学生成绩统计----JavaSpark练习
学生成绩统计----Java版Spark练习
- 题目需求、数据、字段说明
- 1、统计每门课程的参考人数和课程平均分
- 2. 统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数。
- 3、求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分。
javaSpark练手题目,有不对或需要改进的地方还请大佬们指点出来,大家相互学习学习
题目需求、数据、字段说明
统计需求:
1、统计每门课程的参考人数和课程平均分
2、统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数。
3、求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分。
数据及字段说明:
computer,huangxiaoming,85,86,41,75,93,42,85
computer,xuzheng,54,52,86,91,42
computer,huangbo,85,42,96,38
english,zhaobenshan,54,52,86,91,42,85,75
english,liuyifei,85,41,75,21,85,96,14
algorithm,liuyifei,75,85,62,48,54,96,15
computer,huangjiaju,85,75,86,85,85
english,liuyifei,76,95,86,74,68,74,48
english,huangdatou,48,58,67,86,15,33,85
algorithm,huanglei,76,95,86,74,68,74,48
algorithm,huangjiaju,85,75,86,85,85,74,86
computer,huangdatou,48,58,67,86,15,33,85
english,zhouqi,85,86,41,75,93,42,85,75,55,47,22
english,huangbo,85,42,96,38,55,47,22
algorithm,liutao,85,75,85,99,66
computer,huangzitao,85,86,41,75,93,42,85
math,wangbaoqiang,85,86,41,75,93,42,85
computer,liujialing,85,41,75,21,85,96,14,74,86
computer,liuyifei,75,85,62,48,54,96,15
computer,liutao,85,75,85,99,66,88,75,91
computer,huanglei,76,95,86,74,68,74,48
english,liujialing,75,85,62,48,54,96,15
math,huanglei,76,95,86,74,68,74,48
math,huangjiaju,85,75,86,85,85,74,86
math,liutao,48,58,67,86,15,33,85
english,huanglei,85,75,85,99,66,88,75,91
math,xuzheng,54,52,86,91,42,85,75
math,huangxiaoming,85,75,85,99,66,88,75,91
math,liujialing,85,86,41,75,93,42,85,75
english,huangxiaoming,85,86,41,75,93,42,85
algorithm,huangdatou,48,58,67,86,15,33,85
algorithm,huangzitao,85,86,41,75,93,42,85,75
数据解释
数据字段个数不固定:
第一个是课程名称,总共四个课程,computer,math,english,algorithm,
第二个是学生姓名,后面是每次考试的分数,但是每个学生在某门课程中的考试次数不固定。
1、统计每门课程的参考人数和课程平均分
该题目只要求统计参考人数和平均分,所以姓名字段可以直接舍弃,将课程作为键,平均分作为值。
package com.lzr.core;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.*;
public class Demo1 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("group").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD<String, Double> javaPairRDD = sc.textFile("dataset/score.txt")
.mapToPair(line -> {
String[] split = line.split(",");
double sum = 0;
String course = split[0];
for (int i = 2; i < split.length; i++) {
sum += Integer.parseInt(split[i]);
}
double avg = sum / (split.length - 2);
return new Tuple2<>(course, avg);
});
//<课程, 人数>
Map<String, Long> map = javaPairRDD.countByKey();
List<Tuple2<String, Double>> collect = javaPairRDD
.reduceByKey(Double::sum)
.collect();
//[[课程,人数,总分]...]
List<List<String>> list = new ArrayList<>();
map.forEach((k,v) -> {
List<String> x = new ArrayList<>();
x.add(k);
x.add(v +"");
for (Tuple2<String, Double> tuple2 : collect) {
if (tuple2._1.equals(k)) {
x.add(tuple2._2+"");
break;
}
}
list.add(x);
});
sc.parallelize(list)
.map(item -> item.get(0) + "\t" + item.get(1) + "\t" +
Double.parseDouble(item.get(2))/Integer.parseInt(item.get(1)))
.collect()
.forEach(System.out::println);
}
}

2. 统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数。
首先创建StudentBean对象用来存放数据
package com.lzr.core;
import org.apache.hadoop.io.WritableComparable;
import scala.Serializable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class StudentBean implements Serializable {
private String course;
private String name;
private Double avg;
public StudentBean(String course, String name, Double avg) {
this.course = course;
this.name = name;
this.avg = avg;
}
public StudentBean() {
}
@Override
public String toString() {
return course+"\t"+name+"\t"+avg;
}
public String getCourse() {
return course;
}
public void setCourse(String course) {
this.course = course;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getAvg() {
return avg;
}
public void setAvg(Double avg) {
this.avg = avg;
}
}
分区与mapreduce的操作类似,根据键值分区,需要再partitionBy方法中创建一个partitioner对象,重写分区方法。
package com.lzr.core;
import org.apache.spark.Partitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Serializable;
import scala.Tuple2;
import java.util.*;
public class Demo2 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("group").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD<StudentBean, Object> javaPairRDD = sc.textFile("dataset/score.txt")
.mapToPair(line -> {
String[] split = line.split(",");
double sum = 0;
String name = split[1];
String course = split[0];
for (int i = 2; i < split.length; i++) {
sum += Integer.parseInt(split[i]);
}
double avg = sum / (split.length - 2);
return new Tuple2<>(new StudentBean(course, name, avg) , null);
});
JavaRDD<Object> studentBeanObjectJavaPairRDD = javaPairRDD
.sortByKey(new MyComparator(), false, 4) //使用自定义的comparator类
.partitionBy(
new Partitioner() {
@Override
public int numPartitions() {
return 4;
}
@Override
public int getPartition(Object key) {
StudentBean key1 = (StudentBean) key;
switch (key1.getCourse()) {
case "math":
return 0;
case "computer":
return 1;
case "english":
return 2;
default:
return 3;
}
}
}
)
.map(k-> k._1.getCourse() + "\t" + k._1.getName() + "\t" +
String.format(".2%f", k._1.getAvg()))
;
// studentBeanObjectJavaPairRDD.saveAsTextFile(args[1]);
// studentBeanObjectJavaPairRDD.saveAsTextFile("dataset/score2");
studentBeanObjectJavaPairRDD.collect().forEach(System.out::println);
}
}
注意:
1. 经过测试发现RDD需要先进行排序再进行分区操作。
2. 在sortByKey方法中如要自定义排序规则,不能直接新建java.util.Comparator<>(),因为这个类没有实现序列化接口,否则会报类未被序列化的错误
为了避免报错,我们可以新建一个继承java.util.Comparator和Serializable序列化接口的类,重写compare方法。在sortByKey方法中新建这个类。
package com.lzr.core;
import scala.Serializable;
import java.util.Comparator;
public class MyComparator implements Comparator<StudentBean>, Serializable {
@Override
public int compare(StudentBean o1, StudentBean o2) {
return o1.getAvg().compareTo(o2.getAvg());
}
}
结果:

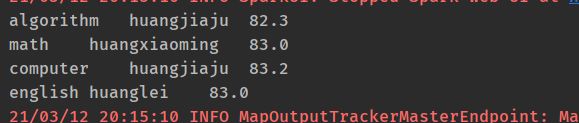
3、求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分。
package com.lzr.core;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Serializable;
import scala.Tuple2;
import java.util.Comparator;
public class Demo3 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("group").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD< StudentBean, String> javaPairRDD = sc.textFile("dataset/score.txt")
.mapToPair(line -> {
String[] split = line.split(",");
double sum = 0;
String name = split[1];
String course = split[0];
for (int i = 2; i < split.length; i++) {
sum += Integer.parseInt(split[i]);
}
double avg = sum / (split.length - 2);
return new Tuple2<>(new StudentBean(course, name, avg), course);
});
javaPairRDD.sortByKey(new MyComparator(), false, 1)
.mapToPair(item -> new Tuple2<>(item._2, item._1))
.groupByKey(1)
.collect()
.forEach(item -> {
Iterable<StudentBean> studentBeans = item._2;
for (StudentBean studentBean : studentBeans) {
System.out.println(studentBean);
break;
}
});
}
}