python练手漫画爬虫,代码,软件成品打包下载链接,效果图
#-*-coding:GBK -*-
import urllib.request
import lxml
import pyquery
import zlib
import winreg #操作注册表
from bs4 import BeautifulSoup
import requests
import re
import time
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
import threading #多线程
import os
from selenium.webdriver.support.select import Select
import tkinter as tk
import tkinter.messagebox as msg
from tkinter import *
import win32gui,win32api,win32con
from win32gui import *
def key360(): #获取360浏览器位置
UnInsKey360 = '360SeSES\shell\open\command'
key360 = winreg.OpenKey(winreg.HKEY_CLASSES_ROOT, UnInsKey360)
name,value,type = winreg.EnumValue(key360,0) #注册表键名,键值,数据类型
num = re.findall(r"(.+?)360se.exe",value)
num = num[0]+'360se.exe'
return(num)
def thread_it(func, *args):
'''将函数打包进线程'''
# 创建
t = threading.Thread(target=func, args=args)
# 守护 !!!
t.setDaemon(True)
# 启动
t.start()
# 阻塞--卡死界面!
# t.join()
def getlink(url): #获取漫画章节
headers = ("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
urllib.request.install_opener(opener)
def get_link(url):
file = urllib.request.urlopen(url).read()
file = file.decode('ANSI')
getlink(url)
#pattern = '(https?://[^\s)";]+(\.(\w|/)*))'
pattern_path = ('class="pic" title=\"((.*?))\"')
pattern_path_link = re.compile(pattern_path,re.S).findall(file)
pattern_path_link = list(pattern_path_link)
for pattern_path_link in pattern_path_link:
path = os.getcwd()
global file_path
file_path = path + '\\'+ str(pattern_path_link[0])
if not os.path.exists(file_path):
os.mkdir(file_path)
else:
print (file_path+' 目录已存在')
continue
global path_file1
path_file1 = pattern_path_link[0]
pattern = ('href=\"((.*?))\"')
pattern1 = re.compile('class=\"plist pmedium max-h200\".*?>(.*?)360浏览器必装,自己的360浏览器可能因为内核版本不同而停留在data页面
没做病毒免杀,安装请关掉卫士杀毒或添加白名单使用
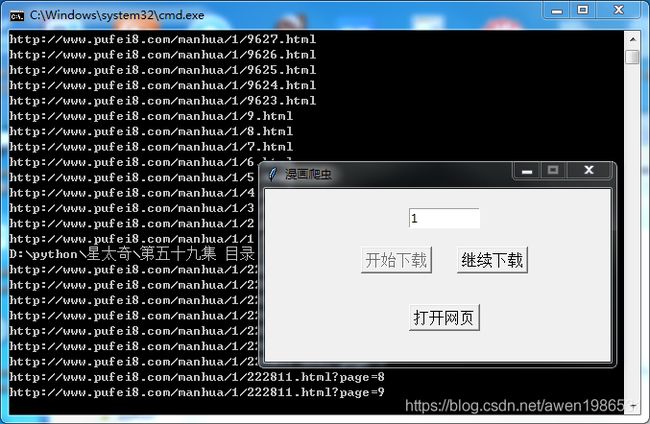
任选一部漫画 举例 http://www.pufei8.com/manhua/1/209670.html?page=14
manhua/后面的1就是要爬的整部漫画,在输入框输入即可,如果没有对应链接会报错,异常没有处理,退出重来就可以了。
漫画没有下载完整而关掉了软件可以再打开点击继续下载,这时不要点击开始下载,会清空下载进度。
这个网站有时会刷不出图片而跳过下载,只好把下载失败的图片删除重试了。
下载的漫画就生成在软件所在的目录文件夹
看图王可以对图片自动排序和跳过文件夹浏览图片非常方便和适合这种目录结构的漫画
有其他问题可以CNDS上私信我。
成品链接:https://pan.baidu.com/s/1hroQfMupsoEGGimSUQ9g_Q
提取码:cgqw