Python自然语言处理 第一章 课后习题答案
前言:从今天开始正式学习自然语言处理,同时还有统计学习方法和机器学习。希望能够一直坚持下去。
(以下答案非标准答案,如有错误请积极回复。谢谢理解。)
正文
在开始之前首先引入nltk和nltk.book
import nltk
from nltk.book import *
- ○尝试使用Python 解释器作为一个计算器,输入表达式,如12/(4+1)。
12/(4+1)
output:2.4
- ○26 个字母可以组成26 的10 次方或者26**10个 10字母长的字符串。也就是 1411 67095653376L(结尾处的 L 只是表示这是 Python长数字格式)。100 个字母长度的 字符串可能有多少个?
26**100
output:3142930641582938830174357788501626427282669988762475256374173175398995908420104023465432599069702289330964075081611719197835869803511992549376
- ○Python 乘法运算可应用于链表。当你输入[‘Monty’, ‘Python’] * 20或者 3 * se nt1会发生什么?
print(['Monty','Python'] * 20)
print(3 * sent1)
output:['Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python']
['Call', 'me', 'Ishmael', '.', 'Call', 'me', 'Ishmael', '.', 'Call', 'me', 'Ishmael', '.']
- ○复习 1.1节关于语言计算的内容。在 text2中有多少个词?有多少个不同的词?
print(len(text2),len(set(text2)))
output:141576 6833
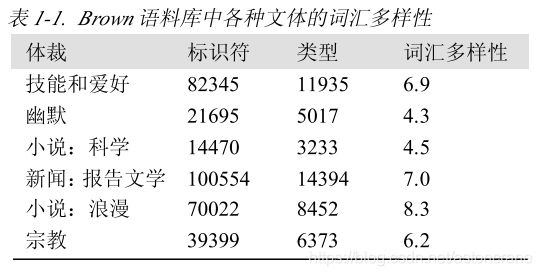
- ○比较表格 1-1 中幽默和言情小说的词汇多样性得分,哪一个文体中词汇更丰富?
- ○制作《理智与情感》中四个主角:Elinor,Marianne,Edward和Willoughby 的分布图。 在这部小说中关于男性和女性所扮演的不同角色,你能观察到什么?你能找出一对夫妻 吗?
text2.dispersion_plot(["Elinor","Marianne","Edward","Willoughby"])

由图所知大概Elinor和Marianne是一对夫妻,另外两人是另一对夫妻。
- ○查找 text5 中的搭配。
text5.collocation_list()
output:['wanna chat', 'PART JOIN', 'MODE #14-19teens', 'JOIN PART', 'PART PART', 'cute.-ass MP3', 'MP3 player', 'JOIN JOIN', 'times .. .', 'ACTION watches', 'guys wanna', 'song lasts', 'last night', 'ACTION sits', '-...)...- S.M.R.', 'Lime Player', 'Player 12%', 'dont know', 'lez gurls', 'long time']
- ○思考下面的 Python表达式:len(set(text4))。说明这个表达式的用途。描述在执行 此计算中涉及的两个步骤。
len(set(text4))
output:9913
该表达式由len()和set()两个方法组成,其含义为text4中不同词数的数量。
- ○复习 1.2节关于链表和字符串的内容。
- a. 定义一个字符串,并且将它分配给一个变量,如:my_string = ‘My String’(在 字符串中放一些更有趣的东西)。用两种方法输出这个变量的内容,一种是通过简 单地输入变量的名称,然后按回车;另一种是通过使用 print 语句。
my_string = 'My String'
print(my_string)
my_string
output:My String 'My String'
- b. 尝试使用my_string+ my_string 或者用它乘以一个数将字符串添加到它自身, 例如:my_string* 3。请注意,连接在一起的字符串之间没有空格。怎样能解决 这个问题?
print(my_string+my_string,'\n'+
my_string*3,'\n'+
my_string+' '+my_string)
output:My StringMy String
My StringMy StringMy String
My String My String
- ○使用的语法my_sent = [“My”, “sent”],定义一个词链表变量my_sent(用你 自己的词或喜欢的话)。
- a. 使用’ '.join(my_sent)将其转换成一个字符串。
my_sent = [My","sent"]
msent1 = ''.join(my_sent)
print(msent1)
output:Mysent
- b. 使用 split()在你指定的地方将字符串分割回链表。
msent2 = msent1.split("s")
print(msent2)
output:['My', 'ent']
- ○定义几个包含词链表的变量,例如:phrase1,phrase2等。将它们连接在一起组
成不同的组合(使用加法运算符),最终形成完整的句子。len(phrase1 + phrase2)
与 len(phrase1) + len(phrase2)之间的关系是什么?
phrase1 = ["123", "is"]
phrase2 = ["my", "password"]
print(phrase1 + phrase2)
print(len(phrase1 + phrase2))
print(len(phrase1)+len(phrase2))
output:['123', 'is', 'my', 'password']
4
4
len(phrase1 + phrase2)是先连接字符串后计算字符串长度
len(phrase1)+len(phrase2)则是依次计算长度后,计算长度的和
- ○考虑下面两个具有相同值的表达式。哪一个在NLP 中更常用?为什么?
a.“Monty Python”[6:12]
b.[“Monty”, “Python”][1]
print("Monty Python"[6:12])
print(["Monty", "Python"][1])
output:Python
Python
前者是取字符串的切片,后者是取列表项。明显后者在任何机器学习的领域中更常用。
- ○我们已经看到如何用词链表表示一个句子,其中每个词是一个字符序列。sent1[2][2]代表什么意思?为什么?请用其他的索引值做实验。
sent1[2][2]
output:'h'
sent[2]的输出是’Ishmael’,该式相当于’Ishmael’[2]即字符串的第三个字符:'h’
- ○在变量 sent3中保存的是 text3的第一句话。在 sent3中 the的索引值是1,因为sent3[1]的值是“the”。sent3中“the”的其它出现的索引值是多少?
for i in range(len(sent3)):
if sent3[i] == 'the':
print(i)
output:1
5
8
- ○复习 1.4 节讨论的条件语句。在聊天语料库(text5)中查找所有以字母 b开头的词。
按字母顺序显示出来。
sorted([word for word in set(text5) if word.startswith('b')])
output:['b', 'b-day', 'b/c', 'b4', 'babay', 'babble', 'babblein', 'babe', 'babes', 'babi', 'babies', 'babiess', 'baby', 'babycakeses', 'bachelorette', 'back', 'backatchya', 'backfrontsidewaysandallaroundtheworld', 'backroom', 'backup', 'bacl', 'bad', 'bag', 'bagel', 'bagels', 'bahahahaa', 'bak', 'baked', 'balad', 'balance', 'balck', 'ball', 'ballin', 'balls', 'ban', 'band', 'bandito', 'bandsaw', 'banjoes', 'banned', 'baord', 'bar', 'barbie', 'bare', 'barely', 'bares', 'barfights', 'barks', 'barn', 'barrel', 'base', 'bases', 'basically', 'basket', 'battery', 'bay', 'bbbbbyyyyyyyeeeeeeeee', 'bbiam', 'bbl', 'bbs', 'bc', 'be', 'beach', 'beachhhh', 'beam', 'beams', 'beanbag', 'beans', 'bear', 'bears', 'beat', 'beaten', 'beatles', 'beats', 'beattles', 'beautiful', 'because', 'beckley', 'become', 'bed', 'bedford', 'bedroom', 'beeeeehave', 'beeehave', 'been', 'beer', 'before'...(以下省略)
- ○在 Python解释器提示符下输入表达式 range(10)。再尝试range(10, 20), range(10, 20, 2)和 range(20, 10, -2)。在后续章节中我们将看到这个内置函数的多用用途。
print(list(range(10)),
list(range(10, 20)),
list(range(10, 20, 2)),
list(range(20, 10, -2)))
output:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [10, 11, 12, 13, 14, 15, 16, 17, 18, 19] [10, 12, 14, 16, 18] [20, 18, 16, 14, 12]
- ◑使用 text9.index()查找词 sunset 的索引值。你需要将这个词作为一个参数插入到圆括号之间。通过尝试和出错的过程中,找到完整的句子中包含这个词的切片。
text9.index('sunset')
startin = 0
endin = len(text9)
for i in range(629, 1, -1):
if text9[i] == '.' or text9[i] == '?' or text9[i] == '!':
startin = i
break;
for i in range(629, endin):
if text9[i] == '.' or text9[i] == '?' or text9[i] == '!':
endin = i
break;
print(text9[startin+1:endin+1])
output:['CHAPTER', 'I', 'THE', 'TWO', 'POETS', 'OF', 'SAFFRON', 'PARK', 'THE', 'suburb', 'of', 'Saffron', 'Park', 'lay', 'on', 'the', 'sunset', 'side', 'of', 'London', ',', 'as', 'red', 'and', 'ragged', 'as', 'a', 'cloud', 'of', 'sunset', '.']
- ◑使用链表加法、set 和sorted操作,计算句子sent1…sent8的词汇表。
word_list = set(sent1 + sent2 + sent3 + sent4 + sent5 + sent6 + sent7 + sent8)
print(sorted(word_list))
output:['!', ',', '-', '.', '1', '25', '29', '61', ':', 'ARTHUR', 'Call', 'Citizens', 'Dashwood', 'Fellow', 'God', 'House', 'I', 'In', 'Ishmael', 'JOIN', 'KING', 'MALE', 'Nov.', 'PMing', 'Pierre', 'Representatives', 'SCENE', 'SEXY', 'Senate', 'Sussex', 'The', 'Vinken', 'Whoa', '[', ']', 'a', 'and', 'as', 'attrac', 'been', 'beginning', 'board', 'clop', 'created', 'director', 'discreet', 'earth', 'encounters', 'family', 'for', 'had', 'have', 'heaven', 'in', 'join', 'lady', 'lol', 'long', 'me', 'nonexecutive', 'of', 'old', 'older', 'people', 'problem', 'seeks', 'settled', 'single', 'the', 'there', 'to', 'will', 'wind', 'with', 'years']
- ◑下面两行之间的差异是什么?哪一个的值比较大?其他文本也是同样情况吗?
>>> sorted(set([w.lower() for w in text1]))
>>> sorted([w.lower() for w in set(text1)]
print(len(sorted(set([w.lower() for w in text1]))))
print(len(sorted([w.lower() for w in set(text1)])))
output:17231
19317
前者是先循环读取了text1中的所有词后更新为小写格式后用set()筛选了不同的词。
后者是先将text1中的不同词筛选完毕后,循环读取其中的词再更新为小写。所以后者再进入列表时,大小写的词是被当成两个词的。
- ◑w.isupper()和not w.islower()这两个测试之间的差异是什么?
w = ']'
print(w.isupper())
print(not w.islower())
output:False
True
前者用来判断w是不是一个大写字母,True时可确定w是大写字母,False时无法确定w是什么。
后者则只能确定w是不是一个小写字母,True时不可确定w是什么,False时确定w是个小写字母
- ◑写一个切片表达式提取 text2 中最后两个词。
text2[-2::1]
output:['THE', 'END']
- ◑找出聊天语料库(text5)中所有四个字母的词。使用频率分布函数(FreqDist),以频率从高到低显示这些词。
FreqDist([word for word in text5 if len(word)==4])
output:FreqDist({'JOIN': 1021, 'PART': 1016, 'that': 274, 'what': 183, 'here': 181, '....': 170, 'have': 164, 'like': 156, 'with': 152, 'chat': 142, ...})
- ◑复习 1.4 节中条件循环的讨论。使用 for 和 if语句组合循环遍历《巨蟒和圣杯》(text6)的电影剧本中的词,输出所有的大写词,每行输出一个。
set([word for word in text6 if word.isupper()])
output:{'A', 'ALL', 'AMAZING', 'ANIMATOR', 'ARMY', 'ARTHUR', 'B', 'BEDEVERE', 'BLACK', 'BORS', 'BRIDE', 'BRIDGEKEEPER', 'BROTHER', 'C', 'CAMERAMAN', 'CART', 'CARTOON', 'CHARACTER', 'CHARACTERS', 'CONCORDE', 'CRAPPER', 'CRASH', 'CRONE', 'CROWD', 'CUSTOMER', 'DEAD', 'DENNIS', 'DINGO', 'DIRECTOR', 'ENCHANTER', 'FATHER', 'FRENCH', 'GALAHAD', 'GIRLS', 'GOD', 'GREEN', 'GUARD', 'GUARDS', 'GUEST', 'GUESTS', 'HEAD', 'HEADS', 'HERBERT', 'HISTORIAN', 'I', 'INSPECTOR', 'KING', 'KNIGHT', 'KNIGHTS', 'LAUNCELOT', 'LEFT', 'LOVELY', 'LUCKY', 'MAN', 'MASTER', 'MAYNARD', 'MIDDLE', 'MIDGET', 'MINSTREL', 'MONKS', 'N', 'NARRATOR', 'NI', 'O', 'OF', 'OFFICER', 'OLD', 'OTHER', 'PARTY', 'PATSY', 'PERSON', 'PIGLET', 'PRINCE', 'PRINCESS', 'PRISONER', 'RANDOM', 'RIGHT', 'ROBIN', 'ROGER', 'S', 'SCENE', 'SECOND', 'SENTRY', 'SHRUBBER', 'SIR', 'SOLDIER', 'STUNNER', 'SUN', 'THE', 'TIM', 'U', 'VILLAGER', 'VILLAGERS', 'VOICE', 'W', 'WIFE', 'WINSTON', 'WITCH', 'WOMAN', 'Y', 'ZOOT'}
- ◑写表达式找出 text6中所有符合下列条件的词。结果应该是词链表的形式:[‘word
1’, ‘word2’, …]。
a. 以 ize 结尾
b. 包含字母 z
c. 包含字母序列 pt
d. 除了首字母外是全部小写字母的词(即 titlecase)
print([word for word in text6 if word.endswith("ize")],
[word for word in text6 if 'z' in word],
[word for word in text6 if 'pt' in word],
[word for word in text6 if word.istitle()])
output:[] ['zone', 'amazes', 'Fetchez', 'Fetchez', 'zoop', 'zoo', 'zhiv', 'frozen', 'zoosh'] ['empty', 'aptly', 'Thpppppt', 'Thppt', 'Thppt', 'empty', 'Thppppt', 'temptress', 'temptation', 'ptoo', 'Chapter', 'excepting', 'Thpppt'] ['Whoa', 'Halt', 'Who', 'It', 'I', 'Arthur', 'Uther', 'Pendragon', 'Camelot', 'King', 'Britons', 'Saxons', 'England', 'Pull', 'I', 'Patsy', 'We', 'Camelot', 'I', 'What', 'Ridden', 'Yes', 'You', 'What', 'You', 'So', 'We', 'Mercea', 'Where', 'We', 'Found', 'In', 'Mercea', 'The', 'What', 'Well', 'The', 'Are', 'Not', 'They', 'What', 'A', 'It', 'It', 'It', 'A', 'Well', 'Will', 'Arthur', 'Court', 'Camelot', 'Listen', 'In', 'Please', 'Am', 'I', 'I', 'It', 'African', 'Oh'...(以下省略)
- ◑定义 sent 为词链表[‘she’, ‘sells’, ‘sea’, ‘shells’, ‘by’, ‘the’, ‘sea’, ‘shore’]。
编写代码执行以下任务:
- a. 输出所有 sh开头的单词
print([word for word in sent if word.startswith('sh')])
output:['she', 'shells', 'shore']
- b. 输出所有长度超过 4个字符的词
print([word for word in sent if len(word) > 4])
output:['sells', 'shells', 'shore']
- ◑下面的 Python 代码是做什么的?sum([len(w) for w in text1]),你可以用它来算出一个文本的平均字长吗?
sum1 = sum([len(w) for w in text1])#text1的字符总数
print(sum1 / len(text1))
output:3.830411128023649
- ◑定义一个名为 vocab_size(text)的函数,以文本作为唯一的参数,返回文本的词汇
量。
def vocab_size(text):
return len(text)
vocab_size(text1)
output:260819
- ◑定义一个函数 percent(word, text),计算一个给定的词在文本中出现的频率,结
果以百分比表示。
def percent(word, text):
word = word.lower()
count1 = 0
for w in text:
if len(w) == len(word):
chosen = word.lower()
if chosen == word:
count1 += 1;
return '%.2f%%' % (count1 / len(text))
percent('the',text1)
output:'0.19%'
- ◑我们一直在使用集合存储词汇表。试试下面的 Python表达式:set(sent3) < set(text1)。实验在 set()中使用不同的参数。它是做什么用的?你能想到一个实际的应用 吗?
set(text3) < set(text1)
output:False
可用来确定一个语料库是否是另一个语料库的子集。