scrapy 教程 MySQL_scrapy框架使用教程
scrapy框架真的是很强大。非常值得学习一下。本身py就追求简洁,所以本身代码量很少却能写出很强大的功能。对比java来说。不过py的语法有些操蛋,比如没有智能提示。动态语言的通病。我也刚学习不到1周时间。记录一下。全部干货。
首先安装scrapy框架。选择的ide是pycharm。
创建一个scrapy项目。项目名称xxoo
scrapy startproject xxoo
会得到一个项目目录。具体目录的作用自己百度下。然后再用一条命令创建一个爬虫类。就是一个模板。帮我们创建好的类。我们只需要写逻辑就行。程序员的天性就是懒!!!
意思是创建了一个xxooSpider的类 这个类只爬取baidu.com这个网站
scrapy genspider [-t template] 即:scrapy genspider xxooSpider baidu.com
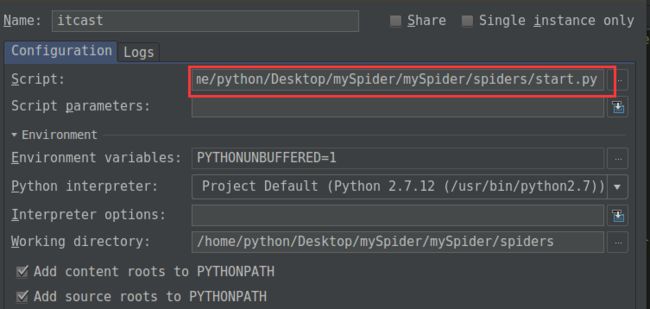
在pycharm中调试项目。
需要特殊配置下。
在根目录下创建一个start.py的文件。 -o itcast1.csv 是输出到csv文件中。可以不加
from scrapy importcmdline
cmdline.execute("scrapy crawl xxooSpider --nolog -o itcast1.csv".split())
就ok了。
使用豆瓣镜像源下载
pip install -i https://pypi.doubanio.com/simple/ scrapy-splash
获取setting.py中的值
from scrapy.conf importsettings
cookie= settings['COOKIE']
获取图片的url地址
大牛通常使用这个方法。原因是,我们一般情况下也可以直接得到src属性的值。但是,有时候src属性的值没有带网址前缀,比如说是/img/1.png这样。我们需要手动加上http://www.baidu.com才可以。用下面这个方法。可以很简单的解决这个问题。
from urllib importparse
url="http://www.baidu.com/xx"xx="/pic/1/1.png"urljoin=parse.urljoin(url, xx)print(urljoin)
http://www.baidu.com/pic/1/1.png
下载图片
scrapy给我们提供好了图片下载的模板。我们只需要在setting中指定一下管道中间件,和需要下载的字段。需要下载的字段值一定是数组类型,不然报错
ITEM_PIPELINES ={'xxoo.pipelines.XxooPipeline': 300,'scrapy.pipelines.images.ImagesPipeline': 1,
}#在item中定义图片url的字段,ImagesPipeline会自动下载这个url地址
IMAGES_URLS_FIELD="image"
#存放的路径,根目录下的img文件夹
IMAGES_STORE=os.path.join(os.path.abspath(os.path.dirname(__file__)),"img")
但是按照上面的写的话,全部都是由scrapy帮我们做了,自己生成文件夹,文件名。非常不可控。如果我们想自定义的话。我们需要继承ImagesPipeline类,重写几个方法
from scrapy.pipelines.images importImagesPipelineimportrefrom scrapy importRequestclassImagesrenamePipeline(ImagesPipeline):#1看源码可以知道,这个方法只是遍历出我们指定的图片字段,是个数组,然后一个一个请求
defget_media_requests(self, item, info):#循环每一张图片地址下载,若传过来的不是集合则无需循环直接yield
for image_url in item['imgurl']:#meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
yield Request(image_url,meta={'name':item['imgname']})#2重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None):#提取url前面名称作为图片名。
image_guid = request.url.split('/')[-1]#接收上面meta传递过来的图片名称
name = request.meta['name']#过滤windows字符串,不经过这么一个步骤,你会发现有乱码或无法下载
name = re.sub(r'[?\\*|“<>:/]', '', name)#分文件夹存储的关键:{0}对应着name;{1}对应着image_guid
filename = u'{0}/{1}'.format(name, image_guid)returnfilename#3这个是请求完成之后走的方法,我们可以得到请求的url和存放的地址
defitem_completed(self, results, item, info):pass
保存item到json文件
自定义的
importcodecsimportjsonclassjsonwrite(object):#初始化,打开文件
def __init__(self):
self.file= codecs.open("xxoo.json", "w",encoding="utf-8")#scrapy会走这个方法进行item的写入
defprocess_item(self,item,spider):
self.file.write(json.dumps(dict(item),ensure_ascii=False) + "\n")#通常是关闭文件的操作
defspider_closed(self,spider):
self.file.close()
scrapy给我们提供的
from scrapy.exporters importJsonItemExporterclassJsonExporterPipleline(object):#调用scrapy提供的json export导出json文件
def __init__(self):
self.file= open('articleexport.json', 'wb')
self.exporter= JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()defclose_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()defprocess_item(self, item, spider):
self.exporter.export_item(item)return item
保存到mysql中(两种方法)
importMySQLdbimportMySQLdb.cursorsfrom twisted.enterprise importadbapiclassMysqlPipeline(object):#采用同步的机制写入mysql
def __init__(self):
self.conn= MySQLdb.connect('192.168.0.106', 'root', 'root', 'article_spider', charset="utf8", use_unicode=True)
self.cursor=self.conn.cursor()defprocess_item(self, item, spider):
insert_sql= """insert into jobbole_article(title, url, create_date, fav_nums)
VALUES (%s, %s, %s, %s)"""self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"]))
self.conn.commit()
#采用异步数据库连接池的方法classMysqlTwistedPipline(object):def __init__(self, dbpool):
self.dbpool=dbpool
@classmethoddeffrom_settings(cls, settings):
dbparms=dict(
host= settings["MYSQL_HOST"],
db= settings["MYSQL_DBNAME"],
user= settings["MYSQL_USER"],
passwd= settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool= adbapi.ConnectionPool("MySQLdb", **dbparms)returncls(dbpool)defprocess_item(self, item, spider):#使用twisted将mysql插入变成异步执行
query =self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider)#处理异常
defhandle_error(self, failure, item, spider):#处理异步插入的异常
print(failure)defdo_insert(self, cursor, item):#执行具体的插入
#根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql, params =item.get_insert_sql()
cursor.execute(insert_sql, params)
优化item类(重要)
我们可以用xpath或者css解析页面,然后写一些判断逻辑。如果你不嫌麻烦的话。
scrapy给我们提供了一整套的流程。可以让代码变得非常精简。处理item的业务逻辑在item中写。爬虫文件只写item的生成规则。
先看item类
from scrapy.loader importItemLoaderfrom scrapy.loader.processors importMapCompose, TakeFirst, Join#一个小技巧,可以覆盖默认的规则,就是TakeFirst()把列表转换成字符串,我们这里不让转成字符串,还是数组
defreturn_value(value):returnvalue#因为通过自带的ItemLoader类生成的item_loader他都是list,所以我们自定义下。默认的处理规则(可以单个字段覆盖),这样就不用每个字段都写重复的代码了
classArticleItemLoader(ItemLoader):#自定义itemloader
default_output_processor =TakeFirst()#自定义的item类。input_processor是指需要处理的业务逻辑,比如一些格式的转换什么的,output_processor可以覆盖默认的规则。
classJobBoleArticleItem(scrapy.Item):
title=scrapy.Field()
create_date=scrapy.Field(
input_processor=MapCompose(date_convert),
)
url=scrapy.Field()
url_object_id=scrapy.Field()
front_image_url=scrapy.Field(
output_processor=MapCompose(return_value)
)
front_image_path=scrapy.Field()
praise_nums=scrapy.Field(
input_processor=MapCompose(get_nums)
)
comment_nums=scrapy.Field(
input_processor=MapCompose(get_nums)
)
fav_nums=scrapy.Field(
input_processor=MapCompose(get_nums)
)
tags=scrapy.Field(
input_processor=MapCompose(remove_comment_tags),
output_processor=Join(",")
)
content= scrapy.Field()
爬虫类
from scrapy.loader importItemLoaderfrom ArticleSpider.items importJobBoleArticleItem, ArticleItemLoaderdefparse_detail(self, response):
article_item=JobBoleArticleItem()#通过item loader加载item
front_image_url = response.meta.get("front_image_url", "") #文章封面图
item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response)
item_loader.add_css("title", ".entry-header h1::text")
item_loader.add_value("url", response.url)
item_loader.add_value("url_object_id", get_md5(response.url))
item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text")
item_loader.add_value("front_image_url", [front_image_url])
item_loader.add_css("praise_nums", ".vote-post-up h10::text")
item_loader.add_css("comment_nums", "a[href='#article-comment'] span::text")
item_loader.add_css("fav_nums", ".bookmark-btn::text")
item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text")
item_loader.add_css("content", "div.entry")
article_item=item_loader.load_item()yield article_item
获取一个页面的全部url
我们当然可以用xpath得到,但是还不够精简。我们可以使用 linkExtractor 类来得到。非常的简单。
from scrapy.linkextractors importLinkExtractor#需要搞一个对象实例,然后写一个符合的规则,利用extract_links方法传一个response过去就能得到这个页面匹配的url
link = linkExtractor=LinkExtractor(allow=r'http://lab.scrapyd.cn')#link = linkExtractor=LinkExtractor()#allow=r'http://lab.scrapyd.cn/archives/\d+.html'
links =link.extract_links(response)iflinks:for link_one inlinks:print(link_one)
日志的使用
Scrapy提供了log功能,可以通过 logging 模块使用。
可以修改配置文件settings.py,任意位置添加下面两行,效果会清爽很多。
LOG_FILE = "TencentSpider.log"LOG_LEVEL= "INFO"
Log levels
Scrapy提供5层logging级别:
CRITICAL-严重错误(critical)
ERROR-一般错误(regular errors)
WARNING-警告信息(warning messages)
INFO-一般信息(informational messages)
DEBUG- 调试信息(debugging messages)
logging设置
通过在setting.py中进行以下设置可以被用来配置logging:
LOG_ENABLED 默认: True,启用logging
LOG_ENCODING 默认:'utf-8',logging使用的编码
LOG_FILE 默认: None,在当前目录里创建logging输出文件的文件名
LOG_LEVEL 默认:'DEBUG',log的最低级别
LOG_STDOUT 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行print "hello" ,其将会在Scrapy log中显示。
保存到mongdb数据库
importpymongofrom scrapy.conf importsettingsclassDoubanPipeline(object):def __init__(self):
host= settings["MONGODB_HOST"]
port= settings["MONGODB_PORT"]
dbname= settings["MONGODB_DBNAME"]
sheetname= settings["MONGODB_SHEETNAME"]#创建MONGODB数据库链接
client = pymongo.MongoClient(host = host, port =port)#指定数据库
mydb =client[dbname]#存放数据的数据库表名
self.sheet =mydb[sheetname]defprocess_item(self, item, spider):
data=dict(item)
self.sheet.insert(data)return item
setting文件
#MONGODB 主机名
MONGODB_HOST = "127.0.0.1"
#MONGODB 端口号
MONGODB_PORT = 27017
#数据库名称
MONGODB_DBNAME = "Douban"
#存放数据的表名称
MONGODB_SHEETNAME = "doubanmovies"
下载中间件,随机更换user-Agent和ip
importrandomimportbase64from settings importUSER_AGENTSfrom settings importPROXIES#随机的User-Agent
classRandomUserAgent(object):defprocess_request(self, request, spider):
useragent=random.choice(USER_AGENTS)#print useragent
request.headers.setdefault("User-Agent", useragent)classRandomProxy(object):defprocess_request(self, request, spider):
proxy=random.choice(PROXIES)if proxy['user_passwd'] isNone:#没有代理账户验证的代理使用方式
request.meta['proxy'] = "http://" + proxy['ip_port']else:#对账户密码进行base64编码转换
base64_userpasswd = base64.b64encode(proxy['user_passwd'])#对应到代理服务器的信令格式里
request.headers['Proxy-Authorization'] = 'Basic' +base64_userpasswd
request.meta['proxy'] = "http://" + proxy['ip_port']
setting文件
USER_AGENTS =['Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)','Opera/9.27 (Windows NT 5.2; U; zh-cn)','Opera/8.0 (Macintosh; PPC Mac OS X; U; en)','Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0','Mozilla/5.0 (Linux; U; Android 4.0.3; zh-cn; M032 Build/IML74K) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30','Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13']
PROXIES=[
{"ip_port" :"121.42.140.113:16816", "user_passwd" : "mr_mao_hacker:sffqry9r"},#{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""}
#{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""}
#{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""}
]
登陆的三种方法
1,直接找到登陆接口,提供账号密码进行登陆,也是最简单的。
2,有时候需要从登录页找到隐藏的值,然后提交到后台,比如知乎就需要在登录页得到_xsrf,
3,最麻烦的一种,对方各种加密验证,我们可以采用cookie进行登陆。
分别写三个代码参考下:
1.简单


#-*- coding: utf-8 -*-
importscrapy#只要是需要提供post数据的,就可以用这种方法,#下面示例:post数据是账户密码
classRenren1Spider(scrapy.Spider):
name= "renren1"allowed_domains= ["renren.com"]defstart_requests(self):
url= 'http://www.renren.com/PLogin.do'
yieldscrapy.FormRequest(
url=url,
formdata= {"email" : "[email protected]", "password" : "alarmchime"},
callback=self.parse_page)defparse_page(self, response):
with open("mao2.html", "w") as filename:
filename.write(response.body)
View Code
2.中等
#-*- coding: utf-8 -*-
importscrapy#正统模拟登录方法:#首先发送登录页面的get请求,获取到页面里的登录必须的参数,比如说zhihu的 _xsrf#然后和账户密码一起post到服务器,登录成功
classRenren2Spider(scrapy.Spider):
name= "renren2"allowed_domains= ["renren.com"]
start_urls=("http://www.renren.com/PLogin.do",
)defparse(self, response):#_xsrf = response.xpath("//_xsrf").extract()[0]
yieldscrapy.FormRequest.from_response(
response,
formdata= {"email" : "[email protected]", "password" : "alarmchime"},#, "_xsrf" = _xsrf},
callback =self.parse_page
)defparse_page(self, response):print "=========1===" +response.url#with open("mao.html", "w") as filename:
#filename.write(response.body)
url = "http://www.renren.com/422167102/profile"
yield scrapy.Request(url, callback =self.parse_newpage)defparse_newpage(self, response):print "===========2====" +response.url
with open("xiao.html", "w") as filename:
filename.write(response.body)
View Code
3.困难
#-*- coding: utf-8 -*-
importscrapy#实在没办法了,可以用这种方法模拟登录,麻烦一点,成功率100%
classRenrenSpider(scrapy.Spider):
name= "renren"allowed_domains= ["renren.com"]
start_urls=('http://www.renren.com/xxxxx','http://www.renren.com/11111','http://www.renren.com/xx',
)
cookies={"anonymid" : "ixrna3fysufnwv","_r01_" : "1","ap" : "327550029","JSESSIONID" : "abciwg61A_RvtaRS3GjOv","depovince" : "GW","springskin" : "set","jebe_key" : "f6fb270b-d06d-42e6-8b53-e67c3156aa7e%7Cc13c37f53bca9e1e7132d4b58ce00fa3%7C1484060607478%7C1%7C1486198628950","jebe_key" : "f6fb270b-d06d-42e6-8b53-e67c3156aa7e%7Cc13c37f53bca9e1e7132d4b58ce00fa3%7C1484060607478%7C1%7C1486198619601","ver" : "7.0","XNESSESSIONID" : "e703b11f8809","jebecookies" : "98c7c881-779f-4da8-a57c-7464175cd469|||||","ick_login" : "4b4a254a-9f25-4d4a-b686-a41fda73e173","_de" : "BF09EE3A28DED52E6B65F6A4705D973F1383380866D39FF5","p" : "ea5541736f993365a23d04c0946c10e29","first_login_flag" : "1","ln_uact" : "[email protected]","ln_hurl" : "http://hdn.xnimg.cn/photos/hdn521/20140529/1055/h_main_9A3Z_e0c300019f6a195a.jpg","t" : "691808127750a83d33704a565d8340ae9","societyguester" : "691808127750a83d33704a565d8340ae9","id" : "327550029","xnsid" : "f42b25cf","loginfrom" : "syshome"}defstart_requests(self):for url inself.start_urls:#yield scrapy.Request(url, callback = self.parse)
#url = "http://www.renren.com/410043129/profile"
yield scrapy.FormRequest(url, cookies = self.cookies, callback =self.parse_page)defparse_page(self, response):print "===========" +response.url
with open("deng.html", "w") as filename:
filename.write(response.body)
View Code