python+opencv实现机器视觉基础技术(2)(宽度测量,缺陷检测,医学处理)
本篇博客接着讲解机器视觉的有关技术和知识。包括宽度测量,缺陷检测,医学处理。
一:宽度测量
在传统的自动化生产中,对于尺寸的测量,典型的方法就是千分尺、游标卡尺、塞尺等。而这些测量手段测量精度低、速度慢,无法满足大规模的自动化生产需求。基于机器视觉的尺寸测量属于非接触式的测量,具有检测精度高、速度快、成本低、安装简便等优点。可以检测零件的各种尺寸,如长度、圆、角度、线弧等测量。
利用python+opencv方法可以进行宽度的测量。步骤是先选取出一个矩形,然后进行阈值分割,再进行反色,边缘提取之后进行点的选择,输出坐标做出两条线段,根据线段进行矩形绘制,这样之后就可以计算两条直线之间的距离,也就是我们需要求得的宽度。
OpenCV是一个c++库,用于实时处理计算机视觉方面的问题,涵盖了很多计算机视觉领域的模块。配合python调用c++库,可以很方便地进行宽度测量,实现要求。
步骤如下:
1.导入需要的库
import cv2
import cv2 as cv
import numpy as np
import imutils
2.读取原图像查看
img = cv2.imread("1.jpg")

3.截取部分图像
手动地进行选取我们感兴趣的部分,然后截取出来。
img = imutils.resize(img, width=500)
roi = cv2.selectROI(windowName="image1", img=img, showCrosshair=True, fromCenter=False)
x, y, w, h = roi
cv2.rectangle(img=img, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 255), thickness=2)
s = img[y:y+h,x:x+w]

4.反色
截取后会出现空白区域很多黑色的情况,需要进行反色,用到的方法是255去除值。
# 反色
def colorReverse(src):
height, width, channels = src.shape
for row in range(height):
for list in range(width):
for c in range(channels):
pv = src[row, list, c]
src[row, list, c] = 255 - pv
return src
src = colorReverse(s)
5.边缘检测去噪
x = cv2.Sobel(src,cv2.CV_16S,1,0)
y = cv2.Sobel(src,cv2.CV_16S,0,1)
absX = cv2.convertScaleAbs(x) # 转回uint8
absY = cv2.convertScaleAbs(y)
dst = cv2.addWeighted(absX,0.5,absY,0.5,0)
result = colorReverse(dst)
6.输出鼠标选择点的坐标
之后进行的操作是利用鼠标选择点,并显示坐标,可以判断时候用鼠标进行点击操作,如果是的话,就可以输出点的坐标在输出框或者图片上标记,把点击函数作为参数,就可以在不点击退出键的时候进行循环递归操作,知道最直到获得想要点的坐标。
# 输出鼠标选择点的坐标
# setMouseCallback使用的回调函数,这个回调函数在捕获到鼠标左键点击事件时,就在图片上点击处绘制一个实心的圆、并显示出坐标。
def on_EVENT_LBUTTONDOWN(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
xy = "%d,%d" % (x, y)
print (xy)
cv2.circle(result, (x, y), 1, (255, 0, 0), thickness = -1)
cv2.putText(result, xy, (x, y), cv2.FONT_HERSHEY_PLAIN,
1.0, (0,0,0), thickness = 1)
cv2.imshow("image2", result)
cv2.namedWindow("image2")
cv2.setMouseCallback("image2", on_EVENT_LBUTTONDOWN)
cv2.imshow("image2", result)
7.绘制线段用输出提示
接下来就可以根据选择的四个点进行连接输出线段,用get_len()方法可以得到两条线之间的距离。
# 绘制线段
s = cv2.line(result,(3, 30), (120, 30), (0, 255, 0), 2)
d = cv2.line(result,(3, 110), (118, 110), (0,255, 0), 2)
lens = s.get_len() - d.get_len()
# 输出图形
text = "宽为:{0}".format(lens)
cv.putText(result, text, (20, 20), cv.FONT_HERSHEY_COMPLEX, 2.0, (0, 255, 0), 1)


二:缺陷检测
缺陷检测通常是指对物品表面缺陷的检测,表面缺陷检测是采用先进的机器视觉检测技术,对工件表面的斑点、凹坑、划痕、色差、缺损等缺陷进行检测。
人工检测是产品表面缺陷的传统检测方法,该方法抽检率低、准确性不高、实时性差、效率低、劳动强度大、受人工经验和主观因素的影响大,而基于机器视觉的检测方法可以很大程度上克服上述弊端。
缺陷检测被广泛使用于布匹瑕疵检测、工件表面质量检测、航空航天领域等。传统的算法对规则缺陷以及场景比较简单的场合,能够很好工作,但是对特征不明显的、形状多样、场景比较混乱的场合,则不再适用。近年来,基于深度学习的识别算法越来越成熟,许多公司开始尝试把深度学习算法应用到工业场合中。
视觉表面缺陷检测系统基本组成主要包括图像获取模块、图像处理模块、图像分析模块、数据管理及人机接口模块。
这里是用python+opencv进行津彩啤酒的图片缺陷检测,将0.bmp图片进行样本,和其他图片进行对比,检测是否合格。通过对比原图和要比较的图像的24位灰度图像进行检测。
步骤如下:
1.导入需要的库
import cv2
import cv2 as cv
import numpy as np
from PIL import Image, ImageDraw, ImageFont
2.比较
读入我们0.bmp图像作为比较因子,设置为rgbimage_std变量
rgbimage_std = cv.imread("0.bmp")

3.转换
将24位rgbimage_std彩色图像转换为8位rgb2grayimage_std灰度图像
rgb2grayimage_std = cv2.cvtColor(rgbimage_std, cv2.COLOR_RGB2GRAY)

4.循环
缺陷检测算法循环六次。
imagename = str(i) + '.bmp'
rgbimage_defect = cv.imread(imagename)
# 将每次imagename对应图像在图像窗口显示出来
# cv.imshow(imagename, rgbimage_defect)
# 将24位rgbimage_defect彩色图像转换8位rgb2grayimage_defect灰度图
gray = np.array(rgbimage_defect)
gray = gray[:,:,0]
rgb2grayimage_defect = np.array([gray,gray,gray])
rgb2grayimage_defect = np.transpose(rgb2grayimage_defect,(1,2,0))
name = str(i) + '_rgb2grayimage_defect.bmp'
# cv.imshow(name, rgb2grayimage_defect)
# 缺陷比较
# 直方图计算的函数,反应灰度值的分布情况
be_compare_image = cv2.calcHist([rgb2grayimage_std], [0], None, [256], [0.0,255.0])
compare_image = cv2.calcHist([rgb2grayimage_defect], [0], None, [256], [0.0,255.0])
#相关性计算,采用相关系数的方式
# result = cv2.compareHist(be_compare_image,compare_image,method=cv2.HISTCMP_CORREL)
result = sum(be_compare_image - compare_image)[0]
# 打开PIL创建的图像
ss = Image.open(str(i) + ".bmp")
# 创建一个操作对象
draw = ImageDraw.Draw(ss)
# 字体对象为simsun,字大小为50号
fnt = ImageFont.truetype(r'C:\Windows\Fonts\simsun.ttc', 50)
# 如果图片对比原图相似度小于7,则合格;否则不合格。
if result < 7:
draw.text((5, 10), u'合格', fill='red', font=fnt)
th_str = str(i) + '.bmp'
draw.text((5, 350), th_str, fill='red', font=fnt)
else:
draw.text((5, 10), u'不合格', fill='red', font=fnt)
th_str = str(i) + '.bmp'
draw.text((5, 350), th_str, fill='red', font=fnt)
ss.show("result" +str(i) + ".png")








5.结束代码
cv.waitKey(0)
三:医学检测
医学信息处理,即对医学信息的处理,医学信息处理过程中借助计算机技术,具有非常高的应用价值,在提高信息处理准确度的同时,也极大地增强了信息处理的效率,为广大患者与患者家属创造更为人性化的就医环境。
利用计算机的先进技术可以对医学图像进行处理,然后更加方便地得到图片上蕴含的信息,从而进行正快速地得到我们想要得到的信息。
这里是用python+opencv进行医学图像识别,借助计算机技术帮助医生对医学图像进行有效地分析。
步骤如下:
1.导入库
from skimage import data,color,morphology
import cv2 as cv
import cv2
2.读入灰度图
img1 = cv.imread('vas0.bmp',0)
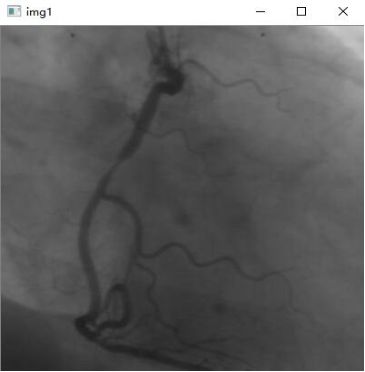
3.反色
img3 = img2.copy()
cv2.threshold(img2,80,255,0,img2)
for i in range(0,img2.shape[0]):
for j in range(0,img2.shape[1]):
img3[i,j] = 255-img2[i,j]
或者如下代码:
# 对img2图像图像进行反色,得到img3图像
def access_pixels(image):
height, width, channels = image.shape
for row in range(height):
for list in range(width):
for c in range(channels):
pv = image[row, list, c]
image[row, list, c] = 255 - pv
return image
img3 = access_pixels(img2)


4.扩展
img4 = cv2.copyMakeBorder(img3,50,50,50,50,cv2.BORDER_REFLECT)

5.去噪
去除噪声位置地小面积区域,可以有两种方式,一种是选择满足面积150-10000的img4图像输出,去除噪声位置元素,另一种是使用Skimage中的形态学处理来进行孤立小区域的去除。
img5 = morphology.remove_small_holes(img4, 100)
或者如下代码:
contours,hierarchy = cv2.findContours(img4, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
#消除小面积
for i in range(len(contours)):
area = cv2.contourArea(contours[i])
if area < 150:
cv2.drawContours(img4,[contours[i]],0,0,-1)
img5 = img4

6.面积滤波
用连通区域的面积除以连通区域包络盒的面积,仅保留当这个比值小于用户所给的div的值时的连通区域。
img5=img5.copy()
contours1,hierarchy = cv2.findContours(img5, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for j in range(len(contours1)):
area1 = cv2.contourArea(contours1[j])
print(area1)
if area1 ==157.0:
cv2.drawContours(img5,[contours1[j]],0,0,-1)
elif area1==261.5:
cv2.drawContours(img5,[contours1[j]],0,0,-1)
elif area1==568.0:
cv2.drawContours(img5,[contours1[j]],0,0,-1)

7.细化函数
输入需要细化的图片(经过二值化处理的图片)和映射矩阵array,并提取骨架。
def Thin(image, array):
h, w = image.shape
iThin = image
for i in range(h):
for j in range(w):
if image[i, j] == 0:
a = [1] * 9
for k in range(3):
for l in range(3):
# 如果3*3矩阵的点不在边界且这些值为零,也就是黑色的点
if -1 < (i - 1 + k) < h and -1 < (j - 1 + l) < w and iThin[i - 1 + k, j - 1 + l] == 0:
a[k * 3 + l] = 0
sum = a[0] * 1 + a[1] * 2 + a[2] * 4 + a[3] * 8 + a[5] * 16 + a[6] * 32 + a[7] * 64 + a[8] * 128
iThin[i, j] = array[sum] * 255
return iThin
# 映射表
array = [0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,\
0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,\
1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\
1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1,\
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\
0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,\
0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,\
1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,\
1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0,\
1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0]
src = cv2.imread(r'img5.png', 0)
Gauss_img = cv2.GaussianBlur(src, (3,3), 0)
# 自适应二值化函数,需要修改的是55那个位置的数字,越小越精细,细节越好,噪点更多,最大不超过图片大小
adap_binary = cv2.adaptiveThreshold(Gauss_img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY,3,2)
img6 = Thin(adap_binary, array)
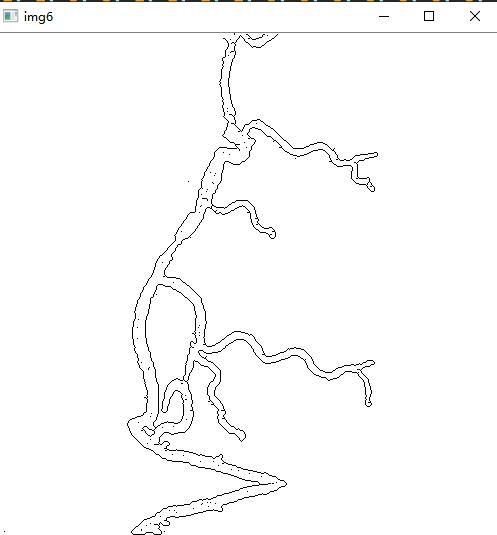
8.边缘检测
img7 = cv2.Canny(img6,80,255)
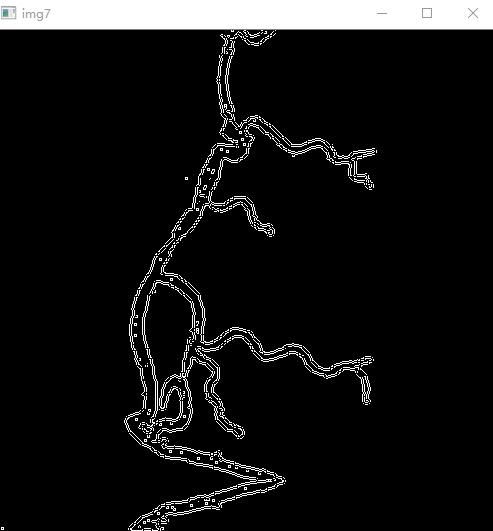
9.图片反色
img8 = img7.copy()
cv2.threshold(img7,80,255,0,img7)
for i in range(0,img7.shape[0]):
for j in range(0,img7.shape[1]):
img8[i,j] = 255-img7[i,j]

10.结束函数
cv.waitKey(0)