mysql 数据相加_数据分析--Part 1: Python基础

笔记内容来源:拉勾教育数据分析实战训练营
终于开始python阶段了,python的老师三丰老师真的对小白超友好,讲解思路非常清晰。因为我之前也看过一些别的老师讲python,但总会听得云里雾里,这次很庆幸可以遇到一位好老师。
我会陆续总结分享一些对小白超友好的笔记,本篇是part1,python的基础部分,后面还会持续更新的~~~~~~~
说明:理论部分是提炼的老师所讲,加上我自己看书添加的一些解释,代码部分有些会融合老师和我自己练习的写法,一起分享给大家
再啰嗦两句,关于拉勾教育数据分析实战训练营:
目前为止已经学习了近4个月的课程,已经学完Excel、数据分析思维、MySQL、Tableau、quickBI、神策、hive、统计学,每一阶段每一模块的知识都是在线自主学习,完成作业后解锁新课程,直播课会根据全体学员进度,收集疑问然后进行在线直播内容回顾和答疑以及作业讲解。每位讲师都很优秀,都有自己的授课特色所在,内容都是很干货的录好的内容,有些内容导师还会重新录制,不断迭代让学员达到更好的学习体验。作业批改、答疑导师西蒙(我接触最多的,经常麻烦他帮我解决问题)和班主任团子比较nice,认真负责,他们分别负责技术答疑和服务类的问题,平时有问题可以在微信群里问,可以单独聊也可以群里问,他们全天非工作日也会答疑。
在这里真心推荐下拉勾教育数据分析实战训练营:
1、课程体系最全面:课程内容有分析方法论、分析方法、Excel、Mysql、Tableau、Quick BI、神策平台、Hive、统计学、Python、挖掘算法、Spss等,是目前我看到的最全面的。
2、课程体系把握行业人才需求痛点:拉勾主营业务是招聘,最明白企业的人才需求,基于此设计的课程体系是比较贴近实际需求的。通过5个月10个阶段,从现状统计到预测分析、从业务数据到编程工具处理复杂业务逻辑数据,实现用数据驱动业务辅助决策,提升公司业绩。
3、课程学习模式灵活:大部分授课采用录播方式,学习完成后还有直播答疑。比直播打卡更容易安排自己的时间。
4、课程学习过程和结果有保障:学习成果作业检测+实时答疑+班主任督导,每个阶段每个模块的知识学完的作业可以锻炼实操。
5、项目实战内容丰富:也是我最看好的一点,涵盖了在线教育、电商等多个领域项目实战。
6、就业辅导+优秀内推:拉勾平台是互联网行业招聘大本营,这是天然优势。
~~~~~~~~~~~~~~~~~以下是笔记~~~~~~~~~~~~~~~~
第一模块:python基础
一、 python基础认知
1 基础认知
数据分析领域的两大编程语言Python和R语言
越来越多的Python分析工具库,从数据采集、清洗、处理、分析、报表、数据挖掘、机器学习,Python都提供了成熟的解决方案,一些常用库,比如像数据分析三剑客(Numpy/Pandas/Matpolib)等等,已经成为各大互联网企业的数据分析师们日常必备工具。
PyCharm是一种Python IDE(Integrated Development Environment ),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。
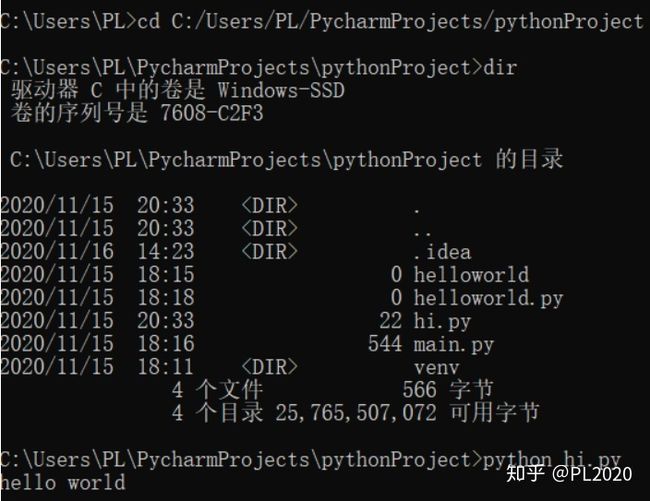
2 命令提示符操作
1、搜索栏输入cmd,回车进入命令提示符
2、输入Python回车进入交互环境
3、退出exit()
4、pycham编辑源代码保存为hello.py,cd切换到源代码所在目录
5、执行命令Python hello.py
其他操作:
1、换行:shift+enter
2、显示文件目录:dir
二、python核心语法
1 变量

2 数据类型
数据类型
- 数值,包括整数和浮点数
- 字符串
- 布尔值True或False
- 空值None
2.1 数值
Python中数值有两种类型,整形(int)和浮点型(float),通俗一点的讲,一个是不带小数点的,一个带小数点的。
- 整形和浮点形数值可以相互运算
- 只要有浮点数参与的运算,它的结果肯定也是浮点数
>>>a = 1
>>>b = 3.0
>>>a + b
4.02.2 字符串
- 字符串可以用“ ”或' '
a = "Hello"
b = 'world'
print(a, b)
# 输出的结果是:Hello world- 反斜杠:转义或连接多行
当如果字符串含有特殊字符,比如双引号,我们可以加一个来进行转义
print("Buddha: "What we think, we become."")
# 输出的结果是:Buddha: "What we think, we become."或单双引号混用
print('Buddha: "What we think, we become."')
# 输出的结果是:Buddha: "What we think, we become."反斜杠来连接多行,但在在输出的时候还是会显示为一整行
sentence = "This's a very long long long
long long sentence............"
print(sentence)- 三引号之间放入任意多行文字
'''123'''
# 输出的结果是:'123'
print("""You can do it.
Come on.
""")
# 输出的结果是:
You can do it.
Come on. 2.3 空值 None
空值None是Python中的一个特殊值,它代表空值,表示“什么都没有”,None同时也是关键字。None的用处有很多,比如说你想定义一个变量,但一时还没想好给它赋什么值,甚至连它用什么类型也没决定好,这时可以先用None
None被输出的时候显示为一个字符串"None"
temp = None
print(temp)2.4 数据类型转换
2.4.1 布尔值转换
把其他值转换为布尔值,需要使用一个内置函数bool()
# 以下值都为True
bool(1)
bool(-1)
bool(255)
bool(0.0000001)
bool(-99.99)
bool('hu')
bool('0')
这是一个只包含一个空格的字符串,转换结果为为True
bool(" ")
# 下面的值为False
bool(0)
bool(0.0)
bool('')
bool(None)- 对于数值类型,所有的非零值转换为True, 只有零值才转换为False
- 字符串也可以转换为布尔值
- 对于任何非空的字符串,转换为布尔值都是True
- 空值转换为布尔值永远都是False
2.4.2 字符串转换
使用str() 将其他类型转换为字符串
True, False, None 这三个值转换为字符串就是它们的单词本身
str(True) # 结果是'True'
str(False) # 结果是'False'
str(None) # 结果是'None'对于数值类型,我们也可以用str()将它们转换为字符串,如果不进行强制转换的话,也不会出错,那是因为,print函数会自动将数值先转换成字符串再输出
print("My age is", str(18))2.4.3 数值转换
要把一个整数字符串转换为int类型,使用int()
num = "1"
int(num) + 1
# 结果是2如果将int()去掉,这段代码则会报错,因为num是个字符串,不能将字符串和数值进行相加。
数值的前后带有空格也可以成功转换
int(" 100 ") # 结果为100带有符号的数字也可以成功转换
int("-1") # 结果为-1
int("+1") # 结果为1要把一个带小数点的字符串转换为float类型,使用float(), 同上,数值带空格,正负号也可以正常转换
int类型和flfloat类型之间也可以相互转换,但float转换为int时,小数部分精度将被丢弃,只取整数部分
int(3.14) #结果为3
int(9.9) # 结果为9
float(100) # 结果为100.0想要四舍五入的来转换,用round,可以指定小数点后位数
round(9.9) #结果为10
round(9.5) #结果为10
round(3.1415926, 2) #结果为3.14布尔值也可以转换为int或者float
int(True) # 结果是1
int(False) # 结果是0
float(True) # 结果是1.0
float(False)# 结果是0.03 运算符
3.1 算术运算符

print(1 + 1)
print(10 - 5)
print(4 * 2)
print(4 / 2) # 结果是2.0 需要注意的是当使用单斜杠除法运算符时,即使除数和被除数都是整数,返回结果也是一个浮点数。
print(4 // 2) # 结果是2所有的运算符两边都有一个空格,这是Python代码的书写规范
取模运算符大家先暂时可以理解为取余数,记住以下几个规则:
- 当两个数能整除时,取模运算的结果为0,比如 8 % 4 的结果是0
- 当0
- 当两个数中有负数时,结果可能会跟我们预料的不同,记住这个公式就行了 :a % b 就相当于a -(a // b) * b
最后,提醒一下,0不能作为除数,也不能用来取模。
3.2 使用算术运算符操作字符串
加号可以将两个字符串拼接成一个字符串,也可以将多个字符串拼接在一起
>>> print('hello' + 'world')
helloworld
>>> print('apple' + 'apple' + 'apple')
appleappleapple可以使用"*"运算符,表示将该字符串重复几次并拼接成一个字符串
>>> print('apple' * 3)
appleappleapple使用加号拼接字符串时需要注意,不能将字符串与数值一起相加
>>> print("您账户积分为:" + str(500))
您账户积分为:500
>>> print("您账户积分为:" ,500)
您账户积分为: 5003.3 赋值运算符
使用等于号赋值
更多的赋值操作:

>>>count = 0
>>>count += 1
>>>count
1
结果变成了13.4 比较运算符
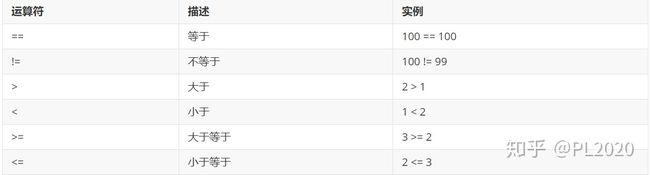
比较运算符是用来运算布尔值的, 将两个值放在一起比较,最后得到True或者False。
100 == 100 # True
100 == "abc" # False
1 != 2 # True
4 // 2 ==2 #True
4 / 2 ==2 #True
100 == "100" # False
100 == 50 * 2 # True
str(100) == "100" # True
1.0 != 1 # False
int(1.9) == 1 # True 3.5 逻辑运算符
逻辑运算符将多个比较运算连接

>>> n = 5
>>> n >= 0 and n % 2 !=0
True
>>> not n == 5
False
>>> n = 30
>>> (n > 0 and n < 60) or (n > 90 or n < 100)
True
>>> not True
False
>>> not 1
False #python将1转换为了布尔值
>>> 1 and 2 - 2 and 3 - 4 #-1 的布尔值也是1
0逻辑运算符可以与赋值操作组合,让代码更老练:
>>> n = 30
>>> a = n or 100 #非零值的布尔值为true,停止运算
>>> a
30
>>> a = 1 or 100
>>> a
1
>>> a = 0 and 100
>>> a
0
>>> n=0
>>> n = 0
>>> a = n or 1
>>> a #零值的布尔值为False,继续运算
14 条件判断
4.1 if...else...语句
if 和 else,看它们的字面意思就能猜到它们表示“如果”... “否则”.
num = 3 # 通过取模运算判断num是否能被2整除
if num % 2 == 0:
print(str(num) + "是一个偶数")
else:
print(str(num) + "是一个奇数")注意两条print语句前面的缩进,缩进4个空格或Tab,pycham里回车自动缩进
Ctrl + / :切换注释
4.2 elif
score = 56
if score > 60:
print('您的成绩不合格')
elif score < 90:
print('您的成绩合格')
else:
print('您的成绩优秀')4.3 if 条件嵌套
pass是Python的关键字,它表示什么也不做。
# 60以下 不及格
# 60~70 合格
# 70~90 良好
# 90以上 优秀
score = 89
if score >= 60:
pass #用pass先占位
else:
print('您的成绩不合格')
完整:
score = 89
if score >= 60:
if score < 70:
print('您的成绩合格')
elif score < 90:
print('您的成绩良好')
else:
print('您的成绩优秀')
else:
print('您的成绩不合格')4.4 与逻辑运算符组合
age = 22
if age > 18 and age < 60:
print("你已经不是个孩子啦,该去工作啦")此处会提示更简洁的写法
if 18 < age < 60:
print("你已经不是个孩子啦,该去工作啦") 4.5 自动类型转换
if 和 elif 的后面总是跟着一个表达式,这个表达式的结果必须是True或者False,如果表达式运算出来的结果不是一个布尔值,则会自动将结果转换为布尔值,无论它是什么类型的值。转换的结果遵循之前学过的布尔转换规律。
count = 0
if count:
print("条件成立")
else:
print("条件不成立")
返回:条件不成立,若count的值改为1,则返回:条件成立
result = None
if result: #不会写if result == None:
print(result)
else:
print("什么收获都没有")
返回:什么收获都没有记住:0值、None 和空字符串转换为布尔值后都是False
result = 1
if result:
print(result)
else:
print('什么都没有')
result = '123'
if result:
print(result)
else:
print('什么都没有')
返回:1 5 循环
5.1 while循环
while循环不断的运行,直到指定的条件不满足为止
lap = 0
while lap < 10:
lap += 1
print('我跑完了第' + str(lap) + '圈')
print('跑步结束')输出:
我跑完了第1圈
我跑完了第2圈
我跑完了第3圈
我跑完了第4圈
我跑完了第5圈
我跑完了第6圈
我跑完了第7圈
我跑完了第8圈
我跑完了第9圈
我跑完了第10圈
跑步结束
5.2 for循环
for循环用于针对集合中的每个元素的一个代码块。
for循环可以用来遍历序列,序列指的是一个可迭代的有序的集合,比如字符串就是一个序列,下面用for循环来打印出一个字符串中的所有字符。
seq = 'world'
for i in seq:
print(i)输出:
w o r l d
for i in range(5):
print(i)输出:
0 1 2 3 4
注意:索引是从0开始,而不是从1开始
之前写的跑圈的while循环,改用for循环加range函数来实现,for循环更简洁
for i in range(5):
print('我跑完了第' + str(i) + '圈')
print('跑步结束')输出:
我跑完了第0圈 我跑完了第1圈 我跑完了第2圈 我跑完了第3圈 我跑完了第4圈 跑步结束
5.3 嵌套循环
既然掌握了两种循环写法,那可以把它们组合起来运用,
例:在控制台中打印出指定边长的长方形或者正方形图案
# 指定长方形的宽和高
width, height = 10, 5
# 因为是从上往下开始打印,所以先遍历高度
for i in range(height):
for j in range(width):
print("*", end='') #默认end是换行符,end=''即为不加换行符
print() 在这里,print函数有了第二个参数,end表示在打印完指定的内容后,在结尾再打印一个指定的字符串,默认每个print语句在结尾会加一个换行符"n", 传递一个空字符串给它,表示打印完星号以后不再添加任何输出内容。
第二个print函数没有任何参数,那它会输出一个换行符。
所以整个程序的逻辑就是每输出10个星号后,输出一个换行符,最终输出的图案如下:
**********
**********
**********
**********
**********
自己练习:
for hight in range(5):
for width in range(10):
print('*',end='')
print()打印一个直角三角形:
for i in range(5):
for j in range(i + 1):
print("*", end='')
print()
或
for i in range(5):
print('*' * (i+1),end='')
print()
输出为:
*
**
***
****
*****%s 创建了包含变量内容的字符串,只要将变量放入字符串中,紧跟着一个百分号%,紧跟着变量名即可,放入多个变量的时候,需要将变量放到()圆括号中,变量之间用逗号隔开
乘法表
for i in range(1,10):
for j in range(1,i+1):
print('%s*%s=%s' % (j, i, i * j), end=' ') #注意end=' '中间有个空格
print()
或
for i in range(1,10):
for j in range(1,i+1):
print(str(j) + '*' + str(i)+ '='+ str(i * j),end=' ')
print()
输出为:
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81 5.4 break和continue
有时候在循环内部,我们需要临时略过某一次循环或者干脆跳出整个循环,这时候就需要用到continue和break。
- 要返回到循环开头,根据条件测试结果决定是否继续执行循环,可使用continue语句;
- 要立即退出while循环,不再执行循环中剩下的代码,也不管条件测试的结果如何,可使用break语句;
lap = 0
while lap < 3:
lap += 1
if lap == 2:
continue
print("我跑完了第" + str(lap) + "圈")
print("跑步结束")输出为:
我跑完了第1圈 我跑完了第3圈 跑步结束
输出10以内的奇数
for i in range(10):
if i % 2 == 0:
continue
print(i)
或
num = 0
while num < 10:
num += 1
if num % 2 == 0:
continue
print(num)
输出为:
1
3
5
7
9输出10以内的奇数,并求和
total = 0
for i in range(10):
if i % 2 == 0:
continue
total += i
print(i,end='')
if i == 9:
continue
print('+',end='')
print('='+str(total))
或
total = 0
for i in range(10):
if i % 2 == 0:
continue
total += i
print(i,end='')
if i == 9:
continue
print('+',end='')
print(" = %s" % total)
输出为:
1+3+5+7+9=25关键字break用来打断整个循环并跳出。
例,给一个字符串,这个字符串是一个小数,要求打印出小数的整数部分。
num = '345.903567' 注意是字符串
for i in num:
if i == '.':
break
print(i, end='')
输出为:
3456 演示:智能密码锁程序
密码开锁功能是这样的,首先设定好密码,以后每次开锁的时候只要输入的数字中含有设定的密码,就视为解锁成功。
首先,由于涉及到了输入,先来学习一下Python内置的输入函数: input
password = input("请设置您的密码 n")在执行到这行代码时,控制台就变成光标闪烁的状态,用户可以用键盘进行字符的输入,输入完成后,再输入一个回车表示输入结束,输入的字符串赋给等号左边的变量。
n 换行符
开锁的时候只要输入的数字中含有设定的密码,使用关键字 in
修改初始密码
# 设置初始密码
password = '123'
while True:
pwd = input("请设置您的密码:n")
# 如果没有输入任何密码,则使用初始密码作为密码
if not pwd:
break
confirm_pwd = input("请再次输入您的密码:n")
if pwd == confirm_pwd:
password = pwd
break
print("您两次输入的密码不致,请重新输入")
print("您的初始密码已设置为:", password)
print("进入开锁程序")
failed_time = 0
while True:
input_pwd = input("请输入您的密码:n")
if password in input_pwd:
print("开锁成功")
break
else:
failed_time += 1
if failed_time >= 3:
print("输入错误超过3次,请联系主人")
break
print("您输入的密码有误,请重新输入")我的练习:
password = 123
while True:
pwd = input('请设置密码: n')
if not pwd:
break
confirm_pwd = input('请确认密码 n')
if pwd == confirm_pwd:
password = pwd
break
print('两次输入的密码不一致,请重新输入')
print('密码已设置为',password)
print('进入开锁程序')
fail_time=0
while True:
pwd = input('请输入密码 n')
fail_time += 1
if password in pwd:
print('开锁成功')
break
print ('密码错误%s次' % fail_time)
if fail_time == 3:
print('密码锁定')
break三、数据结构
1 字符串的格式化输出
1.1 格式化占位符
| 占位符 | 描述 |
|---|
如果给%d 传入一个浮点数,那它会自动将它转换成整数
print("%d" % 3.14) # 输出3
print("%d" % 3.99) # 输出3转换成整数的规则和类型转换的规则一 样,不会四舍五入。
%f的用法有两种,一种就是直接使用,比如
print("%f" % 3.14) 它会输出“3.140000”,后面的0是自动补齐的,如果我们只想要输出小数点后两位,可以这样写:
print("%.2f" % 3.14)
print("%.2f" % 3.1415926) 上面的两行代码输出都是"3.14","%.2f" 这种写法指定了小数点后面的位数,即使浮点数后面的小数部分超出了2位,也只会输出两位。如果不足两位,或者是个整数,会自动补零到两位。
print("%.2f" % 3) # 3.00
print("%.2f" % 3.1) # 3.10 %s 是胜任最广泛的占位符,它可以对应任何类型的变量。%s 创建了包含变量内容的字符串,只要将变量放入字符串中,紧跟着一个百分号%,紧跟着变量名即可,放入多个变量的时候,需要将变量放到()圆括号中,变量之间用逗号隔开。
print("%s" % 100) # 输出100
print("%s" % 3.14) # 输出3.14
print("%s" % "python") # 输出python 在同一个字符串可以同时使用多个占位符:
report = "%d年%s公司营收增长了百分之%.2f" % (2019, "腾讯", 20.28)
print(report)当需要在字符串输出一个百分比,就需要用到%%,比如说:
report = "%d年%s公司营收增长了%.2f%%" % (2019, "腾讯", 20.28)
print(report) 1.2 format函数
除了%运算符外,Python还提供了字符串的format函数提供丰富的格式化。
比如说,在输出一个较长的数字时,根据国际惯例,每三位用逗号分隔:
print('{:,}'.format(1234567890))
# 1,234,567,890 format函数也可以像%那样来格式化多个参数:
report = "{0}年{1}公司营收增长了{2}%".format(2019, "腾讯", 20.28)
print(report)
# 2019年腾讯公司营收增长了20.28%{0}表示第一个参数,{1}{2}表示第二、第三个参数,以此类推。这样做的好处是,如果有参数在字符串出现多次,可以不用重复的传入。
s = "{0}的GDP为{1:,}...虽然它的GDP只有{1:,}美元,但它的人均GDP高达18万美元".format("摩纳哥", 871000000000)
print(s)
# 摩纳哥的GDP为871,000,000,000...虽然它的GDP只有871,000,000,000美元,但它的人均GDP高达18万美元2 字符串的下标和切片
字符串其实也是一种序列,可以理解为一串整齐的按顺序排着队的字符,组成了字符串,那每个字符在队伍中都有自己的位置,这个位置就是下标,又叫作索引。
"CHINA"这个字符串,从左往右每一个字符对应了一个下标(索引),需要特别注意的是,在计算机编程中,**所有的下标都是从0开始的,当我们要访问一个字符串的第1个字符时,使用的下标应该是0。使用负数下标可以从右往左访问,这种写法是Python特有的,非常的快捷,对于任意长度的字符串,都可以使用-1来获取它的最后一个字符,注意使用负数下标是是从-1开始的,因为-0也是0,产生重复了。


使用中括号加数字的方式,表示要访问的是具体哪个位置上的字符。
- 冒号右边的省略,表示一直截取到最后一个字符
- 冒号左边为空表示从第一个字符开始截取
- s[::2]第二个冒号表示截取步长,这里的2表示每两个字符取一个,如果不传,默认就是每一个都取。步长也可以为负数,如果传递了一个负数,则表示是从右往左进行截取
s = "CHINA"
s[0] # C
s[-1] # A
s[-2] # N
"CHINA"[0:0] # 空字符串
"CHINA"[0:-1] # CHIN
s[0:3] # CHI
s[:3] # CHI
# 取出整个字符串
s[0:5] # CHINA
s[0:] # CHINA
s[:] # CHINA
# 从第三个到末尾
s[2:] # INA
# 从头到尾每隔两个字符取一个
print(s[::2]) # CIA
# 每隔两个字符取一个
print("abcdefghijklmn"[8:16:2]) #ikm
# 逆序
print(s[::-1]) # ANIHC
# 逆序每隔两个字符取一个
print(s[::-2]) # AIC3 字符串函数
3.1 去除空白字符函数
先来了解一下什么是空白字符,空白符包括空格、换行(n)、制表符(t)。
print(" AtBtCnDtEtF ")
输出:
A B C
D E F 按键盘上的空格键会产生一个空格,按回车键则会产生一个换行符,按Tab键则会产生一个制表符,用户在输入数据的时候有时候经常会误输入这几个字符,所以在在处理用户输入的数据时,要先去除头尾的空白字符。
strip函数的作用就是去除字符串首尾的所有空白字符
" abc ".strip()
"t abc n".strip() 得到的将是字符串"abc",但是strip函数并不会去除掉字符串之间的空白字符
" a b c ".strip() 得到的结果是"a b c",只去掉了首尾空白字符,保留了中间的。
另外还有 lstrip 和 rstrip 函数,分别去除字符串左边和右边的空白字符
" abc ".lstrip() # 结果'abc '
" abc ".rstrip() # 结果' abc'3.2 大小写操作
# 将所有字符变成大写
print("china".upper()) # CHINA
# 将字符串的首字母变成大写
print("china".capitalize()) # China
# 将所有字符变成小写
print("CHINA".lower()) # china
# 将每个单词的首字母变成大写
print("i have a dream".title()) # I Have A Dream 3.3 字符串判断
判断字符串是否以指定的字符串开头或者结尾,返回结果为True 或False
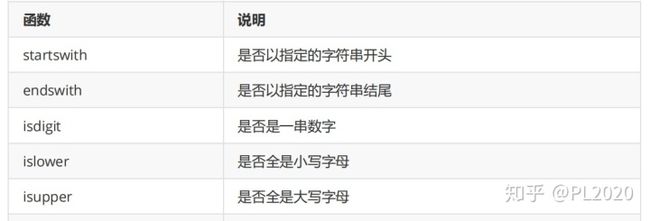
print("China".islower())
print("CHINA".isupper())
print("123456a".isdigit())
print("china".startswith('chi'))
print('China'.endswith('na'))
print("-2423333".startswith('-'))3.4 查找与替换
在前面智能密码锁的案例中,用过in来判断一个字符串是否被包含在另一个字符中
password = '123'
input_pwd = '456123789'
password in input_pwd # True 如果想要知道password在input_pwd中的确切位置,就需要使用find函数,注意索引是从0开始的,如果没有找到则会返回-1
input_pwd.find(password) # 结果是3
input_pwd.find("notexists") # 结果是-1 除了find函数,index函数也有相同的功能,唯一的区别是 ,index函数如果没有找到相应的字符串就会报错
count函数能够查找出指定的字符串一共出现了几次,如果没有出现,则返回0。
"abba".count('a') # 2
'abba'.count('c') # 0 replace函数提供了替换字符串中某些部分的功能
print("abba".replace('a', 'b')) #bbbb
print("apple orange".replace('apple', 'orange')) #orange orange3.5 字符串长度
字符串本身没有测量长度的函数,需要借助一个Python内置函数len。
len("China") # 5
len("") # 0
len("a") # 1 len函数非常重要,它不光可以测量字符串的长度,也可以测量其他所有有长度的对象。
r = range(10)
len(r)
# 10 3.6 综合案例:异常号码数据分析
结合以上的字符操作知识,可以开发一个电话号码识别程序,用户输入一串数字,程序识别它是不是一个有效的电话号码,如果是有效电话号码,我们再识别它是一个固定电话号码、手机号码、还是400号码。用户输入"exit"后,程序退出。
实现代码如下:
# 11位
# 13 15 17 18 19
# 区号+电话号码 010, 0888 + 8位=11位或12位
# 400电话:400开头,10位
# 当用户输入exit的时候,程序退出
cellphone_number_start = "13 15 17 18 19"
telephone_number_start = "010 021 022 025 0888 0555"
# 13812345678
while True:
num = input("请输入一个电话号码:n")
if num.strip() == 'exit':
break
if not num:
print("电话号码不能为空")
continue
num = num.strip()
if not num.isdigit():
print("您输入的是一个无效电话号码")
continue
if num[:2] in cellphone_number_start and len(num) == 11:
print("这是一个手机号码")
continue
if num.startswith('0'):
# 01088888888
# 088812345678
if (len(num) == 12 and num[:4] in telephone_number_start) or
(len(num) == 11 and num[:3] in telephone_number_start):
print("这是固定电话号码")
continue
if num.startswith('400') and len(num) == 10:
print("这是一个广告电话")
continue
print("无法识别该号码")注意:continue的位置,if语句检查结果,如果为True,就忽略剩下的代码,返回到循环开头。如果为False, 就继续执行余下的代码;
4 元组 tuple
4.1 定义元组
知道了字符串是一种序列,它可以迭代循环,也可以按索引访问,也可以切片访问。但它的组成只能是单个的字符,现在来介绍一种更多元化的序列:元组,英文叫tuple
- 元组和字符串一样,是不可变序列,需要记住的是元组和字符串都是只读的,也就是不可修改的。我们不能单独改变元组中的某个元
素,或者是字符串中的某个字符。 - 元组定义的时候也可以不用括号
- 但当,元组中只有一个元素的时候,必须要加一个逗号
# 元组的定义
t = tuple('python')
t = ('p', 'y', 't', 'h', 'o', 'n')
t = ('My', 'age', 'is', 18)
t = 'My', 'age', 'is', 18
t = ('Solo',)
t = 'Solo',下面元组中包含了3个字符串,一个整形数字,元组中的每一项称作元素,4个元素按照从左到右的顺序排列。可以用下标索引访问:
t = ('My', 'age', 'is', 18)
t[0] # 'my'
t[-1] # 18 也可以通过切片来访问,注意切片返回的是一个包含切片片段的新元组。
t[0:2] # ('My', 'age') 可以将一个序列强制转换为元组,后面的逗号表明这是一个元组,否则就会被认为是一个字符串。
tuple('abc') # ('a', 'b', 'c')
tuple(range(5)) # (0, 1, 2, 3, 4)4.2 元组操作
函数join,有了它,可以把元组这样的序列拼接成一个整体的字符串。
# 注意最后一个元素
t = ('My', 'age', 'is', "18")
print(" ".join(t)) 用空格拼接
print("+".join(t)) 用+拼接
# 输出结果:
My age is 18
My+age+is+18 注意最后一个元素,这次我们将它设置成了字符串,因为join函数要求参数序列中的每一个元素都必须是字符串。
和字符串一样,元组也有count, index函数,使用的方法也是一样:
t = ('a', 'b', 'b', 'a')
print(t.count('a')) #2
print(t.index('b')) #1测量长度
t = tuple(range(10000))
print(len(t), t[0], t[-1]) #10000,0,9999元组也支持 in 操作,想要判断元组中是否包含某个元素:
print(8888 in t) #True
print(10000 in t) #False4.3 遍历元组中所有的值:
t = ('a', 'b', 'c', 'd', 'e')
for i in t:
print(i)
或
i = 0
while i < len(t):
print(t[i])
i += 1
输出为:
a
b
c
d
e4.4 综合案例:销售数据统计-销冠
在真实的项目中,数据结构通常是比较复杂,经常碰到嵌套的元组,甚至是多层嵌套,来看一个例子:
某公司所有销售人员第一季度销售业绩的元组,单位是万元,其中的每一个元素对应一个销售人员的信息,人员信息也是一个元组,包括姓名和业绩,业绩又是一个元组,按照顺序分别是1、2、3月份的销售额。需求:找出总销售额最高的那个员工,并将TA的名字和总销售额输出。
sales = (("Peter", (78, 70, 65)),
("John", (88, 80, 85)),
("Tony", (90, 99, 95)),
("Henry", (80, 70, 55)),
("Mike", (95, 90, 95)))
champion = ''
max_amount = 0
for sale in sales:
name = sale[0]
quarter_amount = sale[1]
total = 0
for month_amount in quarter_amount:
total += month_amount
if total > max_amount:
champion, max_amount = name, total
print('第一季度的销售冠军是%s,ta的销售额是%d万元' %(champion, max_amount))上面的代码也可进一步优化一下,使得代码行数更少,结构更简单。
for name,quarter_amount in sales:
total = sum(quarter_amount)
if total > max_amount:
champion, max_amount = name, total
print('第一季度的销售冠军是%s,ta的销售额是%d万元' % (champion, max_amount))5 列表 list
5.1 定义列表
列表可以理解为可变的元组,它的使用方式跟元组差不多,区别就是列表可以动态的增加、修改、删除元素。
列表的定义
# 定义一个空列表
lst = []
lst = list()
# 定义带有初始值的列表
lst = [1, 2, 3] #[1, 2, 3]
lst = ["a", 1, 2, 3, "b", "c"] #["a", 1, 2, 3, "b", "c"]
lst = list(range(5))
lst = list("abc") #["a", "b", "c"]
lst = list((1, 2, 3)) #[1, 2, 3] 5.2 增删改查
列表的访问和字符串、元组一样,索引或者下标都可以。 注意,索引只返回该元素,而不包括方括号和引号,切片返回的是一个包含切片片段的新列表。
lst = ['a', 'b', 'c', 'd', 'e']
print(lst[0]) # a
print(lst[1:3]) # ['b', 'c']
列表是可以修改的, append函数总是在列表后面添加元素,还是以上面的lst为例:
print(lst.append(f)) #['a', 'b', 'c', 'd', 'e', 'f']修改列表中的元素
lst[0] = 'A'
lst[-1] = 'F'
print(lst)
#['A', 'b', 'c', 'd', 'e', 'F']删除列表中的元素,使用del语句
del lst[0]
del lst[-1]
print(lst)
# ['b', 'c', 'd', 'e']注意,由于我们删除的是第一个元素,现在剩下的所有元素的索引都发生了变化,第一个lst[0]变成了'b',后面的也都往前挪了一位。但是lst[-1]没有变,还是'f'。涉及到删除操作的时候要小心,防止使用错误的索引。
5.3 列表函数
列表也是一种序列,它也具有index和count函数和支持len函数,这些函数的用法和元组一样,它的循环遍历也和元组一样。
lst = ['a', 'b', 'c', 'd', 'e','a']
len(lst) # 5
lst.count('a') #2
lst.index('a') #0下面来介绍一下列表特有的一些函数。
insert
insert函数和刚刚介绍的append函数一样,用来向列表中添加一个新的元素,区别就是append是在最后添加,insert则可以向任意位置添加。**在索引位置的前面添加**。注意,索引位置的变化
lst = ['a', 'b', 'c', 'd', 'e']
lst.insert(0, 'A')
lst.insert(2, 'B')
lst.insert(-1, 'E')
print(lst)
# ['A', 'a', 'B', 'b', 'c', 'd', 'E', 'e']pop
删除列表末尾的一个元素
每次调用pop函数会从列表中“弹”出一个元素,跟del的区别是,pop将元素删除,并能获取到它的值
temp = lst.pop()
print(lst) # ['a', 'b', 'c', 'd']
print(temp) # 'e'
lst.pop()
last = lst.pop()
print(lst, last)
while lst: #bool([])返回的是False
print(lst.pop())
print(lst)
#d
c
b
B
a
A
[]如果想“弹”出其他位置的元素,可以传一个位置参数给pop函数,像这样:
temp = lst.pop(2)
print(lst) # ['a', 'b', 'd']
print(temp) # 'c' remove
前面我们已经学习了使用del关键字去删除列表元素,del操作可删除指定下标索引的元素,如果我们要删除指定内容的元素,就需要用到remove函数。
lst = [1, 2, 1, 'a', 'b', 'c']
lst.remove('a')
print(lst) # lst的值为[1, 2, 1, 'b', 'c']
lst.remove(1) # 注意这里的1是元素值,不是索引
print(lst) # lst的值为[2, 1, 'b', 'c'] remove函数会从左至右找到与指定的值相匹配的第一个元素,并将它删除。
lst = ['a', 'b', 'c', 'd', 'e', 'c']
lst.remove('c')
print(lst)
# ['a', 'b', 'd', 'e', 'c']使用remove()从列表中删除元素时,也可接着使用它的值。
clear
clear函数会清空列表内的所有元素。
lst = [1,2,3,4]
lst.clear()
print(lst) # 结果为[]extend
extend函数有点像append函数,但append函数每次只能添加一个元素,而extend可以添加一组。
lst = []
lst.extend(range(5))
print(lst) # [0, 1, 2, 3, 4]
lst.extend([5, 6, 7])
print(lst) # [0, 1, 2, 3, 4, 5, 6, 7] reverse
将整个列表反转,以上一步的lst为例
lst.reverse()
print(lst) # [7, 6, 5, 4, 3, 2, 1, 0] sort
按照一定的规则将列表中的元素重新排序,对于数值,默认按从小到大的顺序排列。sort()对列表进行永久性排序。
lst = [3, 5, 2, 1, 4]
lst.sort()
print(lst)
# [1, 2, 3, 4, 5] 如果想要让列表从大到小排列,可以加上reverse参数。
lst = [3, 5, 2, 1, 4]
lst.sort(reverse=True)
print(lst)
# [5, 4, 3, 2, 1] 对于字符串,则会按照它们的ASCII值的顺序排列。ASCII是基于拉丁字母的一套电脑编码系统,所有的编程语言都支持ASCII编码。ASCII值一共有128个字符,包含数字0~9,字母a-z, A-Z,还有一些常用的符号。每一个字符对应一个数字,比如字母'A'对应的就是65, 字母'B'对应66,等等。在Python中,可以使用内置函数将字符与它的ASSCII值互转。
# ASCII 0~9 , A~Z, a~z,每个字符对应一个数字。
# ord, chr 可以将字符与ASCII值相互转换。
ord('A') # 65
chr(66) # 'B'sort函数会比对每个字符串的第一个字符,如果第一个字符相同,则比对第二个字符,以此类推。
fruits = ['apple', 'banana', 'orange', 'blueberry']
fruits.sort()
print(fruits) # ['apple', 'banana', 'blueberry', 'orange'] 注意观察"banana"和"blueberry"的顺序。
如果列表的元素不是简单的字符或者数字,那怎么进行排序呢,比如有下面一个列表,它存储了公司第一季度每个月的收入。
revenue = [('1月', 5610000), ('2月', 4850000), ('3月', 6220000)]注意列表中的每一个元素是一个元组,元组的第一项是月份,第二项是销售额,现在想要按照它的销售额来从高到低排序。如果直接调用sort函数,它会按照元组中第一项的字符串顺序进行排序。
revenue.sort(reverse=True)
# 排序后为 [('3月', 6220000), ('2月', 4850000), ('1月', 5610000)]
# key参数,使用每个元素的第二个索引作为排序依据
revenue.sort(reverse=True, key=lambda x: x[1])
print(revenue)
# 排序后为 [('3月', 6220000), ('1月', 5610000), ('2月', 4850000)]key参数接收的是一个函数,我们在这里给它传递了一个匿名函数,关于函数的使用后面再学习,这里需要了解是通过key参数,我们指定了sort排序的依据,就是每个元组里面的第二项。
看一个例子:
a = list ('I love cake')
a.sort()
print(a)
print(''.join(a[2:]))
#[' ', ' ', 'I', 'a', 'c', 'e', 'e', 'k', 'l', 'o', 'v']
Iaceeklovcopy
lst1 = [1, 2, 3]
lst2 = lst1
lst1.append(4)上面的代码执行完成以后,lst 和 lst2的值都变成了 [1, 2, 3, 4] ,但我们在代码里面只修改了lst1,lst2的值也跟着改变了,这不符合我的预期,可能会导致bug。所以,如果我们想要创建一个跟lst1一模一样的新列表,且不再受它以后操作的影响,就可以使用copy函数:
lst1 = [1, 2, 3]
lst2 = lst1.copy()
lst1.append(4)
print(lst1) # [1, 2, 3, 4]
print(lst2) # [1, 2, 3] 5.4 列表表达式
列表表达式是一种快捷的创建列表的表达式,可以将多行代码省略为一行。比如,列出20以内的所有偶数
lst = [i for i in range(20) if i % 2 == 0]
print(lst)
# [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]当然,上面的代码我们也可以这样实现
[i * 2 for i in range(10)]
[i for in in range(0,20,2)]列出10以内的奇数
lst = [i for i in range(10) if i % 2]
lst = [i *2 + 1 for i in range(0, 5)]
lst = [i for i in range(1, 10, 2)]range函数可以接收三个参数:第一个是起始数值(包含),可以省略,默认从0开始;第二个是结束数值(不包含);第三个是步长,可以省略,默认为1。
再看一个例子,打印出大写的26个字母。
# 65是大写字母‘A’的ASCII值
[chr(i) for i in range(65, 65 + 26)]5.5 综合案例销售数据统计排行榜
上面销售冠军的例子,
sales = (("Peter", (78, 70, 65)),
("John", (88, 80, 85)),
("Tony", (90, 99, 95)),
("Henry", (80, 70, 55)),
("Mike", (95, 90, 95)))现在将计算出每人的总销售额,并按销售额从多到少,存放到一个列表里。
lst = []
for name, quarter_amount in sales:
total = sum(quarter_amount)
lst.append((name, total))
lst.sort(key=lambda x:x[1], reverse=True)
print(lst)
# [('Tony', 284), ('Mike', 280), ('John', 253), ('Peter', 213), ('Henry', 205)]这个案例用列表表达式来开发,将会非常快速。
lst = [(name,sum(quarter_amount)) for name, quarter_amount in sales]
lst.sort(key=lambda x: x[1], reverse=True)
print(lst)6 字典dict
6.1 字典的定义
使用花括号,可以直接定义字典
sales = {
'Peter': 213,
'John': 253,
'Tony': 284,
'Henry': 205,
'Mike': 280
}每一行冒号左边的是键(key),右边的是值(value),称作键值对,以逗号分隔开。在这里我们故意写成每行一个键值对,实际并不要求每行一个,只要用逗号分隔开来就可以。键是不能重复的,值可以重复。
# 两种定义字典的方式
sales = {
'Tony': 284,
'Mike': 280,
'John': 253,
'Peter': 213,
'Henry': 205,
}
sales = dict(top_sales)
print(sales)
print(sales['Mike'])
6.2 增删改查
# 添加数据
sales['mike'] = 0
print(sales['mike'])
# 修改数据
sales['mike'] = 300
print(sales)
# 删除
del sales['mike']
print(sales)注意,键的名称是区分大小写的,'Mike' 和 'mike'分别对应了不同的键。
6.3 遍历字典
字典的遍历和列表、元组、字符串有所区别,由于它的每一项都是一个键值对,所以在遍历时也要注意。
注意 sales.items() 这种写法,在遍历字典时,这是一种通用的写法。items函数将字典内的内容转换成了一种可迭代的序列,以供for循环遍历,遍历出来的每一项是一个元组,包含了键和值。所以通常直接写成这样:
for key, value in sales.items():
print(key, value)
#Tony 284
Mike 280
John 253
Peter 213
Henry 205注意中间的逗号和最后的打印结果。
如果不使用items函数,那遍历的就是字典所有的key。
for key in sales:
print(key) 6.4 字典函数
字典有一些函数和列表是一样的,比如clear, copy,来看看其他的函数。
get
如果直接访问字典中一个不存在的key,就会产生报错,为了避免报错,如果字典中不存在则返回None,也可以赋值返回0
print(sales.get('mike', 0))
# 相当于下面的写法
if 'mike' in sales:
print(sales['mike'])
else:
print('mike', 0)这一行短短的代码就实现了上面4行代码的功能,它表示在字典中查询'mike'键所对应的值,如果不存在'mike'键,则返回0。这里的0可以替换成任何其他的默认值,这样就极大简化代码逻辑。
keys/values
如果只想单独列出所有的销售人员名单或销售额,可以这样写:
print(sales.keys()) #dict_keys(['Tony', 'Mike', 'John', 'Peter', 'Henry'])
print(sales.values()) #dict_values([284, 280, 253, 213, 205])
可以对它进行遍历
for sale in sales.keys():
print(sale)
# 如果只想计算出所有销售人员的销售额总和,也就是公司总销售额,可以直接取出value部分并求和:
print(sum(sales.values())) #12357 集合 set
集合在Python中是一个无序的不重复的序列,一般用来删除重复数据,还可以计算交集、并集等。
7.1 集合的定义
两方式都可以定义一个集合
nums = {1, 2, 3, 4, 5}
nums = set([1, 2, 3, 4, 5]) 注意,集合是无序的,虽然我们在书写的时候是按照从小到大的顺序,有时候遍历出来也是有序的,但不能把它视为有序,并作为某些逻辑的依据。
集合最常用的用法是用来消除列表或者元组中的重复元素
列表里里面有两个1,先将lst转成了集合,再将集合转成了列表,最终得到了一个没有重复元素的列表[1, 2, 3, 4, 5] ,注意最后得到的列表的顺序有可能跟原来是不一样的。
lst = [1, 2, 3, 1, 3, 4]
nums = set(lst)
print(nums)
#{1, 2, 3, 4}
t = ('a', 'b', 'a', 'c')
print(set(t))
#{'c', 'b', 'a'}转成列表或元组
print(list(nums)) #[1, 2, 3, 4]
print(tuple(nums)) #(1, 2, 3, 4)7.2 遍历集合
集合的遍历和列表、元组很相像,再次重申,它不是有序的。
for n in nums:
print(n)也可以通过len函数来测量它的长度,准备地讲,在数学上叫集合的基数。
print('nums的长度:', len(nums))可以通过 in 来判断集合中是否有某个特定的元素
print(5 in nums)7.3 增删改查
往集合里添加一个元素
nums.add(5)如果集合里已经有这个元素了,则什么也不做。像上面的第一行代码,什么也没有做。
已经加入集合的元素不能修改,只能删除,删除集合里的元素:
nums.remove(5)
nums.remove(5) # Errorremove函数会从集合里删除指定元素,但如果元素不存在,则会报错,上面的第二行代码就会报错。
如果不想报错,可以使用diiscard函数
nums.discard(5)从集合内删除并返回一个元素:
num = nums.pop()如果集合是空的,则会报错。有时候也会使用pop函数来迭代一个集合。这样的好处是可以保证每个元素只被使用一次,不会重复使用
while len(nums) > 0:
num = nums.pop()
print(num)
或
while nums:
num = nums.pop()
print(num)将字典中的值互换
d ={'a': 1, 'b': 2}
d['a'],d['b']=d['b'],d['a']
print(d)7.4 集合函数
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5}
# 求交集
print(s1.intersection(s2)) #{3, 4}
# 求并集
s3 = s1.union(s2)
print(s3) #{1, 2, 3, 4, 5}
# 判断是否是子集
print(s1.issubset(s3)) #True
# 判断是否是父集
print(s3.issuperset(s2)) #True(以上就是对于part1 基本部分的分享,后面会继续记录学习笔记~~~)