tensorflow学习笔记——summary
神经网络像一个黑盒,我们无法解释清楚单个权重或偏置对输出的影响,但如果我们可以得到权重和偏置在训练过程中的变化趋势,对它们有一个宏观认识,也是不错的。运用summary就可以实现上述目的,具体如下:
1、定义summary,如
mean=tf.reduce_mean(w1)
stddev=tf.sqrt(tf.reduce_mean(tf.square(w1-mean)))
tf.summary.scalar(‘mean’,mean)
tf.summary.scalar(‘stddev’,stddev)
tf.summary.scalar(‘max’,tf.reduce_max(w1))
tf.summary.scalar(‘min’,tf.reduce_min(w1))
2、合并summary,merged=tf.summary.merge_all()
3、生成summary,summary, _ = sess.run([merged, train], feed_dict={x:batch_xs, y:batch_ys, keep_prob:0.9})
4、生成计算图,writer=tf.summary.FileWriter(‘logs’,sess.graph)
5、将summary添加到计算图中,writer.add_summary(summary,epoch)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 获取数据集
# one_hot设置为True,将标签数据转化为0/1,如[1,0,0,0,0,0,0,0,0,0]
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)
# 定义一个批次的大小
batch_size=100
n_batch=mnist.train.num_examples//batch_size
# 变量分析
def variable_summaries(var):
with tf.name_scope('summaries'):
mean=tf.reduce_mean(var)
stddev=tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar('mean',mean)
tf.summary.scalar('stddev',stddev)
tf.summary.scalar('max',tf.reduce_max(var))
tf.summary.scalar('min',tf.reduce_min(var))
tf.summary.histogram('histogram',var) #直方图
# 定义三个placeholder
# 行数值为None,None可以取任意数,本例中将取值100,即取决于pitch_size
# 列数值为784,因为输入图像尺寸已由28*28转换为1*784
with tf.name_scope('input'):
x=tf.placeholder(tf.float32,[None,784],name='x_input')
y=tf.placeholder(tf.float32,[None,10],name='y_input')
with tf.name_scope('keep_prob'):
keep_prob=tf.placeholder(tf.float32)
# 定义学习率
with tf.name_scope('lr'):
lr=tf.Variable(0.001,dtype=tf.float32)
# 定义一个神经网络
with tf.name_scope('l1'):
# 权重初始值为0不是最优的,应该设置为满足截断正态分布的随机数,收敛速度更快
w1=tf.Variable(tf.truncated_normal([784,1000],stddev=0.1),name='w1')
# 权重分析
variable_summaries(w1)
# 偏置初始值为0不是最优的,可以设置为0.1,收敛速度更快
b1=tf.Variable(tf.zeros([1000])+0.1,name='b1')
# 偏置分析
variable_summaries(b1)
# 引入激活函数
l1=tf.nn.tanh(tf.matmul(x,w1)+b1,name='l1')
# 引入dropout
l1_drop=tf.nn.dropout(l1,keep_prob,name='l1_drop')
with tf.name_scope('l2'):
w2=tf.Variable(tf.truncated_normal([1000,100],stddev=0.1),name='w2')
variable_summaries(w2)
b2=tf.Variable(tf.zeros([100])+0.1,name='b2')
variable_summaries(b2)
l2=tf.nn.tanh(tf.matmul(l1_drop,w2)+b2,name='l2')
l2_drop=tf.nn.dropout(l2,keep_prob,name='l2_drop')
with tf.name_scope('output'):
w3=tf.Variable(tf.truncated_normal([100,10],stddev=0.1),name='w3')
variable_summaries(w3)
b3=tf.Variable(tf.zeros([10])+0.1,name='b3')
variable_summaries(b3)
# softmax的作用是将tf.matmul(l2_drop,w3)+b3的结果转换为概率值
# 假设tf.matmul(l2_drop,w3)+b3的结果为[1,5,3],转换为概率值为[0.016,0.867,0.117]
prediction=tf.nn.softmax(tf.matmul(l2_drop,w3)+b3)
# 定义损失函数
with tf.name_scope('loss'):
# 由于输出神经元为softmax,交叉熵损失函数比均方误差损失函数收敛速度更快
# loss=tf.reduce_mean(tf.square(y-prediction))
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
# loss分析
tf.summary.scalar('loss',loss)
# 定义训练方式
with tf.name_scope('train'):
# 优化器通过调整loss里的参数,使loss不断减小
# AdamOptimizer比GradientDescentOptimizer收敛速度更快
# train=tf.train.GradientDescentOptimizer(0.2).minimize(loss)
train=tf.train.AdamOptimizer(lr).minimize(loss)
# 计算准确率
with tf.name_scope('accuracy'):
# tf.argmax返回第一个参数中最大值的下标
# tf.equal比较两个参数是否相等,返回True或False
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
# tf.cast将布尔类型转换为浮点类型
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
# accuracy分析
tf.summary.scalar('accuracy',accuracy)
# 合并所有summary
merged=tf.summary.merge_all()
with tf.Session() as sess:
# 变量初始化
sess.run(tf.global_variables_initializer())
# 生成计算图
writer=tf.summary.FileWriter('logs',sess.graph)
# epoch为周期数,所有批次训练完为一个周期
for epoch in range(20):
# 调整学习率
sess.run(tf.assign(lr,0.001*(0.95**epoch)))
for batch in range(n_batch):
# 每次取出batch_size条数据进行训练
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
summary, _ = sess.run([merged, train], feed_dict={
x:batch_xs, y:batch_ys, keep_prob:0.9})
# 将summary添加到计算图中
writer.add_summary(summary,epoch)
learning_rate=sess.run(lr)
test_acc = sess.run(accuracy,feed_dict={
x:mnist.test.images,y:mnist.test.labels,keep_prob:0.9})
train_acc = sess.run(accuracy,feed_dict={
x:mnist.train.images,y:mnist.train.labels,keep_prob:0.9})
print('epoch=',epoch,' ','learning_rate=%.7f' % learning_rate,' ','test_acc=',test_acc,' ','train_acc=',train_acc)
运行结果:

########################################################################
########################################################################
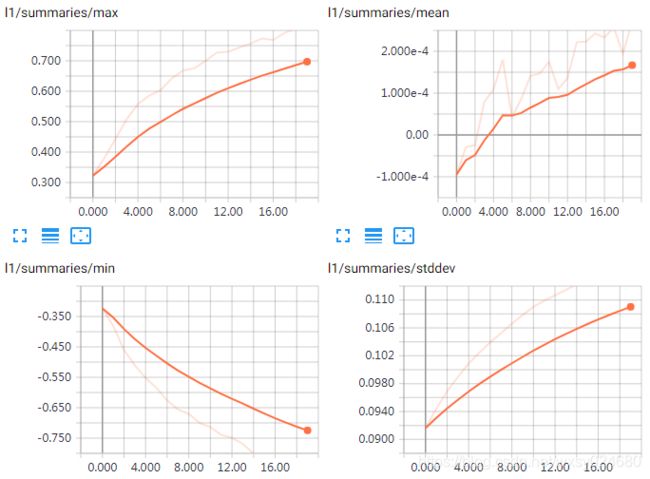
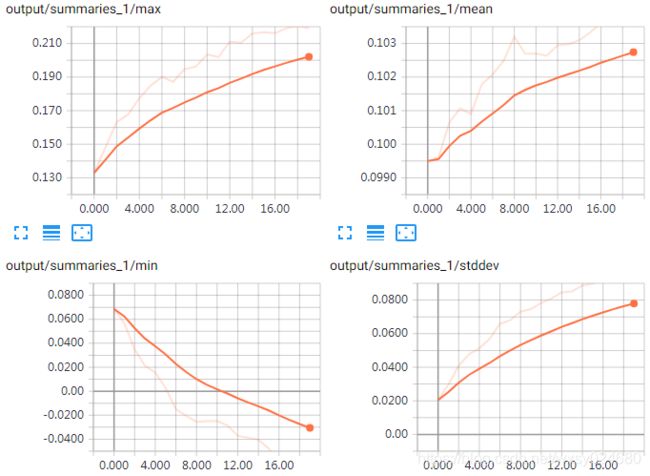
w1变化趋势:
########################################################################
########################################################################
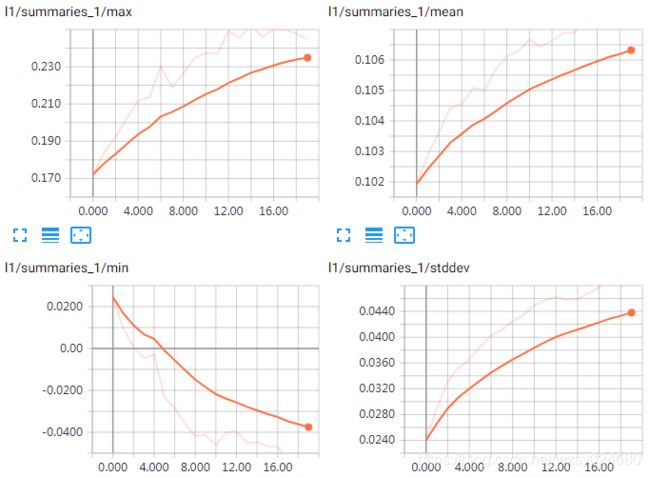
b1变化趋势:
########################################################################
########################################################################
w2变化趋势:

########################################################################
########################################################################
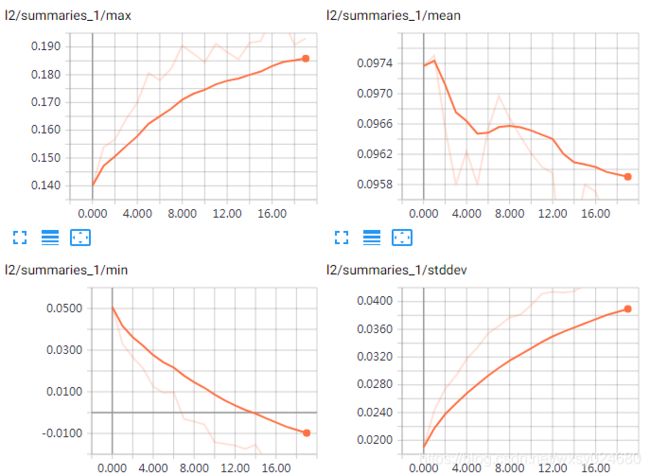
b2变化趋势:
########################################################################
########################################################################
w3变化趋势:

########################################################################
########################################################################
b3变化趋势:
loss变化趋势:

accuracy变化趋势: