数据分析与AI(三)cv2库简单入门/numpy关于矩阵变换,排序操作/pandas介绍/DataFrame介绍
cv2
cv库安装 pip install opencv-python
cv2.imread() 现在不能用, cv2官方指定使用matplotlib.pyplot.imread()
换脸实验
import numpy as np
# computer vision 计算视觉
import cv2
import matplotlib.pyplot as plt
# 1.导入图片
sanpang = cv2.imread('jinzhengen.png')
# plt=rgb cv2= bgr 要转换CV2打开图片的第三维色块顺序
plt.imshow(sanpang[:,:,::-1])
2. 导入一个要替换的脸
# 2. 导入一个要替换的脸
dog = cv2.imread('dog.jpg')
plt.imshow(dog[:,:,::-1])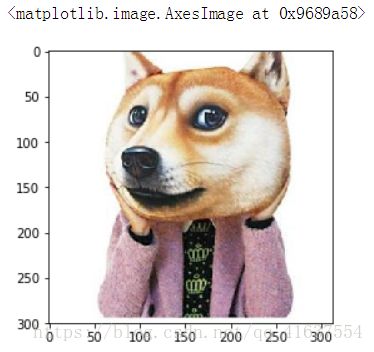
# 3. 识别到人脸的区域, 需要算法
# 算法已经提供好了
face_det = cv2.CascadeClassifier('../data/haarcascade_frontalface_default.xml')
#4. 我们需要用算法去找三半的脸
face_zone = face_det.detectMultiScale(sanpang)
face_zone
# 结果:
array([[182, 62, 61, 61]], dtype=int32)
------------------------------------------------
#5. 裁切狗脸
dog_face = dog[40:180,70:240]
dog_face.shape
# 结果:(140, 170, 3)
# 压缩狗脸
dog_face2 = cv2.resize(dog_face,(61,61))[:,:,::-1]
for x,y,w,h in face_zone:
sanpang[y:y+h, x:x+w] = dog_face2
plt.imshow(sanpang)
# 结果:
4.7数组循环
tile 与 repeat
import numpy as np
nd = np.arange(1,5).reshape([2,2])
nd
# 结果是:
array([[1, 2],
[3, 4]])
------------------------
# tile循环, 依赖的是行, 把每行中的数据循环N次
np.tile(nd, 3)
# 结果是:
array([[1, 2, 1, 2, 1, 2],
[3, 4, 3, 4, 3, 4]])
------------------------
#repeat循环会先降维, 在进行循环
np.repeat(nd, 3)
# 结果是:
array([1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4])五、ndarray的矩阵操作
1. 基本矩阵操作
1) 算术运算符:
- 加减乘除
nd1 = np.random.randint(0,10,size=(5,4))
nd1
# 结果是:
array([[6, 8, 3, 4],
[4, 5, 8, 4],
[7, 5, 7, 9],
[8, 9, 7, 9],
[1, 1, 7, 8]])
------------------------
# 矩阵 + 单个数值 等于 每个基本元素都加上该值
nd1 +3
# 结果是:
array([[ 9, 11, 6, 7],
[ 7, 8, 11, 7],
[10, 8, 10, 12],
[11, 12, 10, 12],
[ 4, 4, 10, 11]])np.add() 求和
不对原来的数组产生影响
# 在jupyter 中 如果某个函数对原数组产生影响的话, 不会再下面进行OUT输出
np.add(nd1, 10)
# 结果是:
array([[16, 18, 13, 14],
[14, 15, 18, 14],
[17, 15, 17, 19],
[18, 19, 17, 19],
[11, 11, 17, 18]])乘积 np.multiply() 乘积
不对原来的结果产生影响
np.multiply(nd1, 10)
# 结果是:
array([[60, 80, 30, 40],
[40, 50, 80, 40],
[70, 50, 70, 90],
[80, 90, 70, 90],
[10, 10, 70, 80]])矩阵的乘积 np.dot()
# 5行4列的可以和4行5列的进行乘积
nd2 = np.random.randint(0,10,size=(4,5))
nd2
# 结果是:
array([[4, 7, 3, 8, 6],
[5, 3, 9, 8, 9],
[6, 2, 4, 7, 7],
[4, 3, 5, 9, 5]])
--------------------------------------
np.dot(nd1, nd2)
# 结果是:
array([[ 98, 84, 122, 169, 149],
[105, 71, 109, 164, 145],
[131, 105, 139, 226, 181],
[155, 124, 178, 266, 223],
[ 83, 48, 80, 137, 104]])三维乘以一维
nd3 = np.random.randint(0,10,size=(5,4,3))
# 一维的size的值必须为第三维的值
nd4 = np.random.randint(0,10,size=(3))
# 发现乘积的结果降维了
np.dot(nd3,nd4)
# 结果是:
array([[23, 47, 23, 27],
[23, 28, 37, 32],
[36, 41, 17, 17],
[38, 32, 15, 27],
[21, 29, 47, 25]])三维乘以二维
nd4= np.random.randint(0,10,size=(3,1))
nd4
# 结果是:
array([[7],
[8],
[9]])
----------------------------
# 没有降维
np.dot(nd3, nd4)
# 结果是:
array([[[ 98],
[194],
[ 76],
[ 77]],
[[ 92],
[135],
[129],
[ 92]],
[[158],
[175],
[ 82],
[ 85]],
[[146],
[100],
[ 50],
[115]],
[[ 99],
[130],
[194],
[124]]])2. 广播机制
【重要】ndarray广播机制的两条规则
规则一:为缺失的维度补1
规则二:假定缺失元素用已有值填充
例1: m = np.ones((2, 3)) a = np.arange(3) 求M+a
nd1= np.ones((2,3))
nd1
# 结果是:
array([[1., 1., 1.],
[1., 1., 1.]])
------------------------
nd2 = np.arange(3)
nd2
# 结果是:
array([0, 1, 2])
------------------------
nd1 + nd2
# 结果是:
array([[1., 2., 3.],
[1., 2., 3.]])
-------------------------
np.add(nd1, nd2)
# 结果是:
array([[1., 2., 3.],
[1., 2., 3.]])六、ndarray的排序
小测验: 使用以上所学numpy的知识,对一个ndarray对象进行选择排序。
代码越短越好
nd = np.random.randint(0,150,size=(10))
nd
# 结果是:
array([117, 97, 128, 87, 145, 58, 70, 36, 44, 36])
-------------------------------------
# 方法1: 冒泡排序
for i in range(nd.size):
for j in range(nd.size - 1):
# 第一轮会将第一个和后面所有个进行对比, 找出最小值, 然后交换位置, 后面每一轮都会进行相同的排序
if nd[i] > nd[j]:
nd[i], nd[j] = nd[j], nd[i]
nd
# 结果是:
array([ 36, 36, 44, 58, 70, 87, 97, 117, 128, 145])
-------------------------------------
# 方法2: 利用argmin进行排序
# 用一层循环
# argmin, 把他封装成一个方法
def sort_nd(nd):
for i in range(nd.size):
# 不加上i索引会乱, i用来合成nd数组的真实索引位置
min_index = nd[i:].argmin() + i
nd[i], nd[min_index] = nd[min_index], nd[i]
sort_nd(nd1)
nd1
# 结果是:
array([ 7, 19, 29, 52, 89, 131, 134, 136, 138, 138])1. 快速排序
np.sort()与ndarray.sort()都可以,但有区别:
- np.sort()不改变输入
- ndarray.sort()本地处理,不占用空间,但改变输入
nd2=np.random.randint(0,10,size=10)
nd2
# 结果:
array([3, 3, 6, 5, 8, 2, 1, 0, 4, 2])
------------------------------
# 或者 np.sort(nd2)
nd2.sort()
# 这种排序方式对原数组产生影响了
nd2
# 结果:
array([0, 1, 2, 2, 3, 3, 4, 5, 6, 8])2. 部分排序
np.partition(a,k)
有的时候我们不是对全部数据感兴趣,我们可能只对最小或最大的一部分感兴趣。
- 当k为正时,我们想要得到最小的k个数
- 当k为负时,我们想要得到最大的k个数
nd3 = np.random.randint(0,10000,size=100)
nd3
# 结果:
array([1010, 3231, 6707, 2998, 2409, 3856, 7664, 6220, 7507, 9490, 1523,
4322, 9689, 1516, 8249, 7102, 9808, 6689, 8966, 2180, 8419, 4360,
2251, 6770, 7583, 518, 3052, 4912, 4328, 3270, 9965, 2714, 1528,
8084, 5791, 9371, 3548, 6305, 9805, 1509, 4956, 4210, 3148, 9618,
4906, 3999, 2057, 4000, 6475, 4105, 9938, 3588, 4628, 5167, 3384,
4410, 4659, 9976, 4147, 4914, 2120, 4655, 3470, 634, 295, 6656,
5256, 9772, 5920, 4559, 7300, 9351, 4085, 1215, 2556, 26, 8253,
4993, 9657, 6586, 8069, 9058, 1513, 2880, 8261, 6585, 905, 7381,
5758, 4941, 8055, 5485, 9447, 1548, 8496, 8585, 5649, 4934, 1774,
9765])
------------------------------------
np.partition(nd3, -5)[-5:] #(求最大的5个数)
# 结果是:
array([9805, 9808, 9965, 9976, 9938])
-------------------------------
np.sort(np.partition(nd3, 5)[:5]) #(求最小的5个数)
# 结果是:
array([ 26, 295, 518, 634, 905])pandas
# 数据分析有三剑客,三个模块
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
# 前两个属于数据分析,展示数据,画图,一图顶千言
import matplotlib.pyplot as plt
# 如果大家用的自己的ubuntu或者用的windows系统尽心数据分心,使用plt.imshow(显示图片,图片没有出来)
# 添加魔法指令
%matplotlib inline #将这个模块加载到当前代码中1、Series(主要用来创建一维数组)
Series是一种类似与一维数组的对象,由下面两个部分组成:
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
1)Series的创建
两种创建方式:
(1) 由列表或numpy数组创建
默认索引为0到N-1的整数型索引
nd = np.random.randint(0,15,size=10)
nd
# 结果:
array([ 6, 10, 3, 1, 10, 8, 0, 6, 13, 12])
-------------------------------
s = Series(nd)
s
# 结果:
0 6
1 10
2 3
3 1
4 10
5 8
6 0
7 6
8 13
9 12
dtype: int32
----------------------------------
# string 类型在Series中也会显示成object
l = list('qwertyuiop')
s = Series(l)
s
# 结果:
0 q
1 w
2 e
3 r
4 t
5 y
6 u
7 i
8 o
9 p
dtype: object通过设置index参数指定索引
#mysql中有两种索引, 语言中一般也有两种索引, 比如dict 枚举(数字) 关联索引('字符串')
# 列表不能做索引,元组可以做索引 对象可以做索引(一般不这样做)
l = [1,2,3,4,5,]
s = Series(l, index=list('abcde'))
s
# 结果:
a 1
b 2
c 3
d 4
e 5
dtype: int64name参数
# name比较类似于表名
# Series用于创建一维数据
s1 = Series(np.random.randint(0,150,size=8),index=list('abcdefgh'),name='python')
s2 = Series(np.random.randint(0,150,size=8),index=list('abcdefgh'),name='数学')
s3 = Series(np.random.randint(0,150,size=8),index=list('abcdefgh'),name='语文')
display(s1,s2,s3)
# 结果:
a 43
b 118
c 5
d 110
e 48
f 71
g 42
h 107
Name: python, dtype: int32
a 12
b 70
c 126
d 123
e 94
f 74
g 38
h 127
Name: 数学, dtype: int32
a 70
b 55
c 134
d 94
e 147
f 48
g 149
h 20
Name: 语文, dtype: int32特别地,由ndarray创建的是引用,而不是副本。对Series元素的改变也会改变原来的ndarray对象中的元素。(列表没有这种情况)
# copy属性
# Series是引用ndarray或list的
nd = np.ones((10))
# 默认是不创建副本
s = Series(nd, copy=True)
s
# 结果:
0 1.0
1 1.0
2 1.0
3 1.0
4 1.0
5 1.0
6 1.0
7 1.0
8 1.0
9 1.0
dtype: float64
------------------------------
s[0] = -1
nd
# 结果:
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])(2) 由字典创建
# 字典的方式在实际的应用中比较适合Series
# 我们在教学中, 为了方便会使用ndarray
s = Series({
'a':1,'b':2,'c':3})
s
# 结果:
a 1
b 2
c 3
dtype: int64============================================
练习1:
使用多种方法创建以下Series,命名为s1:
语文 150
数学 150
英语 150
理综 300
============================================
# 或者 s1 = Series(['150','150','150','300'], index=['语文','数学','英语','理综'], name='s1')
s1 = Series({
'语文':150,'数学':150,'英语':150,'理综':300}, name='s1')
s1
# 结果是:
语文 150
数学 150
英语 150
理综 300
Name: s1, dtype: object2)Series的索引和切片
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的仍然是一个Series类型)。分为显示索引和隐式索引:
============================================
练习2:
使用多种方法对练习1创建的Series s1进行索引和切片:
索引:
数学 150
切片:
语文 150
数学 150
英语 150
============================================
(1) 显式索引:
- 使用index中的元素作为索引值
- 使用.loc[](推荐)
可以理解为pandas是ndarray的升级版,但是Series也可是dict的升级版
注意,此时是闭区间
s1
# 结果:
a 43
b 118
c 5
d 110
e 48
f 71
g 42
h 107
Name: python, dtype: int32
-----------------------------
# 如果Series想同时获得两个及以上的值, 那么索引必须是一个list
s1[['a','b']]
# 结果:
# a 43
# b 118
Name: python, dtype: int32
------------------------------
s1.loc[['a','b']]
# 结果:
# a 43
# b 118
Name: python, dtype: int32(2) 隐式索引:
- 使用整数作为索引值
- 使用.iloc[](推荐)
注意,此时是半开区间
s2
# 结果:
a 12
b 70
c 126
d 123
e 94
f 74
g 38
h 127
Name: 数学, dtype: int32
---------------------------
s2[0]
# 结果: 86
s2.iloc[[0,1,2]]
# 结果:
# a 12
# b 70
# c 126
# Name: 数学, dtype: int32
切片
s2.iloc[0:1] # 或者s2[0:1] 或者s2['a':]
# 结果:
# a 12
# Name: 数学, dtype: int32显式切片
# 显示索引是闭区间
# 显示索引, 即使超出了范围也不会报错, 会显示到最大的索引
s2['a':'z']
# 结果
# a 12
# b 70
# c 126
# d 123
# e 94
# f 74
# g 38
# h 127
# Name: 数学, dtype: int32隐式切片
# 隐式索引是左闭右开
s2[1:3]
# 结果:
b 70
c 126
Name: 数学, dtype: int32
------------------------------------
l = [1,2,3,4,5]
s= Series(l, index=list('你我他她它'))
s
# 结果:
你 1
我 2
他 3
她 4
它 5
dtype: int64
----------------------------------
# 实际上, 这种无规律的关联索引是依赖枚举索引的
s['你':'他']
# 结果:
你 1
我 2
他 3
dtype: int643)Series的基本概念
可以把Series看成一个定长的有序字典
可以通过shape,size,index,values等得到series的属性
s1
# 结果:
a 43
b 118
c 5
d 110
e 48
f 71
g 42
h 107
Name: python, dtype: int32
---------------------------------
# Series的索引是一个特殊值, 不属于其他类型
# Series的值是一个ndarray的类型
display(s1.shape, s1.size, s1.index, s1.values, s1.ndim)
# 结果是:
(8,)
8
Index(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'], dtype='object')
array([ 43, 118, 5, 110, 48, 71, 42, 107])
1
------------------------------------
s1.index= list('abcdefgh')
s1
# 结果:
a 43
b 118
c 5
d 110
e 48
f 71
g 42
h 107
Name: python, dtype: int32
-----------------------------------------
# 在Series中最好使用dtypes, 不使用dtype(dtype可以用, 但是不规范)
s1.dtypes
# 结果:
dtype('int32')可以通过head(),tail()快速查看Series对象的样式
共同都有一个参数n,默认值为5
s1.head(n=3)
# 结果:
a 43
b 118
c 5
Name: python, dtype: int32
-----------------------------------
s1.tail()
# 结果:
d 110
e 48
f 71
g 42
h 107
Name: python, dtype: int32使用pandas读取CSV文件
# 读取文件, 使用的是pandas, 不是使用数据类型
h = pd.read_csv('../data/500_Cities__Local_Data_for_Better_Health.csv')
display(h.shape, type(h))
# 结果:
(810103, 24)
pandas.core.frame.DataFrame
--------------------------------
h.head(5)
# 结果: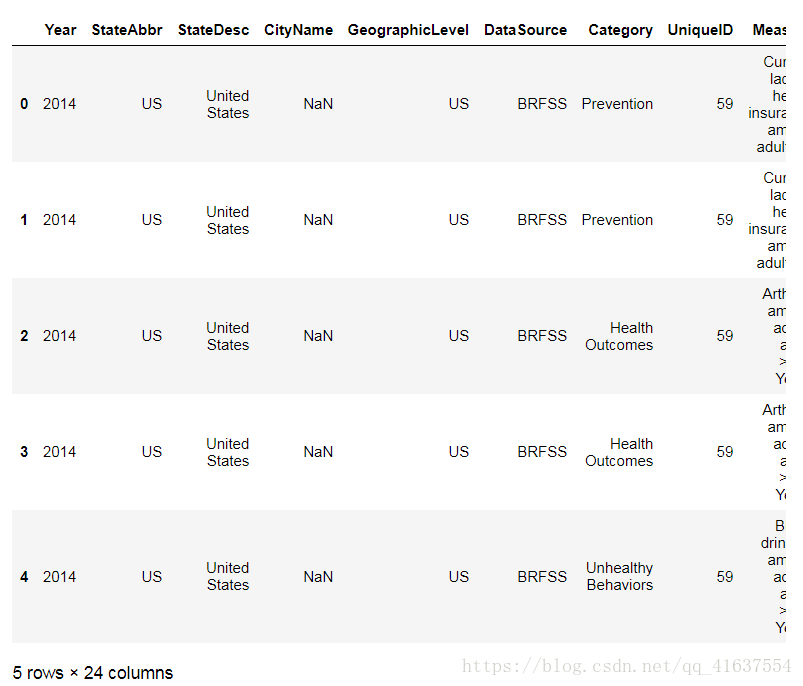
当索引没有对应的值时,可能出现缺失数据显示NaN(not a number)的情况
s6 = Series({
'a':1,'b':2,'c':np.e,'d':None,'e':np.NAN})
s6
# mysql中执行速度快慢 -> int -> float > object(string) -> Null
# mysql中Null的运行效率最低, 我们在开发中,对于一些不重要的字段可以给一个default 0, 用户可以不用输入一些值
# 在统计, 分组, (where/having) 查询的时候效率非常低
# select name,age from user where id =1
# select name,age from user having id= 1 因为having的条件id=1 不在结果集中, 所以这个查询语句是错误的
# null NaN
# NaN在数据计算的时候效率也非常低下, 但是NaN不可避免, 因为数据在导入的时候可能会加载不完全
# 但是NaN不影响计算
# 结果:
s6 = Series({
'a':1,'b':2,'c':np.e,'d':None,'e':np.NAN})
s6
# mysql中执行速度快慢 -> int -> float > object(string) -> Null
# mysql中Null的运行效率最低, 我们在开发中,对于一些不重要的字段可以给一个default 0, 用户可以不用输入一些值
# 在统计, 分组, (where/having) 查询的时候效率非常低
# select name,age from user where id =1
# select name,age from user having id= 1 因为having的条件id=1 不在结果集中, 所以这个查询语句是错误的
# null NaN
# NaN在数据计算的时候效率也非常低下, 但是NaN不可避免, 因为数据在导入的时候可能会加载不完全
# 但是NaN不影响计算
s6 = Series({
'a':1,'b':2,'c':np.e,'d':None,'e':np.NAN})
s6
# mysql中执行速度快慢 -> int -> float > object(string) -> Null
# mysql中Null的运行效率最低, 我们在开发中,对于一些不重要的字段可以给一个default 0, 用户可以不用输入一些值
# 在统计, 分组, (where/having) 查询的时候效率非常低
# select name,age from user where id =1
# select name,age from user having id= 1 因为having的条件id=1 不在结果集中, 所以这个查询语句是错误的
# null NaN
# NaN在数据计算的时候效率也非常低下, 但是NaN不可避免, 因为数据在导入的时候可能会加载不完全
# 但是NaN不影响计算
a 1.000000
b 2.000000
c 2.718282
d NaN
e NaN
dtype: float64可以使用pd.isnull(),pd.notnull(),或自带isnull(),notnull()函数检测缺失数据
cond = pd.isnull(s6)
cond
# 结果:
a False
b False
c False
d True
e True
dtype: bool
------------------------
s6[cond]
# 结果:
d NaN
e NaN
dtype: float64
--------------------------
cond = pd.notnull(s6)
cond
# 结果:
a True
b True
c True
d False
e False
dtype: bool
-----------------------------
s6[cond]
# 结果:
a 1.000000
b 2.000000
c 2.718282
dtype: float644)Series的运算
(1) 适用于numpy的数组运算也适用于Series
s2
# 结果:
a 12
b 70
c 126
d 123
e 94
f 74
g 38
h 127
Name: 数学, dtype: int32
# ----------------------------
c = s2 < 74
s2[c]
# 结果:
a 12
b 70
g 38
Name: 数学, dtype: int32(2) Series之间的运算
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
- 注意:要想保留所有的index,则需要使用.add()函数
s1 = Series(np.random.randint(0,100,size=8), index=list('qwertyui'))
s1
# 结果:
q 21
w 9
e 38
r 90
t 49
y 40
u 91
i 73
dtype: int32
# ------------------------------
s2 = Series(np.random.randint(0,100,size=8), index=list('ertyuiop'))
s2
# 结果:
e 86
r 24
t 60
y 13
u 47
i 66
o 15
p 59
dtype: int32
# --------------------------------
#'qwertyui' 'ertyuiop'
# 没有对应索引的相加都问NaN
s1 + s2
# 结果:
e 124.0
i 139.0
o NaN
p NaN
q NaN
r 114.0
t 109.0
u 138.0
w NaN
y 53.0
dtype: float64Series.add()
# 没有对应索引的值, 直接加上填充值(fill_value)0
s1.add(s2, fill_value=0)
# 结果:
e 124.0
i 139.0
o 15.0
p 59.0
q 21.0
r 114.0
t 109.0
u 138.0
w 9.0
y 53.0
dtype: float642、DataFrame
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(numpy的二维数组)
我们的训练集(一些二维的数据)都是二维的, 那么Series满足不了这个条件, xy轴上的一点(0,0)
# DataFrame就是excel表格
# 等于mysql中的table
# Series是一列
# DataFrame是多列
# DataFrame公用同一索引
1)DataFrame的创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
此外,DataFrame会自动加上每一行的索引(和Series一样)。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
# 这是一种比较现实的数据格式
df = DataFrame({
'数学':['100','90','80','70','60'],
'语文':['101','91','81','71','61'],
'python':['102','92','82','72','62']
},
index=list('abcde'),
columns=['数学','语文','python'])
# 或者:df1= DataFrame(np.random.randint(0,150,size=(5,3)), index=list('abcde'), columns=['数学','语文','python'])
df
# 结果: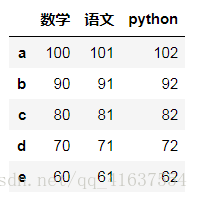
创建示范,给index(列)多增加一个, 注意这种方式不能给columns(行)增加元素
df = DataFrame({
'数学':['100','90','80','70','60'],
'语文':['101','91','81','71','61'],
'python':['102','92','82','72','62']
},
index=list(['雷军','罗胖子','JackMa','华腾','强东']),
columns=['数学','语文','python','Java'])
df
# 结果:
DataFrame属性:values、columns、index、shape、ndim、dtypes
# dataframe 是不可以使用dtype这个属性的, 只能使用dtypes
display(df.values, df.index, df.columns, df.shape,df.ndim, df.dtypes)
# 结果:
array([['100', '101', '102', nan],
['90', '91', '92', nan],
['80', '81', '82', nan],
['70', '71', '72', nan],
['60', '61', '62', nan]], dtype=object)
Index(['数学', '语文', 'python', 'Java'], dtype='object')
(5, 4)
2
数学 object
语文 object
python object
Java object
dtype: object============================================
练习4:
根据以下考试成绩表,创建一个DataFrame,命名为df:
张三 李四
语文 150 0
数学 150 0
英语 150 0
理综 300 0============================================
n = np.zeros((1,4), dtype=int)[0]
list(n)
# 结果:
[0, 0, 0, 0]
---------------------------
df = DataFrame({
'张三':[150,150,150,300],'李四':list(n)}
,
columns=['张三', '李四'], index=['语文','数学','英语','理综'])
df
# 结果:
2)DataFrame的索引
(1) 对列进行索引
- 通过类似字典的方式
- 通过属性的方式
可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。
df['python'] #Series
# 结果:
雷军 102
罗胖子 92
JackMa 82
华腾 72
强东 62
Name: python, dtype: object
------------------------------
# 查询两个课程的成绩
df[['python','语文']]
# 结果:
# 这种查找方法只能先找列, 再找行
df.python
# 结果:
雷军 102
罗胖子 92
JackMa 82
华腾 72
强东 62
Name: python, dtype: object(2) 对行进行索引
- 使用.loc[]加index来进行行索引
- 使用.iloc[]加整数来进行行索引
同样返回一个Series,index为原来的columns。
df.loc['华腾'] #Series
# 结果:
数学 70
语文 71
python 72
Java NaN
Name: 华腾, dtype: object
---------------------------------
# 多个值是DataFrame类型, 单个值是Series类型
df.loc[['雷军','JackMa'],['python','数学']]
# 结果: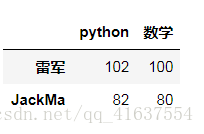
iloc用隐式索引进行检索
df.iloc[0,1]
# 结果: '101'
------------------
df.iloc[0:,2:]
# 结果: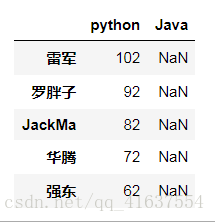
(3) 对元素索引的方法
- 使用列索引
- 使用行索引(iloc[3,1]相当于两个参数;iloc[[3,3]] 里面的[3,3]看做一个参数)
- 使用values属性(二维numpy数组)
# 这种方式会用的比较多, 结构比较清晰, 看个人喜好
df.iloc[0][1]
# 结果:
数学 100
语文 101
python 102
Java NaN
Name: 雷军, dtype: object【注意】
直接用中括号时:
- 索引表示的是列索引
- 切片表示的是行切片
3)DataFrame的运算
(1) DataFrame之间的运算
同Series一样:
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
df5 = DataFrame(np.random.randint(0,150,size=(5,4)),index=list('abcde'),columns=['数学','语文','python','Java'])
df6 = DataFrame(np.random.randint(0,150,size=(5,4)),index=list('abcde'),columns=['数学','语文','python','Java'])
display(df5,df6)
# 结果:
0 1
1 2
2 3
3 4
4 5
dtype: object
df6.add(df5,fill_value=0)
# 结果: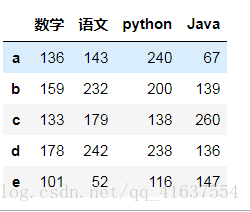
下面是Python 操作符与pandas操作函数的对应表:
| Python Operator | Pandas Method(s) |
|---|---|
+ |
add() |
- |
sub(), subtract() |
* |
mul(), multiply() |
/ |
truediv(), div(), divide() |
// |
floordiv() |
% |
mod() |
** |
pow() |
(2) Series与DataFrame之间的运算
【重要】
使用Python操作符:以行为单位操作(参数必须是行),对所有行都有效。(类似于numpy中二维数组与一维数组的运算,但可能出现NaN)
使用pandas操作函数:
axis=0:以列为单位操作(参数必须是列),对所有列都有效。 axis=1:以行为单位操作(参数必须是行),对所有行都有效。
列方向
df5
# 结果: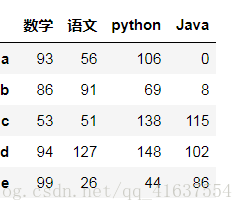
s = Series([1,2,3,4,5])
s
# 结果:
0 1
1 2
2 3
3 4
4 5
dtype: int64
# -------------------------------------
df5.add(s,axis=1)
# 结果:
行方向
df5.add(s, axis=0)
# 结果: