{% block content %}
{% if error_message %}
{ { error_message}}
{% endif %} {% endblock %}今天就带你把它与Python爬虫结合做出个有趣的东西吧。我们将开发这样一个应用,前端用户可以根据行政区划,房厅数和价格区间选择需要爬取的二手房房源信息,后台Python开始爬取数据。爬取数据完成后,通过Django将爬来的数据存入数据库并通过网页显示给用户。通过本文,你将学会:
Django如何与Python爬虫结合与交互
如何利用split方法和正则表达式从字符串中提取我们所需要信息
1、开发环境
使用venv或PyCharm新建一个项目,安装本项目所需要的python第三方库。后面3个库都是python爬虫常用的库。我们将使用Django 2.1 + Python 3.X + SQLite开发。
pip install django
pip install bs4
pip install requests
pip install fake-useragent
2、新建项目与项目设置
使用django-admin startproject home_spider创建一个名为home_spider的django项目,
然后cd home_spider进入项目文件夹,
使用python manage.py startapp homelink创建一个名为homelink的APP,
然后把它加入到settings.py的INSTALLED_APP里去。
#home_spider/settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'homelink',
]
3、把app的urls加到项目里去, 如下所示。
#home_spider/urls.py
"""home_spider URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/3.1/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path
from django.conf.urls import include #新增导入include
#from homelink import urls
urlpatterns = [
path('admin/', admin.site.urls),
#path('accounts/', include('allauth.urls')),
path('homelink/', include('homelink.urls')),
]
在homelink文件夹下新建一个python文件urls.py,添加以下代码。
#\home_spider\homelink\urls.py
from django.urls import path
from . import views
app_name = 'homelink'
'''
该urls对应两个视图方法,
一个(house_index)用于显示查询选项和爬取结果,
一个(house_spider)用于后台爬取数据并存入数据库。
'''
urlpatterns = [
path('', views.house_index, name='house_index'),#对应http://127.0.0.1:8000/homelink/
path('spider/', views.house_spider, name='house_spider'),#对应http://127.0.0.1:8000/homelink/spider/
]
4、视图
我们在urls对应两个视图方法,一个(house_index)用于显示查询选项和爬取结果,一个(house_spider)用于后台爬取数据并存入数据库。我们接下来将分别编写两个视图方法。
视图中house_index方法对应首页(index),其作用是渲染表单和显示爬取结果。当数据库已存有爬取数据时(house_list),分页显示爬取数据。当house_list不存在时,显示带有查询选项的空表单。
视图中house_spider方法将负责爬取数据并通过Django存入数据库。
我们现在来看house_spider方法是如何工作的:
当用户以POST提交查询表单,我们构建需要爬取的链接,然后交由HomeLinkSpider类处理。处理完成后返回index页面。
我们构建HomeLinkSpider类,该类接收需要爬取的url作为参数,并具体包含了三个方法。get_max_page方法可获取目标url的分页最大页数。parse_page方法可以循环爬取每个分页上的数据,并将其存入self.data列表。save_to_model方法可以将self.data遍历并存入Django数据库。
我们使用fake-useragent构造请求头headers防止爬虫被封。
#homelink/views.py
from django.shortcuts import render
# Create your views here.
from .forms import HouseChoiceForm
from .models import HouseInfo
from django.core.paginator import Paginator
from django.http import HttpResponseRedirect
from fake_useragent import UserAgent
import requests
from bs4 import BeautifulSoup
import re
'''
视图中house_index方法对应首页(http://127.0.0.1:8000/homelink/),
其作用是渲染表单和显示爬取结果。
当数据库已存有爬取数据时(house_list),分页显示爬取数据。
当house_list不存在时,显示带有查询选项的空表单。
'''
def house_index(request):
form = HouseChoiceForm()
house_list = HouseInfo.objects.all().order_by('-add_date')
if house_list:
paginator = Paginator(house_list, 50)#每页显示50条数据
page = request.GET.get('page')
page_obj = paginator.get_page(page)
return render(request, 'homelink/index.html',
{'page_obj': page_obj, 'paginator': paginator,
'is_paginated': True, 'form': form,})
else:
return render(request, 'homelink/index.html', {'form': form, })
# house_spider方法将负责爬取数据并通过Django存入数据库
def house_spider(request):
if request.method == 'POST':
form = HouseChoiceForm(request.POST)
if form.is_valid():
district = form.cleaned_data.get('district')
price = form.cleaned_data.get('price')
bedroom = form.cleaned_data.get('bedroom')
url = 'https://sh.lianjia.com/ershoufang/{}/{}{}'.format(district, price, bedroom)
home_spider = HomeLinkSpider(url)
home_spider.get_max_page()#好像无用,parse_page()中会调用get_max_page()
home_spider.parse_page()
home_spider.save_data_to_model()
return HttpResponseRedirect('/homelink/')
else:
return HttpResponseRedirect('/homelink/')
class HomeLinkSpider(object):
def __init__(self, url):
self.ua = UserAgent()
self.headers = {"User-Agent": self.ua.random}
self.data = list()
self.url = url
def get_max_page(self):
response = requests.get(self.url, headers=self.headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
a = soup.select('div[class="page-box house-lst-page-box"]')
max_page = eval(a[0].attrs["page-data"])["totalPage"] # 使用eval是字符串转化为字典格式
return max_page
else:
print("请求失败 status:{}".format(response.status_code))
return None
def parse_page(self):
max_page = self.get_max_page()
for i in range(1, max_page + 1):
url = "{}pg{}/".format(self.url, i)
response = requests.get(url, headers=self.headers)
soup = BeautifulSoup(response.text, 'html.parser')
ul = soup.find_all("ul", class_="sellListContent")
li_list = ul[0].select("li")
for li in li_list:
detail = dict()
detail['title'] = li.select('div[class="title"]')[0].get_text()
# 大华锦绣华城(九街区) | 3室2厅 | 76.9平米 | 南 | 其他 | 无电梯
house_info = li.select('div[class="houseInfo"]')[0].get_text()
house_info_list = house_info.split(" | ")
detail['bedroom'] = house_info_list[0]
detail['area'] = house_info_list[1]
detail['direction'] = house_info_list[2]
# 低楼层(共7层)2006年建板楼 - 张江. 提取楼层,年份和板块
position_info = li.select('div[class="positionInfo"]')[0].get_text().split(' - ')
detail['house'] = position_info[0]
floor_pattern = re.compile(r'.+\)')
#match1 = re.search(floor_pattern, position_info[0]) # 从字符串任意位置匹配
match1 = re.search(floor_pattern, house_info_list[4]) # 从字符串任意位置匹配
if match1:
detail['floor'] = match1.group()
else:
detail['floor'] = "未知"
#detail['floor'] = re.search(floor_pattern, position_info[0]).group() # 从字符串头部开始匹配
year_pattern = re.compile(r'\d{4}')
#match2 = re.search(year_pattern, position_info[0]) # 从字符串任意位置匹配
match2 = re.search(year_pattern, house_info_list[5]) # 从字符串任意位置匹配
if match2:
detail['year'] = match2.group()
else:
detail['year'] = "未知"
detail['location'] = position_info[1]
# 650万,匹配650
price_pattern = re.compile(r'\d+')
total_price = li.select('div[class="totalPrice"]')[0].get_text()
detail['total_price'] = re.search(price_pattern, total_price).group()
# 单价64182元/平米, 匹配64182
unit_price = li.select('div[class="unitPrice"]')[0].get_text()
detail['unit_price'] = re.search(price_pattern, unit_price).group()
self.data.append(detail)
def save_data_to_model(self):
HouseInfo.objects.all().delete()
for item in self.data:
new_item = HouseInfo()
new_item.title = item['title']
new_item.house = item['house']
new_item.bedroom = item['bedroom']
new_item.area = item['area']
new_item.direction = item['direction']
new_item.floor = item['floor']
new_item.year = item['year']
new_item.location = item['location']
new_item.total_price = item['total_price']
new_item.unit_price = item['unit_price']
new_item.save()本例中我们使用到了带有选项的表单HouseChoiceForm, 其代码如下。之所以这么构建选项是因为链家上的二手房信息链接是由不同选项拼接组成的。比如https://sh.lianjia.com/ershoufang/pudong/l2p3/查询的是浦东价格是300-400万之间的二房。
# homelink/forms.py
from django import forms
DISTRICT_CHOICES = (('pudong', '浦东'), ('minhang', '闵行'), ('xuhui', '徐汇'))
PRICE_CHOICES = (('p3', '300-400万'), ('p4', '400-500万'), ('p5', '500-800万'))
BEDROOM_CHOICES = (('l2', '二室'), ('l3', '三室'))
class HouseChoiceForm(forms.Form):
district = forms.CharField(label="区域", widget=forms.RadioSelect(choices=DISTRICT_CHOICES))
price = forms.CharField(label="价格", widget=forms.RadioSelect(choices=PRICE_CHOICES))
bedroom = forms.CharField(label="庭室", widget=forms.RadioSelect(choices=BEDROOM_CHOICES))
5、Html模板:
首页对应模板如下。该模板用户显示表单和爬取结果。如果用户通过表单提交爬取选项,将交由视图homelink:house_spider处理。
#homelink/templates/homelink/base.html
{% load static %}
{% block title %}Django+Python爬取链接二手房信息{% endblock %}
{% block content %}
{% if error_message %}{
{ error_message}}
{% endif %}
{% endblock %}
#homelink/templates/homelink/index.html
{% extends "homelink/base.html" %}
{% block content %}
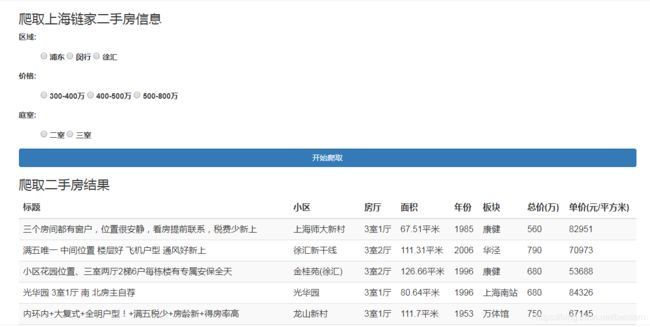
爬取上海链家二手房信息
{% if page_obj %}
爬取二手房结果
标题
小区
房厅
面积
年份
板块
总价(万)
单价(元/平方米)
{% for house in page_obj %}
{
{ house.title }}
{
{ house.house }}
{
{ house.bedroom }}
{
{ house.area }}
{
{ house.year }}
{
{ house.location }}
{
{ house.total_price }}
{
{ house.unit_price }}
{% endfor %}
{% else %}
{# 注释: 这里可以换成自己的对象 #}
尚无二手房信息。
{% endif %}
{# 注释: 下面代码实现分页 #}
{% if is_paginated %}
{% endif %}
{% endblock %}
把html文件的存放路径配置进去:
#\home_spider\home_spider\settings.py
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR,'homelink\\templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]6、数据库模型:
我们的模型非常简单,主要用于存储二手房相关信息,如小区,房厅,朝向,总价和单价。模型的各个字段与我们即将从链家网上爬取的信息是逐一对应的。
#homelink/models.py
from django.db import models
# Create your models here.
class HouseInfo(models.Model):
title = models.CharField(max_length=256, verbose_name='标题')
house = models.CharField(max_length=20, verbose_name='小区')
bedroom = models.CharField(max_length=20, verbose_name='房厅')
area = models.CharField(max_length=20, verbose_name='面积')
direction = models.CharField(max_length=20, verbose_name='朝向')
floor = models.CharField(max_length=60, verbose_name='朝向')
year = models.CharField(max_length=10, verbose_name='年份')
location = models.CharField(max_length=10, verbose_name='位置')
total_price = models.IntegerField(verbose_name='总价(万元)')
unit_price = models.IntegerField(verbose_name='单价(元/平方米)')
add_date = models.DateTimeField(auto_now_add=True, verbose_name="创建日期")
mod_date = models.DateTimeField(auto_now=True, verbose_name="修改日期")
def __str__(self):
return "{}-{}-{}".format(self.house, self.bedroom, self.total_price)
class Meta:
verbose_name = "二手房"
在本例中我们对于面积和年份字段使用了CharField,而不是IntegerField,这是因为房屋面积不一定是整数,而有些二手房年限未知。
进入\home_spider\homelink依次允许一下命令建库:
python manage.py makemigrations---生成代码
python manage.py migrate---建库建表
7、实战效果
启动服务器:进入\home_spider\homelink运行:python manage.py runserver 127.0.0.1:8000
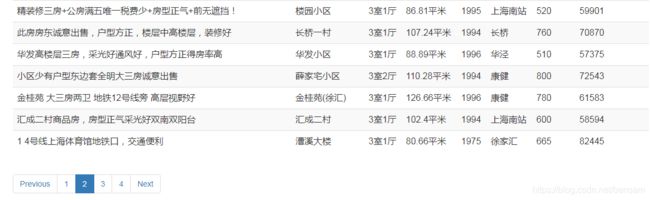
当你在首页选择爬取选项,点击开始爬取,等待2分钟,你就可以看到爬取的数据以表格形式分页显示在同一页面上啦。
8、整套代码:https://download.csdn.net/download/bensam/13077184