Python爬虫学习笔记——Ajax数据抓取实战
前言
在学会了用requests,scrapy等工具爬取较为简单的数据后,接下来可以尝试一下较为复杂的网站。
很多网站,特别是做的比较漂亮的网页,在检查源代码的时候都会发现网页上的内容在源码里找不到,这是因为大部分较复杂的网页是由js渲染的,源代码里没有显示。js渲染的网页较为复杂,本次主要学习Ajax数据的分析及抓取。
Ajax
Ajax,即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML)。简单的来说,就是当你打开一个网页,发现一个网页框架先出来,其中某些内容要加载一段时间,甚至加载不出来,这就说明这个网页应用了Ajax异步加载。这时,仅仅使用Xpath或者BeautifulSoup就无法抓取想要的信息。这次学习以爬取商品价格网为例,介绍一下Ajax数据分析和抓取。
网页分析
因篇幅原因,本文只介绍第一个标签——价格行情里的数据抓取。简单的分析一下可以知道抓取应该分为两个部分,链接获取和数据获取。
链接获取页面
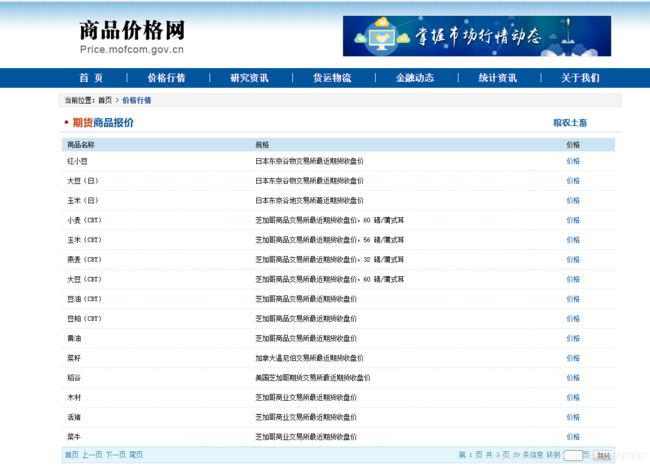
在之前简单网页爬取中,一般这个步骤是获取每个子网页的链接,但右键检查源代码的时候发现,源代码里并没有需要的内容。此时打开Chrome的开发者工具,选中‘Network’标签,会发现里面东西特别多,但是不用害怕,本次爬取只需要分析其中XHR文件(关于XHR文件请参考w3c教程)。
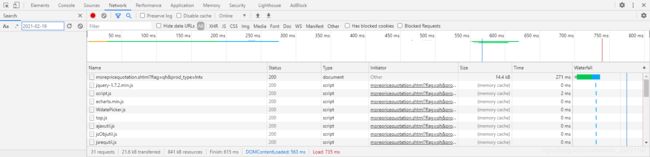
选中‘XHR’标签,经过一定的分析,可以发现链接数据放在‘codeDetailQuery’的标签里,选中‘codeDetailQuery’,点击‘Preview’,可以发现以json形式保存的数据
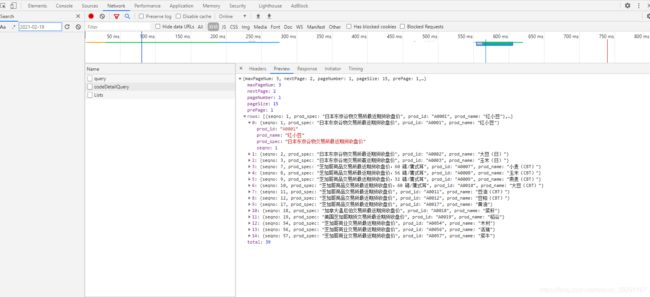
看到这里,你是不是会产疑问,链接在哪呢?别着急,再次选中‘Headers’选项。

是不是发现和之前爬取的网页不同,没错这里是Post请求,再复习一下Get和Post的区别。往深了说可以说很多,这里只说最最简单,最显著的区别,一般可以说“Get请求没有body,请求参数在URL里,Post的请求数据在request body里”。
反映到这里,就是Headers标签里的‘Form Data’这一块。

在实际数据爬取中,我们需要做的就是构建一个request body,把它和Request Url打包,post到服务器上。(注意此时的url不是地址栏的网址,是‘General’里的‘Request Url’)
而之前的链接数据其实就是构建request body中包含的信息。
代码编写
1)链接获取
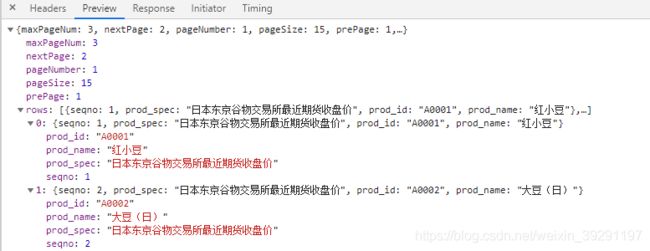
再来分析一下数据页面,以“红小豆”为例,按照之前的分析,数据在priceQueryList里,分析Form Data可以发现,构建爬虫需要的request body只需要‘seqno’的值,这在链接数据里显而易见。

下面开始写获取seqno的代码
def get_seqno(self, form_list_data):
'''
:param data: ajax request body
:return: 返回一个储存seqno的列表
'''
r = self.req(url=self.link_url, data = form_list_data)
seqnos = []
js = r.json()
for i in js['rows']:
seqnos.append(i['seqno'])
return seqnos
我们在获取seqno值的时候也是post请求,同样构建了一个request head,这时候我们来分析一下结构
self.form_list_data = {
'flag': '',
'prod_type': '',
'pageNumber': 1,
'pageSize': 15
}
对比一下网站的信息不难发现,‘flag’表示期货或者现货,‘prod_type’表示商品类型
‘pageNumber’表示页数。了解到这些后,获取链接的完整代码就很容易写出来了:
from fake_useragent import UserAgent
from retrying import retry
import requests
import random
import pymysql
class prduct_price(object):
def __init__(self):
self.flags = ['xh', 'qh']
self.prod_types = ['lntx', 'nyhg', 'jskc']
self.link_url = 'http://price.mofcom.gov.cn/datamofcom/front/price/pricequotation/codeDetailQuery'
self.form_list_data = {
'flag': '',
'prod_type': '',
'pageNumber': 1,
'pageSize': 15
}
# 可以使用代理
self.proxie_list = [
]
@retry(stop_max_attempt_number=10, wait_fixed=1000)
def req(self, url, data=None, headers=None):
'''
基于requests的改写
'''
if not headers:
headers = {
"User-Agent": UserAgent().random
}
splash_url = random.choice(self.proxie_list)
proxies = {
'http': splash_url, 'https': splash_url}
if data:
res = requests.post(url=url, headers=headers, proxies=proxies, data=data, timeout=10)
else:
res = requests.get(url=url, headers=headers, proxies=proxies, timeout=10)
res.raise_for_status()
return res
def get_maxPageNum(self, data):
"""
获取最大页数
:param data: ajax request body
:return: 最大页数
"""
r = self.req(url=self.link_url, data=data)
js = r.json()
maxPageNum = js['maxPageNum']
return maxPageNum
def get_seqno(self, data):
'''
:param data: ajax request body
:return: 返回一个储存seqno的列表
'''
r = self.req(url=self.link_url, data=data)
seqnos = []
js = r.json()
for i in js['rows']:
seqnos.append(i['seqno'])
return seqnos
def run(self):
'''
获取链接主函数
'''
for flag in self.flags:
for prod_type in self.prod_types:
list_form = self.form_list_data
list_form['flag'] = flag
list_form['prod_type'] = prod_type
maxPageNum = self.get_maxPageNum(data = list_form)
for num in range(maxPageNum):
list_form_new = list_form
list_form_new['pageNumber'] = num + 1
seqnos = self.get_seqno(data=list_form_new)
2)数据获取
有了之前的基础,接下来数据获取的部分就比较类似了。首先分析一下Request Body
self.form_index_data = {
'seqno': '',
'startTime': '',
'endTime': '',
'pageNumber': 1,
'pageSize': 10000,
}
我们需要关注的只是‘seqno’的值,代码编写就比较简单了
def get_data(self, data, flag, prod_type):
'''
调用ajax接口获取数据,接口获得的数据并不全,其中节点名称没有
:param data: 获取数据的申请头
:param name: 传入商品名称
:param flag: 传入节点信息
:param prod_type: 传入节点信息
:return: 以字典形式封装数据
'''
r = self.req(url=self.index_url, data=data)
js = r.json()
node_info = {
'xh': '现货',
'qh': '期货',
'lntx': '粮农土畜',
'nyhg': '能源化工',
'jskc': '金属矿物'
}
info_list = []
for i in js['rows']:
info = {
}
info['date'] = i['yyyy'] + '-' + i['mm'] + '-' + i['dd']
info['unit'] = i['unit']
info['price'] = i['price']
info['prod_spec'] = i['prod_spec']
info['name'] = i['prod_name']
info['node'] = node_info.get(flag) + '-' + node_info.get(prod_type)
info_list.append(info)
return info_list
3)写入数据库
通过pymysql库将数据写入数据库,这里每个人数据库设置都不一样,直接贴代码了。
def data_process(self, data_list):
'''
将文件写入数据库
:param data_list: 数据字典
:return:
'''
print('开始写入')
serverName = ''
user_name = ''
password = ''
db = pymysql.connect(user=user_name, password=password, host=serverName, database='spider')
cursor = db.cursor()
for data in data_list:
sql = """
INSERT INTO product_price
(NodeName,ProductName,Instruction,Unit,TransactionDate,QuotedPrice)
VALUES
('{node}','{name}','{prod_spec}','{unit}','{date}','{price}')
""".format(node=data['node'], name=data['name'], prod_spec=data['prod_spec'], unit=data['unit'],
date=data['date'], price=data['price'])
cursor.execute(sql)
# commit 放外面明显更快
db.commit()
print('写入完成')
db.close()
篇幅原因,完整源代码请点击这里
总结
本篇文章介绍了ajax数据的分析过程和爬取方法,这和之前简单的静态网页爬取区别也是比较大的。个人觉得这种抓包的爬取方式更为简单,毕竟不需要分析网页源码。最后对于本篇学习笔记有任何疑问或者批评,请随时写在评论区,或者私信我。