KNN原理和实现
文章目录
-
-
- KNN的原理参考文章
-
- 这里我主要列出kd树上的knn算法
- 1、KNN的优缺点和使用范围
- 2、简单的代码实现(计算所有样本跟该样本的距离,没有用kd树实现)
- 3、实例:使用KNN进行电影分类
- 4、使用kd树实现KNN查看下面链接
- 5、总结
-
本篇介绍的机器学习算法:K-近邻算法,它非常有效而且易于掌握
在阅读本文前,希望先阅读一下两篇参考文章。
KNN的原理参考文章
1、KNN的原理: https://www.joinquant.com/view/community/detail/a98b7021e7391c62f6369207242700b2
2、(强推)KD数实现KNN思想详解: https://zhuanlan.zhihu.com/p/23966698
这里我主要列出kd树上的knn算法
给定一个构建于一个样本集的 kd 树,下面的算法可以寻找距离某个点 p 最近的 k 个样本。
零、设 L 为一个有 k 个空位的列表,用于保存已搜寻到的最近点。
一、根据 p 的坐标值和每个节点的切分向下搜索(也就是说,如果树的节点是照 [公式] 进行切分,并且 p 的 r 坐标小于 a,则向左枝进行搜索;反之则走右枝)。
二、当达到一个底部节点时,将其标记为访问过。如果 L 里不足 k 个点,则将当前节点的特征坐标加入 L ;如果 L 不为空并且当前节点的特征与 p 的距离小于 L 里最长的距离,则用当前特征替换掉 L 中离 p 最远的点。
三、如果当前节点不是整棵树最顶端节点,执行 (a);反之,输出 L,算法完成。
a. 向上爬一个节点。如果当前(向上爬之后的)节点未曾被访问过,将其标记为被访问过,然后执行 (1) 和 (2);如果当前节点被访问过,再次执行 (a)。
- 如果此时 L 里不足 kk 个点,则将节点特征加入 L;如果 L 中已满 k 个点,且当前节点与 p 的距离小于 L 里最长的距离,则用节点特征替换掉 L 中离最远的点。
- 计算 p 和当前节点切分线的距离。如果该距离大于等于 L 中距离 p 最远的距离并且 L 中已有 k 个点,则在切分线另一边不会有更近的点,执行 (三);如果该距离小于 L 中最远的距离或者 L 中不足 k 个点,则切分线另一边可能有更近的点,因此在当前节点的另一个枝从 (一) 开始执行。
1、KNN的优缺点和使用范围
简单的说,k-近邻算法采用测量不同特征值之间的距离方法进行分类
优点:精度高,对异常值不敏感、无数据输入假定
缺点:计算复杂度高,空间复杂度高
使用数据范围:数值型和标称型
2、简单的代码实现(计算所有样本跟该样本的距离,没有用kd树实现)
from numpy import *
import operator
import matplotlib.pyplot as plt
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
'''
k近邻算法:
1、计算已知类别数据集中的每个点与当前点之间的距离;
2、按照距离递增次序排序
3、选取与当前点距离最小的k个点
4、确定前k个点所在类别的出现频率
5、返回前k个点出现频率最高的类别作为当前点的预测分类
'''
def classify0(inX, dataSet, labels, k):
# 计算目标样本跟每一个样本的距离
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # 计算目标向量跟数据集中每一个向量的差值
sqDiffMat = diffMat ** 2 # 每一个差值求平方
sqDistances = sqDiffMat.sum(axis=1) # 求和
distances = sqDistances ** 0.5 # 开根号
print(distances) # 打印查看结果
# 排序增序
sortedDistIndicies = distances.argsort()
# 求前k的最近的样本中哪一个类别的样本最多
classCount = {
}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] # 获取排序后的下标对应的下标
classCount[voteIlabel] = classCount.get(voteIlabel, 0) +1 # 计算该标签有几个
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
if __name__ == '__main__':
group, labels = createDataSet()
print(group, labels, sep='\n')
result = classify0([0,0], group, labels, 3)
print(result)
运行结果:
[[1. 1.1]
[1. 1. ]
[0. 0. ]
[0. 0.1]]
[‘A’, ‘A’, ‘B’, ‘B’]
[1.48660687 1.41421356 0. 0.1 ]
B
3、实例:使用KNN进行电影分类
众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪 个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问 题。没有哪个电影人会说自己制作的电影和以前的某部电影类似,但我们确实知道每部电影在风格 上的确有可能会和同题材的电影相近。那么动作片具有哪些共有特征,使得动作片之间非常类似, 而与爱情片存在着明显的差别呢?动作片中也会存在接吻镜头,爱情片中也会存在打斗场景,我们 不能单纯依靠是否存在打斗或者亲吻来判断影片的类型。但是爱情片中的亲吻镜头更多,动作片中 的打斗场景也更频繁,基于此类场景在某部电影中出现的次数可以用来进行电影分类。
假设我们有这样一组数据

KNN算法通过计算出未知电影与样本集中其他电影的距离,然后选择距离最近的k个样本,在这k个样本中,哪一类别的样本的数量多,该算法认为该未知样本属于哪一个类别。
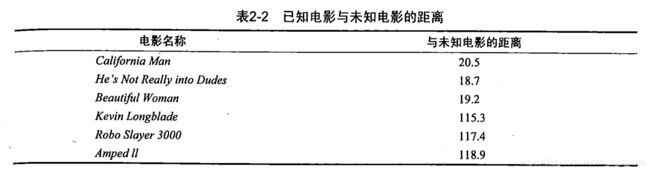

使用scikit-learn代码实现
import pandas as pd
import numpy as np
# 导入数据s
data = pd.read_excel('../../my_films.xlsx')
# 样本数据的提取
feature = data[['Action lens','Love lens']]
target = data['target']
# 训练模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
# n_neighbors 就是k ,n_neighbors=3是找到附近的3个邻居
knn.fit(feature,target) # 传入数据 模型训练完成
# 进行预测
knn.predict([[19,19]]) # array(['Love'], dtype=object)
# 一种简单的方法确定k的值
# score
knn.score(feature,target)
4、使用kd树实现KNN查看下面链接
在本链接文章的最后面
https://www.joinquant.com/view/community/detail/a98b7021e7391c62f6369207242700b2
5、总结
1、虽然该算法实现简单,但是在对数据的处理过程中不能忽视数据归一化这一步骤,这也会影响最终的结果
2、k的取值:根据李航老师的《统计学习方法》书中讲解的,在应用中,k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k值。