如今,物联网(IoT)、社交媒体、应用程序、以及分析设备,都在持续产生着各种类型的海量数据。而我们的业务系统需要每天接收各种大数据,并完成各项处理任务。因此,在日常处理这些持续增长的数据时,数据系统会面临延迟和准确性两个方面的挑战。
Lambda架构的介绍
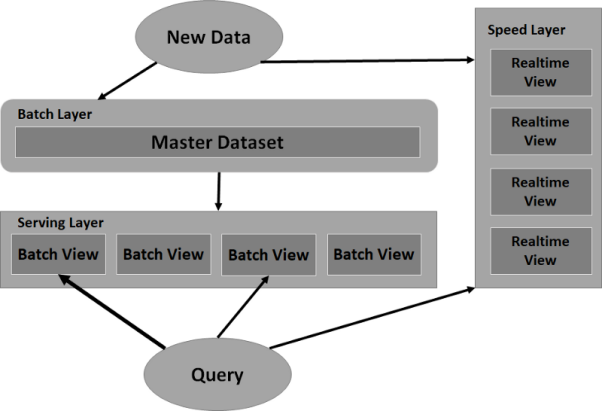
针对上述挑战,Nathan Marz和James Warren于2015年首发了Lambda体系架构。它在逻辑上将数据系统分为三个层面,即:批处理(batch)层、速度(speed)层和服务(serving)层。而作为一种大数据的范例,它可以让用户通过构建数据系统,以克服上述数据延迟与准确性等问题。
由于Lambda体系架构可以被水平扩展,因此如果您的数据集过大,或所需的数据视图过多,则可以通过添加更多的主机来参与处理。不过,Lambda会将系统中最复杂的部分,限制在速度层中。而由于该层面的输出是临时的,因此如果您需要对数据进行改进或校正,则可以每隔几小时清空一次。
Lambda体系架构的工作原理
- Lambda体系架构的第一层--批处理层 ,既可以存储整个数据集,又能够计算出批处理的视图。由于此处的存储数据集不可被改变,因此只能被追加。也就是说,新的数据会不断地被传入,而原有旧的数据则会始终保持不变。同时,批处理层会通过对整个数据集的查询,或功能性计算,得出各种视图。查询这些视图时,我们虽然可以在整个数据集中低延迟地找到答案,但是其缺点是系统需要花费大量的时间,来进行计算。
- Lambda体系架构的第二层--服务层,能够批量加载视图。与传统数据库相似,它通过对视图的只读查询操作,来提供低延迟的响应。一旦批处理层准备好一组新的视图,服务层就会将当前已过时的批处理视图予以替换。
- 流到批处理层的数据,同样也会流入Lambda体系架构的第三层--速度层。其主要区别在于,尽管批处理层从开始就保留了所有数据,但是速度层仅关心从最后一批视图完成以来到达的数据。也就是说,速度层通过处理那些批处理视图尚未计入的最新数据查询,来弥补计算视图时的高延迟。具体原理如下图所示:
比方说明三个层面
为了更好地理解上述概念,让我们来打个比方:在一位老人的豪宅里,每个房间都有一个时钟。但是,除了厨房里的时钟外,其他时钟都是不准的。他需要以厨房里的时钟为基准去校准其他时钟。不过,由于记忆力差,他必须将厨房时钟上的当前时间(上午9:04)记在一张纸上。然后,他以缓慢的步伐走向各个房间,将所有时钟设定为上午9:04。而当他最后到达东厢房时,实际时间已经是上午9:51了。显然,他后续在各个房间时钟上设置的上午9:04,都是错误。
同理,如果数据系统只有批处理层,那么我们就会遇到类似的问题—由于需要花费一段时间才能得到某个问题的答案,因此该答案对于持续涌入的数据并非最新。
让我们回到刚才的例子,幸亏这位老人手上有一只秒表。次日上午9:04,他同样从厨房开始,在一张纸上记下时间,并启动秒表(也就是他的“速度层”)。当最后到达东厢房时,他的秒表上显示为“47分16秒”。通过基本数学计算,他可以知道当前的时钟应该被设置为9:51 AM。
在上述类比中,老人是服务层,其豪宅里各个房间的时钟随处可以显示当前时间的批处理视图。当然,他通过触发秒表,让批处理视图会与速度层同步,以获得最准确的答案。
为什么要使用Lambda体系架构?
在Marz和Warren有关Lambda架构的开创性著作--《大数据》中,他们列出了大数据系统中的八个理想属性,也描述了Lambda架构如何去满足每一种属性:
- 鲁棒性和容错能力。由于批处理层被设计为追加式,即包含了自开始以来的整体数据集,因此该系统具有一定的容错能力。如果任何数据被损坏,该架构则可以删除从损坏点以来的所有数据,并替换为正确的数据。同时,批处理视图也可以被换成完全被重新计算出的视图。而且速度层可以被丢弃。此外,在生成一组新的批处理视图的同时,该架构可以重置整个系统,使之重新运行。
- 可扩展性。Lambda体系架构的设计层是作为分布式系统被构建的。因此,通过简单地添加更多的主机,最终用户可以轻松地对系统进行水平扩展。
- 通用性。由于Lambda体系架构是一般范式,因此用户并不会被锁定在计算批处理视图的某个特定方式中。而且批处理视图和速度层的计算,可以被设计为满足某个数据系统的特定需求。
- 延展性。随着新的数据类型被导入,数据系统也会产生新的视图。数据系统不会被锁定在某类、或一定数量的批处理视图中。新的视图会在完成编码之后,被添加到系统中,其对应的资源也会得到轻松地延展。
- 按需查询。如有必要,批处理层可以在缺少批处理视图时,支持临时查询。如果用户可以接受临时查询的高延迟,那么批处理层的用途就不仅限于生成的批处理视图了。
- 最少的维护。Lambda架构的典型模式是:批处理层使用Apache Hadoop,而服务层使用ElephantDB。显然,两者都很容易被维护。
- 可调试性。Lambda体系架构通过每一层的输入和输出,极大地简化了计算和查询的调试。
- 低延迟的读取和更新。在Lambda体系架构中,速度层为大数据系统提供了对于最新数据集的实时查询。
Lambda体系架构的缺点
事物往往都有两面性,Lambda架构除了具有上述优点,也存在着如下缺点:
- 由于所有数据都是被追加进来,并且批处理层中的任何数据都不会被丢弃,因此系统的扩展成本必然会随着时间的推移而增长。
- 如前文所述,批处理层可使用Hadoop或Snowflake,而速度层则可以使用Storm或Spark。显然,这两层虽然运行同一组数据,但是它们是在完全不同的系统上构建的。因此,用户需要维护两套相互独立的系统代码。这样不但复杂,而且极具一定的挑战性。
机器学习中的Lambda架构
在机器学习领域,数据量无疑是多多益善的。但是,对于机器学习应用算法、以及检测模式而言,它们需要以一种有意义的方式,去接收数据。因此,机器学习可以受益于由Lambda架构构建的数据系统,所处理的各类数据。据此,机器学习算法可以提出各种问题,并逐渐对输入到系统中的数据进行模式识别。
物联网的Lambda架构
如果说机器学习利用的是Lambda架构的输出,那么物联网则更多地使用到了数据系统的输入。设想一下,一个拥有数百万辆汽车的城市,每辆汽车都装有传感器,并能够发送有关天气、空气质量、交通状况、位置信息、以及司机驾驶习惯等数据。这些海量数据流,会被实时馈入Lambda体系架构的批处理层和速度层,进行后续处理。可以说,物联网设备是合理使用大数据源的绝佳示例。
流处理和Lambda架构挑战
速度层也被称为“流处理层”。其目标是提供最新数据的低延迟实时视图。虽说,速度层仅关心,自完成最后一组批处理视图以来导入的数据,但事实上它不会存储这些小部分的数据。这些数据在流入时就会被立即处理,且在完成后被立即丢弃。因此,我们可以认为这些数据是尚未被批处理视图所计入的数据。
Lambda体系架构在其原始理论中,提到了“最终精度(eventual accuracy)”的概念。它是指:批处理层更关注精确计算,而速度层则关注近似计算。此类近似计算最终将由下一组视图所取代,以便系统向“最终精度”迈进。
在实际应用中,由实时处理流以毫秒为单位,持续产生的用于更新视图的数据流,是一个非常复杂的过程。在此,我建议您将基于文档的数据库、索引、以及查询系统配合在一起使用。
Lambda架构和Kappa架构之间的差异
如上所述,由于Lambda体系架构的批处理层和速度层分属不同的分布式系统,我们需要为相似的处理方式,维护两个单独的代码库。而Kappa架构则通过完全删除批处理层,来解决该问题。
具体而言,Kappa使用单个流处理层,既通过最新的数据计算来产生实时视图,又对所有数据进行计算,以产生批处理视图。就整个数据集而言,它以追加日志的形式保持原有数据不变,并且保证数据能够快速地流过系统,以产生具有精确计算的视图。同时,来自Lambda架构的原始“速度层”任务,也会被保留在Kappa 架构中,并持续为低延迟的视图提供近似计算。据此,这种为单个系统生成视图的方式,大幅简化了系统的代码库。
通过Heroku上的容器实现Lambda体系架构
通过使用Docker,我们可以轻松地在启动和试验阶段,完成对Lambda架构所需的各种工具的协调和部署。例如,我们可以使用基于容器的云平台即服务(PaaS)--Heroku,来部署和扩展应用程序。对于批处理层,您可以使用Apache Hadoop来部署一个Docker容器;针对速度层,您可以考虑部署Apache Storm或Apache Spark;而对于服务层,您可以为Apache Cassandra或MongoDB部署Docker容器,并通过Elasticsearch来进行索引和查询。
结论
综上所述,Lambda架构之类的范例具有一定的扩展性和鲁棒性。随着大量数据流不断地被导入数据系统,批处理层提供了高延迟的精度,而速度层提供了低延迟近似值。同时,速度层通过协调两种视图,来为查询提供最佳的响应。当然,使用Lambda架构来实施数据系统并非易事,我们往往需要借助适当的工具,来实现部署与构建。