Webservice WCF WebApi
注明:改编加组合
在.net平台下,有大量的技术让你创建一个HTTP服务,像Web Service,WCF,现在又出了Web API。在.net平台下,你有很多的选择来构建一个HTTP Services。我分享一下我对Web Service、WCF以及Web API的看法。
Web Service
1、它是基于SOAP协议的,数据格式是XML
2、只支持HTTP协议
3、它不是开源的,但可以被任意一个了解XML的人使用
4、它只能部署在IIS上
WCF
1、这个也是基于SOAP的,数据格式是XML
2、这个是Web Service(ASMX)的进化版,可以支持各种各样的协议,像TCP,HTTP,HTTPS,Named Pipes, MSMQ.
3、WCF的主要问题是,它配置起来特别的繁琐
4、它不是开源的,但可以被任意一个了解XML的人使用
5、它可以部署应用程序中或者IIS上或者Windows服务中
WCF Rest
1、想使用WCF Rest service,你必须在WCF中使用webHttpBindings
2、它分别用[WebGet]和[WebInvoke]属性,实现了HTTP的GET和POST动词
3、要想使用其他的HTTP动词,你需要在IIS中做一些配置,使.svc文件可以接受这些动词的请求
4、使用WebGet通过参数传输数据,也需要配置。而且必须指定UriTemplate
5、它支持XML、JSON以及ATOM这些数据格式
Web API
1、这是一个简单的构建HTTP服务的新框架
2、在.net平台上Web API 是一个开源的、理想的、构建REST-ful 服务的技术
3、不像WCF REST Service.它可以使用HTTP的全部特点(比如URIs、request/response头,缓存,版本控制,多种内容格式)
4、它也支持MVC的特征,像路由、控制器、action、filter、模型绑定、控制反转(IOC)或依赖注入(DI),单元测试。这些可以使程序更简单、更健壮
5、它可以部署在应用程序和IIS上
6、这是一个轻量级的框架,并且对限制带宽的设备,比如智能手机等支持的很好
7、Response可以被Web API的MediaTypeFormatter转换成Json、XML 或者任何你想转换的格式。
WCF和WEB API我该选择哪个?
1、当你想创建一个支持消息、消息队列、双工通信的服务时,你应该选择WCF
2、当你想创建一个服务,可以用更快速的传输通道时,像TCP、Named Pipes或者甚至是UDP(在WCF4.5中),在其他传输通道不可用的时候也可以支持HTTP。
3、当你想创建一个基于HTTP的面向资源的服务并且可以使用HTTP的全部特征时(比如URIs、request/response头,缓存,版本控制,多种内容格式),你应该选择Web API
4、当你想让你的服务用于浏览器、手机、iPhone和平板电脑时,你应该选择Web API
原文:http://www.dotnet-tricks.com/Tutorial/webapi/JI2X050413-Difference-between-WCF-and-Web-API-and-WCF-REST-and-Web-Service.html
Web API = Web Service - 服务定义,换言之 Web API + 服务定义 = Web Service。
少了服务定义会怎样?
-
无法发现服务,从而也无法知晓服务的变更和删除。但,这样又如何?服务发现本来就是UDDI而非WSDL做的事情。
-
无法获得数据类型的定义。Web API在这方面使用XML或者json直接传输数据而无须预先定义,这两个都是弱类型的语言:
-
-
好处,再复杂的类型(只要不是循环引用)都轻松的搞定
-
不好不坏,基础类型都有,通用性十足(WSDL也有,而且只需要做一次)
-
坏处,没有动态语言功底的环境,每次都需要解析比较吃力(WS有了WSDL,这种事情只需要做一次)
-
-
无法获得消息结构的定义。正如2中描述的那样,如果描述一个数据那么复杂,又何必为了它建立一个公开接口定义?相应的,如果描述很容易,也没有必要去事先定义。
-
无法定义多个操作。。。对于调用API的人来说没有任何作用。
-
无法定义多个站口/通讯协议。这也是个赘饰。
少了服务定义又会怎样?
-
仍然需要一个服务的源来暴露服务。作为一个服务提供商,这是理所当然要做的事情。
-
数据类型的定义。只要不出现循环引用,一切都简单到不能更简单。
-
服务接口的定义。也许我们无法提供在线的代码框架生成,但我们可以提供手册+现成的接口调用代码。
当然具体到WS的代表SOAP与WebAPI的代表json。PK不会发生在Soap->Http Header VS Http Header(结果一样),就只有Soap Body->Http Body->XML vs Http Body->json了。这两者没什么可说的,json基本上是完胜。
所以,一个通常的服务提供商,json形式的Web API加上统一的源管理,胜过soap+http的Web Service。不要扯什么安全性,大家都是http基础;如果认为json能够跨域就叫“不安全”,那他应该弄明白怎么样才能跨域。
前端数据可视化
原文
在大数据时代,很多时候我们需要在网页中显示数据统计报表,从而能很直观地了解数据的走向,开发人员很多时候需要使用图表来表现一些数据。随着Web技术的发展,从传统只能依靠于flash、IE的vml,各个浏览器尚不统一的svg,到如今规范统一的canvas、svg为代表的html5技术,表现点、线、面要素的技术已经越来越规范成熟。我把前端数据可视化分为了五种:
1.图表
2.图谱
3.地图
4.关系图
5.立体图
我将按照顺序介绍62款前端可视化插件,下面就分享下34款图表插件:
1.amcharts
url: http://www.amcharts.com/
browser:IE6+、chrome、safari、firefox、opear
resume:amCharts是一种先进的图表库,将适合任何数据可视化的需要。图表解决方案包括柱、栏、线、区域,一步,一步没有冒口,平滑线,烛台,OHLC,馅饼/甜甜圈,雷达/极地,XY /分散/泡沫,子弹,漏斗/金字塔图以及指标。
2.awesomechartjs
url:http://cyberpython.github.io/AwesomeChartJS/
github:https://github.com/cyberpython/AwesomeChartJS
browser:现代浏览器
resume:AwesomeChartJS是一个简单的Javascript库,可用于创建图表基于HTML 5画布元素。
3.axiis
url:http://www.axiis.org/
browser:官方未说明
resume:Axiis框架是一个开源的数据可视化为初学者和专家开发人员设计的。
4.bonsaijs
url:http://bonsaijs.org/
github:https://github.com/uxebu/bonsai
browser:IE9+、chrome20+、safari5+、firefox18+、opear12+
resume:用于创建图形和动画的js库
5.canvasjs
url:http://canvasjs.com
browser:官方未说明
resume:一个使用HTML5、JavaScript创建图表在画布上,图表包括几个好看的主题和10倍的速度比传统的基于Flash / SVG库——导致轻量级的,美丽的和响应指示板。收费
6.canvasxpress
url:http://canvasxpress.org/
browser:Firefox 1.5+, Opera 9+, Safari 3.x+, Chrome 1.0+, IE 6+
resume:CanvasXpress是一个独立的Javascript编写的图形库,支持所有主流浏览器中计算机和移动设备。
7.chartist
url:http://gionkunz.github.io/chartist-js/
github:https://github.com/gionkunz/chartist-js
browser:Firefox, Chrome, Safari, Opera, IE9+
resume:绘制多种图形的库
8.chartjs
url:http://www.chartjs.org/
github:https://github.com/nnnick/Chart.js
browser:IE9+、chrome、safari、firefox、opear、部分支持IE7/8
resume:chartjs是一个可以绘制多种图表的库,使用了html5的canvas技术
9.chartkick
url:http://ankane.github.io/chartkick/
github:https://github.com/ankane/chartkick
browser:IE6+、chrome、safari、firefox、opear
resume:chartkick是一个依赖于ruby的绘制图表的js库,在Python中也可以使用
10.DataWrapper
url:https://datawrapper.de/
github:https://github.com/datawrapper/datawrapper
browser:支持大部分浏览器
resume:Datawrapper完全免费,开源。您可以使用他们的免费主机服务,或者安装在您自己的服务器上。Datawrapper用PHP编写,非常易于安装、修改和拓展。可以绘制。但是DataWrapper是生成图表后嵌入到站点的。
11.dataset
url:http://misoproject.com/dataset/
github:https://github.com/misoproject/dataset
browser:官方未说明
resume:dataset是一个JavaScript客户端数据转换和管理库。数据集管理客户端数据简单处理加载、解析、排序、查询和操纵来自各种数据源的数据。
12.dc
url:http://dc-js.github.io/dc.js/
github:https://github.com/dc-js/dc.js
browser:官方未说明
resume:专门为探索大型、多维数据集而进行优化的库
13.dygraphs
url:http://dygraphs.com/
browser:IE8+、chrome、safari、firefox、opear
resume:dygraphs是一种快速、灵活的开源JavaScript库图表。
14.echart
url:http://echarts.baidu.com/index.html
github:https://github.com/ecomfe/echarts
browser:IE9+、chrome、safari、firefox、opear
resume:基于Canvas,纯Javascript图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。创新的拖拽重计算、数据视图、值域漫游等特性大大增强了用户体验,赋予了用户对数据进行挖掘、整合的能力。
15.flotr2
url:http://www.humblesoftware.com/flotr2/
github:https://github.com/HumbleSoftware/Flotr2
browser:FF, Chrome, IE6+, Android, iOS
resume:Flotr2是HTML5画图表和图形库。可以绘制线图、条图、蜡状图、饼图、气泡图
16.Flot
url:http://www.flotcharts.org/
browser:Internet Explorer 6+, Chrome, Firefox 2+, Safari 3+ and Opera 9.5+
resume:一个基于jQuery的绘图库,可以绘制折线、散点、条形、饼状图
17.fusioncharts
url:http://www.fusioncharts.com/
browser:IE6+、chrome、safari、firefox、opear
resume:一个专门用来绘制图表的库,可以绘制90多种图表,但是收费
18.graphael
url:http://g.raphaeljs.com/
browser:Firefox 3.0+, Safari 3.0+, Opera 9.5+ and Internet Explorer 6.0+
resume:可以绘制各种图表的插件,而且非常简单灵活
19.highchart
url:http://www.highcharts.com/
github:https://github.com/highslide-software/highcharts.com/
browser:支持各种设备,ie6+
resume:在高版本浏览器中使用SVG,而在旧版本IE(包括IE6及更新版本)中使用后备的VML。有自己的团队负责,但是只对非商业用途免费,可以绘制 line, spline, area, areaspline, column, bar, pie, scatter, angular gauges, arearange, areasplinerange, columnrange, bubble, box plot, error bars, funnel, waterfall and polar chart types
20.humble Finance
url:http://www.humblesoftware.com/finance/index
browser:FireFox, Safari, Chromium, or IE6+
resume:HumbleFinance是一个HTML5数据可视化工具类似于Flash工具,完全是用JavaScript编写的工具使用原型和Flotr库。
21.ichartjs
url:http://www.ichartjs.com/
github:https://github.com/wanghetommy/ichartjs
browser:IE9+、chrome、safari、firefox、opear
resume:ichartjs 是一款基于HTML5的图形库。使用纯javascript语言, 利用HTML5的canvas标签绘制各式图形。 ichartjs致力于为您的应用提供简单、直观、可交互的体验级图表组件。ichartjs目前支持饼图、环形图、折线图、面积图、柱形图、条形图。
22.icharts
url:http://www.icharts.net/
browser:官方未说明
resume:iCharts免费版本提供了一些基本的交互式图表样式,如果更使用高级的样式,则需要购买高级版本。
23.JavaScript InfoVis Toolkit
url:http://philogb.github.io/jit/
github:https://github.com/philogb/jit
browser:官方未给出具体版本
resume:JavaScript InfoVis Toolkit可以动态绘制各种图形,提供了一些预设的样式可用于展示不同的数据
24.jqplot
url:http://www.jqplot.com/
browser:IE 7+, Firefox, Safari, and Opera
resume:基于jQuery的绘图插件,可以绘制折线、条形、散点、饼状图
25.jscharts
url:http://www.jscharts.com/
browser:Firefox 1.5 +,Chrome 10 +,Internet Explorer 8 +,Safari 3.1 +,Opera 9 +
resume:jscharts是一个基于JavaScript的图表生成器,需要很少或根本没有编码。jscharts绘制图表是一个简单和容易的任务,因为您只需要使用客户端脚本(即由web浏览器)。不需要额外的插件或服务器模块。就包括我们的脚本,准备你的图表数据XML、JSON或JavaScript数组和你的表已经准备好了!允许您创建图柱状图,饼图或简单的线条图。收费但是有免费版本。
26.kendo-ui
url:http://www.telerik.com/kendo-ui
github:https://github.com/telerik/kendo-ui-core
browser:现代浏览器
resume:http://www.cnblogs.com/xiyangbaixue/p/3951297.html
27.nvd3
url:http://nvd3.org/
github:https://github.com/novus/nvd3
browser:Chrome,Firefox, Opera, Safari and Internet Explorer 10
resume:d3图表库
28.pizza-pie-charts
url:http://zurb.com/playground/pizza-pie-charts
github:https://github.com/zurb/pizza
browser:官方未说明
resume:主要用来生成饼状图的库
29.protovis
url:http://mbostock.github.io/protovis/
github:https://github.com/mbostock/protovis
browser:现代浏览器
resume:Protovis组成自定义视图的数据用简单的标志如酒吧和点。与低级图形库,迅速成为可视化乏味,Protovis定义是通过编码数据的动态属性,允许继承,尺度和layoutsto简化施工。
30.Peity
url:http://benpickles.github.io/peity/
browser:Chrome, Firefox, IE9+, Opera, Safari
resume:可以绘制多种图形,但是都是很小的图形,与jQuery Sparklines相似
31.rgraph
url:http://www.rgraph.net/
browser:现代浏览器
resume:RGraph是一个基于HTML5的开放web图表和图表库。RGraph创建这些图表在web浏览器使用JavaScript,这意味着更快的页面和web服务器负载,导致较小的页面大小和更快的网站。
32.webfx
url:http://webfx.eae.net/
browser:Firefox 1.5, Opera 9 and Internet Explorer 6
resume:支持多种图表的库
33.xcharts
url:http://tenxer.github.io/xcharts/
github:https://github.com/tenXer/xcharts/
browser:现代浏览器
resume:xCharts美丽是一个JavaScript库,用于构建和自定义数据驱动的web使用D3.js图表可视化。使用HTML、CSS和SVG,xCharts被设计成动态、流体、集成和定制。
34.zingchart
url:http://www.zingchart.com/
browser:官方未声明
resume:ZingChart创造惊人的可视化提供了灵活性和资源。提供超过100个图表类型,独特的特性,如缩放和交互式。
小结:
每款插件各有千秋,根据项目需求挑选不同插件。其中比较广泛使用的如echart(百度产品)、highchart等,下面我将分享图谱插件。
9款图谱插件:
1.crossfilter
url:http://square.github.io/crossfilter/
github:https://github.com/square/crossfilter
browser:官方未说明
resume:一个可以操作大型、多元数据集的库,帮助数据分析。
2.d3js
url:http://d3js.org/
github:https://github.com/mbostock/d3
browser:Firefox, Chrome, Safari, Opera, IE9+
resume:D3.js是一个JavaScript库,基于数据操作文档。D3可以帮助你把数据使用HTML、SVG和CSS。D3强调web标准给你完整的现代浏览器的功能没有把自己和一个专有的框架,结合强大的可视化组件和DOM操作的数据驱动的方法。
3.envisionjs
url:http://www.humblesoftware.com/envision/index
github:https://github.com/HumbleSoftware/envisionjs
browser:IE6+、chrome、safari、firefox、opear
resume:envisionjs是一个库来创建快速、动态和交互式可视化的图表
4.jsxgraph
url:http://jsxgraph.uni-bayreuth.de/wp/
github:https://github.com/jsxgraph/jsxgraph
browser:现代浏览器
resume:JSXGraph交互式几何是一个跨浏览器的库,函数绘图,图表和数据可视化在web浏览器中。它完全实现在JavaScript中,不依赖于任何其他库,并使用SVG VML或画布上。
5.paperjs
url:http://paperjs.org/
github:https://github.com/paperjs/paper.js
browser:IE9+,chrome,firefox
resume:paperjs是一款不可多得的js插件,可以绘制各种动态图形效果
6.processingjs
url:http://processingjs.org/
github:https://github.com/processing-js/processing-js/
browser:现代浏览器
resume:processingjs是用Java编写的,所以图形在网页上显示要靠Java程序,使用canvas技术
7.Raphaël
url:http://raphaeljs.com/
github:
browser:Firefox 3.0+, Safari 3.0+, Chrome 5.0+, Opera 9.5+ and Internet Explorer 6.0+.
resume:Raphaël是一款绘制矢量图的插件,支持低版本的浏览器
8.sparklines
url:http://omnipotent.net/jquery.sparkline/#s-about
github:
browser:Firefox 2+, Safari 3+, Opera 9, Chrome and Internet Explorer 6+,ios和andriod设备
resume:使用内嵌在HTML中的数据或通过javascript直接生成微线图(小内联图表),最主要的特点是可以生成波形图。
9.tangle
url:http://worrydream.com/Tangle/
github:
browser:
resume:Tangle是一个JavaScript库,用于创建活性文档。读者可以交互式地探索可能性,玩参数,并立即看到文档更新。Tangle是超级简单,容易学习。
小结:后面将分享6款地图插件。
6款地图插件:
1.Kartograph
url:http://kartograph.org/
github:https://github.com/kartograph/kartograph.py
browser:Internet Explorer 7+,chrome,Firefox
resume:Gregor Aisch开发的一个基于JavaScript和Python的非常炫的、完全使用矢量的库。
2.leafletjs
url:http://leafletjs.com/
github:https://github.com/Leaflet/Leaflet
browser:Chrome,Firefox,Safari 5+,Opera 12+,IE 7–11
resume:leafletjs是一个开源的支持移动端的地图插件,js文件仅仅有33kb,
3.Modest Maps
url:http://modestmaps.com/
github:https://github.com/modestmaps/modestmaps-js
browser:Firefox, Chrome, Opera, iOS, Android, and Internet Explorer 7-9.
resume:Modest Maps支持各种设备,也有很多版本。虽然是一款老的地图插件,但是非常小、可扩展而且免费
4.polymaps
url:http://polymaps.org/
github:https://github.com/simplegeo/polymaps
browser:现代浏览器
resume:Polymaps依赖于SVG,因此在较新的浏览器中表现很好。
5.imagemapster
url:http://www.outsharked.com/imagemapster/
browser:Firefox, Chrome, Safari, Opera, IE6+
resume:ImageMapster是一个jQuery插件,它使你的HTML图片像Flash一样炫
6.datavlab
url:http://datavlab.org/
github:https://github.com/TBEDP/datavjs
browser:IE6+、chrome、safari、firefox、opear
resume:datav.js是为了降低日常对于可视化方法使用的成本,用数据可视化的方法帮助到更多的人。
现在来分享9款关系图插件:
1.arborjs
url:http://arborjs.org/halfviz/#/a-new-hope
github:https://github.com/samizdatco/arbor
browser:IE6+,chrome,firefox
resume:基于jQuery的图谱可视化库,对于高版本的浏览器这个库使用了HTML的canvas元素
2.cubism
url:http://square.github.io/cubism/
github:https://github.com/square/cubism
browser:官方未说明
resume:时间序列数据可视化的D3插件
3.gantti
url:http://bastianallgeier.com/gantti/
github:https://github.com/bastianallgeier/gantti
browser:IE7+、chrome、safari、firefox、opear
resume:是一款PHP的前端数据展示插件
4.getspringy
url:http://getspringy.com/
github:https://github.com/dhotson/springy/
browser:官方未说明
resume:Springy是一个使用JavaScirpt实现的有向图布局算法,使用了真实世界中的一些物理原理,你可以随意拖动图表中的元素。
5.graphdracula
url:http://www.graphdracula.net/
github:https://github.com/strathausen/dracula
browser:官方未说明
resume:graphdracula是一组工具来显示和布局互动图表,以及各种相关算法。
6.sigamajs
url:http://sigmajs.org/
github:https://github.com/jacomyal/sigma.js
browser:IE9+,chrome,firefox
resume:一个非常轻量级的图谱可视化库。Sigma.js很漂亮,速度也快。
7.smoothiecharts
url:http://smoothiecharts.org/
github:https://github.com/joewalnes/smoothie/
browser:IE7+、chrome、safari、firefox、opear
resume:smoothiecharts是一个非常小的图表库为实时流媒体数据而设计的
8.timeplot
url:http://www.simile-widgets.org/timeplot/
github:
browser:官方未说明
resume:Timeplot是基于dhtml AJAXy部件绘图时间序列和覆盖基于时间的事件
9.visjs
url:http://visjs.org/
github:https://github.com/almende/vis/
browser:Chrome, Firefox, Opera, Safari, IE9+
resume:Vis.js是一个动态的、基于浏览器可视化库。库被设计成易于使用,处理大量的动态数据,使操作和交互的数据。时间表,包括组件库数据集网络、Graph2d,Graph3d。
C# asp.net PhoneGap html5
很久没写博客,今天自己写一篇吧。来谈一谈c# PhoneGap,html5 与asp.net。能搜到这篇博客就说明你是一位.net开发者,即将或者正在从事移动开发。
大家可能都有疑,我是一名.net开发者,能用.net做苹果,安卓,wp平台的应用吗?
如大家所知,phoneGap是用来开发跨平台移动应用的,而且phoneGap能调用移动设置的硬件接口,实现一些普通html在移动设备上无法实现的功能,比如拍照,录音,录制视频等。
要做html5页面为单元的应用,一定少不了与服务器进行数据交互。想到的与服务器交互有两种方案:
一种是使用默认的本地HTML方式(当然也可以把HTML放在服务器端,但是这样还不如使用第二种方案),一种是全程使用服务器脚本,比如JSP页面,当然这些页面肯定是放在服务器端,客户端只需要在初始化的时候引用这个页面即可,Android客户端,代码如下:
public class MyActivity extends DroidGap {
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
//super.loadUrl("file:///android_asset/login.html");
super.loadUrl("http://220.166.32.204:8080/test/login.jsp");
super.setIntegerProperty("loadUrlTimeoutValue", 15000);
}
}
(注释掉的代码为PhoneGap默认的本地HTML方案)
另一种是http请求即为服务器脚本解决方案
各有各的好处,本地HTML方案可以把代码和服务器端的代码隔离开,维护只需要维护客户端,无需修改服务器端,并且因为是本地读取,可以在无网络情况下使用应用程序(可以把资源保存在本地sqlLite数据库中);服务器脚本解决方案好处是代码简单,和开发普通web页面几乎无差别,甚至可以直接使用之前针对PC写好的web页面,JS识别设备动态更换一下CSS样式即可。
我使用的是本地HTML5解决方案,在数据交互上,使用的是ajax,使用jQuery的ajax方法,JS代码如下:
function pullNoticeList(){
$.ajax({
url:addr+"notice_list.action",
type:"POST",
dataType:"jsonp",
data:{"start":"0","limit":"8","sort":"effectiveDate","dir":"DESC"},
beforeSend: function(){
$("#content").html("
数据拉取中,请稍后...
").trigger("create");},
success:function(response){
var startHtml = '
- ';
;
$.each(response.noticeList,function(index,item){
startHtml+=""+item.noticeTitle+""+item.effectiveDate+"
";
var endHtml = "
});
$("#content").html(startHtml+endHtml).trigger("create");
},
error:function(){
showReConnConfirm();
}
});
}
必须使用jsonp格式,不然无返回值,其次,注意返回的json格式,一定要符合jQuery的json格式,可以通过firedug查看调试json,服务器端使用的struts,可以使用struts的json插件,可以很智能把对象封装成json格式。
如果你想用phoneGap做一款跨平台的应用,首先要确定会不会调用移动设备的硬件接口,如果不需要调用,那么第一张方案是最佳的选择,维护开发与平常web几乎没区别,最佳的适合我们.net开发者,因为我们可以直接选择用aspx页面来开发。
但是如果项目有要求要调用移动设备的硬件接口,那么必须要选择用第二种方案了。
这时,与服务器交互,html5端用ajax,后台可以用aspx,或者ashx,或者asmx,即分别对应普通aspx页面或者一般处理程序ashx页面,或者直接写webservice服务都行。希望能帮到大家。
移动开发html5,必将是主流,一起迎接吧!
C# Where
判断一个字符串中是否包含字符串数组里的字符,恶意字符限制提交,一般人,包括最初的我,会这样写

public bool ValidateStr(string[] parms)
{
bool result = false;
//要验证的字符列表
string[] validateParms = { "'", "\"", "%" };
for (int i = 0; i < parms.Length; i++)
{
for (int j = 0; j < validateParms.Length; j++)
{
if (parms[i].IndexOf(validateParms[j]) != -1)
{
result = true;
}
}
}
return result;
}
但是你绝不觉得,看着代码很乱呢
其实我们可以这样写
public bool ValidateStr(string[] parms)
{
bool result = false;
//要验证的字符列表
string[] validateParms = { "'", "\"", "%" };
for (int i = 0; i < parms.Length; i++)
{
if (validateParms.Where(p => p.IndexOf(parms[i]) > 0).Count() > 0)
{
result = true;
}
}
return result;
}
代码瞬间清晰
网站分布式开发简介
1 概述 分布式应用程序就是指应用程序分布在不同计算机上,通过网络来共同完成一项任务,通常为服务器/客户端模式。更广义上理解“分布”,不只是应用程序,还包括数据库等,分布在不同计算机,完成同一个任务。之所以要把一个应用程序分布在不同的计算机上,主要有两个目的:
1) 分散服务器的压力
大型系统中,模块众多,并发量大,仅用一个服务器承载往往会发生压力过大而导致系统瘫痪的情况。可以在横向和纵向两方面来进行拆分,把这些模块部署到不同的服务器上。这样整个系统的压力就分布到了不同的服务器上。
l 横向:按功能划分。
l 纵向:N层架构,其中的一些层分布到不同的服务器上(分层的概念会在后文进行介绍)。
2) 提供服务,功能重用
使用服务进行功能重用比使用组件进行代码重用更进一层。举例来说,如果在一个系统中的三个模块都需要用到报表功能,一种方法是把报表功能做成一个单独的组件,然后让三个模块都引用这个组件,计算操作由三个模块各自进行;另一种方法是把报表功能做成单独的服务,让这三个模块直接使用这个服务来获取数据,所有的计算操作都在一处进行,很明显后者的方案会比前者好得多。
服务不仅能对内提供还能对外提供,如果其他合作伙伴需要使用我们的报表服务,我们又不想直接把所有的信息都公开给它们。在这种情况下组件方式就不是很合理了,通过公开服务并对服务的使用方做授权和验证,那么我们既能保证合作伙伴能得到他们需要的数据,又能保证核心的数据不公开。
2 架构 分布式的系统架构,主要从以下几个方面来考虑:分层、面向服务以及分布式数据库。
2.1 分层模型 一般地,我们将应用程序功能分为三个方面,对应3层架构模式。它们是数据层、中间层(业务逻辑层)和表示层,如下图所示。
1) 数据层:存储数据以及从数据库中获得较为原始的数据。
2) 业务逻辑层:介于数据层和表示层之间,负责处理来自数据存储或发送给数据存储的数据,把数据转换成符合商务规则的有意义的信息。
3) 表示层:从业务逻辑层获得信息并显示给用户,负责与用户的交互。
三层架构模式,将业务逻辑和数据存储分离,并分别用独立的服务器来承载,有利于分散系统的压力。其优点具体如下所示:
1) 因为客户机不包含业务逻辑,所以它们变得更加简洁。这就使部署和维护工作更加容易,因为更新业务逻辑只需要对应用服务器进行操作。
2) 客户机与数据库细节相分离。应用服务器能够与几个不同的数据源(分布在不同的数据库服务器上,下文中会对分布式数据库系统进行介绍)协同工作,并且只对客户机提供单一的访问点。
3) 如果设计正确,业务逻辑就能够被分布到几个负载均衡的应用服务器上。如果用户需求增加,则可以添加更多的服务器以满足要求。同时,可以将业务逻辑发布为服务,供客户端应用程序或者其它服务调用,构建成面向服务的系统架构。
2.2 面向服务 一家汽车租赁公司决定创建一个新的应用程序,用于汽车预定。该租车预定应用程序的创建者知道,应用程序所实现的业务逻辑必须能够让公司内外运行的其它软件访问。因此,他们决定以面向服务的方式来创建此应用程序,并通过定义完善的一组服务,将此应用程序的逻辑公开给其他软件。
为了实现这些服务并使之与其他软件进行通信,这一新应用程序将使用 .Net Framework的分布式计算技术,主要有:
1) ASP.NET Web 服务
它使用Soap交互信息,是跨平台,跨语言的,目前大多数平台都支持基本的 Web 服务,所以在 WCF 发布之前,这是实现跨供应商互操作性的最直接的方法。一般用在B/S结构的系统中,需要IIS进行启动。
下图演示了客户机消费Web服务的情形。客户机可以是一个Web应用程序、另一个Web服务等。 Web服务的消费者调用名为Method()的Web服务上的方法。实际调用向下层传播,作为Soap消息通过网络,并向上层传播到Web服务。Web服务执行并响应(如果有的话)。实现Web服务与客户机之间的双向通知或者发布/订阅功能是可能的,但是必须手工完成。客户机可以实现自己的Web服务并在对服务器的调用中传递该Web服务的引用。服务器可以保存引用,然后回调给客户机。
2) .NET Remoting
专门为紧密耦合的 .NET 到 .NET 通信而设计,它为本地网络中的应用程序提供了无缝而直接的开发体验。一般用在C/S结构的系统中,需要通过一个WinForm或是Windows服务进行启动。
3) Microsoft 消息队列 (MSMQ)
提供持久稳定的消息传送,这通常是间歇式连接的应用程序的最佳解决方案。这些应用程序对数据传送、工作量分离以及应用程序生存期均要求有保证。
4) WCF服务
WCF是使用托管代码建立和运行面向服务的应用程序的统一架构,是开发者可以建立一个跨平台(可与在J2EE 服务器构建、非 Windows 系统上运行的应用程序通信)、安全、可信赖、事务性的解决方案,能与目前已有的分布式系统兼容。它是微软分布式应用程序开发的集大成者,整合了.Net 平台下所有和分布式系统有关的技术。
以通信范围而言,WCF可以跨进程(同一机器上不同的应用程序之间的通信)、跨子网、企业网(局域网内不同的机器之间的通信)甚至于Internet(互联网中不同的机器之间的通信)。从宿主程序而言,可以是ASP.NET,EXE , WPF(Windows Presentation Foundation), Windows Forms, NT Service, COM+.
2.3 分布式数据库系统 分布式数据库系统由分布于多个计算机结点上的若干个数据库系统组成,它提供有效的存取手段来操纵这些结点上的子数据库。分布式数据库在使用上可视为一个完整的数据库,而实际上它是分布在地理分散的各个结点上。分布式数据库系统适合于单位分散的部门,允许各个部门将其常用的数据存储在本地,实施就地存放本地使用,从而提高响应速度,降低通信费用。它有以下优点:
1) 解决组织机构分散而数据需要相互联系的问题。比如银行系统,总行与各分行处于不同的城市或城市中的各个地区,在业务上它们需要处理各自的数据,也需要彼此之间的交换和处理,这就需要分布式的系统。
2) 均衡负载。负载在各处理机间分担,可避免临界瓶颈。
3) 可靠性高。数据分布在不同场地,且存有多个副本,即使个别场地发生故障,不致引起整个系统的瘫痪。
4) 可扩充性好。当需要增加新的相对自主的组织单位时,可在对当前机构影响最小的情况下进行扩充。
5) 提高系统性能系统。可以根据距离选择离用户最近的数据副本进行操作,减少通信代价,改善整个系统的性能。
分布式数据库系统虽然有诸多优点,但它同时也带来了许多新问题。如:数据一致性问题、更新同步以及查询分解等的复杂性、数据远程传递的实现、通信开销的降低等,这使得分布式数据库系统的开发变得较为复杂。
3 总结 分布式应用程序的开发,要对应用程序进行分层,各层之间相互独立,通过服务或接口来进行调用,不仅便于开发的管理,也有利于集成其他平台上的应用程序,实现了功能模块的复用、重用,提高了应用程序的可扩展性。在业务数据量多的情况下,还要考虑构建分布式的数据库系统,这可以通过DBMS自动管理的数据订阅、分发技术实现数据库的数据同步,以达到数据共享的目的;也可以与一些分布式的计算技术结合起来,比如说.NET Remoting技术来解决各数据库之间的通信问题,等等。
针对大型的网站应用,分布式部署策略可以从以下几个方面考虑:
1) 代理服务器实现请求的分离 。
2) 缓存的分布式部署,提高系统性能。
3) 拆分网站的对外功能,例如不同域名前、后缀,URL 重写。
4) 面向服务,每个服务分布到一台服务器上 。
5) 数据库的分布式集群部署。
6) 设立专门的应用服务器。比如发送邮件通知的服务。
EntityFramework Core依赖注入上下文方式不同造成内存泄漏了解一下?
前言
这个问题从未遇见过,是一位前辈问我EF Core内存泄漏问题时我才去深入探讨这个问题,刚开始我比较惊讶,居然还有这种问题,然后就有了本文,直接拿前辈的示例代码并稍加修改成就了此文,希望对在自学EF Core过程中的童鞋能有些许帮助。
EntityFramework Core内存泄漏回顾
接下来我将用简单示例代码来还原整个造成EntityFramework Core内存泄漏的过程,同时在这个过程中您也可思考一下其中的原因和最终的结果是否一致。
public class TestA
{
public long Id { get; set; }
public string Name { get; set; }
}
public class EFCoreDbContext : DbContext
{
public EFCoreDbContext(DbContextOptions options)
: base(options)
{
}
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer("data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=MemoryLeak;integrated security=True;MultipleActiveResultSets=True;");
base.OnConfiguring(optionsBuilder);
}
public DbSet TestA { get; set; }
}
public class TestUserCase
{
public void InvokeMethod(IServiceProvider serviceProvider)
{
EFCoreDbContext _context = null;
if (_context == null)
{
_context = serviceProvider.GetRequiredService();
}
for (var i = 0; i < 10; i++)
{
var testA = _context.TestA.FirstOrDefault();
Console.WriteLine(i);
}
}
}
如上是整个示例代码,重头戏来了,接下来我们在控制台中来通过依赖注入上下文,并获取注入容器中的上下文并调用上述TestUserCase类中的方法,如下:
var services = new ServiceCollection();
services.AddDbContext(options => options.UseSqlServer("data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=MemoryLeak;integrated security=True;MultipleActiveResultSets=True;"));
var serviceProvider = services.BuildServiceProvider();
for (int i = 0; i < 1000; i++)
{
var test = new TestUserCase();
test.InvokeMethod(serviceProvider);
}

通过上述测试内存基本在15兆左右,当然根据机器配置不同最终得到的结果有所差异,但是内存基本没有什么大的波动,接下来我们来改造上述代码。上述我们将serviceProvider通过方法传递到TestUserCase中的InvokeMethod方法中,为了简便我们将获取到的serviceProvider改造成静态的,如下:
public static class ServiceLocator
{
private static IServiceCollection _services;
public static IServiceProvider Instance
{
get
{
if (_services == null)
return null;
else
return _services.BuildServiceProvider();
}
}
public static void Init(IServiceCollection services)
{
_services = services;
}
}
public class TestUserCase
{
public void InvokeMethod()
{
IServiceScope _serviceScope = null;
EFCoreDbContext _context = null;
if (_context == null)
{
_serviceScope = ServiceLocator.Instance.GetRequiredService().CreateScope();
_context = _serviceScope.ServiceProvider.GetRequiredService();
}
for (var i = 0; i < 10; i++)
{
var testA = _context.TestA.FirstOrDefault();
Console.WriteLine(i);
}
}
}
var services = new ServiceCollection();
services.AddDbContext(options => options.UseSqlServer("data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=MemoryLeak;integrated security=True;MultipleActiveResultSets=True;"));
ServiceLocator.Init(services);
for (int i = 0; i < 1000; i++)
{
var test = new TestUserCase();
test.InvokeMethod();
}
如上我们通过ServiceLocator类来构建serviceProvider,并将返回serviceProvider赋值给静态变量,然后在我们调用的方法中直接获取容器中的上下文,这样就免去了传递的麻烦。

经过我们上述改造后最终运行内存达到了比较可怕的三百多兆,看来上下文压根就没进行GC,那我是不是改造成如下就可以了呢?
var scopeFactory = ServiceLocator.Instance.GetRequiredService(); using (var scope = scopeFactory.CreateScope()) using (var context = scope.ServiceProvider.GetRequiredService ()) { for (var i = 0; i < 10; i++) { var testA = context.TestA.FirstOrDefault(); Console.WriteLine(i); } }

原以为是上下文没有及时得到释放而导致内存激增,但是看到上述结果依然一样没有任何改变,问题是不是到此就结束了呢?下面我们改变注入上下文的方式看看,如下:
var services = new ServiceCollection();
var options = new DbContextOptionsBuilder()
.UseSqlServer("data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=MemoryLeak;integrated security=True;MultipleActiveResultSets=True;")
.Options;
services.AddScoped(s => new EFCoreDbContext(options));

当我们改变了注入上下文方式后发现此时不会造成内存泄漏,也就是说上下文得到了GC,无论是我是否是手动释放上下文即通过Using包括或者不包括都不会出现内存泄漏问题。通过注入方式不同得到的结果截然不同,但是在我们的理解中通过AddDbContext注入上下文中的第二个参数是默认为Scope,那和我们通过AddScoped注入上下文应该是一样对不对,那为何结果又不同呢?岂不是冲突了吗?在Web不会出现这样的问题,未深入研究,我猜测其原因可能如下:
通过AddDbContext注入上下文只适用于Web应用程序即只对Web应用程序有效而对控制台程序可能无效,同时在Web应用程序中AddDbContext注入上下文和AddScoped注入上下文一致,而对于控制台程序存在不一致问题。一言以蔽之,在Web和Console中通过AddDbContext注入上下文可能存在处理机制不同。
总结
不知如上浅薄分析是否有漏洞或者说代码有错误的地方,期待看到本文的您能有更深入的见解可留下您的评论,如果结果是这样不建议在控制台中使用AddDbContext方法注入上下文。
SQL Server之深入理解STUFF
前言
最近项目无论查询报表还是其他数据都在和SQL Server数据库打交道,对于STUFF也有了解,但是发现当下一次再写SQL语句时我还得查看相关具体用法,说到底还是没有完全理解其原理,所以本节我们来谈谈STUFF,Jeff是在项目中哪里不熟悉,哪里不会或者哪里耗时比较多就会去深入理解和巩固即使是很基础的知识,直到完全不用浪费时间去查阅相关资料,这是我的出发点。
深入理解STUFF
STUFF字符串函数是将字符串插入到另一个字符串中。它会删除开始位置第一个字符串中的指定长度的字符,然后将第二个字符串插入到开始位置的第一个字符串中,语法如下。
STUFF(
DECLARE @FullName VARCHAR(100)
DECLARE @Alias VARCHAR(20)
SET @FullName = 'Jeffcky Wang'
SET @Alias = ' "Superman" '
SELECT STUFF(@FullName, CHARINDEX(' ', @FullName), 1, @Alias) AS [FullName]

如上STUFF函数中的第一个参数我们给定的是@FullName,第二个是开始的位置,我们通过CHARINDEX函数找出@FullName以空格隔开的的位置返回,最后由@Alias来代替,结果如图所示。
DECLARE @Time VARCHAR(10) SET @Time = '1030' SELECT STUFF(@Time, 3, 0, ':') AS [HH:MM]

我们给定的字符串为@Time即1030,我们从第3个位置开始,删除长度为0,此时则在3前面插入冒号,结果如上图输出10:30。
DECLARE @CreditCardNumber VARCHAR(20)
SET @CreditCardNumber = '370200199408103544'
SELECT STUFF(@CreditCardNumber, LEN(@CreditCardNumber) -3, 4,
'XXXX') AS [Output]

如上我们将身份证通过STUFF将最后四位用XXXX代替。以上是STUFF最基础的用法。STUFF最常见的用途莫过于结合FOR XML PATH对返回JSON字符串的拼接。首先利用FOR XML PATH则返回XML格式的字符串,我们将FOR XML PATH添加到查询的末尾,此时允许我们将查询的结果作为XML元素输出,元素名称包含在PATH参数中。。
SELECT TOP 5 ',' + Name
FROM Production.Product
FOR XML PATH ('')

,Adjustable Race,All-Purpose Bike Stand,AWC Logo Cap,BB Ball Bearing,Bearing Ball
此时我们利用STUFF将上述利用FOR XML PATH生成的字符串中的前置逗号去掉,如下:
SELECT Name = STUFF((
SELECT TOP 5 ',' + NAME
FROM Production.Product
FOR XML PATH('')
), 1, 1, '')

比如我们要查询各种产品中的产品列表名称,最后我们改造成如下:
SELECT TOP 5 p2.ProductID, Name = STUFF((
SELECT ',' + NAME
FROM Production.Product AS p1
WHERE p1.ProductID = p2.ProductID
FOR XML PATH('')
), 1, 1, '') FROM Production.Product AS p2
GROUP BY p2.ProductID

接下来我们利用STUFF结合FOR XML PATH来拼接JSON字符串,如下:
DECLARE @content VARCHAR(MAX)
SET @content = (SELECT '['+ STUFF((SELECT TOP 5 ',{"ProductName": "' + ProductName + '","Price": "' + CONVERT(VARCHAR, Price) + '","Quantity": "' + CONVERT(VARCHAR, quantity) + '","Inserton": "' + CONVERT(VARCHAR, Inserton, 105) + '"}' FROM ProductList
FOR XML PATH('')), 1, 1,''
)
+ ']'[ProductDetail])
PRINT @content

结果如上正确输出JSON字符串,接下来我们将如上拼接换行再试试。
DECLARE @content VARCHAR(MAX)
SET @content = ( SELECT '['
+ STUFF(( SELECT TOP 5
',{"ProductName": "' + ProductName
+ '","Price": "'
+ CONVERT(VARCHAR, Price)
+ '","Quantity": "'
+ CONVERT(VARCHAR, quantity)
+ '","Inserton": "'
+ CONVERT(VARCHAR, Inserton, 105)
+ '"}'
FROM ProductList
FOR
XML PATH('')
), 1, 1, '') + ']' [ProductDetail]
)
PRINT @content
如上是利用SQL Prompt直接格式化换行,结果依然正确输出JSON字符串,我们再来手动换行试试。
DECLARE @content VARCHAR(MAX)
SET @content = (SELECT
'['+ STUFF((SELECT TOP 5 ',
{"ProductName": "' + ProductName
+ '","Price": "' + CONVERT(VARCHAR, Price)
+ '","Quantity": "' + CONVERT(VARCHAR, quantity)
+ '","Inserton": "' + CONVERT(VARCHAR, Inserton, 105)
+ '"}' FROM ProductList
FOR XML PATH('')), 1, 1,''
)
+ ']'[ProductDetail])
PRINT @content

结果输出如上我们不期望的字符串,主要是由FOR XML PATH造成的,比如我们利用FOR XML PATH进行如下查询:
SELECT ' '
FOR XML PATH('')

当我们利用FOR XML PATH查询数据时,如果字符串中包含空格时会造成出现以如上错误的字符串来填充,所以此时我们为了消除这种错误格式,我们将上述继续添加参数。
SELECT ' '
FOR XML PATH(''),TYPE

此时我们将上述输出JSON字符串不错误的格式修改成如下即可:
DECLARE @content VARCHAR(MAX)
SET @content = (SELECT
'['+ STUFF((SELECT TOP 5 ',
{"ProductName": "' + ProductName
+ '","Price": "' + CONVERT(VARCHAR, Price)
+ '","Quantity": "' + CONVERT(VARCHAR, quantity)
+ '","Inserton": "' + CONVERT(VARCHAR, Inserton, 105) + '"}' FROM ProductList
FOR XML PATH('') ,TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1,''
)
+ ']'[ProductDetail])
PRINT @content

或者我们对上述输出的错误字符串进行替换,如下:
select t.PK,
ltrim(rtrim(replace(
(select ' ' + isnull(ti.Column1, '') + ' ' + isnull(ti.Column2, '')
from yourTable ti
where ti.PK = t.PK
for xml path (''))
, ' ', ''))) fruits
from yourTable t
group by t.PK;
这里我们解决了利用STUFF有可能输出JSON字符串带有错误的字符串的问题,在利用STUFF输出JSON字符串时只要有一列数据包含NULL,那么返回的数据则为空,那么我们在对列数据通过ISNULL来进行判断,比如如下将输出NULL。
DECLARE @content VARCHAR(MAX)
SET @content = (SELECT
'['+ STUFF((SELECT TOP 5 ',
{"ProductName": "' + NULL
+ '","Price": "' + CONVERT(VARCHAR, Price)
+ '","Quantity": "' + CONVERT(VARCHAR, quantity)
+ '","Inserton": "' + CONVERT(VARCHAR, Inserton, 105) + '"}' FROM ProductList
FOR XML PATH('') ,TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1,''
)
+ ']'[ProductDetail])
PRINT @content
所以此时我们必须通过ISNULL来判断列数据是否为NULL,修改成如下形式:
DECLARE @content VARCHAR(MAX)
SET @content = (SELECT
'['+ STUFF((SELECT TOP 5 ',
{"ProductName": "' + ISNULL(ProductName,'')
+ '","Price": "' + CONVERT(VARCHAR, Price)
+ '","Quantity": "' + CONVERT(VARCHAR, quantity)
+ '","Inserton": "' + CONVERT(VARCHAR, Inserton, 105) + '"}' FROM ProductList
FOR XML PATH('') ,TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1,''
)
+ ']'[ProductDetail])
PRINT @content
你必须知道的EntityFramework 6.x和EntityFramework Core变更追踪状态
前言
只要有时间就会时不时去看最新EF Core的进展情况,同时也会去看下基础,把握好基础至关重要,本节我们对比看看如标题EF 6.x和EF Core的不同,希望对正在学习EF Core的同行能有所帮助,同时也希望通过本文能对您心中可能产生的疑惑进行解答,本文略长,请耐心阅读。
深入探讨EF 6.x和EF Core变更追踪状态话题
请注意虽然EF 6.x和EF Core在使用方式上没有什么不同,但是内置实现却有所不同,了解它们的不同很重要,同时也希望更多同行选择EF Core,EF 6.x令人诟病毋庸置疑,在使用上不了解基本知识就会出很大的问题,这一点我已经明确阐述过,EF Core为我们做了许多,只是我们并未知道而已,看完本文相信您会认同我说的这句话,为了便于大家理解我们用实例来说明。
EntityState状态设置和使用对应方法是否匹配?
无论是在EntityFramework 6.x还是EntityFramework Core中DbSet上始终包含有Add、Attath、Remove等方法,当我们调用Add方法来添加对象时,此时内部则是将对象状态置为添加状态(Add),如果我们调用Remove方法删除对象,内部则是将对象置为删除状态(Deleted),在EF 6.x中没有Update方法,若是更新所有列则是只需将对象状态修改为Modified,无论怎样都是通过EntityState来根据我们的操作来设置对象相应的状态,下面我们一起来看下例子。
using (var ctx = new EfDbContext())
{
var customer = new Customer() { Id = 1, Name = "Jeffcky" };
ctx.Entry(customer).State = EntityState.Modified;
ctx.Customers.Add(customer);
var state = ctx.Entry(customer).State;
var result = ctx.SaveChanges();
};
如上示例是在EF 6.x中,我们首先实例化一个customer,然后将其状态修改为Modified,最后我们调用Add方法添加到上下文中,此时我们得到customer的状态会是怎样的呢?

没毛病,对不对,最终调用Add方法其状态将覆盖我们手动通过Entry设置的Modified状态,接下来我们将如上通过Entry方法修改为如下:
ctx.Entry(customer).State = EntityState.Unchanged;
如果我们这样做了,结果当然也是好使的,那要是我们继续修改为如下形式呢?
using (var ctx = new EfDbContext())
{
var customer = new Customer() { Id = 1, Name = "Jeffcky" };
ctx.Entry(customer).State = EntityState.Deleted;
ctx.Customers.Add(customer);
var state = ctx.Entry(customer).State;
var result = ctx.SaveChanges();
};
结果还是Added状态,依然好使,我们继续进行如下修改。
using (var ctx = new EfDbContext())
{
var customer = new Customer() { Id = 1, Name = "Jeffcky" };
ctx.Entry(customer).State = EntityState.Added;
ctx.Customers.Attach(customer);
var state = ctx.Entry(customer).State;
var result = ctx.SaveChanges();
};

恩,还是没问题,这里我们可以得出我们通过Entry方法手动设置未被跟踪对象的状态后,最后状态会被最终调用的方法所覆盖,一切都是明朗,还没完全结束。那接下来我们添加导航属性看看呢?
using (var ctx = new EfDbContext())
{
var customer = new Customer() { Id = 1, Name = "Jeffcky" };
var order = new Order() { Id = 1, CustomerId = 1 };
customer.Orders.Add(order);
ctx.Entry(order).State = EntityState.Modified;
ctx.Customers.Attach(customer);
var state = ctx.Entry(order).State;
var result = ctx.SaveChanges();
};
反观上述代码,我们实例化customer和order对象,并将order添加到customer导航属性中,接下来我们将order状态修改为Modified,最后调用Attath方法附加customer,根据我们上述对单个对象的结论,此时order状态理论上应该是Unchanged,但是真的是这样?

和我们所期望的截然相反,此时通过调用attach方法并未将我们手动通过Entry方法设置状态为Modified覆盖,换言之此时造成了对象状态不一致问题,这是EF 6.x的问题,接下来我们再来看一种情况,你会发现此时会抛出异常,抛出的异常我也看不懂,也不知道它想表达啥意思(在EF Core中不会出现这样的情况,我就不占用一一篇幅说明,您可自行实践)。
using (var ctx = new EfDbContext())
{
var customer = new Customer() { Id = 1, Name = "Jeffcky" };
var order = new Order() { Id = 1 };
customer.Orders.Add(order);
ctx.Entry(order).State = EntityState.Deleted;
ctx.Customers.Attach(customer);
var state = ctx.Entry(order).State;
var result = ctx.SaveChanges();
};

由上我们得出什么结论呢?在EF 6.x中使用Entry设置对象状态和调用方法对相关的对象影响将出现不一致的情况,接下来我们来对比EF 6.x和EF Core在使用上的区别,对此我们会有深刻的理解,如果我们还沿袭EF 6.x那一套,你会发现居然不好使,首先我们来看EF 6.x例子。
using (var ctx = new EfDbContext())
{
var customer = new Customer()
{
Name = "Jeffcky",
Email = "[email protected]",
Orders = new List()
{
new Order()
{
Code = "order",
CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now,
Price = 100,
Quantity = 10
}
}
};
ctx.Customers.Add(customer);
var result = ctx.SaveChanges();
};
这里需要说明的是我将customer和order是配置了一对多的关系,从如上例子也可看出,我们调用SaveChanges方法毫无疑问会将customer和order插入到数据库表中,如下:
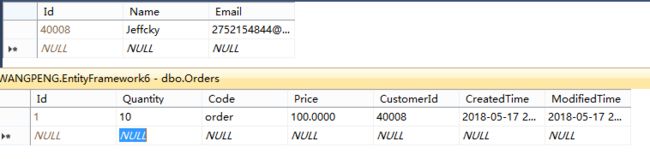
接下来我们手动通过Entry方法设置customer状态为Added,再来看看,如下:
using (var ctx = new EfDbContext())
{
var customer = new Customer()
{
Name = "Jeffcky",
Email = "[email protected]",
Orders = new List()
{
new Order()
{
Code = "order",
CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now,
Price = 100,
Quantity = 10
}
}
};
ctx.Entry(customer).State = EntityState.Added;
var result = ctx.SaveChanges();
};
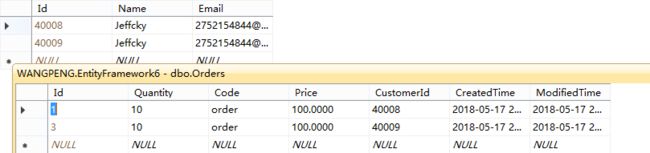
对照如上我们再来看看在EF Core中是如何处理的呢?直接调用Add方法就不浪费时间演示了,用过EF Core的都知道必然好使,我们看看手动设置状态。
public static void Main(string[] args)
{
using (var context = new EFCoreDbContext())
{
var blog = GetBlog();
var post = new Post()
{
CommentCount = 10,
CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now,
Name = "Jeffcky"
};
context.Entry(blog).State = EntityState.Added;
var result = context.SaveChanges();
}
Console.ReadKey();
}
static Blog GetBlog()
{
return new Blog()
{
IsDeleted = false,
CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now,
Name = "Jeffcky",
Status = 0,
Url = "http://www.blogs/com/createmyself"
};
}

通过实践证明此时不会将Post添加到表中,为什么会如此呢?因为我们只是手动设置了blog的状态为Added,而未对Post进行设置,看到这里想必您知道了EF 6.x和EF Core的不同。EF团队之所以这么做的目的在于如EF 6.x一样手动设置根对象的状态其导航属性即相应关联的对象也会设置,这样做会造成混乱,当我们添加对象时其导航属性也会对应添加,虽然看起来很自然,也适应一些情况,但是对象模型并不清楚主体和依赖关系,所以在EF Core中则发生了改变,通过Entry方法只会对传入对象的状态有所影响而对关联的对象不会发生任何改变,这点尤其重要,我们在使用EF Core时要格外注意,额外多说一句在EF Core通过Entry().State这个APi设置状态只会对单个对象产生影响不会对关联对象产生任何影响即忽略关联对象。
EntityFramework Core为什么在上下文中添加对应方法?
不知道使用过EF Core的您有没有发现,在EF 6.x中我们发现在上下文中并没有如暴露的DbSet上的方法比如Add、AddRange、Remove、RemoveRange等等,但是在EF Core则存在对应的方法,不知道您发现过没有,我虽然发现,但是一直不明白为何如此这样做,这样做的目的在哪里呢?我还特意看了EF Core实现源码,结果发现其内部好像还是调用了暴露在DbSet上的方法,如果我没记错的话,这样不是多此一举,吃饱了撑着了吗,有这个时间实现这样一个玩意,那怎么不早早实现通过Incude进行过滤数据呢?EF Core团队在github上讨论当前这不是优先级比较高的特性,其实不然,很多时候我们需要通过导航属性来筛选数据,少了这一步,我们只能加载到内存中再进行过滤。好了回到话题,我也是偶然看到一篇文章,才发现这样设计的目的何在,接下来我们首先来看看在EF 6.x中的上下文中没有对应的方法结果造成的影响是怎样的呢?通过实例我们一看便知。
using (var ctx = new EfDbContext())
{
var order = ctx.Orders.FirstOrDefault();
var newOrder = new Order()
{
CustomerId = order.CustomerId,
CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now,
Code = "addOrder",
Price = 200,
Quantity = 1000
};
ctx.Orders.Add(newOrder);
var result = ctx.SaveChanges();
};

特意给出如上表中数据来进行对比,如上代码我们查询出第一个Order即上图标注,然后我们重新实例化一个Order进行添加,此时您能想象到会发生什么吗?瞧瞧吧。

结果是添加到表中了,但是但是但是,重要的事情说三遍,仔细看看数据和我们要添加的Order数据对照看看,万万没想到,此时得到的数据是主键等于1的数据也就是旧数据。让我们再次回到EF Core中演示上述例子。
using (var context = new EFCoreDbContext())
{
var post = context.Posts.FirstOrDefault();
var newPost = new Post()
{
CreatedTime = Convert.ToDateTime("2018-06-01"),
ModifiedTime = Convert.ToDateTime("2018-06-01"),
Name = "《你必须掌握的Entity Framework 6.x与Core 2.0》书籍出版",
CommentCount = 0,
BlogId = post.BlogId
};
context.Add(newPost);
var result = context.SaveChanges();
}

如上代码重新实例化一个Blog并添加到表中数据和如上图中数据完全不一样,我们通过上下文中暴露的Add方法来添加Blog,我们来看看最终在表中的数据是怎样的呢?
![]()
在EF Core上下文中有了Add,Attach、Remove方法以及Update和四个相关的Range方法(AddRange等等)和暴露在DbSet上的方法一样。 同时在上下文中的方法更加聪明了。 它们现在可以确定类型并自动将实体对象关联到我们想要的的DbSet。不能说很方便,而是非常方便,因为它允许我们编写通用代码而完全不需要再实例化DbSet,当然我们也可以这样做,只不过现在又多了一条康庄大道罢了,代码简易且易于发现。
即使是如下动态对象,EF Core也能正确关联到对应的对象,您亲自实践便知。
using (var context = new EFCoreDbContext())
{
dynamic newBlog = new Blog()
{
IsDeleted = true,
CreatedTime = Convert.ToDateTime("2018-06-01"),
ModifiedTime = Convert.ToDateTime("2018-06-01"),
Name = "《你必须掌握的Entity Framework 6.x与Core 2.0》书籍出版",
Status = 0,
Url = "http://www.cnblogs.com/CreateMyself/p/8655069.html"
};
context.Add(newBlog);
var result = context.SaveChanges();
}
让我们再来看看一种情况来对比EF 6.x和EF Core在使用方式上的不同,首先我们来看看EF 6.x例子:
using (var ctx = new EfDbContext())
{
var customer = ctx.Customers.Include(d => d.Orders).FirstOrDefault();
var newOrder = new Order()
{
CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now,
Code = "addOrder",
Price = 200,
Quantity = 1000,
CustomerId = customer.Id
};
ctx.Orders.Attach(newOrder);
var result = ctx.SaveChanges();
};

此时我们能够看到我们只是通过Attatch方法附加了newOrder,然后进行通过SaveChanges进行提交,此时并未提交到数据库表中,那EF Core处理机制是不是也一样呢?我们来看看:
using (var context = new EFCoreDbContext())
{
var blog = context.Blogs.FirstOrDefault();
var newPost = new Post()
{
CreatedTime = Convert.ToDateTime("2018-06-01"),
ModifiedTime = Convert.ToDateTime("2018-06-01"),
Name = "《你必须掌握的Entity Framework 6.x与Core 2.0》书籍出版",
CommentCount = 0,
BlogId = blog.Id
};
context.Attach(newPost);
var result = context.SaveChanges();
}

很惊讶是不是,在EF Core最终添加到数据库表中了,依照我们对EF 6.x的理解,通过Attach方法只是将实体对象状态修改为Unchanged,如果我们想添加对象那么必须调用Add方法,此时对象状态将变为Added状态,也就是说在EF 6.x中如果我们调用Attatch方法,但是需要将对象添加到数据库表中,此时必须要调用Add方法,反之如果我们调用Add方法,那么调用Attath方法附加对象则多此一举,但是在EF Core中这种情况通过上述演示很显然发生了改变。那么EF Core内部是根据什么来判断的呢?我们来看如下源代码:
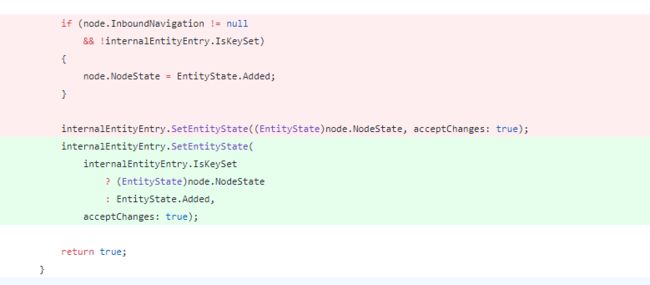
通过上述源代码不难看出在EF Core对于未设置主键都将视为添加换句话说则是如果调用Attach方法附加一个未被跟踪的对象时且主键值未被填充时,EF Core将其视为添加,所以如果我们需要添加对象时此时可直接调用Attach而无需调用Add方法。如果您依然不信,您可自行进行如下测试,也同样会被添加到表中。
public static void Main(string[] args)
{
using (var context = new EFCoreDbContext())
{
var blog = GetBlog();
context.Attach(blog);
var result = context.SaveChanges();
}
Console.ReadKey();
}
static Blog GetBlog()
{
return new Blog()
{
IsDeleted = false,
CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now,
Name = "Jeffcky",
Status = 0,
Url = "http://www.blogs/com/createmyself"
};
}
EF Core团队这么做的目的是什么呢?大部分情况下通过调用Attach方法将可抵达图中所有未跟踪实体的状态设置为Unchanged,除非实体对象的主键我们没有设置且正在使用值生成,对于更新/修改同理。很显然 这对许多断开连接的实体的常见情况非常有用。但是,在许多情况下它不起作用,因为在特殊情况下是根实体,即使我们未设置主键也强制它的状态保持不变,这样做显然不合理。如果我们通过未设置主键调用Attach并最终添加它,这被认为是意外行为,我们需要放开对根实体的特殊封装,通过调用Attach方法来改变这种行为,这会使得Attach变得更加适用,它并不是突破性的改变。
Jeff自问自答模式来了,那么我们是否允许我们多次调用Attach来附加实体对象呢?您觉得是否可行呢?我们来验证下:
using (var context = new EFCoreDbContext())
{
var blog = GetBlog();
context.Attach(blog);
context.Attach(blog);
var result = context.SaveChanges();
}
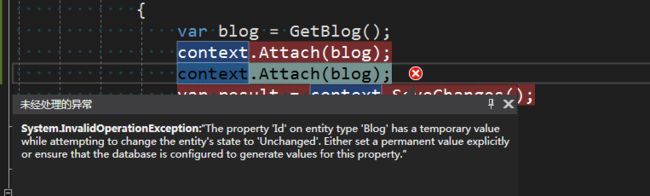
EntityFramework Core为什么添加无连接跟踪图(Disconnected TrackGraph)?
追踪图是EF中全新的概念,它提供了我们对对象状态的完全控制,TrackGraph遍历图(即遍历图中的每个对象)并将指定的函数应用于每个对象。 该函数是TrackGraph方法的第二个参数。此特性的出现也是为了调用对应方法和手动设置状态而造成的混乱而给。比如我们想实现如EF 6.x一样,当调用Attach方法时不添加实体,那么我们可以如下这样做。
using (var context = new EFCoreDbContext())
{
var blog = GetBlog();
context.ChangeTracker.TrackGraph(blog, node =>
{
if (!node.Entry.IsKeySet)
{
node.Entry.State = EntityState.Unchanged;
}
});
context.Attach(blog);
var result = context.SaveChanges();
}
总结
本文我们详细讲解了EF 6.x和EF Core在实体状态上使用方式的不同且讲解了我们需要注意到二者的不同,接下来我们会继续回顾基础,感谢您的阅读,我们下节再会。
修正
关于本文用EF 6.x添加数据出现旧数据问题是我写的代码有问题,特此致歉,不知道是在什么场景会产生旧数据的问题,之前确实看过一篇文章,但是示例忘记了。