爬虫实战:使用Selenium爬取京东宝贝信息
有些页面数据是采用Ajax获取的,但是这些Ajax接口参数比较复杂,可能会加入加密秘钥。对于这种页面,最方便的方法是通过selenium。可以用Selenium来模拟浏览器操作,抓取京东商品信息。
网页分析
今天用Selenium模拟浏览器来爬取信息。
输入框id为q
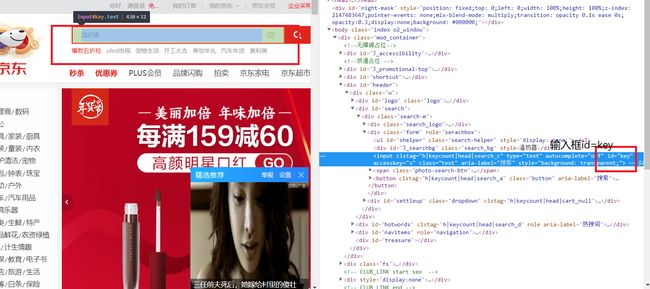
在Chrome浏览器中,选择搜索按钮,审查元素,找到搜索按钮所在位置,右键,选择copy,选择copy seletor 即可选择搜索按钮的css
本次选择结果为#search > div > div.form > button
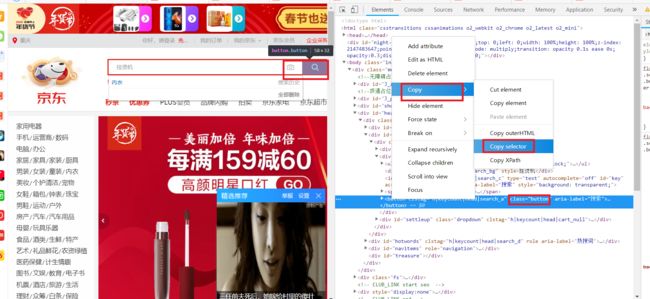
输入宝贝名字:如内衣
然后网页拉到页末
同理找到页末100页的css路径
#J_bottomPage > span.p-skip > em:nth-child(1) > b
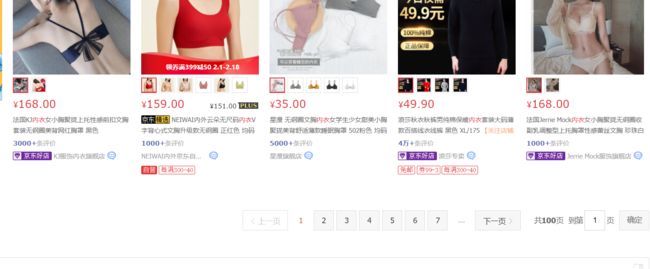
如图发现,每个商品都是一个Li标签。提取li标签css路径(ul包含所有商品)
css路径为#J_goodsList > ul > li

driver.find_elements_by_css_selector('#J_goodsList > ul > li')
得到的是 li:nth-child(1), li:nth-child(2)…
提取商品信息如提取名字,选择某一商品的名字得到的css路径为
#J_goodsList > ul > li:nth-child(1) > div > div.p-name.p-name-type-2 > a > em
我们应修改为div > div.p-name.p-name-type-2 > a > em
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu(余登武)
# @Date : 2021/2/18
#@email:[email protected]
from selenium import webdriver
import time
import csv
import re
def search_product(key):
driver.find_element_by_id('key').send_keys(key)
driver.find_element_by_css_selector('#search > div > div.form > button').click()
# 浏览器窗口最大化
driver.maximize_window()
time.sleep(3)
# 找到页数的标签
page = driver.find_element_by_css_selector('#J_bottomPage > span.p-skip > em:nth-child(1) > b').text
page = re.findall('(\d+)', page)[0]
return int(page)
def get_product():
lis = driver.find_elements_by_css_selector('#J_goodsList > ul > li')#
for li in lis:
# 商品名称
info = li.find_element_by_xpath('div/div[4]/a/em').text
# 商品价格
price = li.find_element_by_css_selector('div > div.p-price > strong > i').text + "元"
#评价数
evaluate=li.find_element_by_css_selector('div > div.p-commit > strong').text
# 店铺名称
name = li.find_element_by_css_selector('div > div.p-shop > span > a').text
#图片超链接
photo=li.find_element_by_css_selector('div > div.p-img > a > img').get_attribute('src')
print(info, price, evaluate,name,photo,sep='|')
with open('京东商品.csv', 'a', newline="") as fp:
csvwriter = csv.writer(fp, delimiter=',')
csvwriter.writerow([info, price, evaluate,name,photo])
def main():
print('正在爬取第一页数据')
page = search_product(keyword)
get_product()
page_num = 1
#
while page_num != page:
print('-*-' * 10)
print('正在爬取第{}页的数据'.format(page_num + 1))
print('*-*' * 10)
driver.get('https://search.jd.com/Search?keyword={}&wq={}&page={}&s=116&click=0'.format(keyword,keyword, page_num))
# 浏览器等待方法
driver.implicitly_wait(2)
# 最大化浏览器
driver.maximize_window()
get_product()
page_num += 1
if __name__ == '__main__':
keyword = input("请输入你要商品的关键字:")
path='D:\chromedriver_win32\chromedriver.exe'#驱动目录
driver = webdriver.Chrome(path)
driver.get('https://www.jd.com/?cu=true&utm_source=c.duomai.com&utm_medium=tuiguang&utm_campaign=t_16282_137005883&utm_term=5b4355c849464534ae6a958b61187471')
main()


换一种商品试试

我们可以抓取京东上的所有商品
![]()
![]()