c语言基础回顾(1)五大板块 —— 数组,指针,结构体,链表,字符串
在 为什么要使用指针 板块:
参考:原文链接
作者:Cloudkip
在 printf 里的 a++,++a,真的有鬼!! 板块:
参考:原文链接
作者:seino_m
之前一直在学习linux系统编程,文件系统与树莓派,如今到智能家居项目,发现c语言的知识陌生了,优先强化相关应用。每天抽出点时间复习,回过头扎实一下c语言的基础吧。
还未完结,持续更新,活到老学到老!
师承陈立臣
基础回顾
- 一、数组
-
- 数组的定义及访问
-
- 完全初始化,部分初始化,不初始化
- 关于数组赋值,还需要注意:
-
- Ⅰ、大多情况下,数组在定义时必须确定大小
-
- 有啊,别用数组了,用指针呗
- Ⅱ 、数组的定义在下面三种情况下不需要指明大小
-
- ①数组是形式参数
- ②数组声明的同时进行了初始化
- ③数组的存储类型为extern
- Ⅲ、也不能直接给数组赋值字符串
-
- 用strcpy函数
- 数组的简单应用
-
- 1到100的和(数组的赋值)
- 比较5个数的大小(数组的遍历)
- 数组作为子函数的形式参数以及数组元素个数计算
- 二、指针
-
- 地址的引入
-
- 概念
- 地址长啥样?
- 指针变量的引入
- 指针分类型与指针偏移量
-
- 整型指针,字符指针
- 函数指针(重点)
-
- 无参无返的函数指针
- 有参有返的函数指针
- 结构体中的函数指针
- 规律总结
- 数组指针(少用)
- 指针数组(少用)
- 结构体指针(重点)
-
- 定义赋值调用与指针偏移
- 实际应用例子
- 野指针
-
- 是什么
- 野指针是怎样生成的?
- 有什么危害
- 如何避免
- malloc与内存泄漏
- 指针类型小测试
- 指针也可以作为数组传入的形式参数
- 为什么要使用指针?
-
- (1)节省内存
- (2)在子函数中修改被传递过来的对象
- (3)动态分配内存
- (4)在指定地址写入数据(目前少用)
- (5)函数多个返回值
- 三、结构体
-
- 结构体的三种定义赋值方法
- 结构体数组
- 结构体指针(在指针中已有介绍)
- 结构体的综合运用学生成绩处理
-
- 小问题:不会释放指针,或者需不需要释放?
- 结构体大小计算方法
- 四、链表
-
- 对比链表与数组
-
- 同样是存放一串数据,链表与数组的区别在哪里?
- 链表方便增删
- 链表的创建之静态创建:最简单的创建
- 链表的动态遍历:统计节点个数与查找节点
- 插入节点与删除节点
-
- 从指定节点的后方插入新节点
- 在指定节点前方插入新节点
- 删除指定节点
- 链表的创建之动态创建
-
- 头插法创建链表
- 尾插法创建链表
- 五、字符串
-
- 字符串的定义方式与输出
- 字符串的结尾是 ' \0 '
- 用strlen计算有效字符的长度
-
- strlen使用注意
- 字符串操作常用API
-
- puts、gets —— 输入与输出
- strcpy、strncpy —— 拷贝
- strcmp —— 比较
- strchr、strstr —— 检索
- strlwr、strupr —— 大小写转换
- strcat —— 拼接
- strtok —— 分割
-
- strtok容易出错的秘密
- 自己实现这些API
- 六、其他小知识点
一、数组
数组的定义及访问
完全初始化,部分初始化,不初始化
#include 运行结果:
可以看到不初始化的时候值是随机分配的,不建议采用这种方式。
1996072264 1 0 1995852616 67032 66992 0 66376 0 0
1 2 3 4 5
0 0 0 0 0
应该采用部分初始化,初始化第一个元素,其他元素的值默认为0
注意:
数组只有在定义的时候[ ]表示个数,其他时候都是下标。
数组的下标是从0开始,即数组的第一个元素是a[0]。
数组的最后一个元素是a[i-1]
关于数组赋值,还需要注意:
Ⅰ、大多情况下,数组在定义时必须确定大小
例如类似下面的情景,数组定义时大小是不确定的,妄图通过后续改变的num进行动态赋值,这样的操作往往出现段错误。
#include 结果:
Segmentation fault
是因为只有数组在定义的时候确定了大小,程序才能根据这个大小分配一段连续的内存空间给数组存放数据。
下面为探索过程-----------------
哎,我头铁,我就硬是要这样动态赋值!
- 会不会是一开始num的值不确定导致的呢?做出如下更改
//int num;
int num = 0;
结果是没有了段错误,但我选择输入5个学生的成绩,然而输入2或者3个就停下了,这样也不行。如下图:
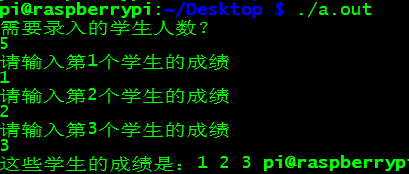
- 那我把数组的定义往下移动,放在scanf后面,等num的值确定了我再定义数组总该可以吧?好想法!
scanf("%d",&num);
int array[num];
这样程序的执行虽无问题,但却是一个不好的习惯。
C语言变量的定义最好要放在开头,否则有时候编译器会报错的 ,就是要先定义完变量,再做其他事。(是的,但这通常是发生在写32,51上,Keil的C51所采用的C标准是一个较早期的标准,在程序书写上有较多的限制。)
而在gcc编译器中变量的定义却可以放在程序任何位置。
上面为探索过程-----------------
那可咋办呀?我好想进行动态赋值啊。在录入成绩之前用户可以选择录入几个人,而不是在程序中写死,不香吗??
有啊,别用数组了,用指针呗
#include
parray++的时候指针已经到达所指向地址空间边界,要parray -= num回调才能读到里面的值。
结果:
zhu@ubuntu:~/Desktop$ ./a.out
需要录入的学生人数?
6
请输入第1个学生的成绩
65
请输入第2个学生的成绩
76
请输入第3个学生的成绩
54
请输入第4个学生的成绩
76
请输入第5个学生的成绩
87
请输入第6个学生的成绩
65
这些学生的成绩是:65 76 54 76 87 65
Ⅱ 、数组的定义在下面三种情况下不需要指明大小
①数组是形式参数
正是下文中数组的简单应用第3个例子
②数组声明的同时进行了初始化
int a[] = {
0,1,2,3};
根据实际情况,自动分配大小
③数组的存储类型为extern
嘿嘿,目前还没用过,用了来更新。
Ⅲ、也不能直接给数组赋值字符串
这个在下文中结构体的三种定义赋值方法也有涉及,这个情况也多见于结构体。
大致是这样
#include 或者这样
#include 都会提示错误:对具有数组类型的表达式赋值
error: assignment to expression with array type
用strcpy函数
#include 成功:
clc mei wo shuai
数组的简单应用
1到100的和(数组的赋值)
#include 比较5个数的大小(数组的遍历)
#include 数组作为子函数的形式参数以及数组元素个数计算
#include ①数组形参,仅仅传递数组的首地址,代表不了个数(所以个数不必写出)。
②传入数组有两种方式:传入数组首个元素的地址(&) / 数组名
③而用sizeof计算数组大小只能传入数组名
④计算数组个数:数组大小 / 数组中某个元素的大小(sizeof(array)/sizeof(array[0])
二、指针
指针,你说他难吧,其实都是在学校学的时候给劝退了,其实很简单,而且学会了之后老是想用,也很好用,以后看到指针就不会有心理障碍啦。
地址的引入
概念
地址是一个十六进制表示的整数,用来映射一块空间,是系统用来查找数据位置的依据。地址标识了存储单元空间,而字节就是最小的存储单位。
按字节的编址方式:每一个字节都有一个唯一的地址。例如:一个int型的变量是4个字节,就会对应4个地址,我们只需要取到这个变量的首地址就能得到完整的int型数据。
地址长啥样?
用一个例子感受变量存放的地址:
#include 结果:可以发现两者地址相差4个字节,说明int型变量用4个字节的空间存放
a的地址是:0x7ea5d1dc
b的地址是:0x7ea5d1d8
大概可以表示为:

指针变量的引入
什么是指针?从根本上看,指针是一个值为内存地址的变量。
正如char型变量存放字符,int型变量存放整型数一样,指针变量存放的是地址,没有什么难理解的。
给指针赋值就是让其指向一个地址。
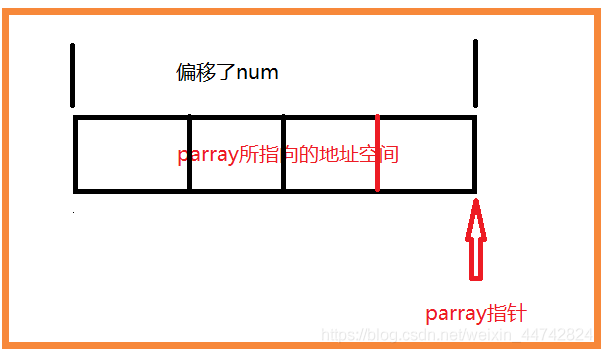
指针分类型与指针偏移量
用sizeof发现linux下所有指针类型的大小均为8字节。
平台:树莓派
整型指针,字符指针
#include 结果:可以看到指针类型不同,其每次偏移的地址量也不同。
pi@raspberrypi:~/Desktop $ ./a.out
int 型指针pa的地址是0x7ead81ec
int 型指针偏移(++pa)后的地址是:0x7ead81f0
char 型指针pb的地址是0x7ead81eb
char 型指针偏移(++pb)后的地址是:0x7ead81ec
不知道你会不会思考,为什么我不使用代码中被注释的两条语句,简短明了,而要使用4条printf。
你尽管试试,打印出来的pa和++pa是一样的,好似是地址没有偏移,这其实关系到了printf的出栈入栈问题,放在六、其他小知识点:printf 里的 a++,++a,真的有鬼!! 中详细展开。
函数指针(重点)
顾名思义,指向函数地址的指针。
无参无返的函数指针
这是函数指针最简单的一种形式
#include 结果:
hello world
hello world
函数指针pprint的地址是0x1046c
函数指针偏移(++pprint)后的地址是:0x1046d
有参有返的函数指针
稍微上升点难度
#include 结果:
total1:11
total2:15
0x10440
0x10441
结构体中的函数指针
比较常见的还是和结构体的结合,这个容易看花眼。
#include 结果:
stu1的名字是华天朱,他的语言综合分数是190
0x10470
0x10471
规律总结
函数指针无非就三步走:
定义
类型 (*指针名)();
void (*pprint)() = NULL;
两个括号很好记
赋值
指针名 = 函数名
pprint = print;
调用
如有参数则调用时传
pprint(); //调用方法1
(*pprint)(); //调用方法2
数组指针(少用)
顾名思义,就是指向数组地址的指针。
目前还没碰到数组指针的使用,涉及即更新
#include 结果:偏移了整个数组的大小12字节
0x7ede61e8
0x7ede61f4
指针数组(少用)
存放一系列指针的数组,本质是数组。
#include 结果:
指针数组的第一个元素是:0x7ed501f4,地址的内容是:1
结构体指针(重点)
定义赋值调用与指针偏移
#include 结果:结构体偏移了4+128个字节
华天朱:100
果粒臣:99
0x7e905170
0x7e9051f4
实际应用例子
用一个结构体指针做一个最简单的学生成绩管理。
#include 结果:
美羊羊:45
废羊羊:100
喜羊羊:60
灰太狼:76
野指针
是什么
野指针指向的地址是随机(又称为:"垃圾"内存)的,无法得知他的地址,操作系统自动对其进行初始化。
野指针是怎样生成的?
(1)创建指针时没有对指针进行初始化
(2)使用free释放指针后没有将其指向NULL
有什么危害
当一个指针成为野指针,指向是随机的,当你使用它时,危害程度也是随机而不可预测的。一般会造成内存泄漏也很容易遭到黑客攻击,只要将病毒程序放入这块内存中,当使用到这个指针时就开始执行。
如何避免
- 定义指针时进行初始化
如果没有确定指向,就让它指向NULL
NULL在宏定义中是
#define NULL (void **) 0,代表的是零地址,零地址不能进行任何读写操作
- 要给指针指向的空间赋值时,先给指针分配空间,并且初始化空间
简单示例:
//char型指针
char *p = (char *)malloc(sizeof(char));
memset(p,0,sizeof(char));
//int型指针
int *p = (int *)malloc(sizeof(int));
memset(p,0,sizeof(int));
//结构体指针
struct stu *p = (struct stu *)malloc(sizeof(struct stu));
memset(p,0,sizeof(struct stu));
malloc动态内存分配,用于申请一块连续的指定大小的内存块区域以void*类型返回分配的内存区域地址。
void *malloc(unsigned int size),因为返回值时void*,所以要进行强制转换。
memset将某一块内存中的内容全部设置为指定的值, 这个函数通常为新申请的内存做初始化工作,是对较大的结构体或数组进行清零操作的一种最快方法。
void *memset(void *s, int ch, size_t n);
- 释放指针同时记得指向NULL
free(p);
p = NULL;
malloc与内存泄漏
情景:
程序刚跑起来的时候没问题,时间久了程序崩溃,大多为内存泄漏。
最常见的情况是在无限的循环中一直申请空间。用malloc申请的空间,程序不会主动释放,只有当程序结束后,系统才回收空间。
避免在循环中一直申请空间,即使合理释放(free,指向NULL)
指针类型小测试
搞几个容易混淆的
int *p[4];
int (*p)[4];
int *p();
int(*p)();
指针数组,数组中存放的是一系列的地址
数组指针,指向一个数组
只是一个普通的函数,其返回值是int* 的指针
函数指针,指向一个函数
指针也可以作为数组传入的形式参数
在数组作为子函数的形式参数小节中,子函数的形式参数我们用 int array[ ]来定义。
学了指针之后,我们也可以用 int *array来定义.这是因为前者的本质上传入的是数组的首地址,而指针也一样,需要传入数组的首地址。
如下:
#include 为什么要使用指针?
(1)节省内存
指针的使用使得不同区域的代码可以轻易的共享内存数据,当然也可以通过数据的复制达到相同的效果,但是这样往往效率不太好。
指针节省内存主要体现在参数传递上,比如传递一个结构体指针变量和传递一个结构体变量,结构体占用内存越大,传递指针变量越节省内存,也就是可以减少不必要的数据复制。
(2)在子函数中修改被传递过来的对象
C语言中的 一切函数调用中,值传递都是“按值传递” 的。如果要在函数中修改被传递过来的对象,就必须通过这个对象的指针来完成。
太抽象了不懂?举个栗子:
#include 结果:可以发现main函数中a的值并没有真正发生改变。
add:a的值为11
main:a的值为10
为什么没有改变呢?
函数add调用时,才申请了一个内存空间,才有了这个变量a,同时把实际参数(main中的a)的值拷贝一份给形式参数(add中的a),函数执行结束后释放空间,这个子函数中的变量自然也被释放了。
其中这个a就是传递入子函数add的对象,如果想要在这个子函数中修改a的值,就要使用指针
#include 结果:
add:a的值为11
main:a的值为11
传入了main中a的地址,再在子函数中修改这个地址中的内容,当然能够修改成功。
(3)动态分配内存
常常可以看到,程序使用的内存在一开始就进行分配(静态内存分配)。这对于节省计算机内存是有帮助的,因为计算机可以提前为需要的变量分配内存。
但是大多应用场合中,可能一开始程序运行时不清楚到底需要多少内存,这时候可以使用指针,让程序在运行时获得新的内存空间(动态内存分配),并让指针指向这一内存更为方便。
在结构体指针实际应用举例中有涉及:
int num;
printf("需要录入几个学生的成绩?\n");
scanf("%d",&num);
//这里开辟了num个结构体所需要的空间,动态分配内存
struct stud *pstu = (struct stud *)malloc(sizeof(struct stud)*num);
(4)在指定地址写入数据(目前少用)
了解就行
#include 结果:
在地址0x7ead81eb中存放的数据是10
注意哈,这个操作运行很有可能
Segmentation fault
这也正常,毕竟可能这地址放有东西或者不允许这样操作。
(5)函数多个返回值
有时候我们总是希望一个功能子函数的返回值可以有很多个,但奈何用return只能返回一个。
碰到实际用上的例子再补充,不硬找例子。
三、结构体
结构体的三种定义赋值方法
#include 运行结果:
stu1的名字是:周星星,分数:100
stu2的名字是:张大大,分数:90
stu3的名字是:华天朱,分数:90
为什么使用
strcpy?
如果不在结构体变量初始化的时候就对具有数组类型的表达式赋值,则要使用strcpy,即不能直接赋值。
结构体数组
做个简单应用就好:输入4个学生的名字成绩,找出最高分。
#include 结果:
请输入第1个学生的名字
喜羊羊
请输入他的成绩
90
请输入第2个学生的名字
懒羊羊
请输入他的成绩
60
请输入第3个学生的名字
美羊羊
请输入他的成绩
80
请输入第4个学生的名字
废羊羊
请输入他的成绩
30
最高分是喜羊羊:90
跟结构体指针真的好像。
结构体指针(在指针中已有介绍)
结构体的综合运用学生成绩处理
因为呢结构体比较重要,搞个稍微复杂一点的练练手。
主要运用结构体指针,输入学生的学号,语文数学英语成绩。
要求封装功能函数(初始化学生成绩,找到分数最高的学生,算出班级平均分)。
#include 结果:
18001>>>>语文:90,数学:80,英语:70
18002>>>>语文:98,数学:9,英语:76
18003>>>>语文:54,数学:89,英语:90
总分最高分是18001:240
班级平均分是:218
小问题:不会释放指针,或者需不需要释放?
free(p);
p = NULL;
报错:释放了一个自由的地址?释放错了?
double free or corruption (!prev): 0x0017d848 ***
可能是因为p++的影响,释放错了地址,于是
free(p-num);
p = NULL;
嘿嘿,还是不行,懂了再回来更新。我还是先注释掉吧。
结构体大小计算方法
四、链表
对比链表与数组
同样是存放一串数据,链表与数组的区别在哪里?
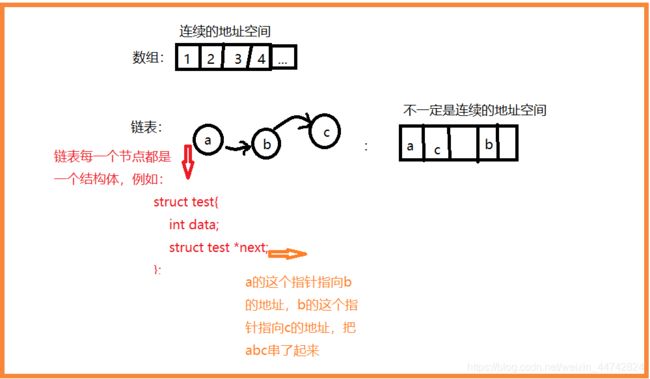
数组是申请连续的地址存放数据,在增加或删除某一元素不方便。
而链表可以很好地解决这个问题。
链表方便增删
大致思路:
- 增加节点
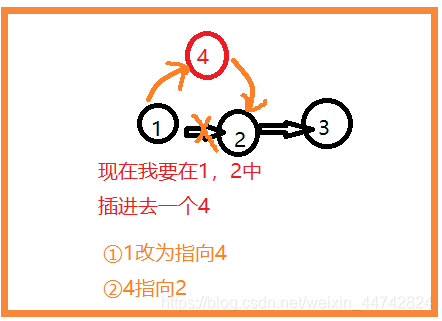
- 删除节点

链表的创建之静态创建:最简单的创建
#include 链表的动态遍历:统计节点个数与查找节点
#include 结果:
1 2 3 链表节点的个数是:3
找到了
要重点理解的是:
p = p->next
指针p指向了下一个结构体的地址,p->next中存放的正是下一个链表节点的地址。
p本身是一个结构体指针,所以用->访问成员next.
插入节点与删除节点
从指定节点的后方插入新节点
思路:
(1)找到指定节点
(2)把指定节点的的next指向new节点的地址
(3)new节点的next指向下一个节点
靠,真拗口,看图!
举例:要从链表1 2 3 4 中,在 2 后插入 5 。
#include 结果:
1 2 5 3 4
思考一下,为什么上面要传入结构体new的地址?
像下图一样修改,传入的是结构体变量new,然后p->next再指向new的地址不就行啦?还不是一样把地址串了起来。
void addBehind(struct Test *head,int data,struct Test new)
{
struct Test *p = head;
while(p != NULL){
if(data == p->data){
new.next = p->next;
p->next = &new;
return;
}
p = p->next;
}
}
addBehind(&t1,2,new);
结果是:段错误
Segmentation fault
为啥?
因为上述中new只是子函数的一个形式参数罢了,地址空间是临时分配,当函数调用结束空间回收,你让一个指针p->next指向这里,必然导致段错误!
在指定节点前方插入新节点
第一种情况:不是1之前插入,链表头未发生改变
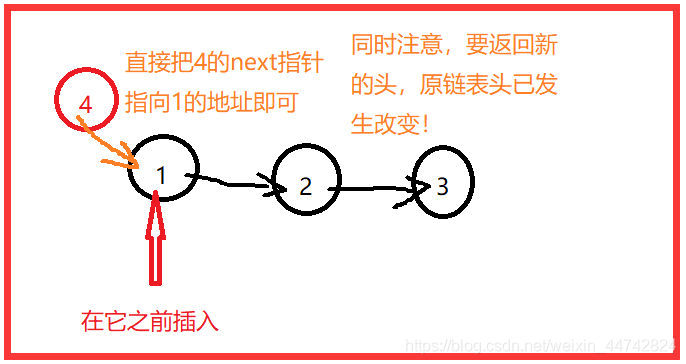
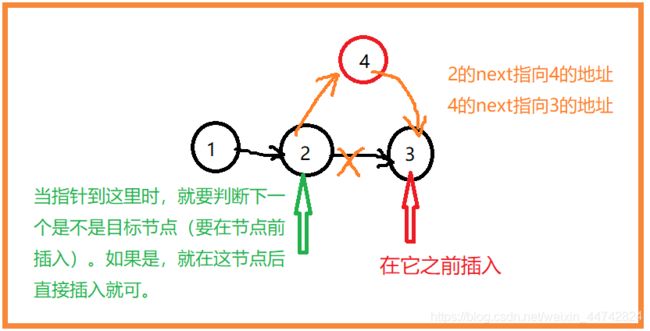 第二种情况:是在1之前插入,链表头发生改变
第二种情况:是在1之前插入,链表头发生改变
举个栗子:(1)要从链表1 2 3 4 中,在 3 前插入 5 。
#include 结果:
1 2 5 3 4
(2)更改程序,在1之前插入5,结果:
5 1 2 3 4
删除指定节点

当删除的是头节点时,还要注意新头的替换!
举例:删除 1 2 3 4中的 1
#include 结果:
2 3 4
删除 1 2 3 4中的4,结果:
1 2 3
链表的创建之动态创建
头插法创建链表
头一直是在变化的
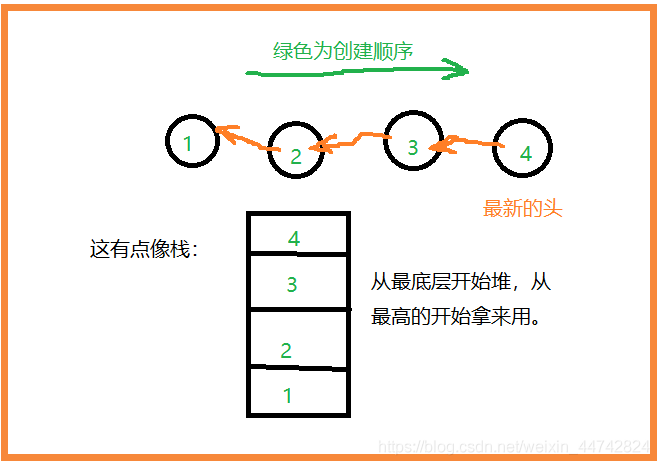 关键步骤:
关键步骤:
new->next = head;//new直接指向原来的链表头
head = new;//赋予新的链表头
实际例子:
运用头插法创建链表,直接输入数据自动串成链表,想要结束时,输入数据999.
#include 结果:
请输入新的节点,输入999结束输入
3
请输入新的节点,输入999结束输入
4
请输入新的节点,输入999结束输入
5
请输入新的节点,输入999结束输入
6
请输入新的节点,输入999结束输入
999
6 5 4 3
尾插法创建链表
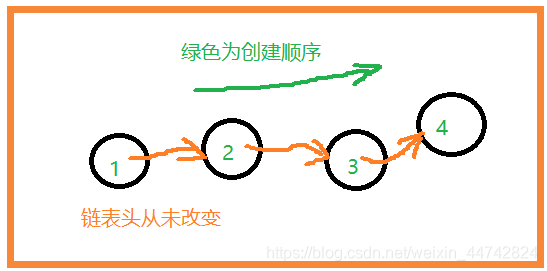 关键步骤:
关键步骤:
(1)去到链表的尾部
while(p->next != NULL){
p = p->next;
}
(2)在尾部添加new
p->next = new;
实际例子:
运用尾插法创建链表,直接输入数据自动串成链表,想要结束时,输入数据999.
#include 结果:
请输入新的节点,输入999结束输入
3
请输入新的节点,输入999结束输入
4
请输入新的节点,输入999结束输入
5
请输入新的节点,输入999结束输入
999
3 4 5
思考:当上面的inserTail函数更改为如下,会发生什么?
ptest insertTail(ptest head,ptest new)
{
ptest p = head;
if(head == NULL){
head = new;
}else{
p->next = new;
}
return head;
}
结果:可以发现无论怎样输入链表都只有第一个和最后一个数据
请输入新的节点,输入999结束输入
1
请输入新的节点,输入999结束输入
3
请输入新的节点,输入999结束输入
5
请输入新的节点,输入999结束输入
6
请输入新的节点,输入999结束输入
8
请输入新的节点,输入999结束输入
999
1 8
那是因为:使用尾插法,链表头一直未改变。然而在每一次的循环中,p->next都指向new,即为每次头都指向new。到最后链表中自然只有头和最新的new啦。
五、字符串
字符串的定义方式与输出
#include 结果:
chen li chen mei wo shuaichen li chen mei wo shuai
chen li chen mei wo shuai
其中第三种定义方式 char str3[] = "str"; 不指明数组的大小,只给出了数组名,而数组名的值是个指针常量,也就是数组第一个元素的地址。
是不是可以猜想,首地址就是字符串的关键呢?
而指针也指明了地址,故可以用指针的方式定义字符串,即字符串指针。也是定义字符串的常用方式。
char* name = "huatianzhu";
注意: 这里说的定义是同时赋值,而不是等待赋值。之所以不需要给指针name分配空间,是因为进行了初始化,编译的时候系统就知道需要分配多大的空间,否则要开辟空间。(后文中也有涉及)。
字符串的结尾是 ’ \0 ’
字符串都是以类似于下面的方式输出:遇到 ‘\0’
#include 用strlen计算有效字符的长度
在很多场景,我们都需要在程序的执行过程中录入字符串,如下:
#include 运行结果:
请输入名字
huatianzhu
sizeof计算:128
strlen计算:10
实际上huatianzhu长这样:
huatianzhu\0\0\0\0.....
strlen当遇到\0时便停止计算,是专门用来计算字符串的长度。
这时候你好奇了,输入中文字符,用strlen计算是多少?
输入:
华天朱
可以发现结果是 9.这与linux系统采用utf-8的编码方式相关,一个汉字占用3个字节。
strlen使用注意
字符数组
字符串操作常用API
puts、gets —— 输入与输出
strcpy、strncpy —— 拷贝
strcmp —— 比较
strchr、strstr —— 检索
strlwr、strupr —— 大小写转换
strcat —— 拼接
strtok —— 分割
strtok容易出错的秘密
自己实现这些API
六、其他小知识点
因为CSDN有篇幅长度限制,这个板块内容只能分开文章记录了。
c语言基础回顾(2)—— 零碎的知识点