1.PLA
重新回顾一下一开始学的PLA,preceptron learning Algorithm。PLA适用于二维及高维的线性可分的情况,如果是非线性可分的数据,如果使用PLA可能会无限循环。问题的答案只有同意或不同意:

PLA要做的其实就找到一个x映射到y的f,使得这个f和数据的分布一致,判断结果一致。
如果是遇到了线性不可分的情况,就不能再要求完全正确了,所以在optimization的时候会要求只需要找到最少错误的分类就可以了,不再要求完全正确的分类。
2.Combine some PLA
把PLA按照aggregation model的想法结合起来:
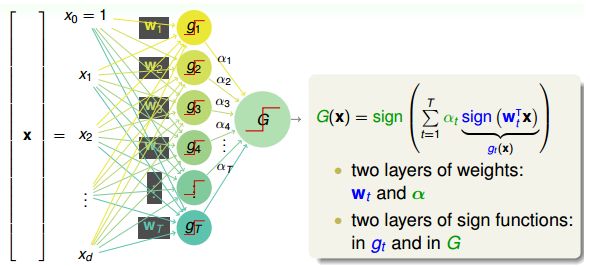
左边是x = {X1, X2, X3, X4......},和右边的w = {W1, W2, W3......}做內积之后就得到了n个值,就相当于PLA里面WX的部分了。把得到WX的称为是g(x),最后再乘上α,其实就是把g(x)做了一个非线性的组合,也就是aggregation的blending模型。
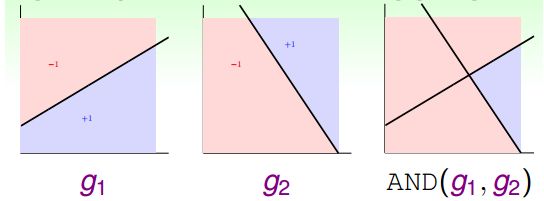
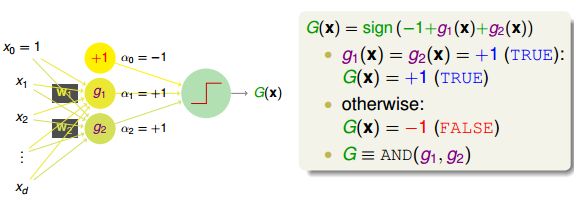
g1,g2 = {-1, +1};g1 = -1, g2 = -1,那么结果是就是-3,g1 = -1, g2 = +1, 结果就是-1,如果g1 = +1, g2 = +1,那么结果就是还是正的,符合预期。
这个例子简单说明了在经过一定的线性组合的情况下是可以做到非线性的分类的。除此之外,OR,XOR等等都是可以通过g(x)的线性组合得到的。
所以说,Neural Network是一种很powerful同上也是complicated的模型,另外,当hidden层神经元数量大的时候计算量会非常大。比如下面的一个例子,有一个圆形区域,里面的+!外面是-1,这种是没有办法使用一个PLA切分开的,只能使用多个PLA了,如果是8个PLA的时候,大概是可以组成一个圆形,16个PLA的时候就要更接近了,因此,使用的PLA越多,得到的结果就会和数据的分布越拟合:
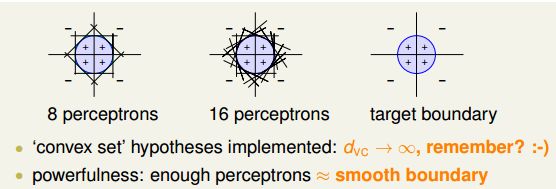
之前说过,凸多边形的VC dimension是无限大的,2的n次方,所以随着PLA数量的增长vc 维是没有限制的,容易造成过拟合。但是,数目较多总是可以得到一个更加平滑更加拟合的曲线,这也是aggregation model的特点。
但是,还是有单层preceptron线性组合做不到的事情,比如XOR操作:
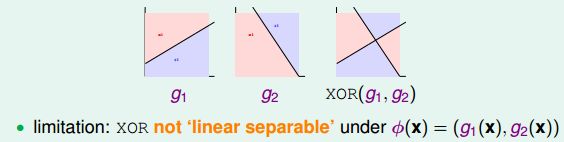
因为XOR得到的是非线性可分的区域,如下图所示,没有办法由g1和g2线性组合实现。所以说linear aggregation of perceptrons模型的复杂度还是有限制的。事实上,一层的perceptron其实就是一次transform,那么既然一次transform不行,我们尝试一下多层的perceptron,多次的transform。把XOR拆分开来,第一次是使用AND,第二次就是使用OR,如下:
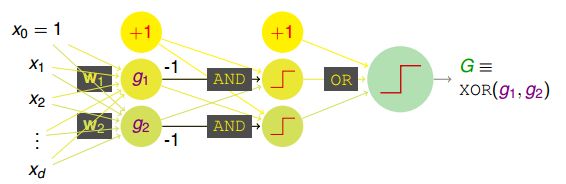
这样就从简单的单层aggregation提升到了multi-layer的多层感知机,模型的复杂度增加之后就更能解决一些非线性的问题了。 第一层的wx处理后再接到下一层wx处理。这其实就是有点接近神经网络的模型了。
3.Neural Network
之前已经介绍过三种线性模型:linear classification,linear regression,logistic regression。那么,对于OUTPUT层的分数s,根据具体问题,可以选择最合适的线性模型。如果是binary classification问题,可以选择linear classification模型;如果是linear regression问题,可以选择linear regression模型;如果是soft classification问题,则可以选择logistic regression模型。
如果根据上面的模型,每一层都是wx,那么无论多少层叠加起来都是www....x而已,都是线性的,所以我们要在每一层结束的时候加上一个activity function。对于激活函数的选择有很多,sigmoid,relu,tanh等。sigmoid函数由于会出现梯度消失的现象,所以现在已经很少用了,relu函数是比较常用的。这里会使用tanh函数:
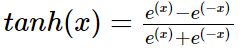
tanh是一个平滑函数,当|s|比较大的时候近似于阶梯函数,|s|比较小的时候会接近于线性函数。处处连续而且可导,计算也比较方便,而且求导的时候可以用上自身的值:
反向传播计算的时候是可以用上之前计算过的缓存下来的值,如果在神经元数量特别多的情况下是可以减少计算复杂度的。
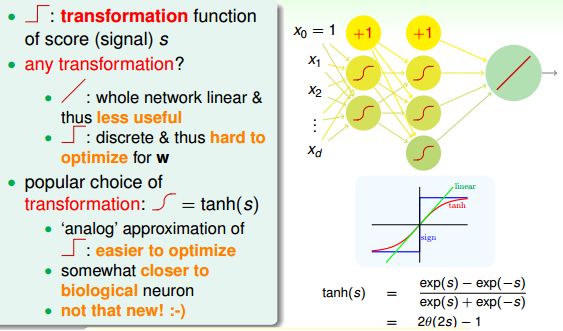
那么下图更新之后的Neural Network:
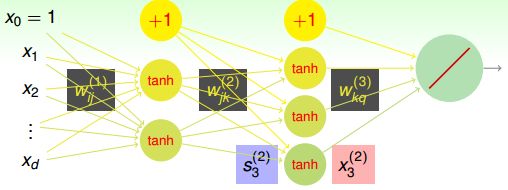
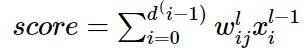
再经过一层激活函数:
每一层的输出就是这样了。
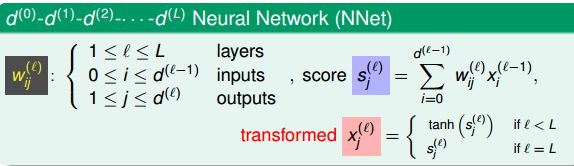
上图中的每一层神经网络其实就是一种transform的过程,而每一层转换的关键就在于权值w,每一层网络利用输入x和权值w的乘积,在经过tanh函数之后,将得到改函数的输出,从左到右,一层一层的进行,如果乘积得到的分数越大,那么tanh(wx)就越接近于1了,表明拟合出来的分布越接近于书记分布。所以每一层的输入x和权重w具有模式上的相似性,比较接近平行,那么transform的效果就比较好。所以,神经网络的核心就是pattern extraction,从数据本身开始查找蕴含的规律,通过一层一层的找到之后再拟合结果。所以,神经网络是生成模型。
根据error function,我们只要计算Ein = (y - score)^2就可利用知道这单个样本点的error了,所以只需要建立Ein与每一个权值之间的关系就可以了,最直接的方法就是使用Gradient Descent了,不断优化w的值。

先来看一下如何计算他们之间的关系:
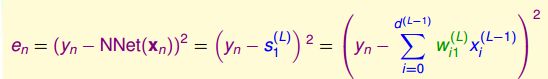
我们的对象是w,自然就是对w求偏导:

这是输出层的偏导结果,也就是delta_output。
对于其他层,根据链式法则:

我们令第j层的神经元的偏导数即为
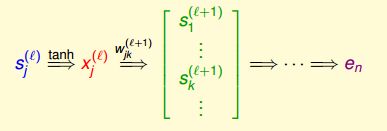
后面的推导其实都很简单了:
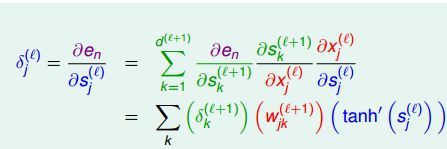
依照这种往上递推的方式,可以把每一层的分数梯度算出来。

上面采用的是SGD的方法,即每次迭代更新时只取一个点,这种做法一般不够稳定。所以通常会采用mini-batch的方法,即每次选取一些数据,例如N/10,来进行训练,最后求平均值更新权重w。这种做法的实际效果会比较好一些。
4.Optimization and Regularization
最终的目标还是要Ein最小,采用什么error function只需要在推导上修正一下就好了。
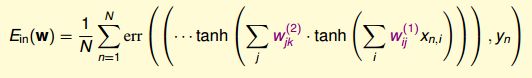
层数越多,说明模型的复杂度就会越大,很明显,这样得到的model肯定不是convex的,可能有很多的山峰,可能只是走到了其中一个而已,并没有到最低的。解决这种情况首先就是对w权值就行随机选择,通过random从普遍概率上选择初始值,避免了人为干扰的因素,有更大的可能走到全局的最优。

从理论上看神经网络,dvc = O(VD)。其中,V是神经网络里面神经元的个数,D表示所有权值的数量,所有如果V很大,那么复杂度就会越大,很有可能会overfit,所以可以通过限制模型复杂度来防止过拟合。
防止overfit还有一个方法,就是regularization,L1或L2正则化。但是使用L2正则化有一个缺点,大的权值就减小很大,小权值基本不怎么变,复杂度事实上还是没有变。而L1正则化是可以使得权值稀疏,但是在某些地方是不可以微分的,使用也不适合。使用我们需要一个可以使得大权值减小很大,小权值减小到0的一个函数:
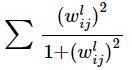

除此之外,训练次数减少也是可以达到限制过拟合效果的。因为训练时间越长,对于寻找可能性就会越多,VC dimension就会越大,当t不大的时候是可以减低模型复杂度的。
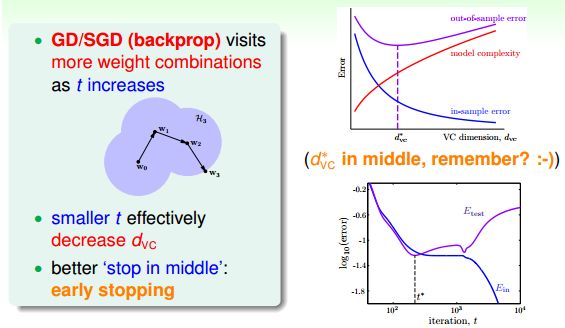
5.代码实现
首先是生成数据,使用的是sklearn的make_moon:
def generator():
np.random.seed(0)
x, y = dataTool.make_moons(200, noise=0.2)
plt.scatter(x[:, 0], x[:, 1], s = 40, c = y, cmap=plt.cm.Spectral)
plt.show()
return x, y
pass
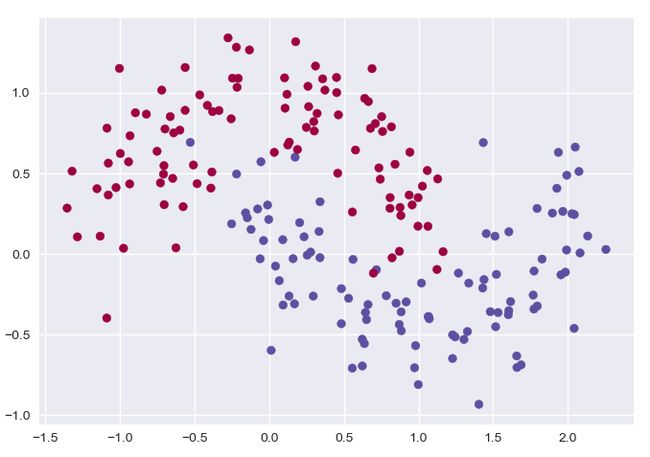
这是我们生成数据的分布,可以看到线性分类器是无法区分开的。
然后就是网络生成训练的主要部分了:
class Network(object):
def __init__(self, x, y):
'''initialize the data'''
self.x = x
self.num_examples = len(x)
self.y = y
self.n_output = 2
self.n_input = 2
self.epsilon = 0.01
self.reg_lambed = 0.01
self.model = None
pass
初始化数据。
def calculate_loss(self, model):
'''calculate the loss function'''
w1, b1, w2, b2 = model['w1'], model['b1'], model['w2'], model['b2']
z1 = self.x.dot(w1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(w2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
corect_logprobs = -np.log(probs[range(self.num_examples), self.y])
data_loss = np.sum(corect_logprobs)
data_loss += self.reg_lambed / 2 * (np.sum(np.square(w1)) + np.sum(np.square(w2)))
return 1.0/self.num_examples * data_loss
计算损失函数,最后使用的是softmax分类器,损失函数使用的是交叉熵:
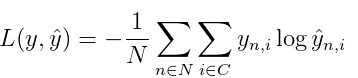
在加上regularization即可。
def predict(self, x):
'''according to the model,predict the consequence'''
w1, b1, w2, b2 = self.model['w1'], self.model['b1'], self.model['w2'], self.model['b2']
z1 = x.dot(w1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(w2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)
pass
预测,常规操作。
def build_Network(self, n_hinden, num_pass = 20000, print_loss = True):
loss = []
np.random.seed(0)
w1 = np.random.randn(self.n_input, n_hinden) / np.sqrt(self.n_input)
b1 = np.zeros((1, n_hinden))
w2 = np.random.randn(n_hinden, self.n_output) / np.sqrt(n_hinden)
b2 = np.zeros((1, self.n_output))
self.model = {}
for i in range(num_pass):
z1 = self.x.dot(w1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(w2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
delta3 = probs
delta3[range(self.num_examples), self.y] -= 1
dw2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(w2.T)*(1 - np.power(a1, 2))
dw1 = np.dot(self.x.T, delta2)
db1 = np.sum(delta2, axis=0)
dw2 += self.reg_lambed * w2
dw1 += self.reg_lambed * w1
w1 += -self.epsilon * dw1
b1 += -self.epsilon * db1
w2 += -self.epsilon * dw2
b2 += -self.epsilon * db2
self.model = {'w1':w1, 'b1':b1, 'w2':w2, 'b2':b2}
if print_loss and i %200 == 0:
print('Loss : ', (i, self.calculate_loss(model=self.model)))
loss.append(self.calculate_loss(model=self.model))
return loss
有使用的是softmax损失函数,对于softmax函数求导之后就是原函数-1,求w2梯度,对w2求导就只有a2了,根据刚刚的公式:
可以求出delta2,最后一次更新即可。
if __name__ == '__main__':
Accuracy = []
losses = []
x, y = Tool.generator()
for i in range(1, 13):
mlp = Network(x, y)
loss = mlp.build_Network(n_hinden=i)
losses.append(loss)
Tool.plot_decision_boundary(mlp.predict, x, y, 'Neutral Network when Hidden layer size is ' + str(i))
predicstions = mlp.predict(x)
a = sum(1*(predicstions == y)) / len(y)
Accuracy.append(a)
'''draw the accuracy picture'''
plt.plot(range(len(Accuracy)), Accuracy, c = 'blue')
plt.title('The Accuracy of the Neural Network')
plt.xlabel('Hinden Layer Size')
plt.ylabel('Accuracy')
plt.show()
'''draw the loss function picture'''
for i, loss in enumerate(losses):
plt.plot(range(len(loss)), loss, c = Tool.get_colors(i), label = 'the hindden layer size '+str(i))
plt.title('Loss Function')
plt.xlabel('time')
plt.ylabel('loss score')
plt.legend()
plt.show()
主要的运行函数。
还需要看一个画图函数:
def plot_decision_boundary(pred_func, X, y, title):
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
plt.title(title)
plt.show()
接下来运行一下看效果吧(有些颜色的代码不全,GitHub上有):
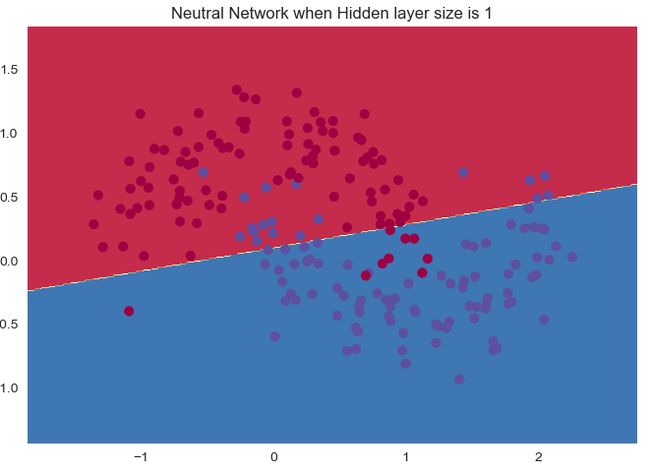
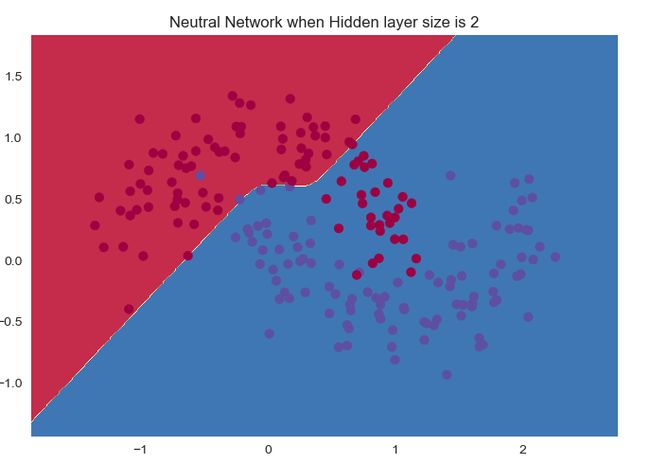
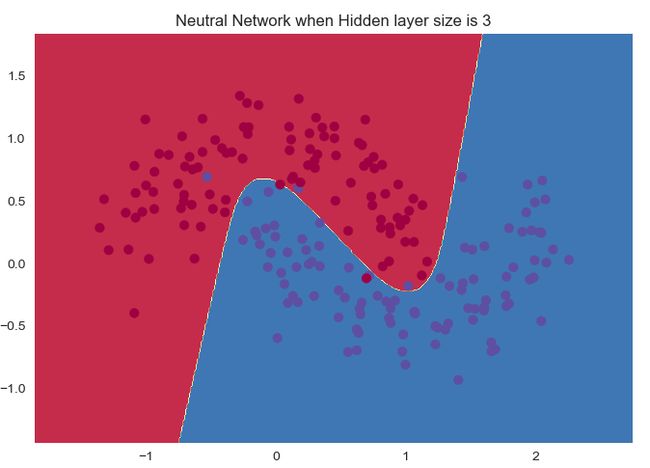
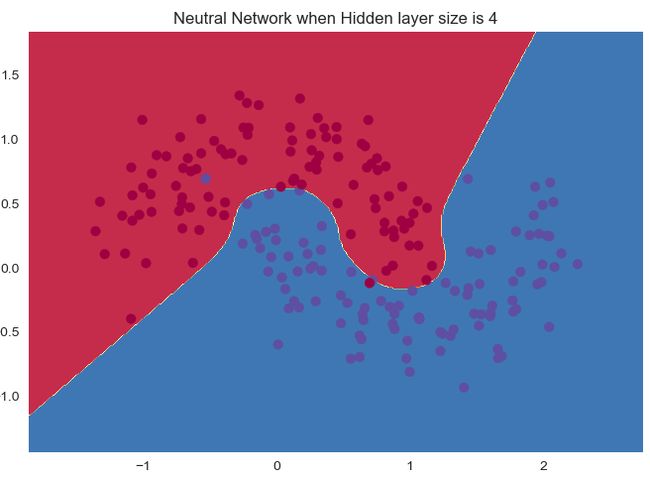
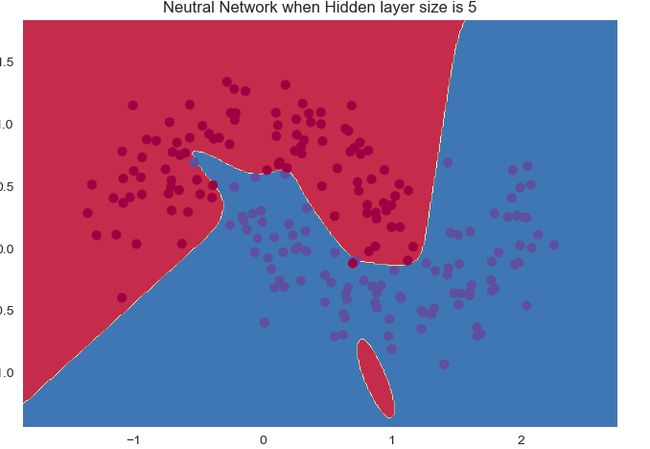
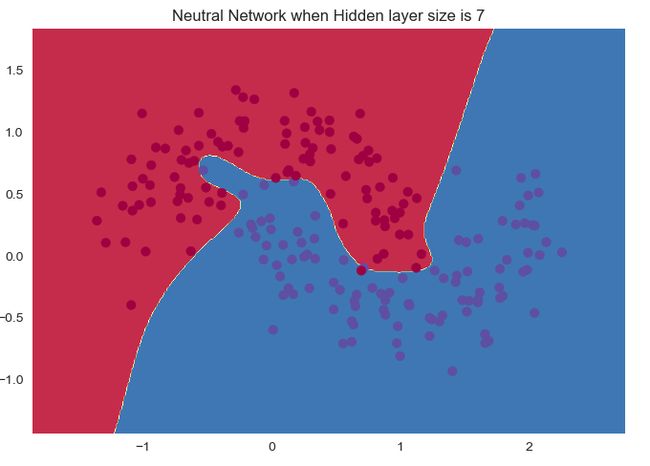
接下来的效果应该都是类似的了。
随着神经元数量的增加:
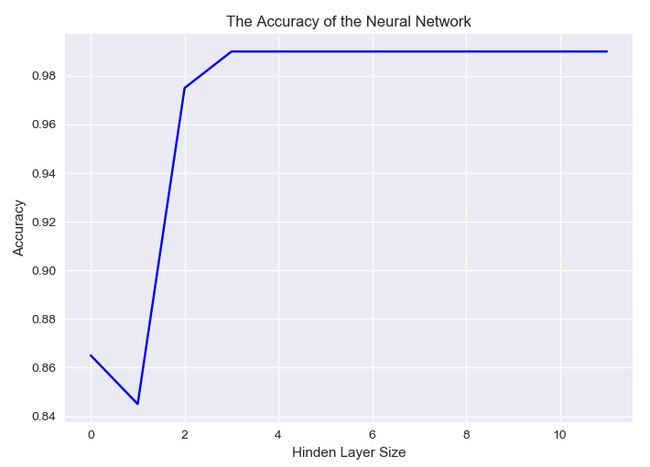
准确率是越来越高的。
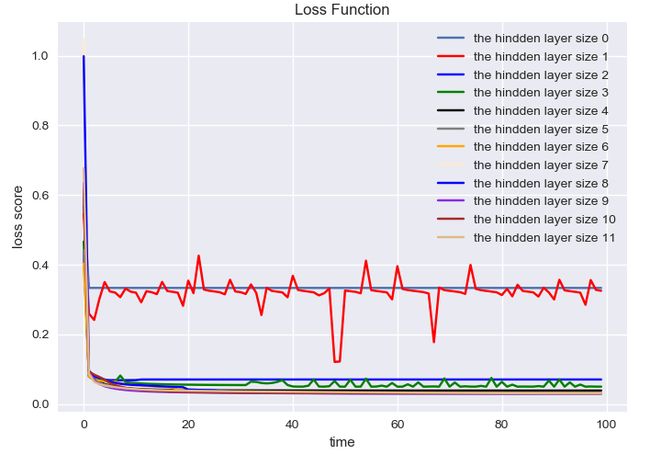
1个神经元和2个神经元的时候明显是欠拟合,后面的效果其实都变化不大。
符上所以GitHub代码:
https://github.com/GreenArrow2017/MachineLearning/tree/master/MachineLearning/NeuralNetwork