Relation-Aware Graph Attention Network for Visual Question Answering阅读笔记
Abstract
这篇论文的工作以一个新的维度为中心,使用问题自适应的对象间关系丰富图像表示,以提高VQA性能。主要有以下的贡献:
1、我们提出了一种新的基于图形的关系编码器,用于通过图形注意网络学习视觉对象之间的显式和隐式关系。
2、学习到的关系是问题自适应的,这意味着它们可以动态地捕捉与每个问题最相关的视觉对象关系。
一 背景
大多数现有技术对VQA的重点在于学习图像和问题的多模态联合表示。具体而言,卷积神经网络(CNN)或基于区域的CNN(R-CNN)是通常用作图像编码的视觉特征提取器。并且递归神经网络(RNN)用于问题编码。在从视觉特征提取器获得稀疏的图像区域集合之后,多模态融合用于学习一个代表每个区域和问题之间的一致性的联合表示。然后将这种联合表示输入一个答案预测器,以产生一个答案。
事实证明,这个框架对于VQA任务很有用,但是图像和自然语言之间仍然存在着显着的语义鸿沟。
例如,给定一组斑马的图像该模型可以识别黑白像素,但不能识别哪些白像素和黑像素来自哪个斑马。因此,很难回答诸如“最右边的斑马是小斑马吗?”或“所有斑马都吃草吗?”这样的问题。VQA系统不仅需要识别对象(“斑马”)和周围环境(“草”),还需要识别图像和问题中有关动作(“吃”)和位置(“在最右边”)的语义。

本文提出了一种基于关系感知的图形关注网络(ReGAT),引入了一种新颖的关系编码器它将每个图像编码成图形,并通过图形注意机制对多种类型的对象间关系进行建模,以学习自适应问题的关系表示。
探讨了两种视觉对象关系:
(1)表示物体间几何位置和语义相互作用的显式关系
(2)捕捉图像区域间隐藏动态的隐式关系
不同类型的relation
该论文意识到,物体的视觉关系可以分为三大类:
语义关系:物体对象之间的语义依赖性,以捕捉视觉场景中的交互动态(如:
空间关系:物体对象之间的相对几何位置,以与问题中的空间描述对齐(如:< motorcycle - next to-car>)
Implicit Relation (隐式关系):以上两种关系被称为explicit relation,因为它们都是可以被明确命名的,但还有一些关系是我们无法说清楚的,却对模型正确回答问题有重要帮助,于是文章称之为implicit relation。
文章最大的动机是用不同的graph对这三种关系建模,然后综合起来。
Regat既考虑显式关系又考虑隐式关系来丰富图像表示。对于显式关系,我们的模型使用图注意网络(GAT),不是使用的简单图卷积网络(GCN)。与GCN相反,GAT的使用允许为同一邻域的节点分配不同的重要性。对于隐式关系,我们的模型通过过滤掉与问题无关的关系,而不是平等地对待所有关系,从而学习了一个适合于每个问题的图
二 ReGAT模型概述

图1:regat模型的架构。显式关系(语义关系和空间关系)和隐式关系都被考虑在内。所提出的关系编码器通过图形注意捕获问题自适应对象之间的交互。
Relation-aware Graph Attention Network
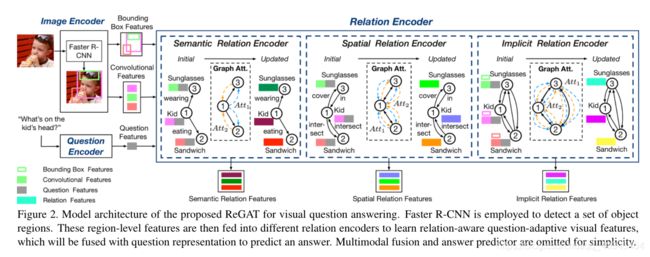
提出的用于可视化问答的ReGAT的模型架构。使用Faster R-CNN来检测一组目标区域。这些区域级特征然后被馈送到不同的关系编码器以学习关系感知的问题自适应视觉特征,其将与问题表示融合以预测答案。
下面介绍图2中各个部分:
对于图像编码器,使用Faster R-CNN用于识别一组对象![]() 其中每个对象vi与视觉特征向量vi∈Rdb和边界框特征向量bi∈Rdb存在密切关联。(k=36,dv=2048,db=4)。每个bi=[x,y,w,h]对应于一个四维空间坐标,其中(x,y)表示边框左上角的坐标,h/w对应于边框的高度/宽度。
其中每个对象vi与视觉特征向量vi∈Rdb和边界框特征向量bi∈Rdb存在密切关联。(k=36,dv=2048,db=4)。每个bi=[x,y,w,h]对应于一个四维空间坐标,其中(x,y)表示边框左上角的坐标,h/w对应于边框的高度/宽度。
关于问题编码器,我们使用具有门控循环单元(GRU)的双向RNN,生成问题嵌入(dq=1024)。
三 图构造
Fully-connected Relation Graph
通过将图像中的每个对象vi视为一个顶点,我们可以构造一个完全连通的无向图
![]()
其中 E是K×(K-1)边集。每个边表示两个对象之间的隐式关系,这两个对象可以通过图注意分配给每个边的学习权重来反映。所有的权重都是在事先不知情的情况下隐式学习的。我们将建立在此图形上的关系编码器命名为隐式关系编码器。
Pruned Graph with Prior Knowledge
基于先验知识的剪枝图。 如果顶点之间存在显式关系,则通过修剪不存在对应显式关系的边,可以将完全连接的图Gimp变换成显式关系图。
对于每对对象i,j,如果是有效关系,则从i到j创建一个边,并使用边标签p。以这种方式,图形变得稀疏,并且每个边缘对图像中的一个对象间关系进行先验知识编码。我们将建立在此图上的关系编码器命名为显式关系编码器。
这些特征的显式性质要求预先训练的分类器以离散类标签的形式提取关系,它们代表了肉眼可见的物体之间的动态和交互。我们探索了两个实例:空间图和语义图。
Spatial Graph
spai,j =
上述公式表示空间关系,代表物体i相对于物体j的相对几何位置的空间关系。我们将spai,j划分为11类位置关系和一个无关系类。
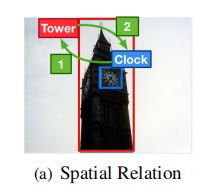
由于空间关系形成的边是对称的:< object i - Pi,j - object j >是有效的空间关系,则必须存在有效的空间关系
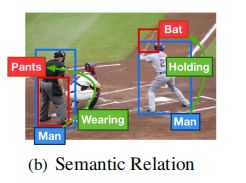
Semantic Graph
为了构建语义图,需要提取对象之间的语义关系。语义关系可以表示为:
![]()
给定两个对象区域 i 和 j ,目标是确定哪个谓词p表示这两个区域之间的语义关系。 这里,对象j与对象i之间的关系不可互换,这意味着由语义关系形成的边不对称。对于有效的在我们的定义中是不存在的关系。
例如 man-holding-bat是一个有效的关系,而从bat到man之间没有语义关系。
Relation Encoder
问题自适应图注意
所提出的关系编码器设计用于编码图像中对象之间的关系动态。对于VQA任务,可能有不同类型的关系对不同类型的问题有用。因此,在关系编码器的设计中,我们采用了一种问题自适应注意机制,将问题中的语义信息注入到关系图中,动态地为那些与每个问题相关的关系分配更高的权重。这是首先通过将问题嵌入q与K个视觉特征vi连接起来实现的,表示为
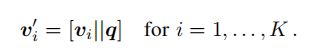
然后在顶点上执行自注意力,这会生成隐藏的关系特征![]()
这个特征描述目标对象及其邻近对象之间的关系。在此基础上,每个关系图都经过以下注意机制:
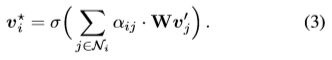
对于不同类型的关系图,注意系数αi j的定义各不相同,投影矩阵W∈Rdh×(dq+dv)和物体i的邻域Ni它们的注意系数也是不同。σ(•)是像relu这样的非线性函数。为了稳定自我关注的学习过程,我们还利用多头注意扩展了上述图的注意机制,其中执行M个独立的注意机制,并将它们的输出特性连在一起,结果产生以下输出特性表示:
最后将Vi* 添加到原始视觉特征vi中,作为最终的关系感知特征。
Implicit Relation (隐式关系)
由于学习隐式关系的图形是完全连接的,所以Ni 包含图像中的所有对象,包括对象i本身。我们设计了注意权重αi j如下:
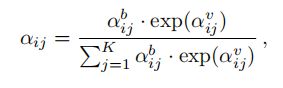
公式分母是对分子的归一化,重点看分子。αi j不仅取决于视觉特征权重avij 而且还取决于边界框权重abij。他们各自的求法如下:
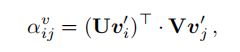
U,V∈Rdh×(dq+dv)是投影矩阵。把原始矩阵映射到子空间中,然后通过点积来衡量两个object视觉特征的相似性。 abij测量任意一对区域之间的相对几何位置:
![]()
首先,fb将objecti和objectj之间的几何特征映射到高维空间, 为了使它对平移和缩放变换保持不变性,使用一个4维的相对几何特征,即: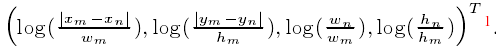
(上述得到的相对位姿就是平移和尺度不变了的)这个4维特征被嵌入到一个高维(dh=64)的表示中,它计算不同波长的余弦和正弦函数。
语义关系编码器 由于语义图Esem中的边缘现在包含了标签信息并且是定向的,我们在公式(3)中设计了注意力机制,使其对方向性(vi-to vj,vj-to-vi和vi-to-vi)和标签敏感。
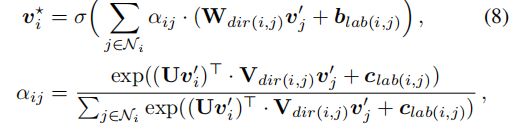
W,V是变换矩阵,dir(i,j)选择变换矩阵每个边的方向性,lab(i,j)表示每条边的标签。
因此,在通过上述图的注意机制编码所有区域![]() 之后,重新细化的区域级特征
之后,重新细化的区域级特征![]() 被赋予了对象之间的先前语义关系。
被赋予了对象之间的先前语义关系。
相对于图卷积网络,这种图形注意机制有效地将不同的权重分配给同一邻域的节点。结合问题自适应机制,学习到的注意力权重可以反映哪些关系与特定问题相关。
Multimodal Fusion and Answer Prediction多模态融合和答案预测
在获得关系感知的视觉特征之后,我们希望通过多模型融合策略将问题信息q与每个视觉表示v*i 融合在一起。由于我们的关系编码器保留了视觉特征的维数,因此可以将其与现有的任何多模式融合方法结合起来学习联合表示J:![]()
f是一种多模态融合方法,Θ是融合模块的可训练参数。
对于答案预测器,我们采用两层多层感知器(MLP)作为分类器,以联合表示J作为输入。使用二元交叉熵作为损失函数。
在训练阶段,不同的关系编码器是独立训练的。在推理阶段,我们将三个图形关注网络与预测的答案分布的加权和组合起来。具体而言,最终回答分布由以下计算: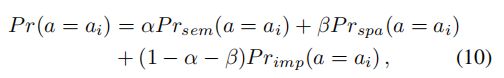
其中α和β是交换的超参数(0 ≤ α + β ≤ 1, 0 ≤ α, β ≤ 1).。Prsem(a=ai)、Prspa(a=ai)和Primp(a=ai)分别表示经过语义、空间和隐式关系训练的模型答案ai的预测概率。
四 实验
提供VQA2.0和VQA-CPv2数据集的实验结果。通过设计,关系编码器可以作为即插即用组件组成不同的vqa体系结构。在实验中,我们考虑了三种常用的VQA模型,它们采用不同的多模态融合方法: Bottom-upTop-down(BUTD), Multimodal Tucker Fusion(MUTAN), and Bilinear Attention Network (BAN).
表1不同融合方法对VQA2.0验证集的性能:

表2 VQA-CP v2基准的模型精度:
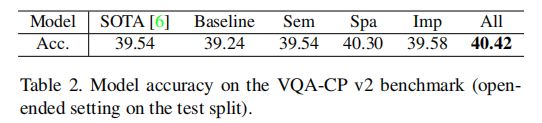
表3 VQA 2.0基准的模型精度:
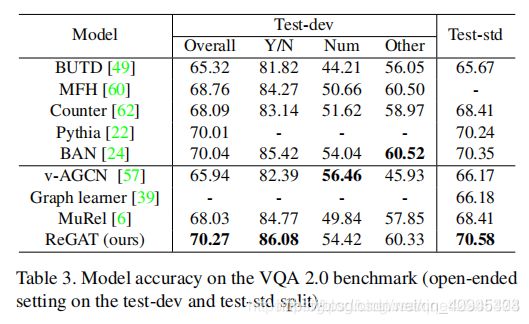
表4用于消融研究的VQA2.0验证集的性能研究:

为了更好地说明添加图形注意和问题自适应机制的有效性,我们进行了可视化的消融实验。将完全ReGAT模型在单一关系设置下学习到的注意图与两个消融模型学习到的注意图进行了比较,如下图:
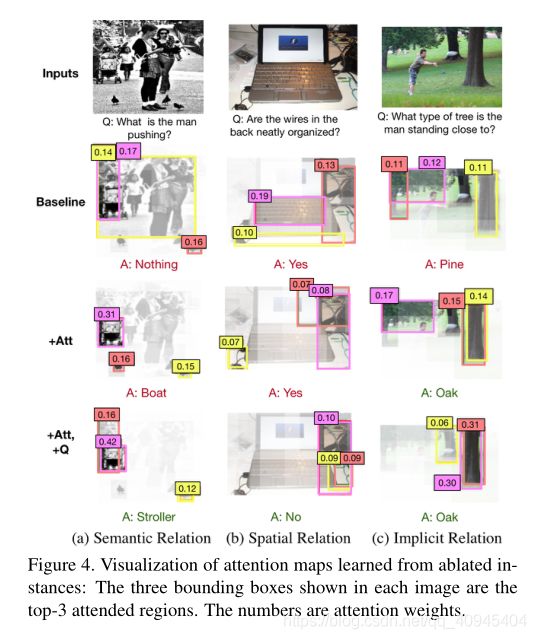
每个图像中显示的三个边界框是前3个关注区域。图中数字是注意力权重。
如图4所示,第二行、第三行和最后一行分别对应于表4中的第1行、第3行和第4行。将第2行与第3行进行比较,可以观察到图形注意力有助于捕捉对象之间的交互,这有助于图像区域和问题之间更好的对齐。第3行和第4行显示,添加问题适应性注意机制会产生更清晰的注意图,并聚焦于更相关的区域。这些可视化结果与表4中报告的定量结果一致。
五 总结
本文提出了一种新的视觉问答框架——关系感知图注意网络(ReGAT),用问题自适应注意机制来建模多类型对象关系。ReGAT利用两种类型的视觉对象关系:显式关系和隐式关系,通过图形注意学习关系感知区域表示。我们的方法在VQA 2.0和VQA-CP v2数据集上都获得了最新的结果。提出的ReGAT模型与通用VQA模型兼容。在两个VQA数据集上的综合实验表明,我们的模型可以以即插即用的方式注入到最先进的VQA体系结构中。对于未来的工作,我们将研究如何更有效地融合这三种关系,以及如何利用每种关系来解决特定的问题类型。