataGenerator(rescale=1./255)
train_dir = r'C:\Users\admin\Desktop\Machine Learning\flowers\Gray\train'
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(256,256),
batch_size=20,
class_mode='categorical'
)
validation_dir=r'C:\Users\admin\Desktop\Machine Learning\flowers\Gray\validation'
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(256,256),
batch_size=20,
class_mode='categorical'
)
# 利用生成器,我们让模型对数据进行拟合
history = model.fit_generator(
train_generator,
steps_per_epoch=25,
epochs=600,
validation_data=validation_generator,
validation_steps=25
)
# 良好实践,保存模型
model.save('flower_model1.h5')
print(type(validation_generator.image_data_generator))(三)模型测试
from keras import layers
from keras import models
from keras.models import load_model
from keras.preprocessing import image#图像预处理工具得模块
from keras.preprocessing.image import ImageDataGenerator
# 绘制训练过程中的损失函数曲线和精度曲线
import matplotlib.pyplot as plt
import pylab
# 使用ImageDataGenerator从目录中读取图像
from keras.preprocessing.image import ImageDataGenerator
import os
from PIL import Image
import numpy as np
validation_dir=r'C:\Users\admin\Desktop\Machine Learning\flowers\Gray\test'
test_datagen=image.ImageDataGenerator(rescale=1./255)
validation_generator=test_datagen.flow_from_directory(validation_dir,target_size=(256,256),batch_size=10,class_mode='categorical')
# keras.preprocessing.image能够将硬盘上的图像文件自动转换为预处理的张量批量
model = load_model('flower_model1.h5')
model.summary()
# score = model.evaluate(validation_generator,verbose = 0)
# print(score)
# print('Test score:', score[0])
# print('Test accuracy:', score[1])
x_test,y_test=next(validation_generator)
# print('x_test',x_test[0:2])
# print('y_test',y_test[0:2])
font={ 'color': 'red',
'size': 20,
'family': 'Times New Roman',
#'style':'italic', # 斜体
'fontweight':'bold'
}
n = 5
encoded_data = y_test[0:n]
# one_hot 解码
decoded_data = np.argmax(encoded_data, axis=1)
# print(decoded_data)
# print(type(decoded_data))
decoded_data = list(decoded_data)
print(decoded_data)
# print(type(decoded_data))
# 从文件夹中读取图片标签
def get_imglst(test_path):
test_label_lst = os.listdir(test_path)
return test_label_lst
test_path = r'C:\Users\admin\Desktop\Machine Learning\flowers\Gray\test'
test_label_lst = get_imglst(test_path)
for i in range(len(decoded_data)):
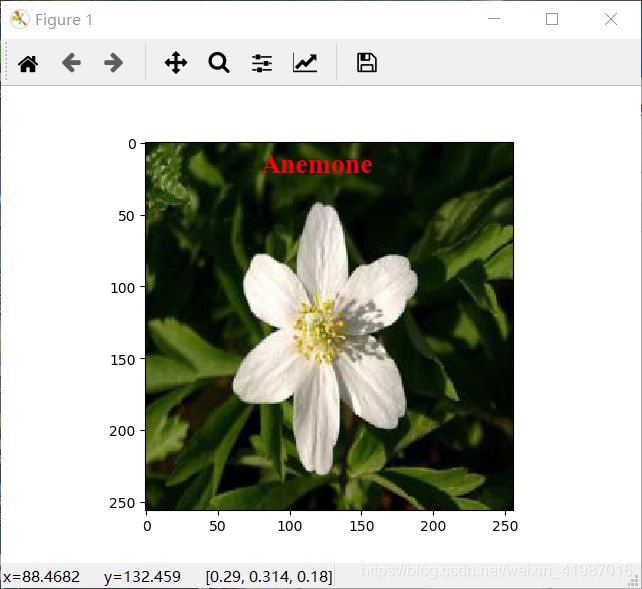
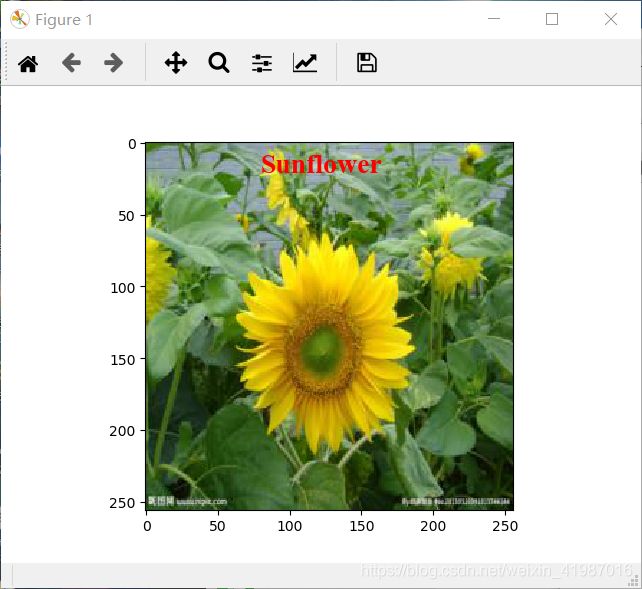
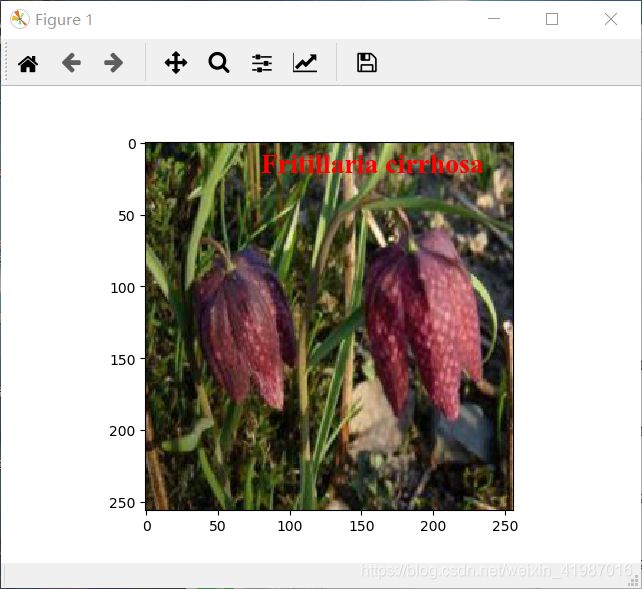
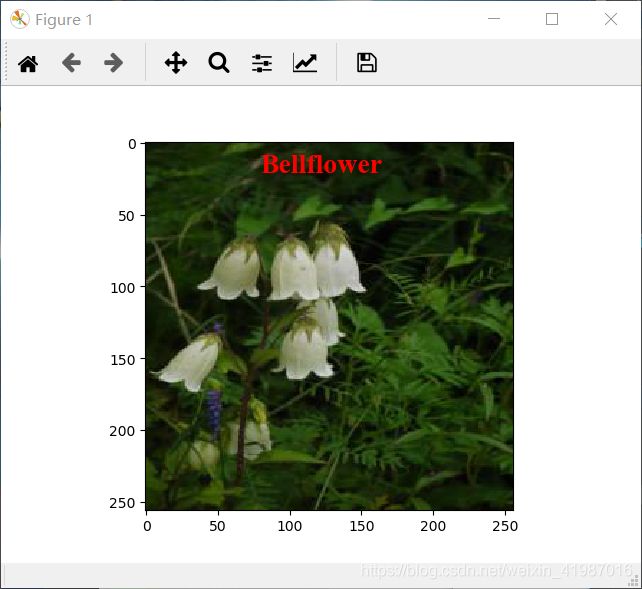
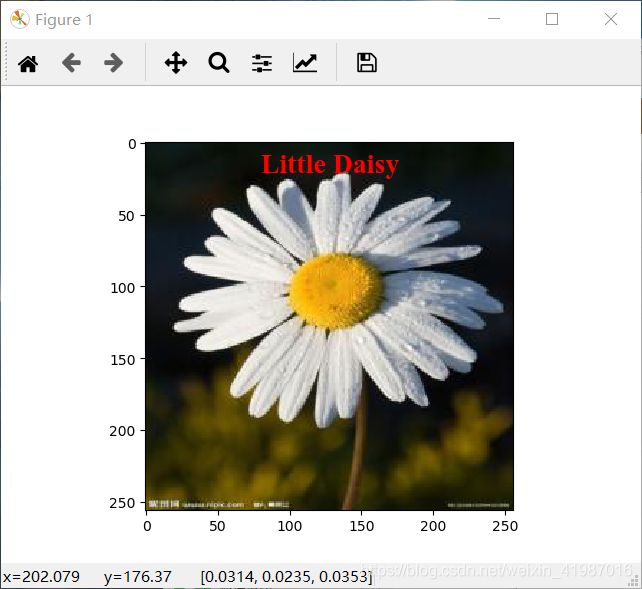
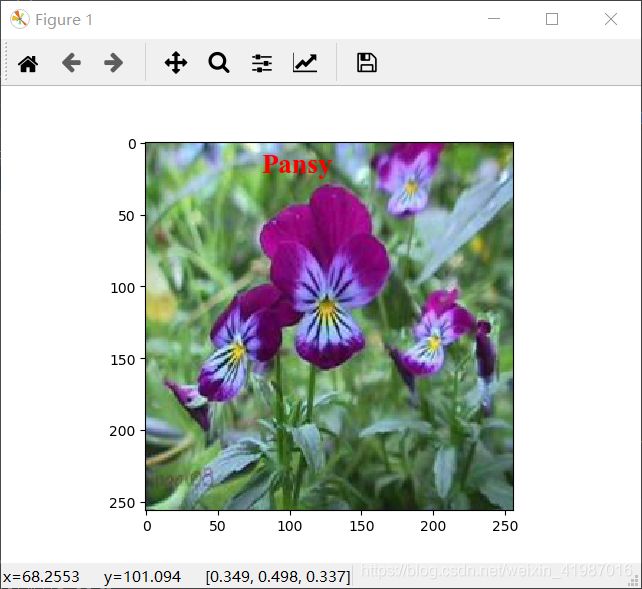
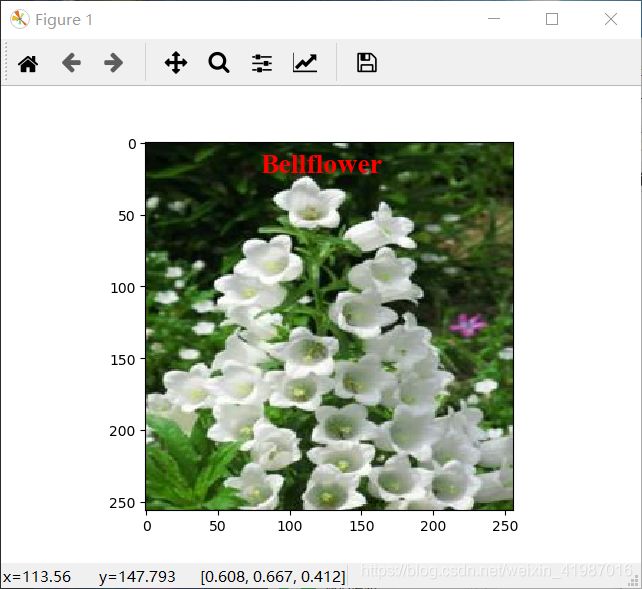
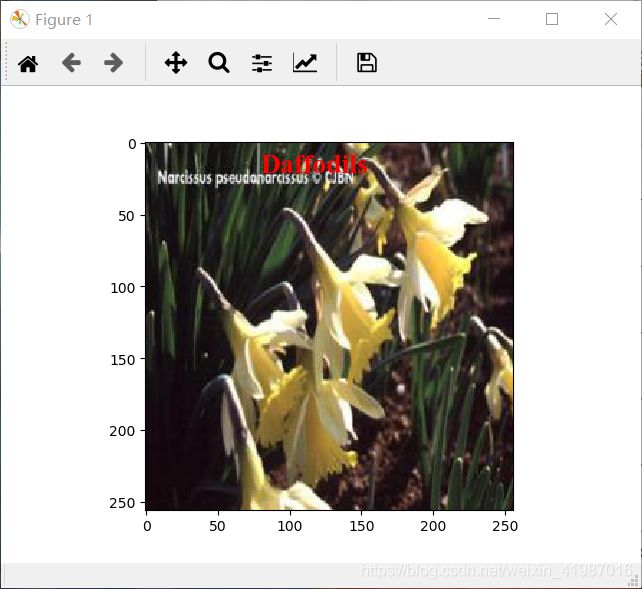
print('该花朵的种类是%s'%test_label_lst[decoded_data[i]])
plt.imshow(x_test[i])
plt.text(80, 20, test_label_lst[decoded_data[i]], fontdict=font)
pylab.show()实验结果图: