Python爬虫 拉勾网招聘爬取
Python爬虫 拉勾网招聘爬取
运行平台: Windows
Python版本: Python3.6
IDE: Sublime Text
其他工具: Chrome浏览器
文章目录
- Python爬虫 拉勾网招聘爬取
-
- 0、打开搜索页
- 1、找到职位连接
- 2、打开职位详情页面,解析职位详情信息
-
- 2.1、详情页面解析
- 2.2 、代码实现
- 3、将获得数据写入CSV或TXT文件
-
- 3.1、求出平均工资
- 4、数据分析
-
- 4.1 工资统计
- 4.2 工作经验统计
- 4.3 职位词频描述
- 4.3.1 读取TXT文件
- 4.3.2 调用stopword,添加自定义字典和词频统计
- 4.3.3 词频可视化:词云
- 邮件发送
- 其他想法
- 完整代码
0、打开搜索页
首先需要安装selenium库 pip install selenium
运用selenium工具,打开搜索页
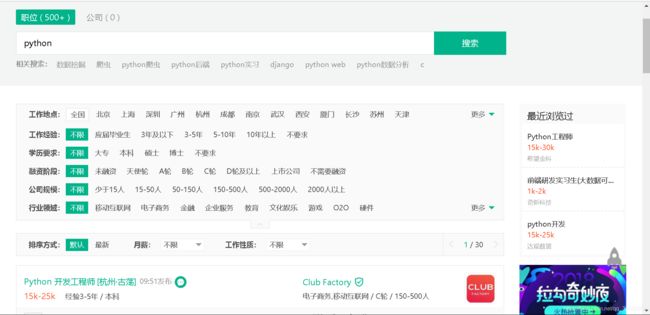
实现代码如下
self.driver = webdriver.Chrome()
self.url = 'https://www.lagou.com/jobs/list_python?px=default&city=%E5%85%A8%E5%9B%BD#filterBox'
1、找到职位连接
为了得到详情页面,我们需要在搜索完成后,找到职位详情页面的连接,操作如下
运用xpath工具找到该连接:
def page_list_details(self, source):
html = etree.HTML(source)
links = html.xpath('//a[@class="position_link"]/@href')
for link in links:
self.request_details(link)
time.sleep(2)
2、打开职位详情页面,解析职位详情信息
2.1、详情页面解析
由第一步得到的页面URL地址,打开详情页面,在游览器打开后,找到我们所需要的数据:
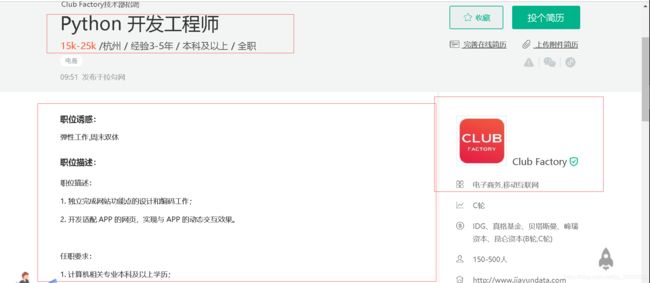
在开发者项并运用xpath工具检验能否得到数据:
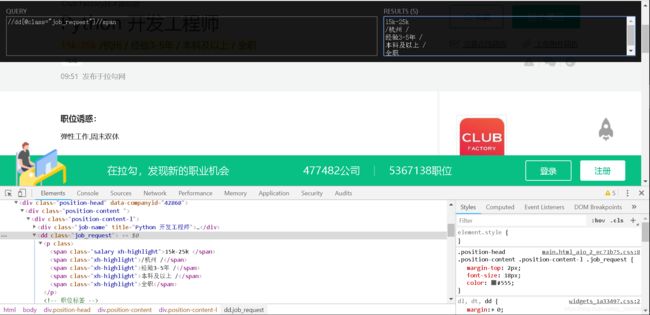
2.2 、代码实现
首先需要具备xpath语法知识,安装lxml库: pip install lxml
def request_details(self, link):
self.driver.execute_script("window.open('%s')" % link)
self.driver.switch_to_window(self.driver.window_handles[1])
source = self.driver.page_source
html = etree.HTML(source)
WebDriverWait(self.driver, timeout=5).until(
EC.presence_of_element_located((By.XPATH, '//span[@class="name"]'))
)
name = html.xpath('//span[@class="name"]/text()')[0].strip()
company = html.xpath('//h2[@class="fl"]/text()')[0].strip()
# salary = html.xpath('//span[@class="salary"]/text()')
job_request = html.xpath('//dd[@class="job_request"]//span/text()')
salary = job_request[0].strip()
city = re.sub(r'[\s/]', '', job_request[1])
experience = job_request[2]
experience = re.sub(r'[\s/]', '', experience)
education = re.sub(r'[\s/]', '', job_request[3])
job_desc = ''.join(html.xpath('//dd[@class="job_bt"]//text()')).strip()
position_detail = {
'name': name,
'city': city,
'company': company,
'salary': salary,
'experience': experience,
'education': education,
# 'job_desc': job_desc
}
self.write_text(job_desc)
self.position_details.append(position_detail)
self.write_csv_rows(self.headers, position_detail)
self.driver.close()
self.driver.switch_to_window(self.driver.window_handles[0])
3、将获得数据写入CSV或TXT文件
将职位描述写入TXT文件,便于词频统计,其余信息写入CSV文件
def write_csv_headles(self, headers):
with open('lagou_positions.csv', 'a', encoding='utf-8', newline='') as f:
position_headline = csv.DictWriter(f, headers)
position_headline.writeheader()
def write_text(self, job_desc):
with open('lagou_position_details.txt', 'a', encoding='utf-8') as f:
f.write('\n------------------------------------------------' + '\n')
f.write(job_desc)
def write_csv_rows(self, headers, position_detail):
with open('lagou_positions.csv', 'a', encoding='utf-8', newline='') as f:
position_headlines = csv.DictWriter(f, headers)
position_headlines.writerow(position_detail)
3.1、求出平均工资
读取CSV文件,获得所有工资信息
工资只有一种形式 ×k-×k,取出数值求平均,乘以1000即可
def read_lagou_information(self, column):
with open('lagou_positions.csv', 'r', encoding='utf-8', newline='') as f:
salary_reader = csv.reader(f)
return [row[column] for row in salary_reader]
sal = self.read_lagou_information(3)
for i in range(len(sal)-1):
requre_sal = sal[i+1]
requre_sal = re.sub(r'k', '', requre_sal)
inx = requre_sal.find('-')
average_sal = (int(requre_sal[0:inx]) + int(requre_sal[inx+1:]))/2
requre_sal = average_sal * 1000
4、数据分析
4.1 工资统计
运用饼状图显示各个工资阶层的分布情况
def analyse_industry_salary(self):
sal = self.read_lagou_information(3)
for i in range(len(sal)-1):
requre_sal = sal[i+1]
requre_sal = re.sub(r'k', '', requre_sal)
inx = requre_sal.find('-')
average_sal = (int(requre_sal[0:inx]) + int(requre_sal[inx+1:]))/2
requre_sal = average_sal * 1000
if requre_sal < 2000:
self.salaries_distribute['2k以下'] += 1
elif requre_sal < 5000:
self.salaries_distribute['2k-5k'] += 1
elif requre_sal < 10000:
self.salaries_distribute['5k-10k'] += 1
elif requre_sal < 25000:
self.salaries_distribute['10k-25k'] += 1
elif requre_sal < 50000:
self.salaries_distribute['25k-50k'] += 1
else:
self.salaries_distribute['50k以上'] += 1
plt.rcParams['font.sans-serif'] = ['SimHei']
# print(self.salaries_distribute)
labels = list(self.salaries_distribute.keys())
values = list(self.salaries_distribute.values())
# explode = (0.5, 0.5, 0, 0, 0, 0.1)
plt.pie(values, labels=labels, autopct='%2.0f%%', labeldistance=1.1,
startangle=90, pctdistance=0.8)
plt.axis('equal')
plt.legend(loc='upper right', bbox_to_anchor=(1.1, 1.1))
plt.grid()
plt.show()
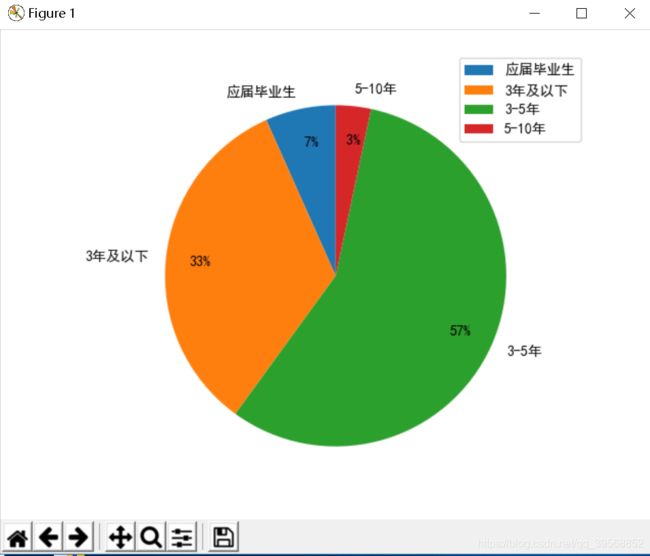
4.2 工作经验统计
运用饼状图显示工作经验分布
def analyse_work_experience(self):
work_experience = self.read_lagou_information(4)
for i in range(len(work_experience)-1):
requre_experience = work_experience[i+1]
if requre_experience == '经验不限' or requre_experience == '经验应届毕业生':
self.experience_distribute['应届毕业生'] += 1
elif requre_experience == '经验1-3年' or requre_experience == '经验1年以下':
self.experience_distribute['3年及以下'] += 1
elif requre_experience == '经验3-5年':
self.experience_distribute['3-5年'] += 1
elif requre_experience == '经验5-10年':
self.experience_distribute['5-10年'] += 1
plt.rcParams['font.sans-serif'] = ['SimHei']
# print(self.salaries_distribute)
labels = list(self.experience_distribute.keys())
values = list(self.experience_distribute.values())
plt.pie(values, labels=labels, autopct='%2.0f%%', labeldistance=1.1,
startangle=90, pctdistance=0.8)
plt.axis('equal')
plt.legend(loc='upper right', bbox_to_anchor=(1, 1.1))
plt.grid()
# plt.title('经验分布图')
plt.show()
4.3 职位词频描述
对职位的任职要求进行词频分析,可以便于应届生找工作和需要换工作的人群,提前了解工作技能基本要求和加分项,检验自己是否符合岗位要求;提前做好就业和跳槽准备
词频统计用到了 jieba、numpy、pandas、scipy库。如果电脑上没有这两个库,执行安装指令:
pip install jieba
pip install pandas
pip install numpy
pip install scipy
4.3.1 读取TXT文件
将以保存的项目描述TXT文件,读取出来:
def read_lagou_details(self):
with open('lagou_position_details.txt', 'r', encoding='utf-8', newline='') as f:
return f.read()
4.3.2 调用stopword,添加自定义字典和词频统计
在此处调用停用表stopword,即为剔除职位描述中不需要的词语。自定义字典是为了,添加jieba词库里面没有的词,提高新词匹配正确率。 停用表stopword.txt 百度自行下载
def demand_technology_rock(self):
content = self.read_lagou_details().strip()
content = re.sub(r'\s', '', content)
jieba.load_userdict('config/usercorpus.txt')
segment = jieba.lcut(content)
word_segment = pd.DataFrame({'segment': segment})
stopwords = pd.read_csv('config/stopwords.txt', index_col=False, quoting=3, sep=' ', names=['stopword'], encoding='utf-8')
global word_rock
word_segment = word_segment[~word_segment.segment.isin(stopwords.stopword)]
word_rock = word_segment.groupby(by=['segment'])['segment'].agg({'计数':numpy.size})
word_rock = word_rock.reset_index().sort_values(by=['计数'], ascending=False)
print(word_rock)
self.request_technogies_ciyun()
### 运行结果
segment 计数
504 开发 103
806 经验 64
257 优先 55
551 技术 47
873 设计 40
235 产品 38
793 系统 37
86 Python 35
578 描述 34
843 良好 32
832 能力 32
857 要求 26
648 服务 25
667 框架 24
492 年 24
273 使用 24
607 数据 24
402 团队 23
817 编程 23
254 任职 23
610 数据库 22
258 优化 21
317 分析 18
686 沟通 18
720 熟练掌握 18
302 具备 17
196 业务 17
491 平台 16
737 理解 16
249 以上学历 16
.. ... ...
539 战斗力 1
540 战略 1
541 截止 1
542 户外 1
146 pep8 1
145 nsq 1
546 扩展 1
547 找到 1
144 nginx 1
550 技巧 1
147 product 1
530 想法 1
154 saas 1
527 总结 1
506 开发工具 1
507 开发技术 1
510 引入 1
152 pythonweb 1
512 弹性 1
150 pylint 1
149 pyQT 1
517 影响 1
518 微 1
519 心情 1
520 必备 1
522 思想 1
523 思维 1
524 思路 1
525 性 1
486 带领 1
从上面打印的结果可以看出,还是有某些词语是不需要的,我们可以自行在stopword里自行添加。
同理,我们也可以在自定义字典里,添加重要的新词,来达到更加完美的效果。
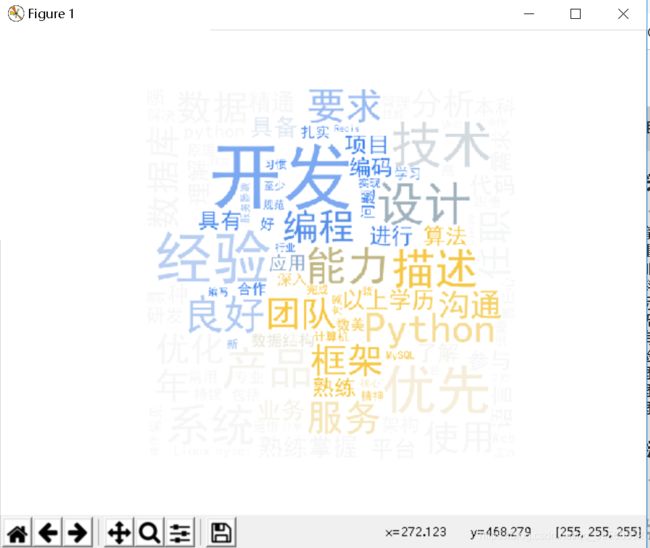
4.3.3 词频可视化:词云
最后,进行词频可视化。
def request_technogies_ciyun(self):
color_mask = imread('config/timg.jpg')
wordcloud = WordCloud(
font_path='simhei.ttf',
background_color='white',
max_words=100,
mask=color_mask,
max_font_size=100,
random_state=42,
width=1000,
height=860,
margin=2
)
word_rock_requence = {x[0]: x[1]for x in word_rock.head(100).values}
# word_rock_requence_dict = {}
# for key in word_rock_requence:
# word_rock_requence_dict[key] = word_rock_requence[key]
wordcloud.generate_from_frequencies(word_rock_requence)
image_colors = ImageColorGenerator(color_mask)
wordcloud.recolor(color_func=image_colors)
wordcloud.to_file('config/rock_key.png')
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
邮件发送
将岗位分析结果,通过邮件发送的形式,发送给他人:
my_sender = '×××××××@163.com' # 发件人邮箱账号
my_pass = '××××××××' # 发件人邮箱密码
my_user = '×××××××@163.com' # 收件人邮箱账号,我这边发送给自己
ret = True
try:
msg = MIMEMultipart()
msg.attach(MIMEText('工作分析结果请看附件','plain','utf-8'))
# msgAlternative = MIMEMultipart('alternative')
# msg.attach(msgAlternative)
msg['From']=formataddr(["FromRunoob", my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
msg['To']=formataddr(["FK",my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
msg['Subject']="拉钩网职业分析" # 邮件的主题,也可以说是标题
csv_att = MIMEText(open('lagou_positions.csv', 'rb').read(), 'base64', 'utf-8')
csv_att["Content-Type"] = 'application/octet-stream'
# 这里的filename可以任意写,写什么名字,邮件中显示什么名字
csv_att["Content-Disposition"] = 'attachment; filename="lagou.csv"'
msg.attach(csv_att)
# mail_msg = """
# Python 邮件发送测试...
#
# 图片演示:
# 
# """
# msgAlternative.attach(MIMEText(mail_msg, 'html', 'utf-8'))
# msg.attach(MIMEText(mail_msg, 'plain', 'utf-8'))
sendimagefile = open('config/rock_key.png', 'rb')
image = MIMEImage(sendimagefile.read())
image.add_header('Content-ID', '')
msg.attach(image)
txt_att = MIMEText(open('test.txt', 'rb').read(), 'base64', 'utf-8')
txt_att["Content-Type"] = 'application/octet-stream'
# 这里的filename可以任意写,写什么名字,邮件中显示什么名字
txt_att["Content-Disposition"] = 'attachment; filename="test.txt"'
msg.attach(txt_att)
server=smtplib.SMTP_SSL("smtp.163.com", 465) # 发件人邮箱中的SMTP服务器,端口是25
server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码
server.sendmail(my_sender,[my_user,],msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.quit() # 关闭连接
实现结果如图

其他想法
我们可以自定义配置文件,然后所有IT行业在全国各地,各地热门行业等进行分析。
完整代码
from selenium import webdriver
from lxml import etree
import re
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import csv
import pandas as pd
import matplotlib.pyplot as plt
import jieba
import numpy
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
class LagouSpider(object):
headers = ['name', 'city', 'company', 'salary', 'experience', 'education']
position_details = []
salaries_distribute = {'2k以下': 0, '2k-5k': 0, '5k-10k': 0, '10k-25k': 0, '25k-50k': 0, '50k以上': 0}
experience_distribute = {'应届毕业生': 0, '3年及以下': 0, '3-5年': 0, '5-10年': 0}
def __init__(self):
# self.driver = webdriver.Chrome()
self.url = 'https://www.lagou.com/jobs/list_python?px=default&city=%E5%85%A8%E5%9B%BD#filterBox'
def run(self):
self.demand_technology_rock()
self.analyse_industry_salary()
self.analyse_work_experience()
# self.driver.get(self.url)
# self.write_csv_headles(self.headers)
# while True:
# source = self.driver.page_source
# self.page_list_details(source)
# WebDriverWait(self.driver, timeout=10).until(
# EC.presence_of_element_located((By.XPATH, '//div[@class="pager_container"]/span[last()]'))
# )
# pager_next = self.driver.find_element_by_xpath('//div[@class="pager_container"]/span[last()]')
# if 'pager_next_disabled' in pager_next.get_attribute('class'):
# break
# else:
# pager_next.click()
# time.sleep(2)
def page_list_details(self, source):
html = etree.HTML(source)
links = html.xpath('//a[@class="position_link"]/@href')
for link in links:
self.request_details(link)
time.sleep(2)
# break
def request_details(self, link):
self.driver.execute_script("window.open('%s')" % link)
self.driver.switch_to_window(self.driver.window_handles[1])
source = self.driver.page_source
html = etree.HTML(source)
WebDriverWait(self.driver, timeout=5).until(
EC.presence_of_element_located((By.XPATH, '//span[@class="name"]'))
)
name = html.xpath('//span[@class="name"]/text()')[0].strip()
company = html.xpath('//h2[@class="fl"]/text()')[0].strip()
# salary = html.xpath('//span[@class="salary"]/text()')
job_request = html.xpath('//dd[@class="job_request"]//span/text()')
salary = job_request[0].strip()
city = re.sub(r'[\s/]', '', job_request[1])
experience = job_request[2]
experience = re.sub(r'[\s/]', '', experience)
education = re.sub(r'[\s/]', '', job_request[3])
job_desc = ''.join(html.xpath('//dd[@class="job_bt"]//text()')).strip()
position_detail = {
'name': name,
'city': city,
'company': company,
'salary': salary,
'experience': experience,
'education': education,
# 'job_desc': job_desc
}
self.write_text(job_desc)
self.position_details.append(position_detail)
self.write_csv_rows(self.headers, position_detail)
self.driver.close()
self.driver.switch_to_window(self.driver.window_handles[0])
def write_csv_headles(self, headers):
with open('lagou_positions.csv', 'a', encoding='utf-8', newline='') as f:
position_headline = csv.DictWriter(f, headers)
position_headline.writeheader()
def write_text(self, job_desc):
with open('lagou_position_details.txt', 'a', encoding='utf-8') as f:
f.write('\n------------------------------------------------' + '\n')
f.write(job_desc)
def write_csv_rows(self, headers, position_detail):
with open('lagou_positions.csv', 'a', encoding='utf-8', newline='') as f:
position_headlines = csv.DictWriter(f, headers)
position_headlines.writerow(position_detail)
def read_lagou_information(self, column):
with open('lagou_positions.csv', 'r', encoding='utf-8', newline='') as f:
salary_reader = csv.reader(f)
return [row[column] for row in salary_reader]
def analyse_industry_salary(self):
sal = self.read_lagou_information(3)
for i in range(len(sal)-1):
requre_sal = sal[i+1]
requre_sal = re.sub(r'k', '', requre_sal)
inx = requre_sal.find('-')
average_sal = (int(requre_sal[0:inx]) + int(requre_sal[inx+1:]))/2
requre_sal = average_sal * 1000
if requre_sal < 2000:
self.salaries_distribute['2k以下'] += 1
elif requre_sal < 5000:
self.salaries_distribute['2k-5k'] += 1
elif requre_sal < 10000:
self.salaries_distribute['5k-10k'] += 1
elif requre_sal < 25000:
self.salaries_distribute['10k-25k'] += 1
elif requre_sal < 50000:
self.salaries_distribute['25k-50k'] += 1
else:
self.salaries_distribute['50k以上'] += 1
plt.rcParams['font.sans-serif'] = ['SimHei']
# print(self.salaries_distribute)
labels = list(self.salaries_distribute.keys())
values = list(self.salaries_distribute.values())
# explode = (0.5, 0.5, 0, 0, 0, 0.1)
plt.pie(values, labels=labels, autopct='%2.0f%%', labeldistance=1.1,
startangle=90, pctdistance=0.8)
plt.axis('equal')
plt.legend(loc='upper right', bbox_to_anchor=(1.1, 1.1))
plt.grid()
# plt.title('经验分布图')
plt.show()
def analyse_work_experience(self):
work_experience = self.read_lagou_information(4)
for i in range(len(work_experience)-1):
requre_experience = work_experience[i+1]
if requre_experience == '经验不限' or requre_experience == '经验应届毕业生':
self.experience_distribute['应届毕业生'] += 1
elif requre_experience == '经验1-3年' or requre_experience == '经验1年以下':
self.experience_distribute['3年及以下'] += 1
elif requre_experience == '经验3-5年':
self.experience_distribute['3-5年'] += 1
elif requre_experience == '经验5-10年':
self.experience_distribute['5-10年'] += 1
plt.rcParams['font.sans-serif'] = ['SimHei']
# print(self.salaries_distribute)
labels = list(self.experience_distribute.keys())
values = list(self.experience_distribute.values())
plt.pie(values, labels=labels, autopct='%2.0f%%', labeldistance=1.1,
startangle=90, pctdistance=0.8)
plt.axis('equal')
plt.legend(loc='upper right', bbox_to_anchor=(1, 1.1))
plt.grid()
# plt.title('经验分布图')
plt.show()
def read_lagou_details(self):
with open('lagou_position_details.txt', 'r', encoding='utf-8', newline='') as f:
return f.read()
def demand_technology_rock(self):
content = self.read_lagou_details().strip()
content = re.sub(r'\s', '', content)
jieba.load_userdict('config/usercorpus.txt')
segment = jieba.lcut(content)
word_segment = pd.DataFrame({'segment': segment})
stopwords = pd.read_csv('config/stopwords.txt', index_col=False, quoting=3, sep=' ', names=['stopword'], encoding='utf-8')
global word_rock
word_segment = word_segment[~word_segment.segment.isin(stopwords.stopword)]
word_rock = word_segment.groupby(by=['segment'])['segment'].agg({'计数':numpy.size})
word_rock = word_rock.reset_index().sort_values(by=['计数'], ascending=False)
print(word_rock)
self.request_technogies_ciyun()
def stopwordslist(self):
stopwords = [line.strip() for line in open('config/stopwords.txt', 'r', encoding='utf-8').readlines()]
return stopwords
def request_technogies_ciyun(self):
color_mask = imread('config/timg.jpg')
wordcloud = WordCloud(
font_path='simhei.ttf',
background_color='white',
max_words=100,
mask=color_mask,
max_font_size=100,
random_state=42,
width=1000,
height=860,
margin=2
)
word_rock_requence = {x[0]: x[1]for x in word_rock.head(100).values}
# word_rock_requence_dict = {}
# for key in word_rock_requence:
# word_rock_requence_dict[key] = word_rock_requence[key]
wordcloud.generate_from_frequencies(word_rock_requence)
image_colors = ImageColorGenerator(color_mask)
wordcloud.recolor(color_func=image_colors)
wordcloud.to_file('config/rock_key.png')
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
if __name__ == "__main__":
lagouspider = LagouSpider()
lagouspider.run()