23神经网络 :唐宇迪《python数据分析与机器学习实战》学习笔记
唐宇迪《python数据分析与机器学习实战》学习笔记
23神经网络
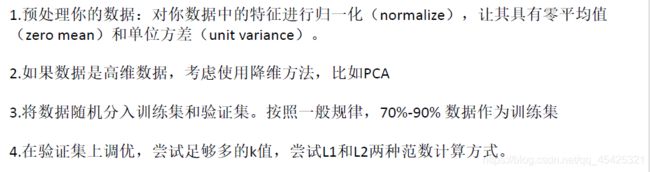
1.初识神经网络
百度深度学习研究院的图,当数据规模较小时差异较小,但当数据规模较大时深度学习算法的效率明显增加,目前大数据时代利用深度学习明显效果更好。

一些举例:用深度学习可以进行图片描述

用深度学习进行图片风格融合,从左到右:1为内容、2为风格、3为1的内容进行2的风格转换。

计算机中图像表示为三维数组,例如3001003,300*100像素长宽,3表达颜色通道,一个彩色图有3种类颜色通道:R【红色】、G【绿色】、B【蓝色】。图像由很多像素点拼接成,像素点的取值范围0~255,值越大亮度越高。

改变某些因素后计算机识别变得具有挑战性:例如照射角度、光照强度、形状改变、部分遮蔽、背景混入。其中部分遮蔽是需要重点克服的。

接下来看一些深度学习的常规套路(流程跟机器学习类似):这里的分类器转换为神经网络了

二、K近邻
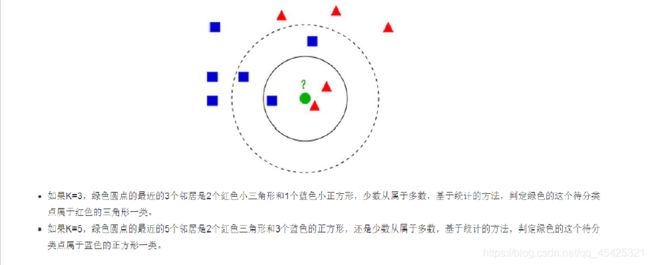
K近邻算法:附近K个值中谁占比大就分类为谁。
假设现在进来一个绿点,分类未知就看一下周围离谁近,当K=3时看附近3个点,其中2个三角一个方形,所以就将绿色分类为三角。 K=5时相同逻辑…
K近邻算法流程:

优点:不需要进行训练 。缺点:需要挨个计算距离,当你的文档总数很大时效率低。


练手数据集介绍:

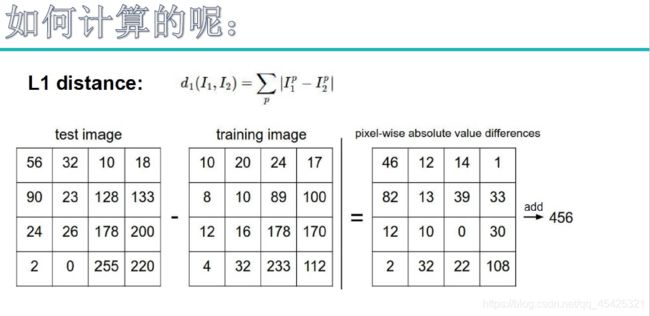
图像数据(矩阵数据)如何算距离? 用对应像素点相减求差异值再将其累加求和。
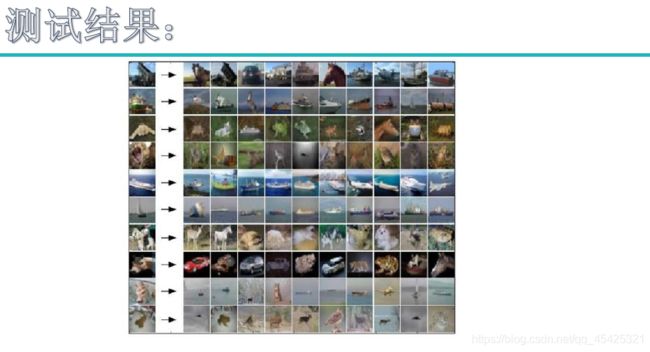
依据上面做法后得到的结果,发现并不好。

刚才提到距离,这里叫超参数:L1麦哈顿距离,L2欧式距离,实际中用L2比较多



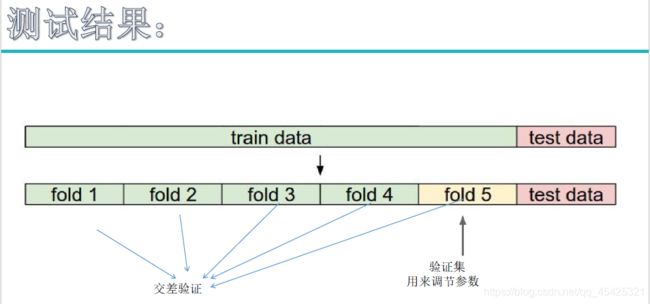
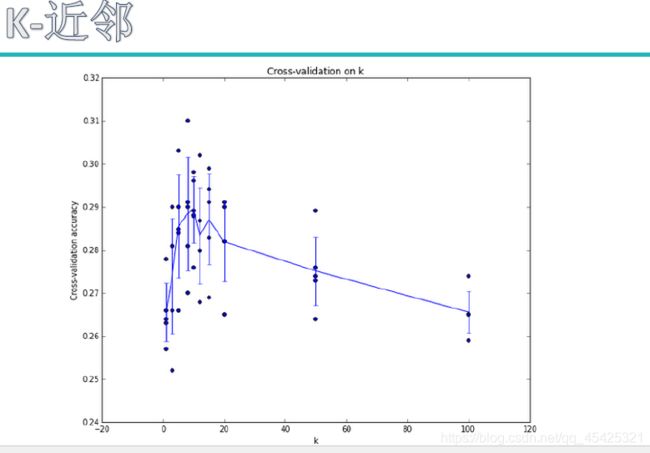
测试集太宝贵,用其调参数太奢侈。因此这里把引入交叉验证,就是把训练集再切分,例如下面切分为5份,4份用来训练,1份用来作为验证集调节参数。为避免数据不纯的影响,这5份轮流来当验证集,迭代5次求平均。
参数值对结果影响较大例如下图:K值对结果的影响,交叉验证可有效降低这部分影响 。
K近邻结果不准的原因,有些距离不太靠谱。例如刚才的小猫,整个图片背景占比较大,然而我们计算了每个像素点,背景无用却因此对结果的影响很大。



综合来说K近邻算法不可取,所以这里借此过渡到神经网络。
三、神经网络
3.1线性分类原理
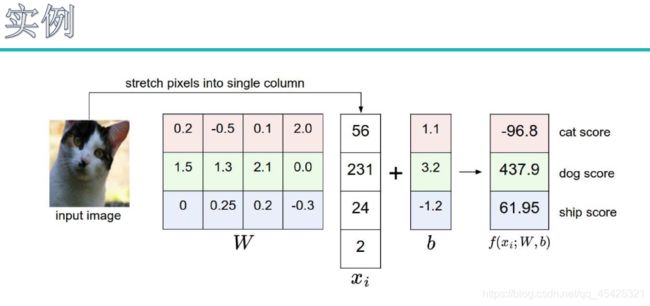
来了一个输入数据这里想要找到一些权重参数W将其分类。(彩色图颜色通道为3,灰度图为1)
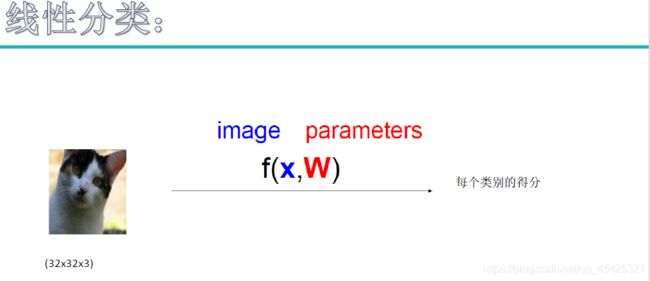
用矩阵去线性分类:
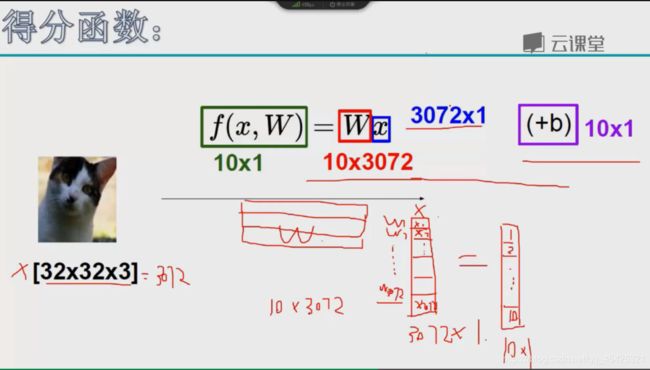
这里将像素点(32x32x3=3072)进行拉伸转换为列向量(3072x1的矩阵),最终分类为1~10(结果为10x1的矩阵,每个类别的得分值或概率值),所以我们的W是一个10x3072的矩阵。
这里右边加上的b是一个10x1的矩阵,因为想得到10个类别。
下面实例中:W为4x3的矩阵,分为3类,照片有4个像素点。每一个权重参数都会与对应的输入相乘,再加上对应的b就收获了每类得分值。哪个类别的得分值比其他大就分类为哪个。
(这里dog得分最高,所以显然分类错了哈哈哈,权当举例了)
损失函数
上面相当于完成了线性分类操作,找决策边界—通过w找斜率—通过b找到交点值

刚才的预测有问题,所以要改正过来。
损失函数如下图,这里假设有3个输入,得到输出。我们看一下正确预测同其他错误预测的差异,猫的正确为3.2、最大错误为5.1,计算损失值(5.1-3.2),再,加一个容忍程度1,接下来计算其他损失值,得到的损失值分别与0比较取较大的相加。

在红色区间上代表预测结果还行,score值越高离错误分类越远损失值越小

最终的损失函数需要算一个模型的效果,需要进行大量的测试,先把总体的损失函数值求出来。
假设这里有x数据得到w1和w2,发现结果都为1。但是实际两个w差异较大:w1只关注x1而其他为多少不关注,容易过拟合下一个数据传入x1变化一大效果就不好了。而w2分布均匀综合考虑了每个像素点这个是我们实际操作中需要的。

那么如何得到2号这类模型,引入正则化惩罚项。例如L2惩罚项,求w²,w1的惩罚值:1,w2惩罚值:¼,这样就会选择惩罚值低的。


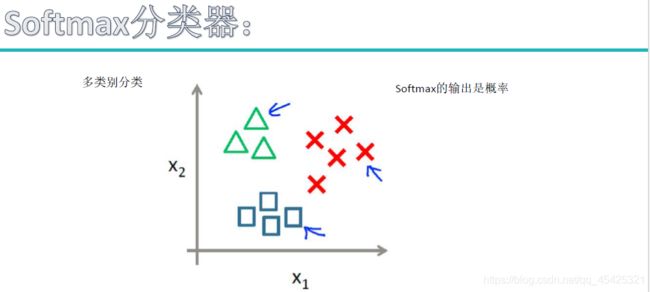
3.2softmax分类器
上面线性分类最终得到的都是得分值,然而分类显然更喜欢概率值。
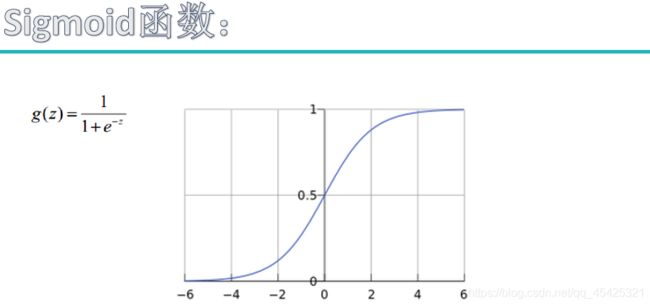
用sigmoid函数可以将负无穷到正无穷的所有值映射为[0,1]上的概率值,这样我们就可以选择一个阀值概率就行分类,例如>0.8就分为一类,≤0.8又是一类。

例如猫的各类得分值如下,先算e的x次幂映射为正值大小,再归一化操作,再计算损失值。

下面是两种损失计算方式的直观对比,当然也有可能遇到max(0,9-10+1)+max(0,9-10+1)=0这种情况得到的损失值为0意味着分类效果很好了(实际正确与错误差别这么小分类效果并不好),如果使用softmax则无论什么情况都可以得到一个损失值,区分得更精细。

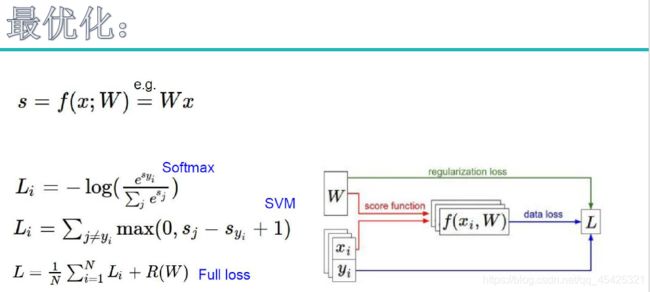
3.3最优化(梯度下降、学习率)
θ比喻为人,曲线为山,人如何下山到达最佳的J(θ),人的前进方向(θ1、θ2…)如何选择,如何更快的下山,沿着坡度走的速度显然最快,即用梯度下降的思维求J(θ)。梯度通过求导所得,一般为反方向,所以加个符号就成了梯度下降的问题。

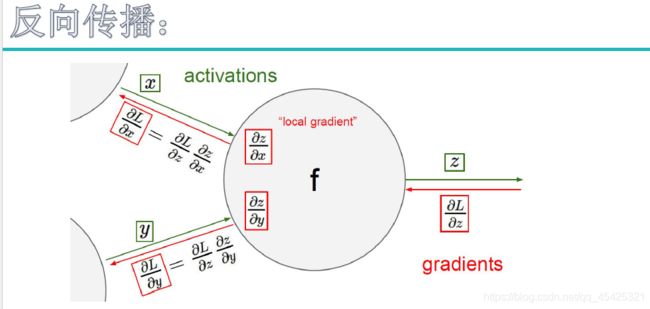
之前从x开始经过W后得到得分值F(X),经e的x幂再做归一化,得到一个属于类别的概率值,得到一个log值加负号得到Li,以上步骤称为:前向传播。w好不好通过Li已经知晓,但是能不能使w改变使的Li更小呢?借下来用反向传播来得到最优解。
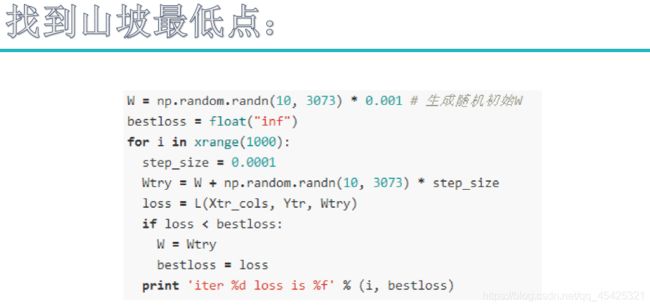
每次沿着坡走即跟随梯度


一次通常迭代多张图片,看计算机负载量,一般是2的倍数,64和128较多。
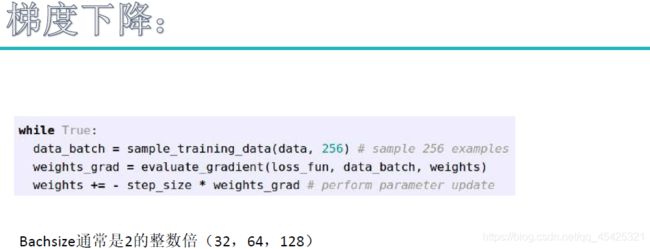
loss损失值,epoch代表跑了几遍,假如全部4000张图片跑一次就是epoch=1

算完梯度后不一次更新那么多,加个学习率不更新那么大,一次少走些多走几次,不然有可能一次越过最低谷跑到对面山坡的一个水坑底了。比如取学习率0.001或0.0001
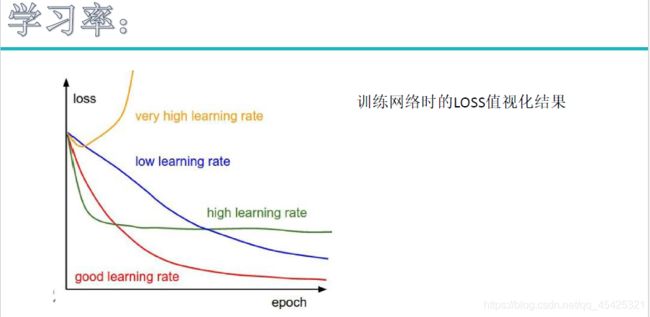
体现在代码中学习率就是stepsize * 梯度 weight_grad ,最后再更新就完成了一次反向传播。

最优化就是在神经网络反向传播去更新权重参数w中体现出来的
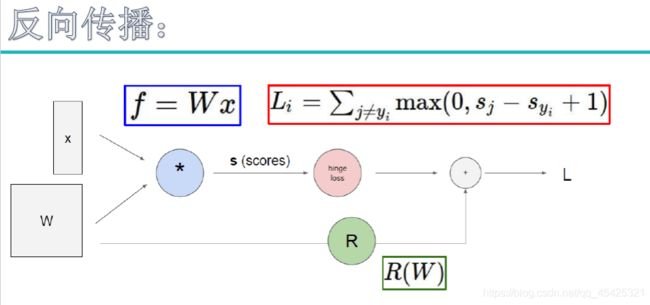
下图计算出的-12假设其就是损失值,那么现在就要看xyz对其的贡献程度。指定额外元素q,想看z对f的贡献就求其偏导得出q(3),z增大1倍则f增大3倍所以我们要降低z。想看x对f的贡献就找q对f 的贡献,求偏导得z(-4),即q上一倍则f上升-4倍所以q值尽量整大。再看x对q的贡献,求导为1。最终为1*-4,(链式法则:多步操作叠乘)
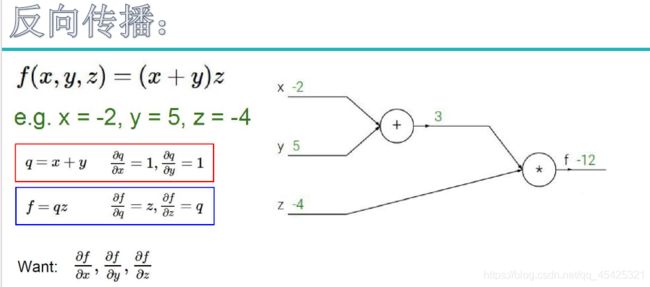
反向传播必须先从L传到z再传到x或y,不能越过。
比如下面的sigmod函数,从后面一步一步往前传,

简化:逐步计算太麻烦了这里简化整体简化。

加法门单元:例如x+y=q这时无论对x还是y求导都是1,均等分配了。MAX门单元:下面操作max时传回来直接给z,与w就无关了。

3.4神经网络
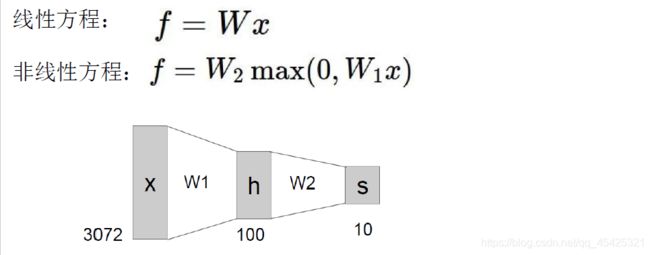
层次结构:输入层、隐层1、隐层2、输出层。需要指定的参数如:w1、w2、w3的形状大小。

为什么Wx就可以表示了却要这么麻烦?因为神经网络本来是很任意的,用线性表示就相当一刀刀切添加了局限性。神经网络为一个非线性结构中间加上了max(无论加啥都称为激活函数)。
有些数据线性一刀分不开,用分线性表达可以切分,想要非线性就加激活函数。而神经网络那么多层其实就是方便加更多的激活函数,比如隐层1加一个,隐层2在加一个,所以效果才那么好。
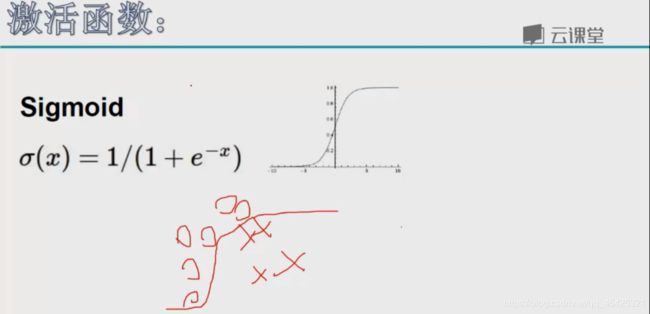
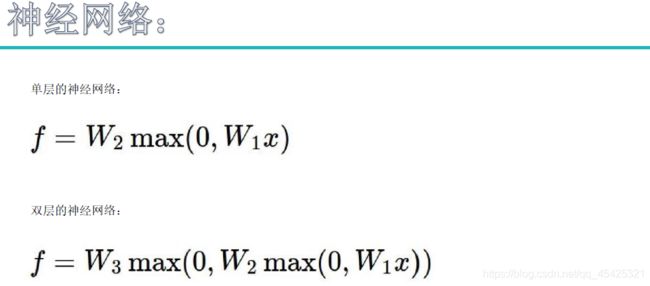
一个神经网络往往不止2个隐层,深度残差甚至达到了152层。用sigmoid函数激活时可能导致梯度消失,且深度越深这种情况越严重。看w1、w2等对loss的贡献时需要反向逐步求导,梯度累乘,当>5时斜率逐步近似0,链式法则累乘就≈0了,梯度无法更新了因此Sigmoid被淘汰。

因此引入ReLU激活函数 max(0,x)

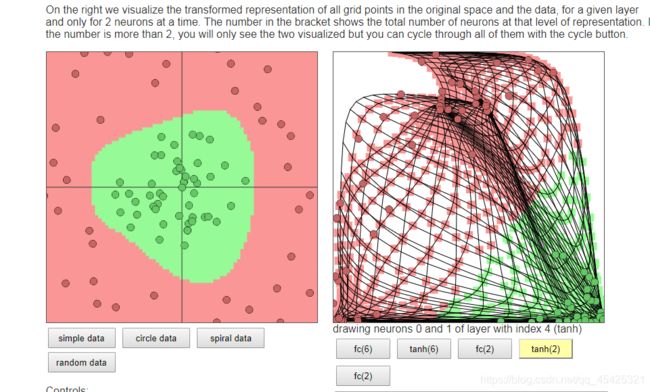
接下来到网站看一下:https://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html
现在有两类点将其分开,通过调节网页上方代码的参数num_neurons神经元个数来看一下分类变化,神经元个数越多往往分类效果比较好。

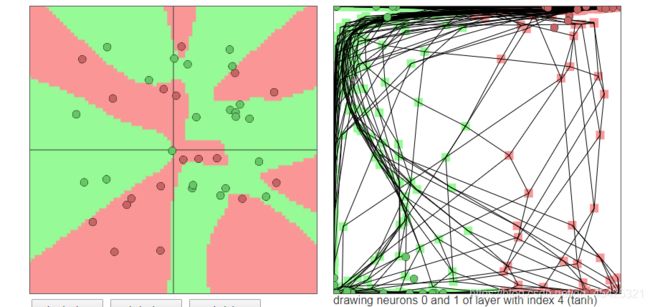
当然神经元数量太多会分得特别碎,例如下面的随机数据我设置了20个神经元都能分类到这个程度,存在过拟合,模型就废了。
神经网络表达效果很好,但是存在黑箱效应,即内部基本无法解释,你根本无法解释为什么w这么设置各个w之间的关系为何,想表达出什么。
下面来看一下正则化项对结果的影响。太小就过拟合,稍微调大明显更平稳了泛化能力更强了。

不同个数神经元的变现就如下图了

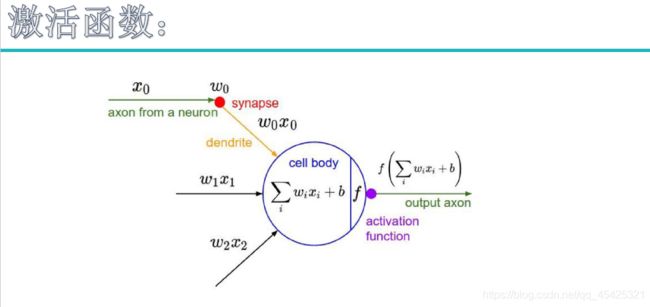
下面来看一下完整的层,输入x0、x1、x2三个像素点分别乘权重参数再+b,经过激活函数后产生非线性。
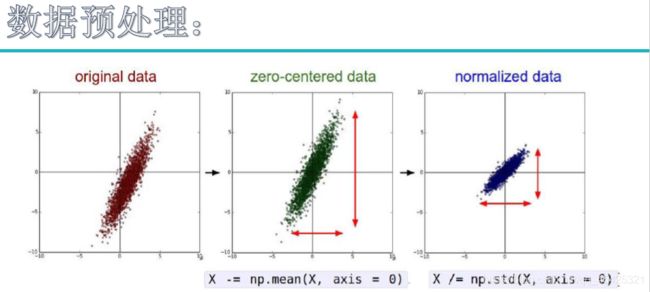
数据预处理
数据来后以0为中心化,即每个样本都减去均值。但是发现y轴的浮动比较大,所以标准化处理,其实就是把xy都映射到[0,1]上。
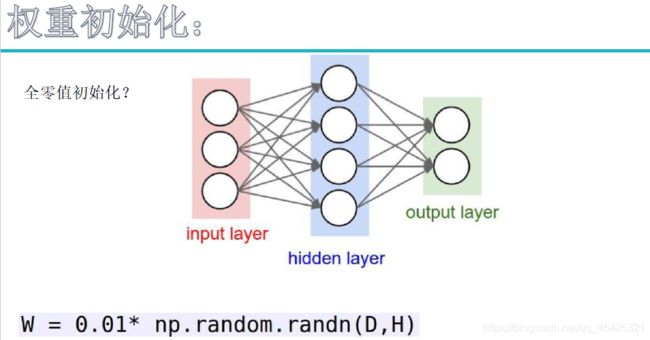
权重初始化 指定矩阵形状随机初始化,b的值就0初始化行了
第一个为全连接操作,神经元太多时连接太多了过拟合风险太大,所以提出DROP-OUT
随机带你玩,例如:这次迭代带这60%,下次迭代带另外60%。

3.5感受神经网络的强大
3.5.1数据构造
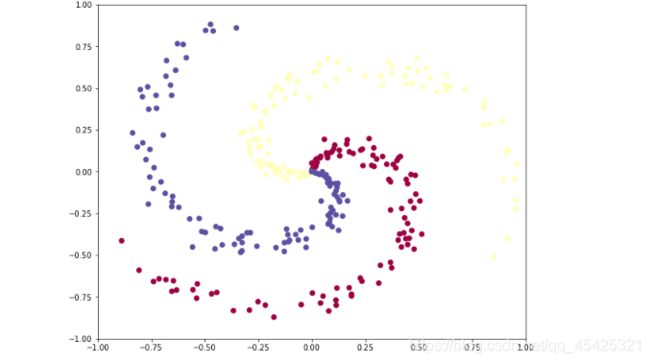
首先是构造数据,3类每类包含100个点
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10.0, 8.0) # 绘图的一些基本设置
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
np.random.seed(0)
N = 100 # 每个类别包含的点个数
D = 2 # 维度
K = 3 # 共3类
X = np.zeros((N*K,D))
y = np.zeros(N*K, dtype='uint8')
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # 半径
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
fig = plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim([-1,1])
plt.ylim([-1,1])
plt.show()
3.5.2线性分类器
看一下线性分类器,下面这个跟神经网络差不多,只不过现在的模型wx+b再做个归一化操作就完事了,不像神经网络那样的有层次结构跟激活函数等,只是通过一个简单的结构去分类。
#训练一个线性分类器
#首先初始化W和b
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))
# 一些超参数
step_size = 1e-0
reg = 1e-3 # 正则化强度
# 梯度下降循环
num_examples = X.shape[0]
for i in range(1000):
# 评估各类得分, [N x K]
scores = np.dot(X, W) + b #x:300*2 scores:300*3
# 把得分值转换为概率值
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K] probs:300*3
# 计算损失:平均交叉熵损失和正则化
corect_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss
if i % 100 == 0: #每100次迭代打印一下损失值
print(i, loss)
# 计算分数的梯度
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# 将梯度反推到参数(W,b)
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W #正则化梯度
#执行参数更新
W += -step_size * dW
b += -step_size * db
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print( np.mean(predicted_class == y))
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b
Z = np.argmax(Z, axis=1)
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()

发现迭代100次往后损失值不变了基本趋于饱和状态,准确率也就0.49,。如图线性操作永远无法把这个环状数据切割好,100次后无论怎么摆弄线都没法让损失值变小了。
3.5.2神经网络
神经网络相比于线性模型,其具有层次结构通过多组权重参数(w1w2…)来控制模型,数据来后先经过全连接操作再经激活操作。下面看一下 简单的2层神经网络+1个激活函数的效果。
h = 100 # 隐层大小(神经元个数)
W = 0.01 * np.random.randn(D,h) # x:300*2 2*100
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))
# 超参数设置
step_size = 1e-0
reg = 1e-3 # regularization strength
# 梯度下降循环
num_examples = X.shape[0]
for i in range(2000):
# 得分值, [N x K]
hidden_layer = np.maximum(0, np.dot(X, W) + b) # ReLU激活隐藏层:300*100
scores = np.dot(hidden_layer, W2) + b2 #得分:300*3
#概率
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# 损失计算
corect_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2)
loss = data_loss + reg_loss
if i % 100 == 0:
print (i, loss)
# 计算分数梯度
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# 将梯度反推到参数上
# 首先支持参数 W2和b2
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)
#下一个支持到隐藏层
dhidden = np.dot(dscores, W2.T)
#支持ReLU非线性
dhidden[hidden_layer <= 0] = 0
# 最后到W, b
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
#添加正则化梯度贡献
dW2 += reg * W2
dW += reg * W
#执行参数更新
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2
hidden_layer = np.maximum(0, np.dot(X, W) + b)
scores = np.dot(hidden_layer, W2) + b2
predicted_class = np.argmax(scores, axis=1)
print (np.mean(predicted_class == y))
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = np.dot(np.maximum(0, np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b), W2) + b2
Z = np.argmax(Z, axis=1)
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()


结果显示随着迭代次数增加损失值越来越小,准确率也变成了0.97,如图分类效果很好。
但是神经网络也有些问题,例如下面多了个奇怪的圈,神经网路花费了很大的代价去拟合这个点,而这个点可能是数据不纯导致的,现在这样过拟合在测试数据集上表现会很差。
