金融数据接口tushare爬取数据
import matplotlib.pyplot as plt
import seaborn as sns
import tushare as ts
from datetime import datetime
import csv
stock1 = ts.get_profit_statement('600498')
stock1.to_csv('利润表.csv',encoding='utf_8_sig')
filename='利润表.csv'
with open(filename,encoding='utf_8_sig') as f:
r=csv.DictReader(f)
d={}
for row in r:
if row['报表日期'] == '减:所得税费用':
d['第一季度'] = float(row['20170331'])
d['第二季度'] = float(row['20170630'])
d['第三季度'] = float(row['20170930'])
d['第四季度'] = float(row['20171231'])
#print(d)
sns.set_style("whitegrid")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
sns.barplot(x=list(d.keys()),y=list(d.values()))
plt.title('各季度所得税')
plt.xlabel('季度')
plt.ylabel('所得税')
plt.show()
break
#观测当前的股价
import tushare as ts
STOCK = ['600219', '000002', '000623', '000725', '600036', '601166', '600298', '600881', '002582', '600750',
'601088',
'000338',
'000895',
'000792']
quotes= ts.get_realtime_quotes(STOCK)
print(quotes)
quotes.to_csv('d:/bigdata/realtime_quotes.csv',encoding="utf_8_sig")
#保存并输出徐工机械[000425]股票2012年初到2017年末的后复权成交价数据,存为csv文件,再绘制折线图
import matplotlib.pyplot as plt #绘图
import seaborn as sns #基于matplotlib的数据可视化库
import tushare as ts #财经数据接口
from datetime import datetime #从datetime模块导入datetime函数
#首先用tushare获取成交价数据,复权类别是后复权,开始时间2012年1月1日,截止时间2017年12月31日
#get_k_data获取分时k线数据
stock = ts.get_k_data('000425', autype='hfq', ktype='M', start='2012-1-1', end='2017-12-31')
#存为csv文件:逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)
stock.to_csv('d:/23.csv')
#用seaborn绘制画板,加上白色网格
sns.set_style("whitegrid")
#在画板上加上线条和图例说明,图片比例为15:9
stock['open'].plot(legend=True, figsize=(15, 9))
stock['close'].plot(legend=True, figsize=(15, 9))
stock['high'].plot(legend=True, figsize=(15, 9))
stock['low'].plot(legend=True, figsize=(15, 9))
#输出K线数据
print(stock)
#展示画板
plt.show()
#绘制最近一年的数据乐视网[300104]股票每日涨跌幅核密度估计图
import matplotlib.pyplot as plt #绘图
import seaborn as sns #基于matplotlib的数据可视化库
import tushare as ts #财经数据接口
from datetime import datetime
end = datetime.today() #结束时间
start = datetime(end.year-1,end.month,end.day) #开始时间,选取最近一年的数据
#字符串化,datetime抓取时间是精确到秒,只保留年、月、日,YYYY-MM-DD,因此保留长度为10位
end = str(end)[0:10]
start = str(start)[0:10]
# get_hist_data函数,获取某只股票的历史交易数据,参数与get_k_data相同
stock = ts.get_hist_data('300104',start,end)
#计算每日涨跌幅度,pct_change()函数用来计算两个相邻数字之间的变化率
stock['Daily Return'] = stock['close'].pct_change()
# kdeplot函数绘制核密度估计图,dropna()方法删除缺失数据
sns.kdeplot(stock['Daily Return'].dropna())
#展示画板
plt.show()
GDP柱状图



import matplotlib.pylab as plt
GDP=[185691, 112182.8, 49386.411111111111111, 34666.3]
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.bar(range(4),GDP,align = 'center' ,color='steelblue', alpha = 0.8 )
plt.ylabel(u'GDP')
plt.title(u'四个直辖市大比拼')
plt.xticks(range(4),['北京市','上海市','天津市','重庆市'])
#添加刻度标签
plt.ylim([30000,550000])
#设置y轴刻度范围
for x,y in enumerate(GDP):
#可遍历的数据对象enumerate可以同时获得索引和值
plt.text(x,y+100
,'%s' %round(y,1) , ha='center')
#为每个条形图添加数值标签,就是柱形图上面的数字,y+100代表距离,%s表示格化式一个对象为字符,round(y,1)小数点后保留几位
plt.show()
'''rcParams:由于matplotlib对中文的支持并不是很友好,所以需要提前对绘图进行字体的设置,即通过rcParams来设置字体,这里将字体设置为微软雅黑,同时为了避免坐标轴不能正常的显示负号,也需要进行设置;
bar函数指定了条形图的x轴、y轴值,设置x轴刻度标签为水平居中,条形图的填充色color为铁蓝色,同时设置透明度alpha为0.8;
添加y轴标签、标题、x轴刻度标签值,为了让条形图显示各柱体之间的差异,将y轴范围设置在30000,550000
通过循环的方式,添加条形图的
此处 ha='right'点在注释右边(right,center,left),va='bottom'点在注释底部('top', 'bottom', 'center', 'baseline')
ha有三个选择:right,center,left
va有四个选择:'top', 'bottom', 'center', 'baseline'
Center的区别在于水平居中和垂直居中
水平柱状图
同一本书不同平台最低价比较
很多人在买一本书的时候,都比较喜欢货比三家,例如《python数据分析实战》在亚马逊、当当网、中国图书网、京东和天猫的最低价格分别为39.5、39.9、45.4、38.9、33.34。针对这个数据,我们也可以通过条形图来完成,这里使用水平条形图来显示:

import matplotlib.pylab as plt
price = [39.5, 39.9, 45.4, 38.9, 33.34]
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.barh(range(5),price,align='center',color='black',alpha=0.5)
#横柱状图 barh
plt.xlabel('price')
plt.yticks(range(5),['Amazon','Dangdang','BooksChina','Jingdong','Tianmao'])
#y轴刻度标签
plt.xlim([32,47])
plt.title('Book Price Comparsion')
for x,y in enumerate(price):plt.text(y+0.1,x,'%s' %y,va='center')
plt.show()
水平交错条形图
胡润财富榜:亿万资产超高净值家庭数
利用水平交错条形图对比2016年和2017年亿万资产超高净值家庭数
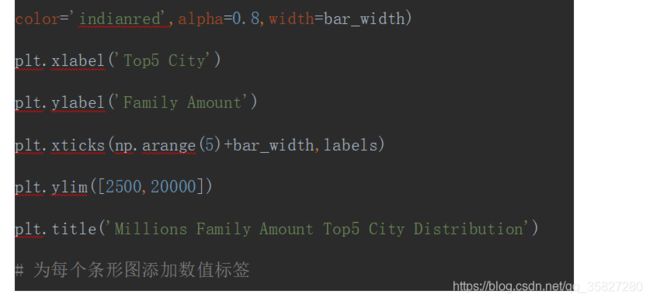

import matplotlib.pylab as plt
import numpy as np
Y2016 = [15600,12700,11300,4270,3620]
Y2017 = [17400,14800,12000,5200,4020]
labels = ['Beijing','Shanghai','Hongkong','Shenzhen','Guangzhou']
bar_width = 0.5
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.bar(np.arange(5),Y2016,label='2016',color='steelblue',alpha=0.8,width=bar_width)
plt.bar(np.arange(5) + bar_width, Y2017, label='2017', color='indianred',alpha=0.8,width=bar_width)
plt.xlabel('Top5 City')
plt.ylabel('Family Amount')
plt.xticks(np.arange(5)+bar_width,labels)
plt.ylim([2500,20000])
plt.title('Millions Family Amount Top5 City Distribution')
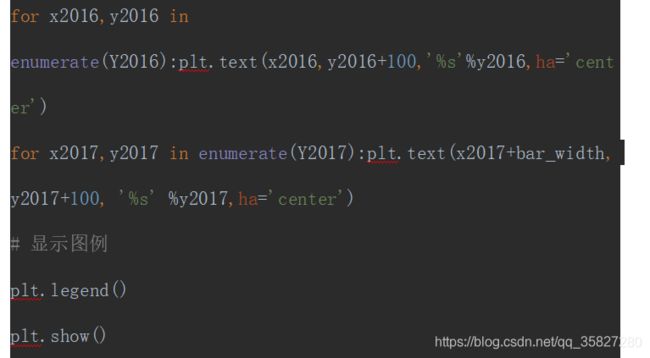
# 为每个条形图添加数值标签
for x2016,y2016 in enumerate(Y2016):plt.text(x2016,y2016+100,'%s'%y2016,ha='center')
for x2017,y2017 in enumerate(Y2017):plt.text(x2017+bar_width, y2017+100, '%s' %y2017,ha='center')
# 显示图例
plt.legend()
plt.show()
'''水平交错条形图绘制的思想很简单,就是在第一个条形图绘制好的基础上,往左移一定的距离,再去绘制第二个条形图,所以在代码中会出现两个bar函数;
图例的绘制需要在bar函数中添加label参数;color和alpha参数分别代表条形图的填充色和透明度;
给条形图添加数值标签,同样需要使用两次for循环的方式实现;'''
两者的区别仅仅是arange返回的是一个数据,而range返回的是list
饼图
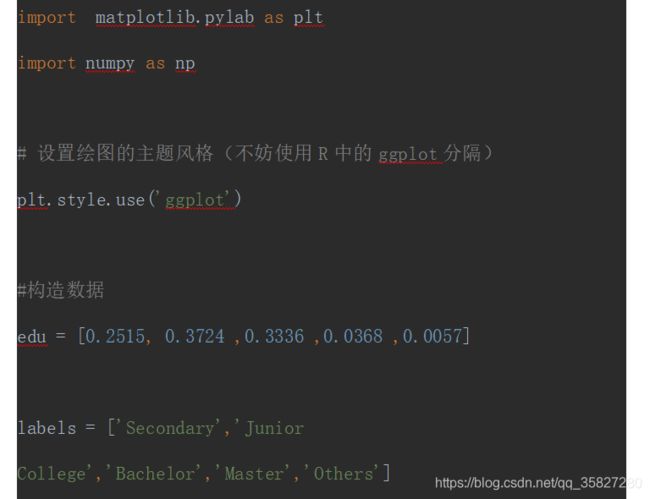
芝麻信用失信用户分析
我们使用芝麻信用近300万失信人群的样本统计数据来绘制饼图,该数据显示,从受教育水平上来看,中专占比25.15%,大专占比37.24%,本科占比33.36%,硕士占比3.68%,剩余的其他学历占比0.57%。对于这样一组数据,我们该如何使用饼图来呈现呢?
import matplotlib.pylab as plt
import numpy as np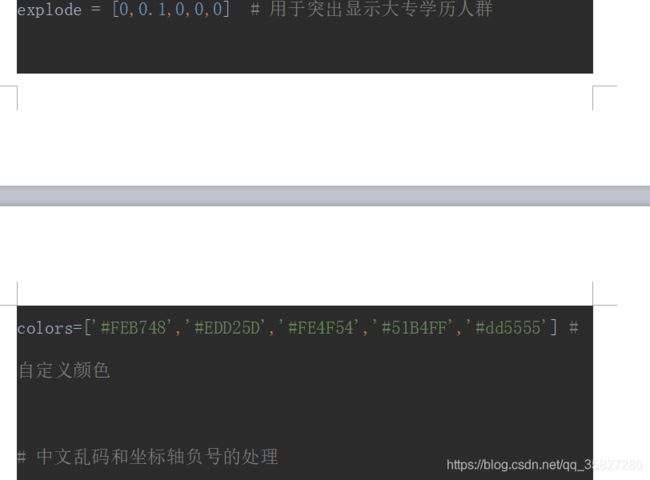


# 设置绘图的主题风格(不妨使用R中的ggplot分隔)
plt.style.use('ggplot')
#构造数据
edu = [0.2515, 0.3724 ,0.3336 ,0.0368 ,0.0057]
labels = ['Secondary','Junior College','Bachelor','Master','Others']
explode = [0,0.1,0,0,0] # 用于突出显示大专学历人群
colors=['#FEB748','#EDD25D','#FE4F54','#51B4FF','#dd5555'] # 自定义颜色
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 将横、纵坐标轴标准化处理,保证饼图是一个正圆,否则为椭圆
plt.axes(aspect='equal')
# 控制x轴和y轴的范围
plt.xlim(0,4)
plt.ylim(0,4)
# 绘制饼图
plt.pie(x = edu, # 绘图数据
explode=explode, # 突出显示大专人群
labels=labels, # 添加教育水平标签
colors=colors, # 设置饼图的自定义填充色
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
pctdistance=0.8,# 设置百分比标签与圆心的距离
labeldistance = 1.15, # 设置教育水平标签与圆心的距离
startangle = 180, # 设置饼图的初始角度
radius = 1.5, # 设置饼图的半径
counterclock = False, # 是否逆时针,这里设置为顺时针方向
wedgeprops = { 'linewidth': 1.5, 'edgecolor':'green'},# 设置饼图内外边界的属性值
textprops = { 'fontsize':12, 'color':'k'}, # 设置文本标签的属性值
center = (1.8,1.8), # 设置饼图的原点
frame = 1)# 是否显示饼图的图框,这里设置显示
# 删除x轴和y轴的刻度
plt.xticks(())
plt.yticks(())
# 添加图标题
plt.title('Zhima Credit Discredited User Analysis')
# 显示图形
plt.show()
箱线图
最简单的实例


import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
np.random.seed(2) #设置随机种子
df = pd.DataFrame(np.random.rand(5,4),
columns=['A', 'B', 'C', 'D'])
#先生成0-1之间的5*4维度数据,再装入4列DataFrame中
df.boxplot() #也可用plot.box()
plt.show()
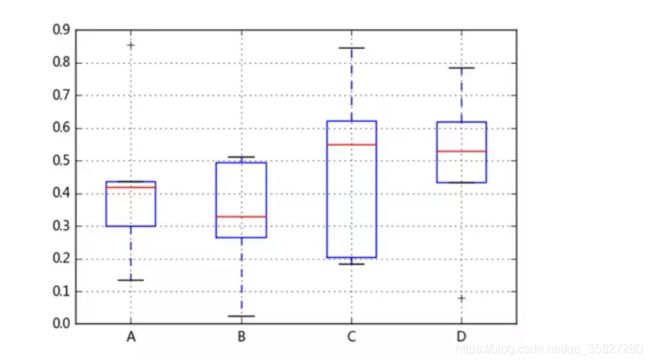
从图形可以看出,A、B、C、D四组数A、D数据较集中(大部分在上下四分位箱体内),但都有异常值,C的离散程度最大(最大值与最小值之间距离),以均值为中心,B分布都有明显右偏(即较多的值分布在均值的右侧),A、C则有明显左偏。
关于boxplot参数
- x:指定要绘制箱线图的数据;
- notch:是否是凹口的形式展现箱线图,默认非凹口;
- sym:指定异常点的形状,默认为+号显示;
- vert:是否需要将箱线图垂直摆放,默认垂直摆放;
- whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差;
- positions:指定箱线图的位置,默认为[0,1,2…];
- widths:指定箱线图的宽度,默认为0.5;
- patch_artist:是否填充箱体的颜色;
- meanline:是否用线的形式表示均值,默认用点来表示;
- showmeans:是否显示均值,默认不显示;
- showcaps:是否显示箱线图顶端和末端的两条线,默认显示;
- showbox:是否显示箱线图的箱体,默认显示;
- showfliers:是否显示异常值,默认显示;
- boxprops:设置箱体的属性,如边框色,填充色等;
- labels:为箱线图添加标签,类似于图例的作用;
- filerprops:设置异常值的属性,如异常点的形状、大小、填充色等;
- medianprops:设置中位数的属性,如线的类型、粗细等;
- meanprops:设置均值的属性,如点的大小、颜色等;
- capprops:设置箱线图顶端和末端线条的属性,如颜色、粗细等;
- whiskerprops:设置须的属性,如颜色、粗细、线的类型等;
- 整体乘客的年龄箱线图
# 导入第三方模块import pandas as pdimport matplotlib.pyplot as plt
# 读取Titanic数据集titanic = pd.read_csv('../input/pandas_exercise/exercise_data//train.csv')# 检查年龄是否有缺失any(titanic.Age.isnull())# 不妨删除含有缺失年龄的观察titanic.dropna(subset=['Age'], inplace=True)
# 设置图形的显示风格plt.style.use('ggplot')
# 设置中文和负号正常显示plt.rcParams['font.sans-serif'] = 'Microsoft YaHei'plt.rcParams['axes.unicode_minus'] = False
# 绘图:整体乘客的年龄箱线图plt.boxplot(x = titanic.Age, # 指定绘图数据
patch_artist=True, # 要求用自定义颜色填充盒形图,默认白色填充
showmeans=True, # 以点的形式显示均值
boxprops = { 'color':'black','facecolor':'#9999ff'}, # 设置箱体属性,填充色和边框色
flierprops = { 'marker':'o','markerfacecolor':'red','color':'black'}, # 设置异常值属性,点的形状、填充色和边框色
meanprops = { 'marker':'D','markerfacecolor':'indianred'}, # 设置均值点的属性,点的形状、填充色
medianprops = { 'linestyle':'--','color':'orange'}) # 设置中位数线的属性,线的类型和颜色# 设置y轴的范围plt.ylim(0,85)
# 去除箱线图的上边框与右边框的刻度标签plt.tick_params(top='off', right='off')# 显示图形plt.show()
- 不同等级仓的年龄箱线图
titanic.sort_values(by = 'Pclass', inplace=True)
# 通过for循环将不同仓位的年龄人群分别存储到列表Age变量中Age = []Levels = titanic.Pclass.unique()for Pclass in Levels:
Age.append(titanic.loc[titanic.Pclass==Pclass,'Age'])
# 绘图plt.boxplot(x = Age,
patch_artist=True,
labels = ['一等舱','二等舱','三等舱'], # 添加具体的标签名称
showmeans=True,
boxprops = { 'color':'black','facecolor':'#9999ff'},
flierprops = { 'marker':'o','markerfacecolor':'red','color':'black'},
meanprops = { 'marker':'D','markerfacecolor':'indianred'},
medianprops = { 'linestyle':'--','color':'orange'})
# 显示图形plt.show()
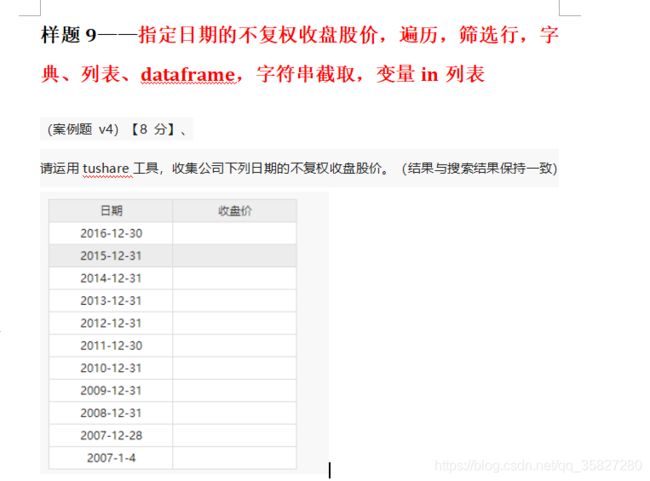
import matplotlib.pyplot as plt # 绘图
import seaborn as sns # 基于matplotlib的数据可视化库
import tushare as ts # 财经数据接口
import pandas as pd
import csv
from datetime import datetime
# 抓取2007到2016每个月的收盘数据并保存
stock = ts.get_hist_data('600177', '2007-01-01', '2016-12-30', ktype='M')
stock.to_csv('1.csv', encoding='utf_8_sig')
# 列表DATE用来设置需要提取的月份清单
DATE = ['2016-12-30', '2015-12-31', '2014-12-31', '2013-12-31',
'2012-12-31', '2011-12-30', '2010-12-31', '2009-12-31',
'2008-12-31', '2007-12-28', '2007-01-04']
filename = '1.csv'
with open(filename, encoding='utf_8_sig') as f:
r = csv.DictReader(f)
a = [] # 空列表,用来保存日期
b = [] # 空列表,用来保存收盘价
for row in r: # 遍历r
if row['date'] in DATE: # 如果某一行的date在列表DATE中,则保存其date和close值
a.append(row['date'])
b.append(row['close'])
c = {"date": a, "close": b} # 将列表a,b转换成字典
data = pd.DataFrame(c) # 将字典转换成为数据框
print(data)