2021-02-23
寒假数据处理任务总结
任务描述
本次任务要处理的数据共101227行,样例如下:
18 Jogging 102271561469000 -13.53 16.89 -6.4
18 Jogging 102271641608000 -5.75 16.89 -0.46
18 Jogging 102271681617000 -2.18 16.32 11.07
18 Jogging 3.36
18 Downstairs 103260201636000 -4.44 7.06 1.95
18 Downstairs 103260241614000 -3.87 7.55 3.3
18 Downstairs 103260321693000 -4.06 8.08 4.79
18 Downstairs 103260365577000 -6.32 8.66 4.94
18 Downstairs 103260403083000 -5.37 11.22 3.06
18 Downstairs 103260443305000 -5.79 9.92 2.53
6 Walking 0 0 0 3.214402
Step 1
将数据集中所有信息异常的行删除。
比如上面的样例中第4行数据只有3个元素,而其他行都有6个元素,所以第4行是信息异常的行,将其删除。再如第12行数据的第3个元素明显也是有问题的,所以它也是信息异常的行,将其删除。
数据集中可能还会存在一些其他异常。
将全部信息处理之后,每行的元素以逗号为分隔符,写入文件test1。
文件test1共100471行,样例如下:
6,Walking,23445542281000,-0.72,9.62,0.14982383
6,Walking,23445592299000,-4.02,11.03,3.445948
6,Walking,23470662276000,0.95,14.71,3.636633
...
任务需求的分析
首先是要把txt文件转换成CSV文件,然后我们才能对它处理,由于本文的重点不在这,我就不赘述了,在这里我们假设已经转化好了。
对于要求抓住两个点,每行元素的个数和第三列是否为零
这是Python数据分析基础CSV文件筛选特定的行的操作
step1.py实现
import csv
import sys
input_file=sys.argv[1]
output_file=d=sys.argv[2]
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader=csv.reader(csv_in_file)
filewriter=csv.writer(csv_out_file)
for row_list in filereader:
length=len(row_list)
if length==6 and int(row_list[2])!=0:
filewriter.writerow(row_list)
step1.py注释
input_file=sys.argv[1]
output_file=d=sys.argv[2]
这两行代码使用sys模块的argv参数,它是一个传递给python脚本的命令行参数列表,也就是当你运行脚本时在命令行中输入的内容
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
这是一个with语句,将input_file打开为一个文件对象csv_in_file。'r'表示只读模式,说明打开文件时为了读取数据。'w'表示可写模式,打开它是为了写入数据,with语句很有用,因为它可以在语句结束时自动关闭文件对象。
filereader=csv.reader(csv_in_file)
filewriter=csv.writer(csv_out_file)
使用csv模块中的reader函数创建了一个文件读取对象filewriter,可以使用这个对象读取输入文件中的行。同理可理解第二行。需要注意一下,这两个函数的第二个参数delimiter='分隔符',delimiter=','是默认分隔符也就是说上边的代码和下面表示的一个意思
filereader=csv.reader(csv_in_file,delimiter=',')
filewriter=csv.writer(csv_out_file,delimiter=',')
它的意义就是:如果你的输入文件和输出文件都是用逗号分隔的,就不需要指定参数,在下面的步骤中也会有这方面的考点。
for row_list in filereader:
length=len(row_list)
if length==6 and int(row_list[2])!=0:
filewriter.writerow(row_list)
这是代码的核心部分,就是判断每行代码是否符合小编刚才说的那两个条件,如果符合就写入,不符合就不写入。
test1.csv

以记事本的方式打开
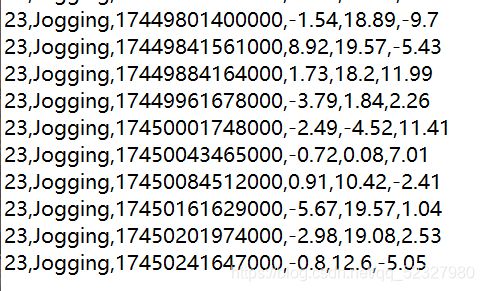
Step 2
统计文件test1的数据中所有动作的数目并打印到屏幕,然后将动作数目对100取整后写入test2文件,多余的信息行抛弃。比如统计出Jogging的数量为3021次,则在屏幕上打印Movement: Jogging Amount: 3021,然后将前3000行信息写入test2文件。
文件test2共100200行。
任务需求的分析
我们可以看一下,要对每个动作进行计数,一个动作对应一个出现的次数,看到这你想到了什么?是不是字典!!(话说对于小编这个新手还没有实际操作过字典,这是我的首次字典show,嘿嘿嘿)我们要做的就两步,一是统计一是筛选特定的行。我们直接看代码
step2.py实现
import csv
import sys
input_file=sys.argv[1]
output_file=sys.argv[2]
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
move_dir={
}
j_dir={
}
for row_list in filereader:
movement=str(row_list[1])
if(movement not in move_dir):
move_dir[movement]=1
else:
move_dir[movement]=move_dir[movement]+1
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
for row_list in filereader:
movement = str(row_list[1])
if (movement not in j_dir):
j_dir[movement] = 1
if(j_dir[movement]<=move_dir[movement]//100*100):
filewriter.writerow(row_list)
j_dir[movement]=j_dir[movement]+1
for key,value in move_dir.items():
print("Movement: {0} Amount: {1:d}".format(key,value))
step2.py注释
move_dir={
}
j_dir={
}
第一个是对所有动作统计的空字典,第二个是算是一个对动作次数的实时计数,因为上边的要求不是选取写入下一个文件嘛。
for row_list in filereader:
movement=str(row_list[1])
if(movement not in move_dir):
move_dir[movement]=1
else:
move_dir[movement]=move_dir[movement]+1
这几行代码可以也能说是核心代码,把动作的那一列取出,如果不在字典中,那就加入并把对应的变为1,如果在,就在相对应的动作次数下面+1。
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
这在我解释下为什么要两次用这块代码,因为本身统计数目就需要对文件进行一次遍历 ,统计后文件指针指向了文件末尾 ,再次对文件进行操作的话 就需要关闭文件重新打开 (当然也可以用其他方法,现代当初我就是因为这个点没注意到,test2.csv文件一直生成不出来)
for row_list in filereader:
movement = str(row_list[1])
if (movement not in j_dir):
j_dir[movement] = 1
if(j_dir[movement]<=move_dir[movement]//100*100):
filewriter.writerow(row_list)
j_dir[movement]=j_dir[movement]+1
这部分代码块,重新对文件遍历,在对动作数目对100取整后写入test2文件
test2.csv
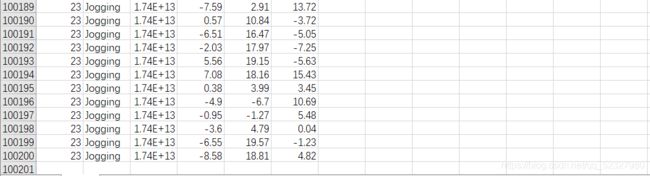
以记事本打开
Step 3
读取文件test2的数据,取每行的后3列元素,以空格为分隔符写入文件test3。
文件test3共100200行,样例如下:
-0.72 9.62 0.14982383
-4.02 11.03 3.445948
0.95 14.71 3.636633
...
任务需求的分析
这步就跟书上的代码差不多了,一个简单的选取特定的列。注意以空格符写入test3.csv文件。这步也是为第四步做铺垫。
step3.py实现
import csv
import sys
input_file=sys.argv[1]
output_file=sys.argv[2]
col=[3,4,5]
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader=csv.reader(csv_in_file)
filewriter=csv.writer(csv_out_file,delimiter=" ")
for row_list in filereader:
row_list_output=[]
for index_value in col:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)
step3.py注释
filewriter=csv.writer(csv_out_file,delimiter=" ")
我为什么把这行代码也注释,就是注意该步要求我们以空格写入下一个文件,所以带上第二个参数。
col=[3,4,5]
这是选取列的下标。
for row_list in filereader:
row_list_output=[]
for index_value in col:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)
这里面用创建了一个名为row_list_output的空列表,在col列表循环,把每行的4,5,6列加入row_list_output列表,然后写入下一个文件。
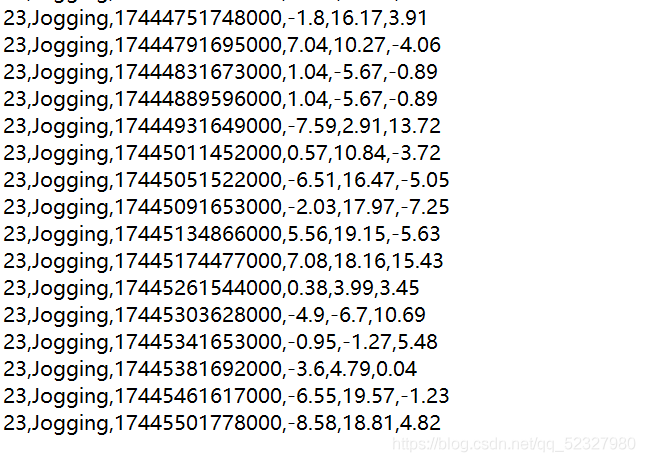
test3.csv

以记事本打开

Step 4
读取文件test3的数据,每行数据为一组,每组组内的元素以空格为分隔符,组与组之间的数据以逗号为分隔符,每20组元素为一行,写入文件finally。
文件finally共5010行,样例如下:
-0.72 9.62 0.14982383,-4.02 11.03 3.445948,0.95 14.71 3.636633,-3.57 5.75 -5.407278,-5.28 8.85 -9.615966,-1.14 15.02 -3.8681788,7.86 11.22 -1.879608,6.28 4.9 -2.3018389,0.95 7.06 -3.445948,-1.61 9.7 0.23154591,6.44 12.18 -0.7627395,5.83 12.07 -0.53119355,7.21 12.41 0.3405087,6.17 12.53 -6.701211,-1.08 17.54 -6.701211,-1.69 16.78 3.214402,-2.3 8.12 -3.486809,-2.91 0 -4.7535014,-2.91 0 -4.7535014,-4.44 1.84 -2.8330324
任务需求的分析
看似很简单,其实还是有坑的,就空格和逗号、字符串和列表就很讲究,一开始我写的时候,没注意,生成的文件还带着[],这一步的主要思想就是,把原来的一行变成大列表的一个,满20后,输出这个列表,但是首先你要把原来的一行列表转换成字符串,只有这样输出的结果才不会带[]。
step4.py实现
import csv
import sys
input_file=sys.argv[1]
output_file=sys.argv[2]
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
data=[]
output_data=[]
j=1
for row in filereader:
row_str=''.join(row)
data.append(row_str)
for data_value in data:
if(j<=20):
output_data.append(data_value)
j=j+1
if(j==21):
filewriter.writerow(output_data)
output_data=[]
j=1
step4.py注释
data=[]
output_data=[]
j=1
data代表所有的数据列表,output_data代表输出的每行数据,j就是一个计数器
for row in filereader:
row_str=''.join(row)
data.append(row_str)
对文件每行进行遍历,并把每行转化成字符串,存入data列表
for data_value in data:
if(j<=20):
output_data.append(data_value)
j=j+1
if(j==21):
filewriter.writerow(output_data)
output_data=[]
j=1
对data遍历,加入output_data列表,够20个元素,则写入下一个文件,并把output_data列表清空,j=1,然后接着计数。
test4.csv

以记事本打开

到这本期讲解就结束了,欢迎大家来交流。
本期参考书目《Python数据分析基础》