Flink面试时陷阱广播变量与累积加器的区别……
要说当代大数据最火最热的计算框架,那非Flink莫属了,当前如果你要从事大数据开发工作,Spark、Flink主流大数据计算框架,是每个大数据程序员必备的技能,可以说你不会Spark、Flink几乎是寸步难行,重要性就如同java开发中的Spring全家桶套餐。
Flink中有两个概念,很可能会被你忽略,Flink Broadcast和Accumulators的区别。而且面试官也会经常问,以此来评估你Flink的基础是否牢固程度。
Flink广播变量,使用广播变量的好处:每个节点的executor有一个副本,不是每个task有一个副本,可以优化资源提高性能。是将一个公用的小数据集通过广播变量,发送到每个TaskManager中,作为公共只读变量使用,供每个task共享使用,以减少复制变量到每个task的次数,降低资源开销,从而提高性能。
注意事项:
1.不能将一个RDD使用广播变量广播出去
2.广播变量只能在Driver端定义,不能在Executor端定义
3.在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值
累加器:累加器可以在各个executor之间共享,修改,需要注意,累加器只能在Driver端定义赋予初始值,只能在在Driver端读取,在 Excutor 端更新。Flink现有的内置累加器为以下几个:
IntCounter
LongCounter
DoubleCounter
我们通过一个例子来具体看累加器的使用,核心代码如下:
def main(args: Array[String]): Unit = {
//获取执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data = env.fromElements("a","b","c","d")
val res = data.map(new RichMapFunction[String,String] {
//1:定义累加器
val numLines = new IntCounter
override def open(parameters: Configuration): Unit = {
super.open(parameters)
//2:注册累加器
getRuntimeContext.addAccumulator("num-lines",this.numLines)
}
var sum = 0;
override def map(value: String) = {
//如果并行度为1,使用普通的累加求和即可,但是设置多个并行度,则普通的累加求和结果就不准了
sum += 1;
System.out.println("sum:"+sum);
this.numLines.add(1)
value
}
}).setParallelism(1)
// res.print();
res.writeAsText("d:\\data\\count0")
val jobResult = env.execute("BatchDemoCounterScala")
// //3:获取累加器
val num = jobResult.getAccumulatorResult[Int]("num-lines")
println("num:"+num)
}
上面例子是设置了并行度为1的情况下,可是使用普通累加求和,下面我们来撸一个并行度不为1的,本例将通过读取系统中的文件,计算含有:“一点IT技术” 的行数是多少。数据如下
核心代码如下:
def main(args: Array[String]): Unit = {
//获取flink运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val text = env.readTextFile("d:/flink.txt")
val result: DataSet[String] = text.map(
new RichMapFunction[String, String] {
//1.创建累加器
val intCounter = new IntCounter()
override def open(parameters: Configuration): Unit = {
//2:注册累加器
getRuntimeContext.addAccumulator("myAccumlator", intCounter)
}
override def map(value: String): String = {
if (value.contains("一点IT技术")) {
//3使用累加器
intCounter.add(1)
}
value
}
})
result.writeAsText("d:/result.txt",WriteMode.OVERWRITE)
val counter = env.execute("counter")
//4:获取累加器结果
val counterResult = counter.getAccumulatorResult[Int]("myAccumlator")
println("counterResult: " + counterResult)
}
上面代码的输出结果为:
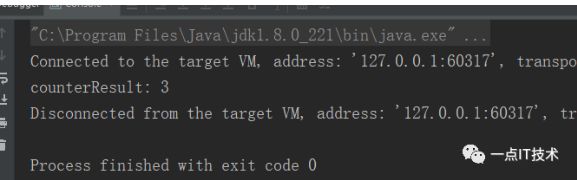
通过上面两个例子,我们可以总结出累加器的使用步骤:
1、创建累加器
2、注册累加器
3、使用累加器
4、获取累加器的结果
广播变量与累加器的区别在于:
广播变量只能在Driver端定义,不能在Executor端定义,在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值
累加器只能在Driver端定义赋予初始值,只能在在Driver端读取,在 Excutor 端更新
如果觉得还不错的话,就尽情的转发分享吧。关注更多内容,欢迎关注公众号:一点IT技术,进入公众号联系我们,更可以参与到共同读者的讨论中哦!
你的转发和分享是对作者最大的肯定和动力