多元统计分析——聚类分析——K-均值聚类(K-中值、K-众数)
| 聚类方法 | 适用场景 | 代表算法 | 优点 | 缺陷 | 延伸 |
| 层次聚类 | 小样本数据 | - | 可以形成类相似度层次图谱,便于直观的确定类之间的划分。 该方法可以得到较理想的分类 |
难以处理大量样本 | |
| 基于划分的聚类 | 大样本数据 | K-means算法 |
|
|
|
| 两步法聚类 | 大样本数据 | BIRCH算法 | 层次法和k-means法的结合,具有运算速度快、不需要大量递归运算、节省存储空间的优点 | - | |
| 基于密度的聚类 |
大样本数据 | DBSCAN算法 |
|
当簇的密度变化太大时,会有麻烦对于高维问题,密度定义是个比较麻烦的问题 | |
| 密度最大值算法 | - | - |
注意:有的时候我们可以结合各个聚类算法的特性进行聚类,层次聚类的特点是比较直观的确定聚成几类合适,K-均值聚类的特点在于速度,所以这个这个时候我们可以采用以下的步骤进行聚类:
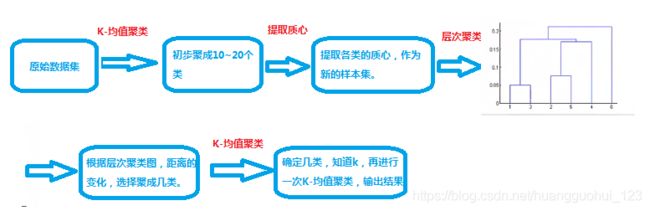
一、K-均值聚类
K-均值聚类与层次聚类都是关于距离的聚类模型,关于层次聚类的介绍详见《多元统计分析——聚类分析——层次聚类》。
层次聚类的局限:在层次聚类中,一旦个体被分入一个族群,它将不可再被归入另一个族群(单向的过程,局部最优的解法)。
故现在介绍一个“非层次”的聚类方法——分割法(Partition)。最常用的分割法是k-均值(k-Means)法。
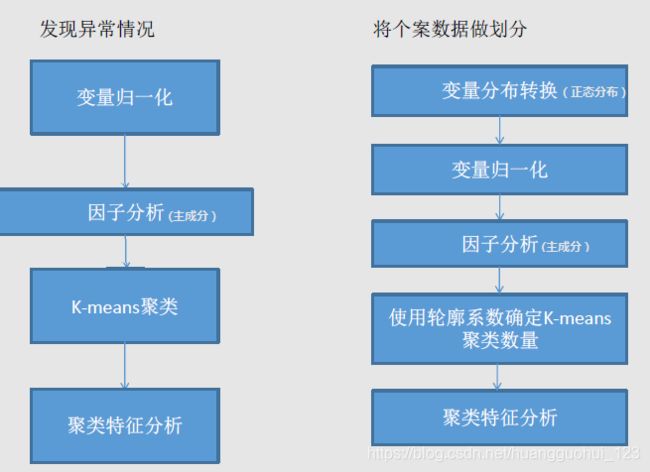
1、聚类算法的两种常见运用场景
- 发现异常情况:如果不对数据进行任何形式的转换,只是经过中心标准化或级差标准化就进行快速聚类,会根据数据分布特征得到聚类结果。这种聚类会将极端数据单独聚为几类。这种方法适用于统计分析之前的异常值剔除,对异常行为的挖掘,比如监控银行账户是否有洗钱行为、监控POS机是有从事套现、监控某个终端是否是电话卡养卡客户等等。
- 将个案数据做划分:出于客户细分目的的聚类分析一般希望聚类结果为大致平均的几大类(原始数据尽量服从正态分布,这样聚类出来的簇的样本点个数大致接近),因此需要将数据进行转换,比如使用原始变量的百分位秩、Turkey正态评分、对数转换等等。在这类分析中数据的具体数值并没有太多的意义,重要的是相对位置。这种方法适用场景包括客户消费行为聚类、客户积分使用行为聚类等等。
以上两种场景的大致步骤如下:
聚类算法不仅是建模的终点,更是重要的中间预处理过程,基于数据的预处理过程,聚类算法主要应用于以下领域:
- 图像压缩:在使用聚类算法做图像压缩过程时,会先定义K个颜色数(例如128种颜色、256种颜色),颜色数就是聚类类别的数量;K均值聚类算法会把类似的颜色分别放在K个簇中,然后每个簇使用一种颜色来代替原始颜色,那么结果就是有多少个簇,就生成了由多少种颜色构成的图像,由此实现图像压缩。
- 图像分割:图像分割就是把图像分成若干个特定的、具有独特性质的区域,并提出感兴趣的目标技术和过程,这是图像处理和分析的关键步骤。图像分割后提取出的目标可以用于图像语义识别、图像搜索等领域。例如从图像中分割出前景人脸信息,然后做人脸建模和识别。
- 图像理解:在图像理解中,有一种称为基于区域的提取方法。基于区域的提取方法是在图像分割和对象识别的前提下进行的,利用对象模板、场景分类器等,通过识别对象及对象之间的拓扑关系挖掘语义,生成对应的场景语义信息。例如,先以颜色、形状等特征对分割后的图像区域进行聚类,形成少量BLOB;然后通过CMRM模型计算出BLOB与某些关键词共同出现的联合概率。
- 数据离散化: 使用K均值将样本集分为多个离散化的簇。
2、K-均值聚类算法原理
K-均值法试图寻找 个族群(
个族群(![]() )的划分方式,使得划分后的族群内方差(within-group sum of squares,WGSS)最小,其中
)的划分方式,使得划分后的族群内方差(within-group sum of squares,WGSS)最小,其中 ,这里
,这里![]() 是族群
是族群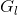 中变量
中变量 的均值,
的均值,![]() ,
,![]() 。
。
![]() 可以理解为每个点到其簇(最终聚类)的质心的距离之和。
可以理解为每个点到其簇(最终聚类)的质心的距离之和。
3、聚类步骤
给定,如何有效地最小化WGSS?
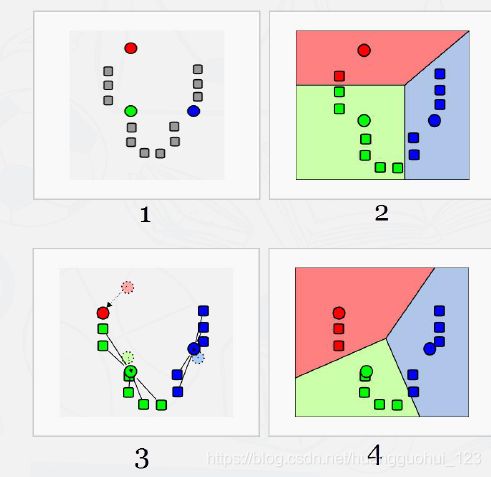
- 选定个“种子”(Cluster seeds,初始质心,可以不是原始数据中的样本点)作为初始族群代表。
- 每个个体归入距离其最近的种子所在的族群。
- 归类完成后,将新产生的族群的质心定为新的种子。
- 重复步骤2和3,直到不再需要移动质心。
4、k的选取
我们的目标是使得WGSS足够小,是否应该选取k使得WGSS最小?
根据上面的式子我们知道,当![]() (即每个族群只有一个点)的时候,
(即每个族群只有一个点)的时候, ,即组内方差平方和最小。但是这个时候就是一个过拟合的现象。也就是说,我们的目标是选择一个使得WGSS足够小(但不是最小)的值。
,即组内方差平方和最小。但是这个时候就是一个过拟合的现象。也就是说,我们的目标是选择一个使得WGSS足够小(但不是最小)的值。
我们可以用WGSS的碎石图来寻找最优的,通常选取拐点(knee point)为最优的,如下图。
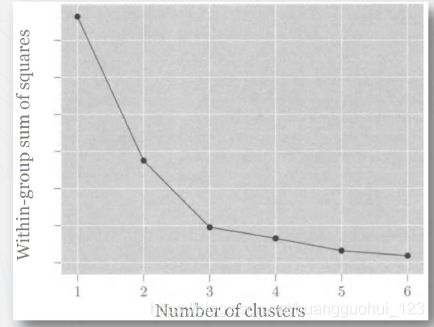
图中建议选择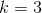 。从3开始,下降率开始变得缓慢。
。从3开始,下降率开始变得缓慢。
注意:与主成分分析和因子分析选取特征值个数的区别:如果上图是主成分和因子分析的碎石图,则建议取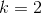 。
。
5、选择初始种子(质心)

我们知道,如上边左图,如果我们的初始质心选择如左图那样,那我们的聚类效果会非常好,并且质心会更加快速的收敛。但是如果初始质心选择如右图那样,那我们的聚类收敛速度就会比较慢,并且根据质心移动的原理,绿色区域(或者红色区域)的质心很难移动到图中的右下区域,也就是说,无法将右下区域单独聚成一类,所以聚类效果没有左图好。这个时候我们就叫做一个局部最优的聚类,没有达到全局最优。所以,初始种子(质心)的选择还是很重要的。
有多种初始种子的选取方法可供选择:
- 在相互间隔超过某指定最小距离的前提下,随机选择个个体。
- 选择数据集前个相互间隔超过某指定最小距离的个体。
- 选择个相互距离最远的个体。
- 选择个等距网格点(Grid points),这些点可能不是数据集的点。
【小贴士】
- k-均值法对初始种子的选择比较敏感。可尝试再不同的种子选择下多次进行聚类。如果不同的初始种子造成了聚类结果很大的不同,或是收敛的速度极其缓慢,也许说明数据可能原本并不存在天然的族群(本身数据集就不太适合做聚类)。
- k-均值法也可以作为层次聚类的一种改进。 我们首先用层次聚类法聚类,通过“剪枝”把它聚成
二、对K-Means的思考
1、K-中值、K-众数
K-Means将簇中所有点的均值作为新质心,若簇中含有异常点,将导致均值偏离严重。以一维数据为例:•数组1、2、3、4、100的均值为22,显然距离“大多数”数据1、2、3、4比较远,改成求数组的中位数3,在该实例中更为稳妥。这种聚类方式即K-Mediods聚类(K-中值聚类),另外还有以众数来求质心的方法的聚类,称为K-Mode聚类(K-众数聚类)。以下为三种不同方法的适用场景:
| 聚类方法 | 求质心方法 | 适合场景 |
| K-Means | 平均值 | 一般场景 |
| K-Mediods | 中位数 | 异常点较为明显的数据集 |
| K-Mode | 众数 | 适合分类变量,只有分类变量的众数才相对有意义 |
2、K-Means适用范围
K-Means适用于以下分布的数据集:
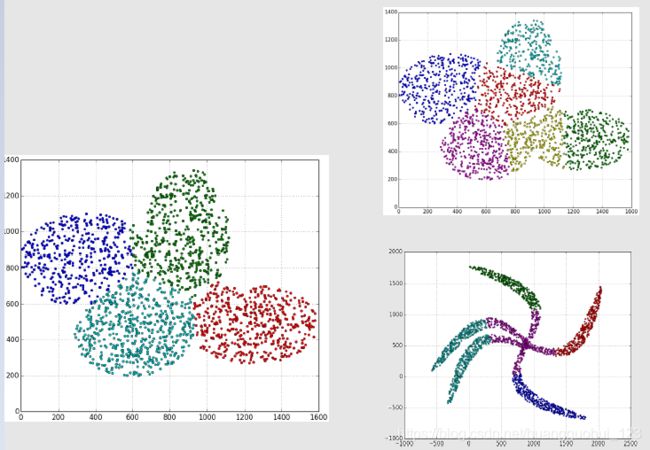
3、模型评估指标:轮廓系数(Silhouette) VS 族群内方差(WGSS) VS 调整兰德系数(Adjusted Rand index)
3.1、族群内方差(WGSS)
前面已经讲过:
K-均值法的原理是:寻找个族群(![]() )的划分方式,使得划分后的族群内方差(within-group sum of squares,WGSS)最小,其中。
)的划分方式,使得划分后的族群内方差(within-group sum of squares,WGSS)最小,其中。
那么我们是否可以使用![]() 来作为聚类的衡量指标呢?即
来作为聚类的衡量指标呢?即![]() 越小模型越好。
越小模型越好。
可以,但是![]() 的缺点和极限太大。
的缺点和极限太大。
-
第一,它不是有界的。我们只知道,
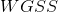 越小越好,是0最好,但我们不知道,一个较小的究竟有没有达到模型的极限,能否继续提高。
越小越好,是0最好,但我们不知道,一个较小的究竟有没有达到模型的极限,能否继续提高。 -
第二,它的计算太容易受到特征数目的影响,数据维度很大的时候,
的计算量会陷入维度诅咒之中,计算量会爆炸,不适合用来一次次评估模型。 -
第三,它会受到超参数K的影响,前面介绍过,随着K越大,
注定会越来越小,但这并不代表模型的效果越来越好了。 -
第四,
对数据的分布有假设,它假设数据满足凸分布(即数据在二维平面图像上看起来是一个凸函数的样子),并且它假设数据是各向同性的(isotropic),即是说数据的属性在不同方向上代表着相同的含义。但是现实中的数据往往不是这样。所以使用作为评估指标,会让聚类算法在一些细长簇,环形簇,或者不规则形状的流形时表现不佳。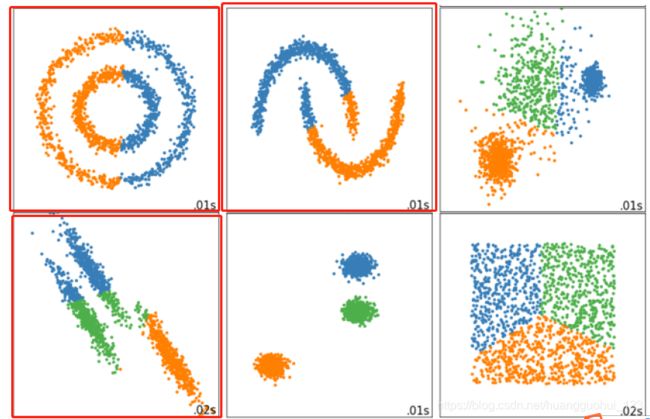
鉴于 ![]() 的不足,我们下边介绍以下聚类算法最常用的模型评估指标——轮廓系数(Silhouette)。
的不足,我们下边介绍以下聚类算法最常用的模型评估指标——轮廓系数(Silhouette)。
3.2、轮廓系数(Silhouette)
轮廓系数是综合评价簇内的稠密程度(簇内差异小)和簇间的离散程度(簇外差异大)来评估聚类的效果的指标。
它是对每个样本来定义的,它能够同时衡量:
-
簇内不相似度
 :样本
:样本 与其自身所在的簇中的其他样本的不相似度,等于样本与同一簇中所有其他点之间的平均距离,越小,说明样本越应该被聚类到该簇。
与其自身所在的簇中的其他样本的不相似度,等于样本与同一簇中所有其他点之间的平均距离,越小,说明样本越应该被聚类到该簇。 -
簇间不相似度
 :样本与其他簇中的样本的不相似度,等于样本与另一个最近的簇中的所有点之间的平均距离,越大,说明样本越不属于其他簇。
:样本与其他簇中的样本的不相似度,等于样本与另一个最近的簇中的所有点之间的平均距离,越大,说明样本越不属于其他簇。
根据聚类的要求”簇内差异小,簇外差异大“,我们希望永远大于,并且大得越多越好。
单个样本的轮廓系数计算为:
![]() ,此方程可以进一步解析为:
,此方程可以进一步解析为: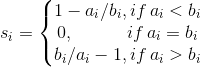
 接近1,则说明样本聚类合理;接近-1,则说明样本更应该分类到另外的簇;若近似为0,则说明样本在两个簇的边界上,两个簇本应该是一个簇。在sklearn中,我们使用模块metrics的silhouette_sample计算数据集中每个样本自己的轮廓系数。
接近1,则说明样本聚类合理;接近-1,则说明样本更应该分类到另外的簇;若近似为0,则说明样本在两个簇的边界上,两个簇本应该是一个簇。在sklearn中,我们使用模块metrics的silhouette_sample计算数据集中每个样本自己的轮廓系数。
所有样本的的均值称为聚类结果的轮廓系数,是该聚类是否合理、有效的度量标准。在sklearn中,我们使用模块metrics中的类silhouette_score来计算总体聚类效果的轮廓系数。
轮廓系数有很多优点,它在有限空间中取值,使得我们对模型的聚类效果有一个“参考”。并且,轮廓系数对数据的分布没有假设,因此在很多数据集上都表现良好。但它在每个簇的分割比较清洗时表现最好。但轮廓系数也有缺陷,它在凸型的类上表现会虚高,比如基于密度进行的聚类,或通过DBSCAN获得的聚类结果,如果使用轮廓系数来衡量,则会表现出比真实聚类效果更高的分数。
实际应用中,需要紧密结合轮廓系数与业务需求,才能得到恰当的结果(选择聚成几类,除了轮廓系数,还需要考虑实际业务)。
3.3、调整兰德系数(Adjusted Rand index,ARI)
评价指标分为外部指标和内部指标两种,外部指标指评价过程中需要借助数据真实情况进行对比分析,内部指标指不需要其他数据就可进行评估的指标。
| 方法 | 类别 | 取值范围 | 最佳值 |
| 轮廓系数 | 内部指标 | [-1,1] | 1 |
| 调整兰德系数(Adjusted Rand index) | 外部指标 | [-1,1] | 1 |
3.3.1、兰德系数(Rand index,RI)
讲ARI之前呢,先讲述一下RI,也就是rand index,从两者的名字也可以看出来,这是ARI的祖宗版。
![]()
a表示应该在一类(标准答案),最后也聚类到一类的数量。
b表示不应该在一类 ,最后聚类结果也没把他们聚类在一起的数量。
c和d表示应该在一类而被分开的和不应该在一类而被迫住在一起的。
c和d固然是错误的。所以从R的表达式中可以看出,我们只认为a和b是对的,这样能够保证RI在0到1之间,而且,聚类越准确,指标越接近于1。
这里有一个关键性的问题,如何计算配对的数量?比如说a是应该在一类而真的在一类的数量。
在 个样本点中,任意选两个就是一个配对。所以,就是
个样本点中,任意选两个就是一个配对。所以,就是![]() 这样来计算,也就是组合数(个样本当中选两个的选法有几种)。同时我们看到,分母其实是所有配对的总和,所以,我们最后可以写成这样:
这样来计算,也就是组合数(个样本当中选两个的选法有几种)。同时我们看到,分母其实是所有配对的总和,所以,我们最后可以写成这样:![]() 。
。
3.3.2、调整兰德系数(Adjusted Rand index,ARI)
RI有一个缺点,就是惩罚力度不够,换句话说,大家普遍得分比较高,遍地80分。这样的话,区分度不高。于是就诞生出了ARI,这个指标相对于RI就很有区分度了。
调整兰德系数(Adjusted Rand index,ARI):当聚类结果有“标准答案”时,可以使用ARI评价聚类效果。
![]()
具体公式如下:
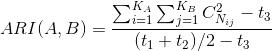 ,其中
,其中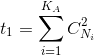 ,
,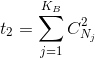 ,
,![]()
其中A和B是数据集Z的两个划分(注意:其中一个划分即所谓的“标准答案”),分别有![]() 和
和![]() 个簇;
个簇;
 ,
,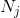 分别表示划分A中第个簇与划分B的第个簇中数据的数量。
分别表示划分A中第个簇与划分B的第个簇中数据的数量。
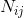 表示在划分A的第个簇中的数据同时也在划分B的第个簇中数据的数量,
表示在划分A的第个簇中的数据同时也在划分B的第个簇中数据的数量,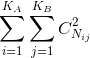 即为RI中的a(应该在一类(标准答案),最后也聚类到一类的数量);
即为RI中的a(应该在一类(标准答案),最后也聚类到一类的数量);
![]() 表示如果聚类是完全对的(聚类结果与“标准答案”完全一致),那么就应该是这个数目,所以在表达式里面叫做max index。
表示如果聚类是完全对的(聚类结果与“标准答案”完全一致),那么就应该是这个数目,所以在表达式里面叫做max index。
![]() 是a的期望,也就是
是a的期望,也就是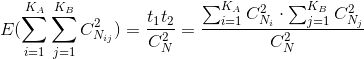 ,该公式可以这样理解:如下图所示,假设配对矩阵是这样的,显然,我们共有n(n-1)/2个配对方法。我们在行方向计算出可能取到的配对数,在列方向计算可能取到的配对数,相乘以后,除以总的配对数。这就是a的期望了。
,该公式可以这样理解:如下图所示,假设配对矩阵是这样的,显然,我们共有n(n-1)/2个配对方法。我们在行方向计算出可能取到的配对数,在列方向计算可能取到的配对数,相乘以后,除以总的配对数。这就是a的期望了。
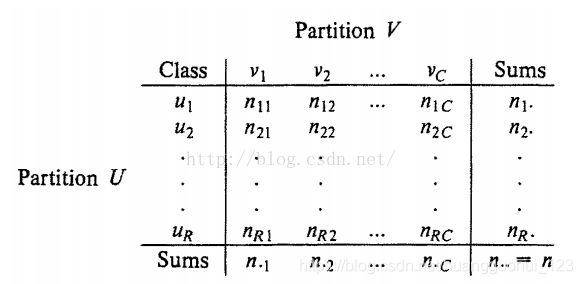
 从ARI的取值区间为[0,1],当ARI(A,B)=0:则划分A和B是独立的。当ARI(A,B)=1:则划分A和B是完全相同的。
从ARI的取值区间为[0,1],当ARI(A,B)=0:则划分A和B是独立的。当ARI(A,B)=1:则划分A和B是完全相同的。
4、K-均值聚类特点
优点:
- 是解决聚类问题的一种经典算法,简单、快速,复杂度低(复杂度为O(N))。
- 对处理大数据集,该算法保持可伸缩性和高效率。
- 当簇近似为高斯分布时,它的效果较好。
缺点:
- 在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用:如数据集存在分类变量,分类变量的平均值是没有意义的。
- 必须事先给出k(要生成的簇的数目),而且对初值(初始质心)敏感,对于不同的初始值,可能会导致不同结果。
- 不适合于发现非凸形状的簇或者大小差别很大的簇。
- 对躁声和孤立点数据敏感(故在聚类前我们一般要进行降维)。
建议:
- 可作为其他聚类方法的基础算法,如谱聚类。
- k值可以通过其他的算法来估计,如:BIC(Bayesian information criterion)、MDL(minimum description length)。
- 数据预处理对聚类效果是很重要的:如果数据集之间各个指标有一个比率的关系,而且比率关系比各指标的绝对值更重要的时候,用Normalizer(正则化)可以达到一个比较好的效果。详细可见《机器学习——数据的标准化(Z-Score,Maxmin,MaxAbs,RobustScaler,Normalizer)》中的Normalizer部分。
- 聚类前对数据集进行降维(PCA)有时也会提高聚类效果,尤其是存在噪声点的数据集,降维起到了一个降噪的目的。
5、超大数据量时应该放弃K均值算法
K均值在算法稳定性、效率和准确率(ARI)上表现非常好,并且在应对大量数据时依然如此。它的算法时间复杂度上界为O(n*k*t),其中n是样本量、k是划分的聚类数、t是迭代次数。当聚类数和迭代次数不变时,K均值的算法消耗时间只跟样本量有关,因此会呈线性增长趋势。
当真正面对海量数据时,使用K均值算法将面临严重的结果延迟,尤其是当K均值被用做实时性或准实时性的数据预处理、分析和建模时,这种瓶颈效应尤为明显。到底K均值的时间随着样本量的增加会如何变化?笔者利用Python生成一个具有3个分类类别的样本集,每个样本都是二维空间分布(2个维度),样本量从100增长到1000000,步长为1000,我们用折线图来看下计算时间与样本量的关系,结果如下图所示(这幅图耗时2小时)。
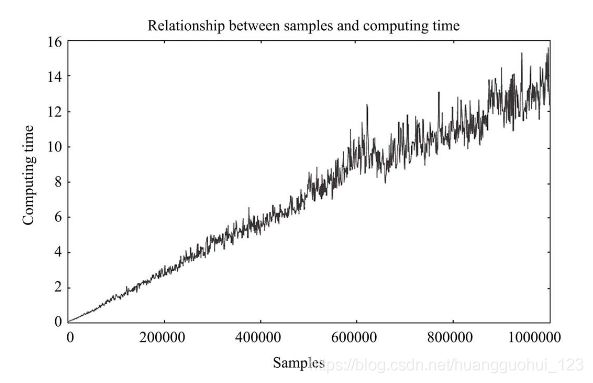
从上图结果中发现,计算时间跟数据量基本成线性关系。在样本点为二维空间的前提下,当数据量在200000以下时,计算时间基本都在2秒以内;当数据量在1000000时,耗时近16秒。由此可以试想,如果样本点有更多样本量或需要更多聚类类别,那么耗时将比上述场景长很多。
针对K均值的这一问题,很多延伸算法出现了,MiniBatchKMeans就是其中一个典型代表。MiniBatchKMeans使用了一个名为Mini Batch(分批处理)的方法计算数据点之间的距离。
MiniBatch的好处是计算过程中不必使用所有的数据样本,而是从不同类别的样本中抽取一部分样本(而非全部样本)作为代表参与聚类算法过程。由于计算样本量少,所以会相应减少运行时间;但另一方面,由于是抽样方法,抽样样本很难完全代表整体样本的全部特征,因此会带来准确度的下降。MiniBatchKMeans算法的准确度如何,请看下面的实验。在该实验中,我们对30000个样本点分别使用K-Means和MiniBatchKMeans进行聚类,然后对比两种方法得到结果的差异性,如下图所示。
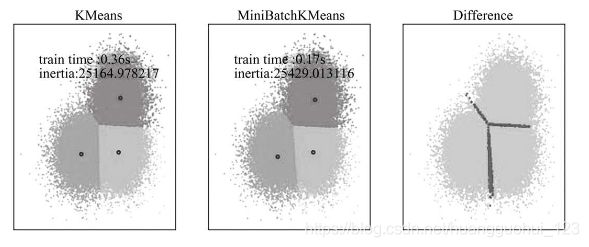
由上图结果发现:在30000样本点的基础上,二者的运行时间K-Mean是0.36秒、MiniBatchKMeans是0.17秒,计算时间的差距为2倍多(当然这在预期之内),但聚类结果差异性却很小(第三张图中深色的样本点则代表了差异分类样本)。我们看到,MiniBatchKMeans在基本保持了K-Means原有较高类别识别率的前提下,其计算效率的提升非常明显。因此,MiniBatchKMeans是一种能有效应对海量数据,尽量保持聚类准确性并且大幅度降低计算耗时的聚类算法。
6、高维数据应如何聚类?
传统的在低维空间通用的聚类方法运用到高维空间时,通常不能取得令人满意的聚类结果,主要表现在聚类计算耗时太长、聚类结果相对于真实标签分类的准确性和稳定性都大大降低。为什么在高维空间下聚类会出现这种问题?原因如下:
-
在面对高维数据时,基于距离的相似度计算效率极低;
-
高维空间的大量属性特征使得在所有维上存在簇的可能性非常低;
-
由于稀疏性以及近邻特性,基于距离的相似度几乎都为0,导致高维的空间中很难存在数据簇。
应对高维数据的聚类主要有2种方法:降维、子空间聚类。
降维是应对高维数据的有效办法,通过特征选择法或维度转换法将高维空间降低或映射到低维空间,直接解决了高维问题。有关降维的更多内容,可参考《多元统计分析——数据降维——因子分析(FA)》和《机器学习——数据降维——主成分分析(PCA)和奇异值分解(SVD)》。
子空间聚类算法是在高维数据空间中对传统聚类算法的一种扩展,其思想是选取与给定簇密切相关的维,然后在对应的子空间进行聚类。比如,谱聚类就是一种子空间聚类方法,由于选择相关维的方法以及评估子空间的方法需要自定义,因此这种方法实施起来对操作者的要求较高。
7、如何选择聚类分析算法
聚类算法有几十种之多,聚类算法的选择主要参考以下因素:
-
如果数据集是高维的,那么选择谱聚类,它是子空间划分的一种。
-
如果数据量为中小规模,例如在100万条以内,那么K均值将是比较好的选择;如果数据量超过100万条,那么可以考虑使用MiniBatchKMeans。
-
如果数据集中有噪点(离群点),那么使用基于密度的DBSCAN可以有效应对这个问题。
-
如果追求更高的分类准确度,那么选择谱聚类将比K均值准确度更好。
三、K-均值聚类python语言示例
例:考古学家对三个不同区域(Region)中五个不同窑炉(Kiln)出土的罗马世纪的陶器展开研究。区域1包括窑炉1号,区域2包括窑炉2号和3号,区域3包括窑炉4号和5号。数据集包含了45个陶器的9种化学成分。我们需要验证的是:是否不同出土地的陶器化学成分也不同?
解析:如果不同出土地的陶器化学成分不同,就可以利用以往的经验(同一个出土地的陶器化学成分一致)直接保存,不用再费力检测化学成分了。所以问题就变成了,对包含了45个陶器的9种化学成分进行聚类(聚成3类),看聚类的结果是否与区域(3个区域)对得上?
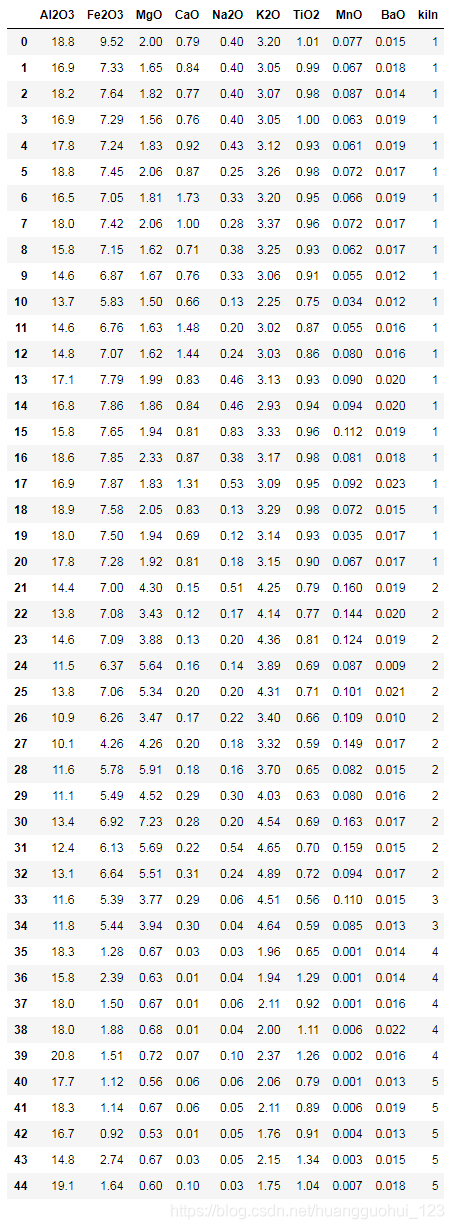
数据样本如下:
import pandas as pd
import numpy as np
data = pd.read_table("D:/CDA/dataset/pots.txt",sep=' ')
data输出:
1、计算距离矩阵
import scipy.cluster.hierarchy as sch
A=data.iloc[:,:9]
# A是一个向量矩阵:euclidean代表欧式距离
distA=sch.distance.pdist(A,metric='euclidean')
# squareform:将distA数组变成一个矩阵
distB = pd.DataFrame(sch.distance.squareform(distA.round(2)),columns=data.index,index=data.index)
distB输出:
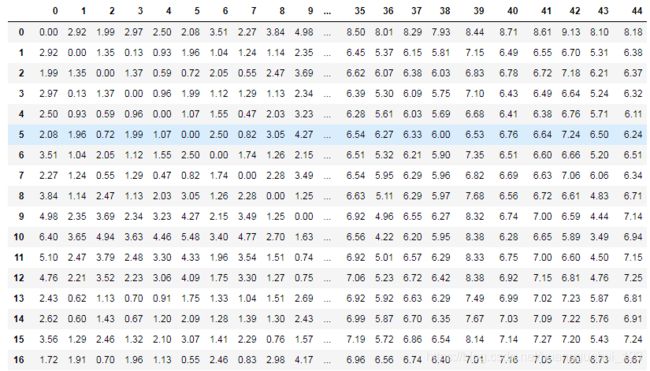
受篇幅的影响,仅展示部分数据样本的距离。
可通过热图展示距离矩阵的分布。
import seaborn as sns
import matplotlib.pyplot as plt
fig=plt.figure(figsize=(10,10)) #表示绘制图形的画板尺寸为6*4.5;
sns.heatmap(distB)输出: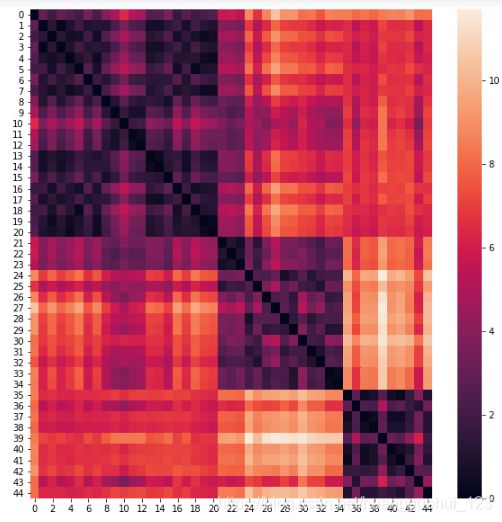
从图中,我们大致可以分成三类,有三个颜色较深的区域,颜色越深,距离约近,越相近。
2、K-Meas聚类
直接采用sklearn中的K-Means算法进行聚类。
2.1、k的选取——族群内方差(WGSS)
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
wgss=[]
for i in range(6):
cluster = KMeans(n_clusters=i+1, random_state=0).fit(A)
wgss.append(cluster.inertia_) #inertia_:每个点到其簇的质心的距离之和。即WGSS
#绘制WGSS的碎石图
plt.plot([i+1 for i in range(6)],wgss,marker='o')输出:
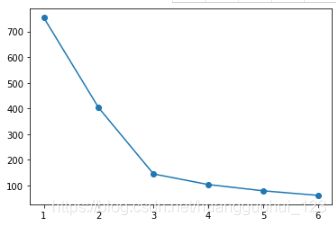
由距离矩阵和碎石图显示,聚成3类最合适。
注意:
KMeans(n_clusters=i+1, random_state=0).fit(A)中的random_state为0的目的是保证每次测试时的初始值(质心)一致,这样避免由于初始值(质心)不同导致的聚类结果差异。
在收到随机初始化的算法中,设置random_state的值在测试效果和优化时非常必要,这样可以避免信息干扰。假如不设置相同的随机种子,当两次运行时可能会使用不同的随机种子,这样会导致K-Means这类算法由于随机初始值(质心)的不同,聚类结果产生差异。
2.2、k的选取——轮廓系数(Silhouette)
from sklearn.metrics import silhouette_score #总的聚类效果轮廓系数
from sklearn.metrics import silhouette_samples #单个样本的轮廓系数
silhouette_scores=[]
for i in range(1,6):
cluster = KMeans(n_clusters=i+1, random_state=0).fit(A)
# 访问labels_属性,获得聚类结果
y_pred = cluster.labels_
# 计算平均轮廓系数
silhouette_avg = silhouette_score(A, y_pred)
silhouette_scores.append(silhouette_avg)
#绘制silhouette_scores的图形
plt.plot([i+1 for i in range(1,6)],silhouette_scores,marker='d')输出:
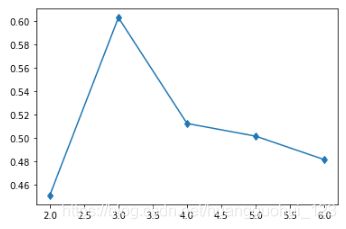
由轮廓系数的变化走势显示,聚成3类最合适,此时的轮廓系数最高。
2.3、聚类成3类
cluster = KMeans(n_clusters=3, random_state=0).fit(A)
cluster.cluster_centers_.round(2)输出:
array([[17.75, 1.61, 0.64, 0.04, 0.05, 2.02, 1.02, 0. , 0.02],
[16.92, 7.43, 1.84, 0.94, 0.35, 3.1 , 0.94, 0.07, 0.02],
[12.44, 6.21, 4.78, 0.21, 0.23, 4.19, 0.68, 0.12, 0.02]])以上是聚类成3类,各簇质心的坐标。
根据命题,区域1包括窑炉1号,区域2包括窑炉2号和3号,区域3包括窑炉4号和5号,我们将代表“区域”的标签和聚类结果的标签,填充进原数据集。如下
import numpy as np
#填充区域标签
bins=[0,1,3,5]
data['area']=pd.cut(data['kiln'],bins,labels=[1,2,3])
#填充聚类标签
data['cluser_label']=cluster.labels_ #labels_返回聚类结果列表
data输出:
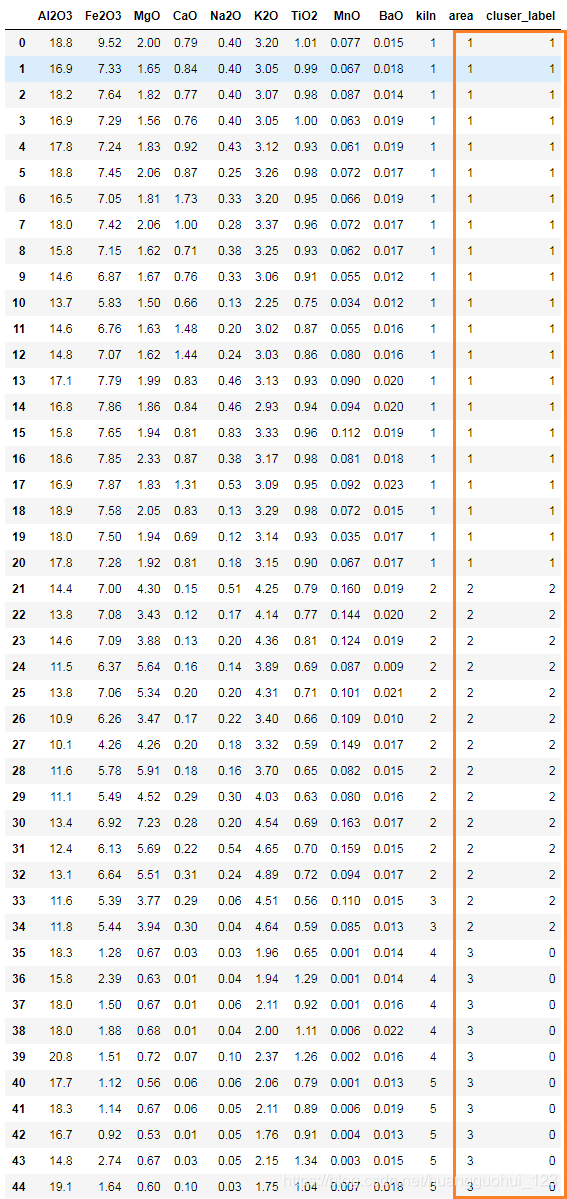
以上看出,聚类的结果和窑炉区域的分布完全一致。因此考古学家日后可直接根据出土地点判断陶器化学成分,从而制定保护方法,鉴定方法等。
聚类结果与窑炉区域的分布完全一致,所以我们可以进一步输出ARI(调整兰德系数)验证一下
from sklearn.metrics import adjusted_rand_score #调整兰德系数
print('ARI:%s'%(adjusted_rand_score(data['area'],data['cluser_label'])))输出:
ARI:1.0ARI=1,说明聚类结果与“标准答案”完全一致。
我们也可以绘制主成分散点图来评估聚类效果的好坏。
from sklearn.decomposition import PCA
pca = PCA(n_components = 0.95) #选择方差累积占比95%的主成分
A=data.iloc[:,0:9]
pca.fit(A) #主城分析时每一行是一个输入数据
result = pca.transform(A) #计算结果
fig=plt.figure(figsize=(10,6)) #表示绘制图形的画板尺寸为6*4.5;
plt.scatter(result[:, 0], result[:, 1], c=data['cluser_label'],edgecolor='k') #绘制两个主成分组成坐标的散点图
for i in range(result[:,0].size):
plt.text(result[i,0],result[i,1],data.index.values[i]) #在每个点边上绘制数据名称
x_label = 'PC1(%s%%)' % round((pca.explained_variance_ratio_[0]*100.0),2) #x轴标签字符串
y_label = 'PC1(%s%%)' % round((pca.explained_variance_ratio_[1]*100.0),2) #y轴标签字符串
plt.xlabel(x_label) #绘制x轴标签
plt.ylabel(y_label) #绘制y轴标签输出:

可以看出聚类效果是非常好的。