pandas学习——基础练习
pandas基础
- 一、基本数据结构
-
- (一)Series
-
- 1)创建
- 2)访问
- (二)DataFrame
-
- 1)创建
- 2)访问
- 3)修改索引
- (三)对比
- 二、遇到的问题
-
- (一)randn和rand的区别:
- (二)value_counts统计缺失值
- (三)df.mean(axis=1)是什么意思?它与df.mean()的结果一样吗?第一问提到的函数也有axis参数吗?怎么使用?
- 三、实例
-
- (一)权利游戏
- (二)科比投篮
一、基本数据结构
(一)Series
是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组。轴标签统称为索引。
1)创建
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'],name='这是一个Series',dtype='float64')
s
2)访问
s.values
s.name
s.index
s.dtype

![]()
![]()
![]()
(二)DataFrame
1)创建
方法一:
df1 = pd.DataFrame([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],columns=["col1", "col2", "col3", "col4"])
df1

方法二:
df=pd.DataFrame({
'A':['zhang','zhao','wang','li'],'B':list('xyzq'),
'C':range(1,5)},index=list('一二三四'))

2)访问
df['A']

type(df)
![]()
type(df['A'])
![]()
3)修改索引
df.rename(index={
'一':'one'},columns={
'A':'new_col1'})
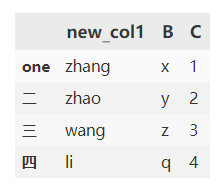
(三)对比
| Series | DataFrame | |
|---|---|---|
| axex | 返回Series索引列表 | 获取行及列索引 |
| dtype | 返回数据类型 | 返回数据类型 |
| values | 将Series作为ndarray返回 | 返回ndarray类型的对象 |
| head()/tail() | 返回前几行/最后几行 | 显示前/后(i)行数据,默认为前/后5行 |
二、遇到的问题
(一)randn和rand的区别:
np.random.randn(d0,d1,…,dn)从标准正态分布中返回一个或多个样本值。
而np.random.rand(d0,d1,…,dn)产生的随机样本位于[0,1)中
(二)value_counts统计缺失值
不会。
import pandas as pd
df1 = pd.DataFrame({
'A':[1,2,3]},index=[1,2,3])
df1['B']=list('abc')
df3=df1.assign(C=pd.Series(list('def')))
df3['C'].value_counts()
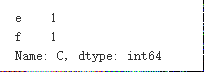
(三)df.mean(axis=1)是什么意思?它与df.mean()的结果一样吗?第一问提到的函数也有axis参数吗?怎么使用?
df1 = pd.DataFrame([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],columns=["col1", "col2", "col3", "col4"])
df1
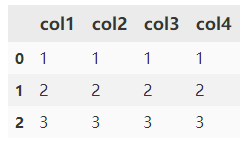
# axis=1时为按行计算的均值,默认为按列计算均值。
print(df1.mean())
print(df1.mean(axis=1))

df2=pd.Series([1,2,3,4],dtype='float64')
print(df2)
print(df2.mean())
print(df2.mean(axis=1))

三、实例
(一)权利游戏
- 在所有的数据中,一共出现了多少人物?
- 以单元格计数(即简单把一个单元格视作一句),谁说了最多的话?
- 以单词计数,谁说了最多的单词?(这块可以参考一下制作词云,我觉得和这块挺像,有借鉴之处)
test=pd.read_csv('data/Game_of_Thrones_Script.csv')
test.head()
# 问题1
test['Name'].nunique()
# 问题2
test['Name'].value_counts().nlargest(1)
# 或者
test['Name'].value_counts().index[0]
# 问题 3
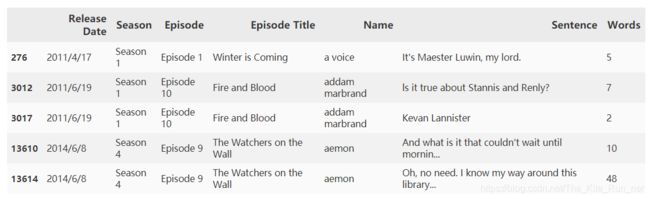
test_words = test.assign(Words=test['Sentence'].apply(lambda x:len(x.split()))).sort_values(by='Name')
test_words.head()
L_count = []
N_words = list(zip(test_words['Name'],test_words['Words']))
for i in N_words:
if i == N_words[0]:
L_count.append(i[1])
last = i[0]
else:
L_count.append(L_count[-1]+i[1] if i[0]==last else i[1])
last = i[0]
test_words['Count']=L_count
test_words['Name'][test_words['Count'].idxmax()]
![]()
![]()
![]()
(二)科比投篮
#index_col是将某一列作为行索引
pd.read_csv('data/Kobe_data.csv',index_col='shot_id').head()
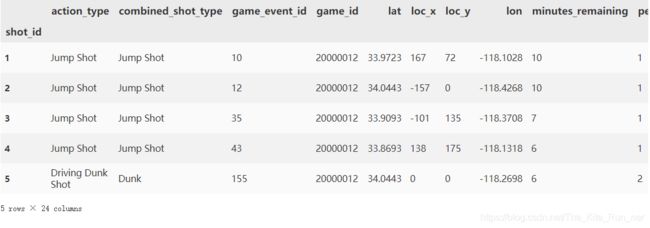
- 哪种action_type和combined_shot_type的组合是最多的?
pd.Series(list(zip(df['action_type'],df['combined_shot_type']))).value_counts().index[0]
![]()
2. 在所有被记录的game_id中,遭遇到最多的opponent是一个支?
pd.Series(list(list(zip(*(pd.Series(list(zip(df['game_id'],df['opponent'])))
.unique()).tolist()))[1])).value_counts().index[0]
![]()