文章持续更新,可以微信搜一搜「golang小白成长记」第一时间阅读,回复【教程】获golang免费视频教程。本文已经收录在GitHub https://github.com/xiaobaiTec... , 有大厂面试完整考点和成长路线,欢迎Star。

什么是HTTP
HTTP 全称超⽂文本传输协议,也就是HyperText Transfer Protocol。
其中我们常见的文本,图片,视频这些东西都可以用超文本进行表示,而我常看的猫片,也属于超文本,所以大家不要再说我偷偷看猫片了,我只是在看超文本。HTTP只是定义了一套传输超文本的规则,只要符合了这一套规则,不管你是用iphone,还是用老爷机,都可以实现猫片的传输。

七层网络

大概了解了HTTP后,给大家看看它在它们家族里的地位。HTTP位于应用层,跟它类似的协议还有常见的FTP协议,常见的某影天堂的下载链接曾经经常是以FTP开头的。

HTTP报文格式


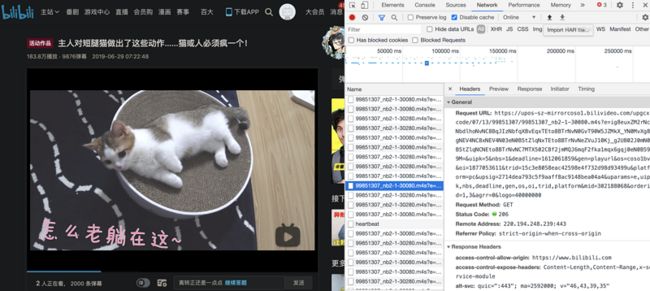
有点抽象?不知道小白说的啥?那实操一下,用wireshark抓包看一下猫片里的请求报文和响应报文具体长什么样子吧
请求报文
GET /cmaskboss/164203142_30_1.enhance.webmask HTTP/1.1
Host: upos-sz-staticks3.bilivideo.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36
Accept: */*
Origin: https://www.bilibili.com
Sec-Fetch-Site: cross-site
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://www.bilibili.com/
Accept-Encoding: identity
Accept-Language: zh-CN,zh;q=0.9
Range: bytes=0-16
这上面第一行的GET 就是请求方法,/cmaskboss/164203142_30_1.enhance.webmask 则是 URL , 而HTTP/1.1则是协议版本。接下来从Host开始到最后一行Range,都是Headers头。
响应报文
HTTP/1.1 206 Partial Content
Content-Type: application/octet-stream
Content-Length: 17
Connection: keep-alive
Server: Tengine
ETag: "92086de1e6d1d4791fb950a0ac7e30ba"
Date: Sat, 30 Jan 2021 09:31:31 GMT
Last-Modified: Sun, 04 Oct 2020 01:54:28 GMT
Expires: Mon, 01 Mar 2021 09:31:31 GMT
Age: 1018695
Content-Range: bytes 0-16/353225
Accept-Ranges: bytes
X-Application-Context: application
x-kss-request-id: 75bcbfa8ab194e3c825e89c81a912692
x-kss-BucketOwner: MjAwMDAyMDEwNw==
X-Info-StorageClass: -
Content-MD5: kght4ebR1HkfuVCgrH4wug==
X-Cache-Status: HIT from KS-CLOUD-JH-MP-01-03
X-Cache-Status: HIT from KS-CLOUD-TJ-UN-14-13
X-Cache-Status: HIT from KS-CLOUD-LF-UN-11-25
Access-Control-Allow-Origin: https://www.bilibili.com
Access-Control-Allow-Headers: Origin,X-Requested-With,Content-Type,Accept,range
X-Cdn-Request-ID: 7e2c783ca7d392624118593ec1dc66bc类似请求报文,HTTP/1.1是协议版本,206是状态码,Partial Content 则是状态描述符。接下来从Content-Type开始到最后一行X-Cdn-Request-ID都是Headers信息。
报文信息解读
其实上面的抓包信息,在浏览器里按F12就能看到,之所以要用wireshark可能只是装X效果比较好吧。按下F12看到的响应数据就跟下图展示的那样。

1.请求数据

2.响应数据

3.Request URL
URL是什么
URL 代表着是统一资源定位符(Uniform Resource Locator)。作用是为了告诉使用者 某个资源在 Web 上的地址。这个资源可以是一个 HTML 页面,一个 CSS 文档,一幅图像或一个猫片等等。上面我们请求猫片的URL就是 https://upos-sz-staticks3.bilivideo.com/cmaskboss/164203142_30_1.enhance.webmask 这里面细分,又可以分为好几个部分。
- 协议部分
表示该URL的协议部分为http还是https,会用//为分隔符。上面的URL表示网页用的是HTTPS协议,而上面提到的X影天堂用的则是ftp协议的下载链接。
- 域名部分
域名是upos-sz-staticks3.bilivideo.com,在发送请求前,会向DNS服务器解析IP,如果已经知道ip,还可以跳过DNS解析那一步,直接把IP当做域名部分使用。
- 端口部分
域名后面有些时候会带有端口,和域名之间用:分隔,端口不是一个URL的必须的部分。当网址为http://时,默认端口为80
当网址为https://时,默认端口为443,以上两种都可以省略端口号。上面的URL其实省略了443端口号。
- 虚拟目录
从域名的第一个/开始到最后一个/为止,是虚拟目录的部分。虚拟目录也不是URL必须的部分,本例中的虚拟目录是/cmaskboss/
- 文件名部分
从域名最后一个/开始到?为止,是文件名部分;如果没有?,则是从域名最后一个/开始到#为止,是文件名部分;如果没有?和#,那么就从域名的最后一个/从开始到结束,都是文件名部分。本例中的文件名是164203142_30_1.enhance.webmask,文件名也不是一个URL的必须部分。
URL 和 URI 的区别
- URL:Uniform Resource Locator 统一资源定位符;
- URI: Uniform Resource Identifier 统一资源标识符;
其实一直有个误解,很多人以为URI是URL的子集,其实应该反过来。URL是URI的子集才对。简单解释下。
假设"小白"(URI)是一种资源,而"在迪丽亦巴的怀里"表明了一个位置。如果你想要找到(locate)小白,那么你可以到"在迪丽亦巴怀里"找到小白,而"在迪丽亦巴怀里的/小白"才是我们常说的URL。而"在迪丽亦巴怀里的/小白"(URL)显然是"小白"(URI)的子集,毕竟,"小白"还可能是"在牛亦菲怀里的/小白"(其他URL)。
.jpg)
4.Request Method
HTTP 定义了一组请求方法,以表明要对给定资源执行的操作。指示针对给定资源要执行的期望动作.。虽然他们也可以是名词,但这些请求方法有时被称为HTTP动词.。每一个请求方法都实现了不同的语义。
这次请求B站猫片的请求里用的是GET,意味着获取。但其实HTTP定义了多种请求方法,来满足各种需求。除了Get,还有几个POST、HEAD、OPTIONS、PUT、DELETE、TRACE 和 CONNECT。

常见的各个请求方法的具体功能如下:
GET
请求指定的页面信息,并返回消息主体(body)+头信息(header)。
HEAD:
HEAD和GET本质是一样的,区别在于HEAD只返回头信息(header),不返回消息主体(body)。大家不要以为它没用,它跟GET和POST一样,在http/1.0的时候就存在了,实属三元老之一了。主要用途
- 如果想要判断某个资源是否存在,虽然用GET也能做到,但这里用HEAD还省下拿body的消耗,返回状态码200就是有404就是无
- 如果请求的是一个比较大的资源,比如一个超大视频和文件,你只想知道它到底有多大,而不需要整个下载下来,这时候使用HEAD请求,返回的headers会带有文件的大小(
content-lenght)。
POST
向服务器提交数据。这个方法用途广泛,几乎目前所有的提交操作都是靠这个完成。POST跟GET最常用,但最大的区别在于,POST每次调用都可能会修改数据,是非幂等的,而GET类似于只读,是幂等的。
PUT:
这个方法比较少见。在HTTP规范中POST是非等幂的,多次调用会产生不同的结果。比如:创建一个用户,由于网络原因或是其他原因多创建了几次,那么将会有多个用户被创建。而PUT id/xiaobai 则会创建一个id为 xiaobai 的用户,多次调用还是会创建的结果是一样的,所以PUT是等幂的。但是一般为了避免造成心智负担,实战中也会使用POST替代PUT。
DELETE:
删除某一个资源。基本上这个也很少见,一般实战中如果是删除操作,也是使用POST来替代。
OPTIONS:
options是什么
它用于获取当前URL所支持的方法。若请求成功,则它会在HTTP响应头部中带上给各种“Allow”的头,表明某个请求在对应的服务器中都支持哪种请求方法。比如下图:

这里面需要关注的点有两个
- Request Header里的关键字段
.jpg)
- Response Header里的关键字段
.jpg)
Options堪称是网络协议中的老实人,就好像老实人刚谈了个女朋友,每次牵手前都要问下人家 “我可以牵你的手吗?”, “我可以抱你吗?”,得到了答应后才会下手。差点被这老实人气质感动得留下了不争气的泪水。

什么时候需要使用options
在跨域(记住这个词,待会解释)的情况下,浏览器发起复杂请求前会自动发起 options 请求。跨域共享标准规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是 GET 以外的 HTTP 请求,或者搭配某些 MIME 类型的 POST 请求),浏览器必须首先使用 options 方法发起一个预检请求,从而获知服务端是否允许该跨域请求。服务器确认允许之后,才发起实际的 HTTP 请求。
这里提到了两个关键词:
- 跨域
- 复杂请求
什么是简单请求和复杂请求。
某些请求不会触发 CORS 预检请求,这样的请求一般称为"简单请求",而会触发预检的请求则为"复杂请求"。
简单请求
- 请求方法为
GET、HEAD、POST 只有以下
Headers字段AcceptAccept-LanguageContent-LanguageContent-TypeDPR/Downlink/Save-Data/Viewport-Width/Width(这些不常见,放在一起)
Content-Type只有以下三种application/x-www-form-urlencodedmultipart/form-datatext/plain
- 请求中的任意 XMLHttpRequestUpload 对象均没有注册任何事件监听器;
- 请求中没有使用 ReadableStream 对象。
- 请求方法为
复杂请求
- 不满足简单请求的,都是复杂请求
由此可见,因为上述请求在获取B站资源的请求Headers里带有 Access-Control-Request-Headers: range , 而range正好不在简单请求的条件2中提到的Headers范围里,因此属于复杂请求,于是触发预检options请求。
什么是跨域
刚刚提到了一个词叫跨域,那什么是跨域呢?在了解跨域之前,首先要了解一个概念:同源。所谓同源是指,域名、协议、端口均相同。
不明白没关系,举个例子。

需要特别注意的是,localhost和127.0.0.1虽然都指向本机,但也不属于同源。
而非同源之间网页调用就是我们所说的跨域。在浏览器同源策略限制下,向不同源发送XHR请求,浏览器认为该请求不受信任,禁止请求,具体表现为请求后不正常响应。
options带来什么问题
由此可见,复杂请求的条件其实非常容易满足,而一旦满足复杂请求的条件,则浏览器便会发送2次请求(一次预检options,一次复杂请求),这一次options就一来一回(一个RTT),显然会导致延迟和不必要的网络资源浪费,高并发情况下则可能为服务器带来严重的性能消耗。
.jpg)
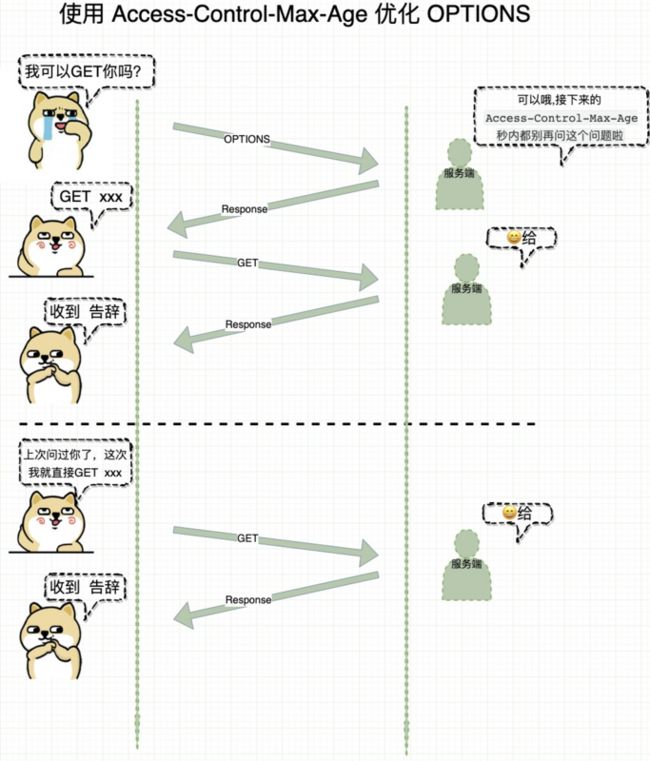
如何优化options
每次复杂请求前都会调用一次options,这其实非常没有必要。因为大部分时候相同的请求,短时间内获得的结果是不会变的,是否可以通过浏览器缓存省掉这一次查询?
Access-Control-Max-Age就是优化这个流程中使用的一个Header。它的作用是当你每次请求options方法时,服务端返回调用支持的方法(Access-Control-Allow-Methods )和Headers(Access-Control-Allow-Headers)有哪些,同时告诉你,它在接下来 Access-Control-Max-Age时间(单位是秒)里都支持,则这段时间内,不再需要使用options进行请求。特别注意的是,当Access-Control-Max-Age的值为-1时,表示禁用缓存,每一次请求都需要发送预检请求,即用OPTIONS请求进行检测。
5.Status Code
状态码是什么
HTTP Status Code则是常说的HTTP状态码。当用户访问一个网页时,浏览器会向网页所在服务器发出请求。服务器则会根据请求作出响应,而状态码则是响应的一部分,代表着本次请求的结果。所有状态码的第一个数字代表了响应的大概含义,组合上第二第三个数字则可以表示更具体的原因。如果请求失败了,通过这个状态码,大概初步判断出这次请求失败的原因。以下是五类状态码的含义。

状态码流程
可以根据以下流程图了解下各类状态码间的关系。

- 2xx和3xx之间的流程关系
.jpg)
- 4xx的状态流程

- 5xx的状态流程
.jpg)
常见状态码介绍
- 200 OK
这是最常见的状态码。代表请求已成功,数据也正常返回。而B站猫片里虽然响应成功了,但却不是200,而是206,是为什么呢,接下去继续看看。
- 206 Partial Content
这个状态码在上面B站请求的响应结果。服务器已经成功处理了部分 GET 请求。类似于B站看视频或者迅雷这类的 HTTP下载工具都是使用此类响应实现断点续传或者将一个大文档分解为多个下载段同时下载。
- 307 Temporary Redirect
内部重定向。重定向的意思是,当你输入一个网址的时候,浏览器会自动帮你跳转到另外一个网址上。比如,当你在浏览器输入框输入
http://www.baidu.com/时。由于使用http并不安全,百度会自动帮你跳转到它对应的https网页上。而此时,需要重定向的地址,会通过Response Headers的Location返回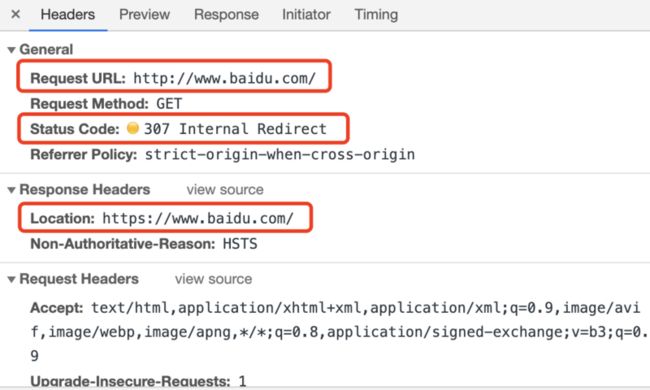
- 404 Not Found
请求失败,请求所希望得到的资源未被在服务器上发现。出现这个错误的最有可能的原因是服务器端没有这个页面,或者是Request Method与注册URL的Method不一致,比如我有一个URL在服务端注册的Request Method 为 POST,但调用的时候却错误用了GET,则也会出现404错误。
- 499 Client has closed connection
网络请求过程中,由于服务端处理时间过长,客户端超时。一般常见于,后端服务器处理时间过长,而客户端也设置了一个超时等待时间,客户端等得“不耐烦”了,主动关掉连接时报出。

- 502 Bad Gateway
服务器方面无法给于正常的响应。一般常见于服务器崩溃后,nginx 无法正常收到服务端的响应,给客户端返回502状态码。
.jpg)
- 504 Gateway Timeout
网络请求过程中,由于服务端处理时间过长,网关超时。一般常见于,后端服务器逻辑处理时间过长,甚至长于 nginx设置的最长等待时间时报错。它跟 499 状态码非常像,区别在于499 表示的是客户端超时,504是网关超时。如果是499超时,可以考虑修改客户端的代码调整超时时间,如果是504,则考虑调整nginx的超时配置。
.jpg)
6. Headers
Content-Length
Content-Length是HTTP的消息长度, 用十进制数字表示。Content-Length首部指出报文中消息的当前实际字节大小。如果消息文本进行了gzip压缩的话, Content-Length指的就是压缩后的大小而不是原始大小。
正常情况下Content-Length是不需要手动去设置的,大部分语言的网络库都会自动封装好,但是如果在一些特殊情况下,出现Content-Length与实际要发送的消息大小不一致,就会出现一些问题。
如果
Content-Length< 实际长度下面启动一个HTTP服务器,所有语言都一样,示例里使用了golang。
package main import ( "fmt" "io/ioutil" "log" "net/http" ) // w表示response对象,返回给客户端的内容都在对象里处理 // r表示客户端请求对象,包含了请求头,请求参数等等 func index(w http.ResponseWriter, r *http.Request) { b, _ := ioutil.ReadAll(r.Body) fmt.Printf("request body=%#v, content_length=%v \nheaders=%v",string(b), r.ContentLength, r.Header) // 往w里写入内容,就会在浏览器里输出 fmt.Fprintf(w, string(b)) } func main() { // 设置路由,如果访问/,则调用index方法 http.HandleFunc("/", index) // 启动web服务,监听9090端口 err := http.ListenAndServe(":9999", nil) if err != nil { log.Fatal("ListenAndServe: ", err) } }在控制台输入
$ $ curl -L -X POST 'http://127.0.0.1:9999' -H 'Content-Type: application/json' -H 'Content-Length: 5' -d '1234567' | jq % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 12 100 5 100 7 828 1160 --:--:-- --:--:-- --:--:-- 1400 12345输入的body是
1234567,共7个数字,但是输入的Content-Length为 5。到了服务器那,收到了12345,共5个数字,数量上跟输入的Content-Length一致。 由此可见当Content-Length< 实际长度, 消息会被截断。如果
Content-Length> 实际长度还是上面的服务端代码,但是控制台输入以下命令
$ curl -L -X POST 'http://127.0.0.1:9999' -H 'Content-Type: application/json' -H 'Content-Length: 100' -d '1234567' | jq % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 7 0 0 0 7 0 0 --:--:-- 0:01:19 --:--:-- 0这次情况不太一样,会发现请求一直阻塞没有返回。这是因为输入的body是
1234567,共7个数字,但是输入的Content-Length为 100。也就是服务端一直认为这次的body长度为100,但是目前只收到了部分消息(长度为7),剩余的长度为93的消息由于各种原因还在路上,因此选择傻傻等待剩下的消息,就造成了上面提到的阻塞。
Range

视频播放需要支持用户调整播放进度,支持让用户选择直接跳到中间部分开始播放。为了实现这个功能,需要通过HTTP Range Requests 协议用于指定需要获取视频片段。而 Request Header里的range头则是用于指定要请求文件的起始和结束位置。

- 如果服务器支持 Range Requests 协议,会读取视频文件,并将他的第 162653~242638 字节提取出来,并以状态码 206 响应请求。

- 如果服务器不支持,直接忽略 Range 头,读取整个文件内容,以状态码 200 响应即可。
当我们在 html 中放一个 video 标签,浏览器会直接发起一个
Range: bytes=0-的请求,向服务器请求从开始到结尾的完整文件- 如果服务器不支持 Range Requests,响应码为 200,浏览器会正常按流式加载整个视频文件;
- 如果服务器支持 Range Requests,响应码为 206,则浏览器会在接收到足够字节(比如当前播放进度往后推20s)时结束掉请求,以节省网络流量;当播放进度继续往前,缓存不够时,浏览器会发起一个新的 Range Requests 请求,请求的 Range 直接从缓存结尾的字节开始,只加载剩余的部分文件。
- 同时返回的Response Headers中有一个 content-range 的字段域,用于告诉了客户端发送了多少数据。content-range 描述了响应覆盖的范围和整个实体长度。一般格式:
Content-Range: 开始字节位置-结束字节位置/文件大小(byte)。
Connection
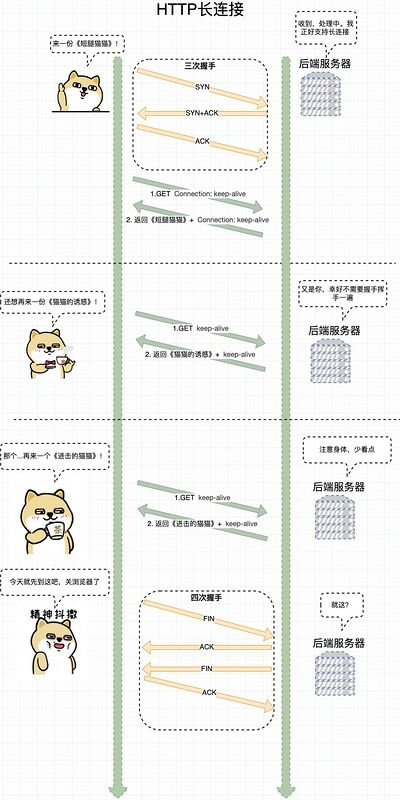
长连接和短连接
- Connection: close
表示请求响应完成之后立即关闭连接,这是HTTP/1.0请求的默认值。每次请求都经过“创建tcp连接 -> 请求资源 -> 响应资源 -> 释放连接”这样的过程
- Connection: keep-alive
表示连接不立即关闭,可以继续响应下一个请求。HTTP/1.1的请求默认使用一个持久连接。可以做到只建立一次连接,多次资源请求都复用该连接,完成后关闭。流程上是 建立tcp连接 -> 请求资源 -> 响应资源 -> ... (保持连接)... -> 第n次请求资源 -> 第n次响应资源 -> 释放连接。
在http1.1中Request Header和Reponse Header中都有可能出现一个Connection: keep-alive 头信息。Request Header里的Connection: keep-alive 头是为了告诉服务端,客户端想要以长连接形式进行通信。而Response Header里的Connection: keep-alive 头是服务端告诉客户端,我的服务器支持以长连接的方式进行通信。如果不能使用长连接,会返回 Connection: close ,相当于告诉客户端“我不支持长连接,你死了这条心,老老实实用短连接吧” 。
HTTP为什么要使用长连接
我们知道 HTTP 建立在 TCP 传输层协议之上,而 TCP 的建立需要三次握手,关闭需要四次挥手,这些步骤都需要时间,带给 HTTP 的就是请求响应时延。如果使用短连接,那么每次数据传输都需要经历一次上面提到的几个步骤,如果能只连接一次,保持住这个连接不断开,期间通信就可以省下建立连接和断开连接的过程,对于提升HTTP性能有很大的帮助。

- 可以看到,在使用 Connection: close 通信时,每次都需要重新经历一次握手挥手。可以通过 Connection: keep-alive 省下这部分的资源消耗。
- 长连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户来说,较适用长连接。但是在长连接的应用场景下,需要有一方主动关闭连接。如果客户端和服务端之间的连接一直不关闭的话,连接数则会越来越多,严重的时候会造成资源占用过高。
- 解决方案也比较简单。如果这些连接其实长时间内并没有任何数据传输的话,那其实属于空闲连接,这时候可以在服务端设置空闲连接的存活时间,超过一定时间后由服务端主动断掉,从而保证无用连接及时释放。
Cookies
Cookies是什么
- Cookie 是浏览器访问服务器后,服务器传给浏览器的一段数据。里面一般带有该浏览器的身份信息。
- 浏览器需要保存这段数据,不得轻易删除。
- 此后每次浏览器访问该服务器,都必须带上这段数据。服务器用使用这段数据确认浏览器身份信息。
Cookie的作用
Cookie 一般有两个作用。
识别用户身份。
- 举个例子。用户 A 用浏览器访问了“猫猫网”,“猫猫网”的服务器就会立刻给 A 返回一段Cookie数据,内含「uid=a」。
- 当 A 再次访问“猫猫网”下的其他页面时,比如跳转到“猫猫交友评论”,就会附带上「uid=a」这段数据。
- 同理,用户 B 用浏览器访问“猫猫网” 时,就给 B 分配了一段Cookie数据,内含「uid=b」。B 之后访问“猫猫网”的时候,就会一直带上「uid=b」这段数据。
- 因此“猫猫网”的服务器通过Cookie数据就能区分 A 和 B 两个用户了。
持久化用户信息。
- 因为cookies的数据会被用户浏览器保存到本地下。因此可以利用这一特点保持一些简单的用户数据。
- 比如一些博客网站,可以通过cookies记录下用户的性别年龄等信息,以此进行一些个性化展示。
- 当然上面提到的都是一些比较粗糙的场景,是为了方便大家理解cookies的功能。实际使用cookies会非常谨慎。
Referrer Policy 和 Referrer

Referrer是什么
Referrer 是HTTP请求header的报文头,用于指明当前流量的来源参考页面,常被用于分析用户来源等信息。通过这个信息,我们可以知道访客是怎么来到当前页面的。比如在上面的请求截图里,可以看出我是使用https://www.bilibili.com/访问的视频资源。
Referrer Policy 是什么
- Referrer 字段,会用来指定该请求是从哪个页面跳转页来的,里面的信息是浏览器填的。
- 而 Referrer Policy 则是用于控制Referrer信息传不传、传哪些信息、在什么时候传的策略。
为什么要这么麻烦呢?因为有些网站一些用户敏感信息,比如 sessionid 或是 token 放在地址栏里,如果当做Referrer字段全部传递的话,那第三方网站就会拿到这些信息,会有一定的安全隐患。所以就有了 Referrer Policy,用于过滤 Referrer 报头内容。
比如在上面的请求截图里,可以看出我是使用strict-origin-when-cross-origin策略,含义是跨域时将当前页面URL过滤掉参数及路径部分,仅将协议、域名和端口(如果有的话)当作 Referrer。否则 Referrer 还是传递当前页的全路径。同时当发生降级(比如从 https:// 跳转到 http:// )时,不传递 Referrer 报头。
Cache-control
什么是cache-control
cache-control,用于控制浏览器缓存。简而言之,当某人访问网站时,其浏览器将在本地保存某些资源,例如图像和网站数据。当该用户重新访问同一网站时,缓存控制设置的规则会确定该用户是否从本地缓存中加载这些资源,或者浏览器是否必须向服务器发送新资源的请求。
什么是浏览器缓存
浏览器缓存是指浏览器本地保存网站资源,以便不必再次通过网络从服务器获取它们。例如,“猫猫网”的背景图像可以保存到本地缓存中,这样在用户第二次访问该页面时,该图像将从用户的本地文件加载,剩下网络获取资源的时间,页面加载速度就会更快。
但是浏览器也不会永远把这些网站资源放在本地,否则本地磁盘就会炸,所以会限定保存资源的时间,这叫生存时间(TTL)。如果 TTL 过期后用户请求缓存的资源,浏览器必须再次通过网络与服务器建立连接并重新下载这个资源。
常见的缓存控制策略
- cache-control: private
具有“private”指令的响应只能由客户端缓存,不能由中间代理(例如 CDN或代理)缓存。这些资源通常是包含私密数据的资源,例如显示用户个人信息的网站。 - cache-control: public
相反,“public”指令表示资源可以由任何缓存存储。 - cache-control: no-store
带有“no-store”指令的响应无法缓存到任何位置,也永不缓存。也就是说,用户每次请求此数据时,都必须将请求发送到源站服务器以获取新副本。此指令通常保留给包含极其敏感数据的资源,例如银行帐户信息。 - cache-control: max-age
此指令指定了生存时间,也就是资源在下载后可以缓存多少秒钟。例如,如果将最大期限设置为 1800,则首次从服务器请求资源后的 1800 秒(30 分钟)内,后续请求都会向用户提供该资源的缓存版本。如果 30 分钟后用户再次请求资源,则客户端需要向服务器重新请求该资源。 - cache-control: no-cache
从B站截图里可以看出,使用的缓存控制指令是
cache-control: no-cache。它表示,只有先检查资源没有更新版本后,才可使用所请求资源的缓存版本。那么问题来了,怎么判断资源是否有更新版本呢?这就需要ETag。
ETag

Etag是 Entity tag的缩写,是服务端的一个资源版本的令牌标识。在 HTTP 响应头中将其传送到客户端。每当资源更新时,此令牌会源站服务器上更改。
- 比如,浏览器第一次请求资源的时候,服务端返回了这个资源的
ETag: "095933fff2323351d3b495f2f879616f1762f752"。 当浏览器再次请求这个资源的时候,浏览器会将
If-None-Match: "095933fff2323351d3b495f2f879616f1762f752"传输给服务端,服务端拿到该ETAG,对比资源是否发生变化。- 如果资源未发生改变,则返回304HTTP状态码,不返回具体的资源。
- 否则表示资源已经更新,浏览器需要下载新版本以提供给用户。
- 此过程可确保用户始终获得资源的最新版本,并且无需进行不必要的下载。
最后
果然B站是个充满学习氛围的地方,看个猫片都能学到这么多硬核知识。接下来我打算去舞蹈区看看有没有适合你们的知识点。

我是小白,有空?一起在知识的海洋里呛水啊,懂我意思?
参考资料
- [1] 计算机网络自动向下
- [2] 极客时间-趣谈网络协议
- [3] 极客时间-透视HTTP
- [4] 图解HTTP
- [5] 漫画形象-小肥柴