python爬虫基础爬取猫眼电影
爬取猫眼电影排行榜第一页
import requests
from requests.exceptions import RequestException
from sqlalchemy import create_engine
from lxml import etree
import pandas as pd
import numpy as np
url = 'https://maoyan.com/board/4'
try:
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
response=requests.get(url,headers=headers)
if response.status_code==200:
response=response.text
except RequestException:
print("错误")
html_1=etree.HTML(response)
movie_sorce_1=html_1.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[1]/text()')
movie_sorce_2=html_1.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[2]/text()')
movie_sorce=[]
for i in range(10):
movie_sorce.append(movie_sorce_1[i]+movie_sorce_2[i])
movie_title=html_1.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/a/@title')
movie_actor=html_1.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[2]/text()')
movie_time=html_1.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[3]/text()')
data_1=[]
for i in range(10):
data = {
}
data['title']=movie_title[i]
data['sorce']=movie_sorce[i]
data['actor']=movie_actor[i].strip()
data['time']=movie_time[i]
data_1.append(data)
print(data_1)
file=pd.DataFrame(data_1)
engine = create_engine("mysql+pymysql://root:password@localhost:3306/data?charset=utf8")
pd.io.sql.to_sql(file, 'maoyan', engine, schema=data, if_exists='append')
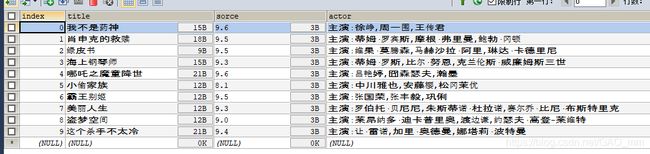
总结:随手写的,希望大佬放过,可以添加循环实现多页爬取,这里就懒得加了。。。
最后:我是小白,不要喷我啊
