背景
公司项目的广告展示率太低,需要查找原因,之前做了统计埋点,运维给出过滤后的数据,一个 txt 文件 500M 以上,文件打开非常乱。

询问运维是否有工具转换,回复说没有,然后想到之前重学 Python3 的初衷,就是为了能写一些脚本方便处理一些事情。
这个数据主要是 HTTP 的 GET 请求,需要转码,然后把参数拿到,目标是写到 Execl 文件中。
因为一直没用,语法也记不清楚,只能不停回看笔记,关于 Execl 这块也没用过,临时网上查找。
读文件
由于原文件太大,所以先复制了一部分存入当前目录的 test.txt 文件中。
import os
file = open('./test.txt') # 打开文件
for line in file: # 按行遍历文件
...
file.close() # 最后要关闭
遍历每一行数据后,转码,分割,转成字典结构
import urllib.parse
# 定义个方法将一行数据转成字典
def getOneDict(line):
params = dict() # 创建字典保存数据
pre = 'timeAnalysis?'
index = line.find(pre) # 找到这个位置,后面的数据是需要的参数
if index > -1:
line = line[index+len(pre):].split()[0] # 先截子串然后选空格之前的
line = urllib.parse.unquote(line) # 网上搜到的用于将 HTTP 编码后的文字解码
paramList = line.split('&') # 得到类似 s=android 的内若
for item in paramList:
param = item.split('=')
if (len(param) > 1): # 如果等于号后面有值
params[param[0]] = param[1] # 字典加个数据
return params
创建 Execl 文件
有了每一行对应的字典,就想把这内容写到 Execl 文档里。要先切换到 pip3 目录,执行 sudo pip3 install openpyxl 安装 openpyxl 模块,最新的语法参考 http://openpyxl.readthedocs.io/en/stable/
import openpyxl
def createExcel():
if 'time.xlsx' in os.listdir('./'): # 如果有了这个文件,就不要再创建了
return
wb = openpyxl.Workbook() # 创建 Execl
wb.active.title = 'Splash' # 默认有一个活动的 Sheet,把名字改成 Splash
wb.create_sheet(title='Home') # 再创建一个 Sheet
wb.save('time.xlsx') # 最后一定不能忘了这句
结果本地生成了文件 time.xlsx,打开后有两个 Sheet。
向 Execl 中插入数据
看 Execl,横向是 A、B、C... 这样编号,纵向是 1、2、3... 这样编号,看文档可以通过两个编号组合来定位。我这里没用这个函数。
我需要把字典里的 key 作为第一行用作标题,然后每来一个字典里的数据,先寻找是否有了这个 key,有了就往下一行添加对应的 value,没有的话先添加一列,行数是第一行,值是字典里的这个 key,然后再添加 value。
def writeToExecl(params):
wb = openpyxl.load_workbook('time.xlsx') # 打开 Execl 文件
splashSheet = wb['Splash'] # 找到两个 Sheet
homeSheet = wb['Home']
if params['pid'] == '04': # 如果字典里有一个 pid=04 的,要放到 Splash 表里
writeToSheet(splashSheet, wb, params)
elif params['pid'] == '00':
writeToSheet(homeSheet, wb, params)
def getValue(t):
return t.value
def writeToSheet(sheet, wb, params):
rows = tuple(sheet.rows) # 拿到所有行转成元组
index = len(rows) + 1 # 在原有的行数的下一行插入数据
print('rows ' + str(index))
titles = list(map(getValue, rows[0])) # 用高阶函数 map 转换第一行,拿到里面的 value,然后要转成 list
if titles == [None]: # 测试发现列表不是空的,长度是 1,里面是 None,所以判断一下
titles = []
for k,v in params.items(): # 遍历字典
if k in titles: # 如果第一行有这个标题,直接插值
sheet.cell(row = index, column = titles.index(k) + 1).value = v # 行数为 index,列为这个 key 在的行,cell 里的索引从 1 开始
else:
sheet.cell(row = 1, column = len(titles) + 1).value = k # 先插标题,先插了一列
sheet.cell(row = index, column = len(titles) + 1).value = v # 再插字典的 value
titles.append(k) # 标题多了一个,要更新
wb.save('time.xlsx') # 保存以生效
遍历文件
将要分析的文件放入当前目录的 web 文件夹下,然后遍历,对每一个文件进行读取。
for file in os.listdir('./web'):
print('read file ' + os.path.basename(file))
readAFile('./web/' + file)
def readAFile(filename):
file = open(filename)
for line in file:
params = getOneDict(line)
if (len(params) == 0): # 如果字典为空,继续下一行
continue
writeToExecl(params)
file.close()
其它
运行时报出了一个错误
...
self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 3131: invalid start byte ...
网上搜了下,是编码的问题,没去特地解决,一两行数据不影响统计比例,找到一种方法,打开文件时忽略错误。
file = open(filename, errors='ignore')
还有生成的文件名,要分析文件的路径等可以通过命令行参数传入,这样可用性高些,就不搞了。
整体做下来,其实功能很简单,但是由于对语言的不熟悉,花了不少时间,map 这个高级函数还是因为 Kotlin,Rx 里都有类似的,所以搜了下才知道,有些不知道的可能就写繁琐了。
文件太大,写入时间太长,只运行了一会看了一些数据,分析出大概的原因,最终还是让运营再去过滤分析比例的。
结果
源代码
import os
import urllib.parse
import openpyxl
import sys
# 将一行数据转成字典
def getOneDict(line):
params = dict() # 创建字典保存数据
pre = 'timeAnalysis?'
index = line.find(pre)
if index > -1:
line = line[index+len(pre):].split()[0]
line = urllib.parse.unquote(line)
paramList = line.split('&')
for item in paramList:
param = item.split('=')
if (len(param) > 1):
params[param[0]] = param[1]
return params
def createExcel():
if 'time.xlsx' in os.listdir('./'):
return
wb = openpyxl.Workbook() # 创建Execl
wb.active.title = 'Splash'
wb.create_sheet(title='Home')
wb.save('time.xlsx')
def writeToExecl(params):
wb = openpyxl.load_workbook('time.xlsx')
splashSheet = wb['Splash']
homeSheet = wb['Home']
if params['pid'] == '04': # 开屏
writeToSheet(splashSheet, wb, params)
elif params['pid'] == '00': # 首页
writeToSheet(homeSheet, wb, params)
def getValue(t):
return t.value
def writeToSheet(sheet, wb, params):
rows = tuple(sheet.rows)
index = len(rows) + 1 # 从这一行开始插入数据
titles = list(map(getValue, rows[0])) # 拿到第1行的内容,做标题用
if titles == [None]:
titles = []
for k,v in params.items():
if k in titles:
sheet.cell(row = index, column = titles.index(k) + 1).value = v
else:
sheet.cell(row = 1, column = len(titles) + 1).value = k # 先插标题
sheet.cell(row = index, column = len(titles) + 1).value = v
titles.append(k) # 更新标题
wb.save('time.xlsx')
def readAFile(filename):
file = open(filename, errors='ignore')
for line in file:
params = getOneDict(line)
if (len(params) == 0):
continue
writeToExecl(params)
file.close()
createExcel()
for file in os.listdir('./web'):
print('read file ' + os.path.basename(file))
readAFile('./web/' + file)
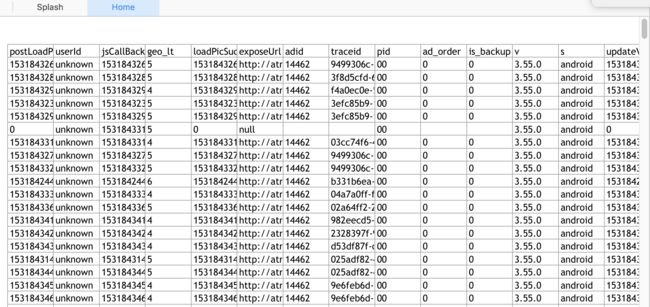
生成 Execl 如下
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=1bylyaan0796j