Kafka入门概述及原理介绍
文章目录
- 一、Kafka是什么
- 二、Kafka的特点
- 三、Kafka重要概念
-
- (一)Broker
- (二)Producer
- (三)Topic
- (四)Partition
- (五)Consumer Group
- (六)Message
- 四、三种消息投递模式
- 五、分布式原理
- 六、Demo
一、Kafka是什么
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统.
二、Kafka的特点
-
Kafka高吞吐量: Kafka的高吞吐量体现在读写上,分布式并发的读和写都非常快,写的性能体现在以o(1)的时间复杂度进行顺序写入。读的性能体现在以o(1)的时间复杂度进行顺序读
-
Kafka delivery guarantee(message传送保证):
(1)At most once消息可能会丢,绝对不会重复传输;
(2)At least once 消息绝对不会丢,但是可能会重复传输;
(3)Exactly once每条信息肯定会被传输一次且仅传输一次,这是用户想要的。 -
批量发送:Kafka支持以消息集合为单位进行批量发送,以提高push效率。
-
push-and-pull : Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
-
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
-
高并发:对topic进行partition分区,consume group中的consume线程可以以很高能性能进行顺序读。支持数千个客户端同时读写
三、Kafka重要概念
(一)Broker
1、定义:Kafka的服务器,用户存储消息,Kafka集群中的一台多台服务器统称为一个 broker。
2、副本:Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。Message消息是有多份的。
3、Broker Leader选举过程:
Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。(这个过程叫Controller在ZooKeeper注册Watch)。这个Controller会监听其他的Kafka Broker的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。
一旦有一个broker宕机了,这个kafka broker controller会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader(如果ISR列表中的replica全挂,选一个幸存的replica作为leader; 如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader),这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
(二)Producer
1、定义:Producer为kafka中消息发送者.
2、消息发送方式:
Kafka producer 发送message不用维护message的offsite信息,因为这个时候,offsite就相当于一个自增id,producer就尽管发送message就好了Topic
所以Kafka的producer一般都是大批量的batch发送message,向这个topic一次性发送一大批message,load balance到一个partition上,一起插进去,offsite作为自增id自己增加就好
采用Push的形式
3、Producer与Partition:
Producers直接发送消息到broker上的leader partition,不需要经过任何中介或其他路由转发。为了实现这个特性,kafka集群中的每个broker都可以响应producer的请求,并返回topic的一些元信息,这些元信息包括哪些机器是存活的,topic的leader partition都在哪,现阶段哪些leader partition是可以直接被访问的。
Producer客户端自己控制着消息被推送到哪些partition。实现的方式可以是随机分配、实现一类随机负载均衡算法,或者指定一些分区算法。Kafka提供了接口供用户实现自定义的partition,用户可以为每个消息指定一个partitionKey,通过这个key来实现一些hash分区算法。比如,把userid作为partitionkey的话,相同userid的消息将会被推送到同一个partition。
4、Batch定义:Kafka支持以集合(batch)为单位发送消息,在此基础上,Kafka还支持对消息集合进行压缩,Producer端可以通过GZIP或Snappy格式对消息集合进行压缩。Producer端进行压缩之后,在Consumer端需进行解压。压缩的好处就是减少传输的数据量,减轻对网络传输的压力,在对大数据处理上,瓶颈往往体现在网络上而不是CPU。
以Batch的方式推送数据可以极大的提高处理效率,kafka Producer 可以将消息在内存中累计到一定数量后作为一个batch发送请求。Batch的数量大小可以通过Producer的参数控制,参数值可以设置为累计的消息的数量(如500条)、累计的时间间隔(如100ms)或者累计的数据大小(64KB)。通过增加batch的大小,可以减少网络请求和磁盘IO的次数,当然具体参数设置需要在效率和时效性方面做一个权衡。
5、异步消息发送机制:
Producers可以异步的并行的向kafka发送消息,但是通常producer在发送完消息之后会得到一个future响应,返回的是offset值或者发送过程中遇到的错误。这其中有个非常重要的参数“acks”,这个参数决定了producer要求leader partition 收到确认的副本个数。
- 如果acks设置数量为0,表示producer不会等待broker的响应,所以,producer无法知道消息是否发送成功,这样有可能会导致数据丢失,但同时,acks值为0会得到最大的系统吞吐量。
- 若acks设置为1,表示producer会在leader partition收到消息时得到broker的一个确认,这样会有更好的可靠性,因为客户端会等待直到broker确认收到消息。
- 若设置为-1,producer会在所有备份的partition收到消息时得到broker的确认,这个设置可以得到最高的可靠性保证。
(三)Topic
1、定义:Topic相当于传统消息系统MQ中的一个队列queue,或者一类消息的有序集合
2、Topic中Partition的划分规则
假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中server.properties文件配置(参数log.dirs=xxx/message-folder),例如创建2个topic名 称分别为report_push、launch_info, partitions数量都为partitions=4
存储路径和目录规则为:
xxx/message-folder
|–report_push-0
|–report_push-1
|–report_push-2
|–report_push-3
|–launch_info-0
|–launch_info-1
|–launch_info-2
|–launch_info-3
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
消息发送时都被发送到一个topic,其本质就是一个目录,而topic由是由一些Partition组成,其组织结构如下图所示:
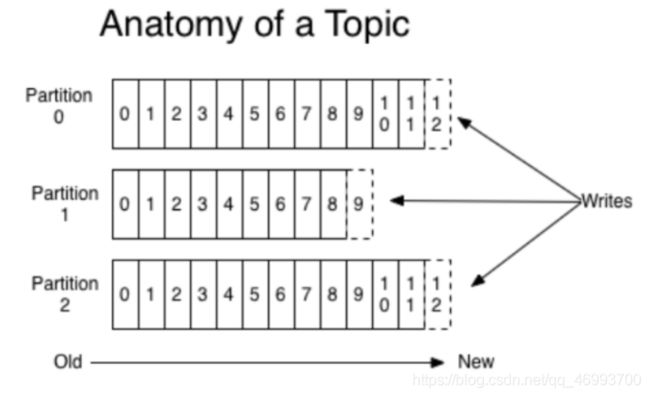

我们可以看到,Partition是一个Queue的结构,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition上,其中的每一个消息都被赋予了一个唯一的offset值。
(四)Partition
1、定义:Partition为Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列,Topic是个逻辑概念,而Partition是个物理概念
2、leader选取规则
-Partition leader与follower:partition也有leader和follower之分。leader是主partition,producer写kafka的时候先写partition leader,再由partition leader push给其他的partition follower。partition leader与follower的信息受Zookeeper控制,一旦partition leader所在的broker节点宕机,zookeeper会冲其他的broker的partition follower上选择follower变为parition leader。
3、副本机制
Kafka允许topic的分区拥有若干副本,这个数量是可以配置的,你可以为每个topic配置副本的数量。Kafka会自动在每个副本上备份数据,所以当一个节点down掉时数据依然是可用的。
Kafka的副本功能不是必须的,你可以配置只有一个副本,这样其实就相当于只有一份数据。
创建副本的单位是topic的分区,每个分区都有一个leader和零或多个followers.所有的读写操作都由leader处理,一般分区的数量都比broker的数量多的多,各分区的leader均匀的分布在brokers中。所有的followers都复制leader的日志,日志中的消息和顺序都和leader中的一致。followers向普通的consumer那样从leader那里拉取消息并保存在自己的日志文件中。
许多分布式的消息系统自动的处理失败的请求,它们对一个节点是否着(alive)”有着清晰的定义。Kafka判断一个节点是否活着有两个条件:
- 节点必须可以维护和ZooKeeper的连接,Zookeeper通过心跳机制检查每个节点的连接。
- 如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久。
符合以上条件的节点准确的说应该是“同步中的(in sync)”,而不是模糊的说是“活着的”或是“失败的”。Leader会追踪所有“同步中”的节点,一旦一个down掉了,或是卡住了,或是延时太久,leader就会把它移除。至于延时多久算是“太久”,是由参数replica.lag.max.messages决定的,怎样算是卡住了,怎是由参数replica.lag.time.max.ms决定的。
只有当消息被所有的副本加入到日志中时,才算是“committed”,只有committed的消息才会发送给consumer,这样就不用担心一旦leader down掉了消息会丢失。Producer也可以选择是否等待消息被提交的通知,这个是由参数acks决定的。
4、分区策略
Partition与其副本分到broker上策略
(1)将Broker(size=n)和待分配的Partition排序。(2)将第i个Partition分配到第(i%n)个Broker上。(3)将第i个Partition的第j个Replica分配到第((i + j) % n)个Broker上
Message分到partition上策略
(1)指定了 patition,则直接使用;
(2)未指定 patition 给定数据的key值,通过key取hashCode除余进行分区
(3)patition 和 key 都未指定,使用轮询选出一个 patition。
(4)自定义分区
5、分区文件
每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
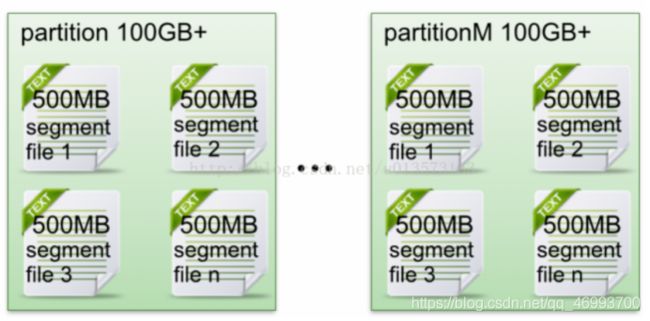
producer发message到某个topic,message会被均匀的分布到多个partition上(随机或根据用户指定的回调函数进行分布),kafka broker收到message往对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息consumer才能消费,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。

每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
- segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件.
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个全局partion的最大offset(偏移message数)。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
例如读取offset=368776的message,需要通过下面2个步骤查找。
第一步查找segment file
只要根据offset 二分查找文件列表,就可以快速定位到具体索引文件。
当offset=368776时定位到00000000000000368769.index|log
第二步通过segment file查找message通过第一步定位到segment file,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和 00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到 offset=368776为止。
(五)Consumer Group
1、定义:各个consumer(consumer 线程)可以组成一个组(Consumer group),partition中的每个message只能被组(Consumer group)中的一个consumer(consumer 线程)消费。所以如果想同时对一个topic做消费的话,启动多个consumer group就可以了,但是要注意的是,这里的多个consumer的消费都必须是顺序读取partition里面的message,新启动的consumer默认从partition队列最头端最新的地方开始的读message,所以会存在重复消费这批message的
2、消费机制:当启动一个consumer group去消费一个topic的时候,无论topic里面有多个少个partition,无论我们consumer group里面配置了多少个consumer thread,这个consumer group下面的所有consumer thread一定会消费全部的partition;即便这个consumer group下只有一个consumer thread,那么这个consumer thread也会去消费所有的partition。因此,最优的设计就是,consumer group下的consumer thread的数量等于partition数量,这样效率是最高的
3、offset存储机制:
(1)High level api:High level api是consumer读的partition的offset是存在zookeeper上。High level api 会启动另外一个线程去每隔一段时间,offset自动同步到zookeeper上。换句话说,如果使用了High level api, 每个message只能被读一次,一旦读了这条message之后,无论我consumer的处理是否ok。High level api的另外一个线程会自动的把offset+1同步到zookeeper上。如果consumer读取数据出了问题,offset也会在zookeeper上同步。因此,如果consumer处理失败了,会继续执行下一条。这往往是不对的行为。因此,Best Practice是一旦consumer处理失败,直接让整个conusmer group抛Exception终止,但是最后读的这一条数据是丢失了,因为在zookeeper里面的offset已经+1了。等再次启动conusmer group的时候,已经从下一条开始读取处理了。
(2)Low level api:Low level api是consumer读的partition的offset在consumer自己的程序中维护,不会同步到zookeeper上。但是为了kafka manager能够方便的监控,一般也会手动的同步到zookeeper上。这样的好处是一旦读取某个message的consumer失败了,这条message的offset我们自己维护,我们不会+1。下次再启动的时候,还会从这个offsite开始读。这样可以做到exactly once对于数据的准确性有保证。
4、Consumer Rebalance:同一组内消费者分配策略,确定某个消费者应该消费哪个partition
(1)Range Startegy(根据范围消费)
Range startegy是对每个主题而言的 , 首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母进行排序。在对十个分区排序的话是0-9;消费者线程排完序是C1-0,C2-0,C2-1。然后用partitions的总数除以消费者的总数来决定每个消费者线程消费几个分区。如果有余数,那么排在前列的几个消费者线程将会多消费一个分区
(2)RoundRobin strategy(轮询的消费策略)
将所有主题的分区组成TopicAndPartition列表,然后对TopicAndPartition列表按照hashcode进行排序,最后按照round-robin风格将分区分别分配给不同的消费者线程。
5、Consumer与Partition的关系:
- 如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的,所以consumer数不要大于partition数
- 如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀
- 如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有不同
- 增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化
(六)Message
1、定义:message为kafka中传递消息的格式类型

2、参数说明
| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte | message size message大小 |
| 4 byte | CRC32 用crc32校验message |
| 1 byte | “magic" 表示本次发布Kafka服务程序协议版本号 |
| 1 byte | “attributes" 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte | key length 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte | key 可选 |
| value bytes | payload 表示实际消息数据。 |
3、message状态:在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
4、message持久化:Kafka中会把消息持久化到本地文件系统中,并且保持o(1)极高的效率。我们众所周知IO读取是非常耗资源的性能也是最慢的。但是Kafka作为吞吐量极高的MQ,却可以非常高效的message持久化到文件。这是因为Kafka是顺序写入o(1)的时间复杂度,速度非常快。也是高吞吐量的原因。由于message的写入持久化是顺序写入的,因此message在被消费的时候也是按顺序被消费的,保证partition的message是顺序消费的。不需要寻址,速度非常快。
5、message有效期:Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
四、三种消息投递模式
Kafka提供3种消息传输一致性语义:最多1次,最少1次,恰好1次。
- at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中consumer进程失效(crash),导致部分消息未能继续处理.那么此后可能其他consumer会接管,但是因为offset已经提前保存,那么新的consumer将不能fetch到offset之前的消息(尽管它们尚没有被处理),这就是"at most once"。因此可能会出现数据丢失情况。
- at least once: 消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常或者consumer失效,导致保存offset操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",因此可能会重传数据,有可能出现数据被重复处理的情况;
- exactly once:"Kafka Cluster"到消费者的场景中可以采取以下方案来得到“恰好1次”的一致性语义:最少1次+消费者的输出中额外增加已处理消息最大编号:由于已处理消息最大编号的存在,不会出现重复处理消息的情况。
五、分布式原理
(一) Zookeeper 协调控制
- 管理broker与consumer的动态加入与离开。(Producer不需要管理,随便一台计算机都可以作为Producer向Kakfa Broker发消息)
- 触发负载均衡,当broker或consumer加入或离开时会触发负载均衡算法,使得一个consumer group内的多个consumer的消费负载平衡。(因为一个comsumer消费一个或多个partition,一个partition只能被一个consumer消费)
- 维护消费关系及每个partition的消费信息。
4、kafka使用zookeeper来存储一些meta信息,并使用了zookeeper watch机制来发现meta信息的变更并作出相应的动作(比如consumer失效,触发负载均衡等)
(二) Zookeeper上的细节:
- 每个broker启动后会在zookeeper上注册一个临时的broker registry,包含broker的ip地址和端口号,所存储的topics和partitions信息。
- 每个consumer启动后会在zookeeper上注册一个临时的consumer registry:包含consumer所属的consumer group以及订阅的topics。
- 每个consumer group关联一个临时的owner registry和一个持久的offset registry。对于被订阅的每个partition包含一个owner registry,内容为订阅这个partition的consumer id;同时包含一个offset registry,内容为上一次订阅的offset。
(三)总结:
-
Producer端使用zookeeper用来"发现"broker列表,以及和Topic下每个partition leader建立socket连接并发送消息.
-
Broker端使用zookeeper用来注册broker信息,已经监测partition leader存活性.
-
Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
六、Demo
(一)引入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.28</version>
</dependency>
(二)创建生产者类
package com.nan.test;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProducerFastStart {
public static final String BROKER_LIST = "120.78.203.252:9092";
public static final String TOPIC = "topic-demo";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_LIST);
//构建所需要发送的消息
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, "Hello Kafka!");
//配置生产者客户端参数并创建KafkaProducer示例
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
//发送消息
producer.send(record, (metadata, exception) -> {
if (exception != null) {
exception.printStackTrace();
} else {
System.out.println(metadata.topic() + "-" + metadata.partition() + ":" + metadata.offset());
}
});
}
}
}
(三)创建消费者类
package com.nan.test;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class KafkaConsumerAnalysis {
public static final String BROKER_LIST = "120.78.203.252:9092";
public static final String TOPIC = "topic-demo";
public static final String GROUP_ID = "group.demo";
public static final AtomicBoolean isRunning = new AtomicBoolean(true);
private static Properties initConfig() {
Properties props = new Properties();
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_LIST);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
props.put(ConsumerConfig.CLIENT_ID_CONFIG, "consumer.client.id.demo");
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(TOPIC));
try {
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000).toMillis());
for (ConsumerRecord<String, String> record : records) {
System.out.println("topic=" + record.topic() + ", partition=" + record.partition() + ", offset=" + record.offset());
System.out.println("key=" + record.key() + ", value=" + record.value());
}
}
} finally {
consumer.close();
}
}
}
参考:
[1]Kafka史上最详细原理总结
[2]Kafka教程(一)Kafka入门教程
[3]Kafka分区分配策略