Python数据分析:时间序列分析——基础理论
我们可以用时间序列分析解决一些预测模型,这种方法可以预测数据在未来的发展趋势。下面将会介绍时间序列分析的基础理论。
基础介绍
1.时间序列
- 时间戳(timestamp)
- 固定周期(period)
- 时间间隔(interval)
2.数据重采样:将数据的分布频率从一个频率转换为另一个频率。
- 降采样:将数据的分布频率减小,即数据的个数由多到少,如将日变成月。
- 升采样:将数据的分布频率增加,即数据的个数由少到多,如将月变成日。
- 由于在升采样时,数据中可能会出现空值,这是由于从少量数据到大量数据会造成部分数据未知。这时我们需要采用插值方法。
3.滑动窗口:将待预测数据所在数据区间缩小以获得更加精确的结果。
ARIMA模型
1.平稳性:平稳性就是要求经由样本时间序列所得到的拟合曲线在未来的一段时间内仍能顺着现有的形态“惯性”地延续下去。平稳性要求序列的均值和方差不发生明显变化。
- 严平稳:严平稳表示的分布不随时间的改变而改变,如:正态分布,无论如何取值,期望都是0,方差都是1。
- 弱平稳:期望与相关系数(依赖性)不变,未来某时刻的t的值
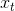 就要依赖于它的过去信息,所以需要依赖性。
就要依赖于它的过去信息,所以需要依赖性。
2.原理:将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型
3.各物理量含义:
- AR:自回归
- p:自回归项
- MA:移动平均
- q:移动平均项数
- d:时间序列平稳时的差分次数
差分法(I)
- 计算时间序列在t与t-1时刻的插值,以将非平稳时间序列转化为平稳时间序列,可以进行多阶差分。
自回归模型(AR)
- 描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测。
- 自回归模型必须满足平稳性的要求。
- p阶自回归过程的公式定义为:

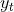 是当前值,
是当前值, 是常数项,p是阶数,
是常数项,p是阶数,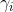 是自相关系数,
是自相关系数,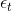 是误差。
是误差。
自回归模型的限制:
- 自回归模型是用自身的数据来进行预测。
- 必须具有平稳性。
- 必须具有自相关性,如果自相关系数
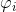 小于0.5,则不宜采用。
小于0.5,则不宜采用。 - 自回归只适用于预测与自身前期相关的现象。
移动平均模型(MA)
- 移动平均模型关注的是自回归模型中的误差项的累加。
- q阶自回归过程的公式定义:
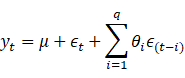
- 移动平均法能有效地消除预测中的随机波动。
自回归移动平均模型(ARMA)
- 自回归与移动平均的结合。
- 公式定义:

自相关函数(ACF)
- 有序的随机变量序列与其自身比较,自相关函数反映了同一序列在不同时序的取值之间的相关性。
- 公式:
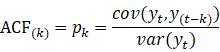
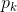 的取值范围是[-1,1]。
的取值范围是[-1,1]。
偏自相关函数(PACF)
- 经过自相关可以得出
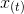 和
和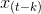 的关系,但是和均受中间的k-1个变量影响,所以需要用偏自相关函数获得更准确的预测。
的关系,但是和均受中间的k-1个变量影响,所以需要用偏自相关函数获得更准确的预测。 - ACF包含其他变量影响。
- PACF是严格的两个变量间的相关性。
- ACF决定MA的q,PACF决定AR的p。
ARIMA建模流程
1.得到平稳的时间序列(用差分法求出d)。
2.根据ACF和PACF的图像求出p和q,ACF决定q,PACF决定p。
3.ARIMA(p,d,q)
模型选择
由于根据图像求出来的p和q可能不止一组,这时候我们就要从中选择出一组最适合的p和q,模型越简单越好,这部分可以绘制热度图来观察AIC和BIC的值从而选择p和q。
- AIC:赤池信息准则
![]()
- BIC:贝叶斯信息准则
![]()
- k为模型参数个数,n为样本数量,L为似然函数,AIC和BIC均越低越好,也就是k,越小,L越大越好。
模型残差检验
- ARIMA模型的残差是否是平均值为0且方差为常数的正态分布。
- QQ图:呈线性则残差正态分布。