大数据-Hadoop:搭建Hadoop完全分布式集群(在VMware中的Linux虚拟机)
一、VMware、Linux虚拟机环境准备
1、网络配置
1.1 查看网络IP和网关
1.1.1 查看虚拟网络编辑器
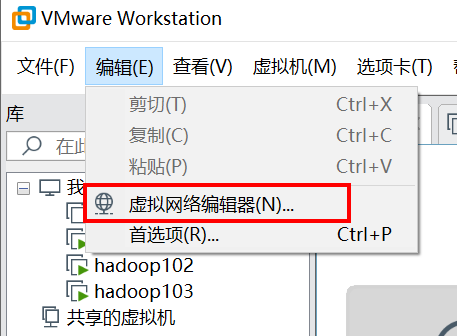
1.1.2 修改ip地址
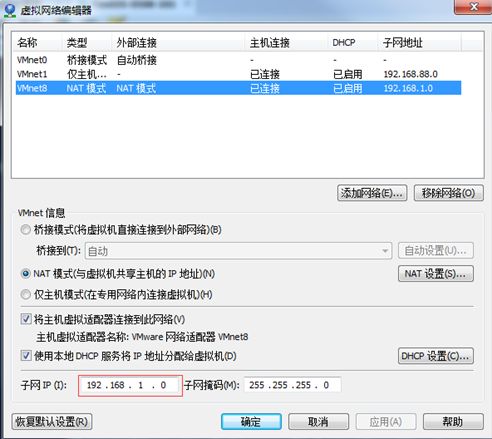
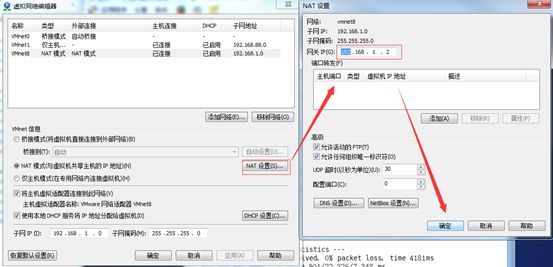
1.1.3 查看网关
1.1.4 查看windows环境的中VMnet8网络配置(控制面板-网络和Internet-更改适配器选项)
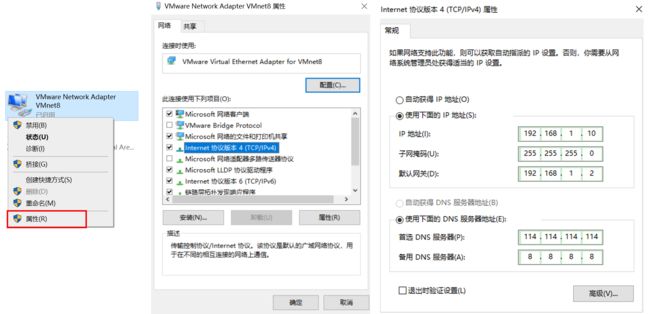
1.2 配置Linux系统的网络IP和网关
1.2.1 查看当前网络IP
[whx@hadoop101 ~]$ ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:7D:B7:BC
inet addr:192.168.1.101 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe7d:b7bc/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:3066 errors:0 dropped:0 overruns:0 frame:0
TX packets:1172 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:240100 (234.4 KiB) TX bytes:133232 (130.1 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:123 errors:0 dropped:0 overruns:0 frame:0
TX packets:123 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:18048 (17.6 KiB) TX bytes:18048 (17.6 KiB)
[whx@hadoop101 ~]$
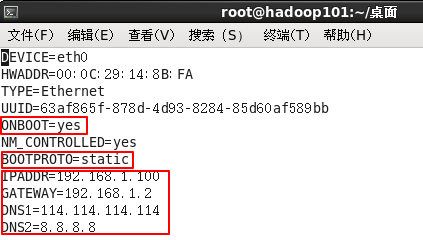
1.2.2 修改当前Linux系统的IP地址为固定地址
[whx@hadoop101 ~]$ vim /etc/sysconfig/network-scripts/ifcfg-eth0
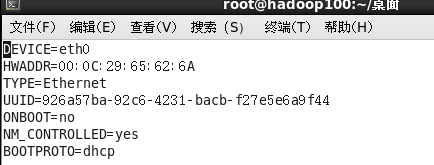
以下标红的项必须修改,有值的按照下面的值修改,没有该项的要增加。
DEVICE=eth0
HWADDR=00:0c:29:7d:b7:bc
TYPE=Ethernet
UUID=d902e817-ae32-4272-bc86-66ebca38f2b6
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.1.101
GATEWAY=192.168.1.2
DNS1=114.114.114.114
DNS2=8.8.8.8
1.2.3 重启network
执行
service network restart
如果报错,reboot,重启虚拟机

2、配置主机名
2.1 查看当前Linux系统的主机名称
[whx@hadoop101 ~]$ hostname
hadoop101
[whx@hadoop101 ~]$
2.2 修改当前Linux系统的主机名称
如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/sysconfig/network文件,修改HOSTNAME。
注意:主机名称不要有“_”下划线
[whx@hadoop101 ~]$ vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop101
NTPSERVERARGS=iburst
3、关闭防火墙
3.1 临时关闭防火墙
[whx@hadoop101 ~]$ sudo service iptables stop
3.1 关闭iptables服务的自动启动:开机启动时关闭防火墙
[whx@hadoop101 ~]$ sudo chkconfig iptables off
4、添加新用户并配置新用户具备root权限
4.1 添加新用户
[root@hadoop101 ~]# useradd whx
[whx@hadoop101 ~]$ ll /home/
total 4
drwx------. 27 whx whx 4096 Jan 26 17:05 whx
[whx@hadoop101 ~]$
4.2 设置用户密码
[root@hadoop101 ~]# passwd whx
4.3 赋予普通用户具有root权限
修改配置文件
[root@hadoop101 ~]# vi /etc/sudoers
修改 /etc/sudoers 文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
whx ALL=(ALL) ALL
或者配置成采用sudo命令时,不需要输入密码
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
whx ALL=(ALL) NOPASSWD:ALL
修改完毕,现在可以用whx帐号登录,然后用命令 sudo ,即可获得root权限进行操作。
二、多台Linux集群环境准备
1、在VMware中克隆3台Linux
1.1 修改各个Linux虚拟机主机名
第一台虚拟机:
[whx@hadoop101 ~]$ vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop101
NTPSERVERARGS=iburst
第二台虚拟机:
[whx@hadoop102 ~]$ vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop102
NTPSERVERARGS=iburst
第三台虚拟机:
[whx@hadoop103 ~]$ vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop103
NTPSERVERARGS=iburst
1.2 修改各个Linux虚拟机网卡名称
第一台虚拟机:
[whx@hadoop101 ~]$ vim /etc/udev/rules.d/70-persistent-net.rules
# This file was automatically generated by the /lib/udev/write_net_rules
# program, run by the persistent-net-generator.rules rules file.
#
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{
address}=="00:0c:29:7d:b7:bc", ATTR{
type}=="1", KERNEL=="eth*", NAME="eth0"
第二台虚拟机:
[whx@hadoop102 ~]$ vim /etc/udev/rules.d/70-persistent-net.rules
# This file was automatically generated by the /lib/udev/write_net_rules
# program, run by the persistent-net-generator.rules rules file.
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{
address}=="00:0c:29:65:d4:7f", ATTR{
type}=="1", KERNEL=="eth*", NAME="eth0"
第二台虚拟机:
[whx@hadoop102 ~]$ vim /etc/udev/rules.d/70-persistent-net.rules
# This file was automatically generated by the /lib/udev/write_net_rules
# program, run by the persistent-net-generator.rules rules file.
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{
address}=="00:0c:29:65:d4:7f", ATTR{
type}=="1", KERNEL=="eth*", NAME="eth0"
第三台虚拟机:
[whx@hadoop103 ~]$ vim /etc/udev/rules.d/70-persistent-net.rules
# This file was automatically generated by the /lib/udev/write_net_rules
# program, run by the persistent-net-generator.rules rules file.
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{
address}=="00:0c:29:29:9b:63", ATTR{
type}=="1", KERNEL=="eth*", NAME="eth0"
1.3 修改各个Linux虚拟机网络配置
根据网卡中的信息修改:HWADDR修改为各个Linux自己的HWADDR值
第一台虚拟机:
[whx@hadoop101 ~]$ vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:0c:29:7d:b7:bc
TYPE=Ethernet
UUID=d902e817-ae32-4272-bc86-66ebca38f2b6
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.1.101
GATEWAY=192.168.1.2
DNS1=114.114.114.114
DNS2=8.8.8.8
第二台虚拟机:
[whx@hadoop102 ~]$ vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:0c:29:65:d4:7f
TYPE=Ethernet
UUID=d902e817-ae32-4272-bc86-66ebca38f2b6
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.1.102
GATEWAY=192.168.1.2
DNS1=114.114.114.114
DNS2=8.8.8.8
第三台虚拟机:
[whx@hadoop103 ~]$ vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:0c:29:29:9b:63
TYPE=Ethernet
UUID=d902e817-ae32-4272-bc86-66ebca38f2b6
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.1.103
GATEWAY=192.168.1.2
DNS1=114.114.114.114
DNS2=8.8.8.8
1.4 添加各个Linux虚拟机的节点映射
[whx@hadoop101 ~]$ sudo vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
2、各个Linux节点间ssh免密通信
如果A机器的a用户,希望使用b用户的身份,免密登录到B机器!实现步骤:
① A机器的a用户,在A机器上生成一对密钥
ssh-keygen -t rsa
② 密钥分为公钥和私钥,a用户需要将公钥拷贝到B机器上b用户的家目录下的authorithxxxx_keys
方法①:使用b用户登录到B机器,编辑authorithxxxx_keys,将公钥的内容进行添加
方法②:在A机器,使用a用户执行以下命令: ssh-copy-id b@B
③A机器的a用户,可以使用 ssh b@B进行登录!
注意:如果在配置时,省略了用户名,那么默认使用当前操作的用户名作为目标机器的用户名!
[a@A] ssh B 等价于 [a@A] ssh a@B
两种ssh的使用方式
①登录到目标主机,再执行命令
[a@A] ssh B
[a@B] jps
属于Login-shell,默认读取/etc/profile文件!
②在A机器,执行命令
[a@A] ssh B jps
属于non-Login-shell,不会读取/etc/profile文件!
只会读取 ~/.bashrc
解决: 在a@B的~/.bashrc中配置 source /etc/profile
注意:当前主机也要配置自己到自己的SSH免密登录!
配置SSH的作用 :
①执行scp,rsync命令时,不需要输入密码,方便
②在执行start-all.sh群起脚本时,需要输入密码
以第二台Linux虚拟机hadoop102为主要操作平台,在第二台Linux虚拟机hadoop102上创建一对密钥,默认保存在/home/whx/.ssh
[whx@hadoop102 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/whx/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/whx/.ssh/id_rsa.
Your public key has been saved in /home/whx/.ssh/id_rsa.pub.
The key fingerprint is:
bc:de:d1:40:6d:6f:a3:63:2d:0d:8b:67:e7:ba:04:6a whx@hadoop101
The key's randomart image is:
+--[ RSA 2048]----+
| |
| . |
| . o |
| . . . . |
| S o . + |
| o = B . |
| E o @ + |
| o . * = |
| . . oo. |
+-----------------+
[whx@hadoop101 ~]$
[whx@hadoop102 ~]$ ll -la
total 164
drwx------. 27 whx whx 4096 Jan 26 15:57 .
drwxr-xr-x. 3 root root 4096 Jan 26 11:03 ..
drwxrwxr-x. 2 whx whx 4096 Jan 26 11:17 .abrt
-rw-------. 1 whx whx 1952 Jan 26 15:11 .bash_history
-rw-r--r--. 1 whx whx 18 May 11 2016 .bash_logout
-rw-r--r--. 1 whx whx 176 May 11 2016 .bash_profile
-rw-r--r--. 1 whx whx 124 May 11 2016 .bashrc
drwxr-xr-x. 3 whx whx 4096 Jan 26 11:52 .cache
drwxr-xr-x. 5 whx whx 4096 Jan 26 11:17 .config
drwx------. 3 whx whx 4096 Jan 26 11:17 .dbus
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Desktop
drwxr-xr-x. 2 whx whx 4096 Jan 26 12:00 Documents
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Downloads
-rw-------. 1 whx whx 16 Jan 26 11:17 .esd_auth
drwx------. 4 whx whx 4096 Jan 26 14:41 .gconf
drwx------. 2 whx whx 4096 Jan 26 14:57 .gconfd
drwxr-xr-x. 6 whx whx 4096 Jan 26 11:52 .gnome2
drwx------. 2 whx whx 4096 Jan 26 11:52 .gnome2_private
drwxrwxr-x. 3 whx whx 4096 Jan 26 11:17 .gnote
drwx------. 2 whx whx 4096 Jan 26 14:41 .gnupg
-rw-rw-r--. 1 whx whx 127 Jan 26 14:41 .gtk-bookmarks
drwx------. 2 whx whx 4096 Jan 26 11:17 .gvfs
-rw-------. 1 whx whx 930 Jan 26 14:41 .ICEauthority
-rw-r--r--. 1 whx whx 631 Jan 26 14:41 .imsettings.log
drwxr-xr-x. 3 whx whx 4096 Jan 26 11:17 .local
drwxr-xr-x. 5 whx whx 4096 Jan 26 11:52 .mozilla
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Music
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 .nautilus
drwxrwxr-x. 2 whx whx 4096 Jan 26 11:55 .oracle_jre_usage
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Pictures
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Public
drwx------. 2 whx whx 4096 Jan 26 11:17 .pulse
-rw-------. 1 whx whx 256 Jan 26 11:17 .pulse-cookie
drwx------. 2 whx whx 4096 Jan 26 16:24 .ssh
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Templates
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Videos
-rw-------. 1 whx whx 990 Jan 26 14:59 .viminfo
-rw-------. 1 whx whx 110 Jan 26 15:57 .Xauthority
-rw-------. 1 whx whx 3096 Jan 26 14:57 .xsession-errors
-rw-------. 1 whx whx 4407 Jan 26 12:27 .xsession-errors.old
[whx@hadoop102 ~]$ cd .ssh
[whx@hadoop102 .ssh]$ ls
id_rsa id_rsa.pub known_hosts
将生成的id_rsa.pub分别发送到hadoop101 、hadoop102 、hadoop103 三台Linux虚拟机上
[whx@hadoop102 .ssh]$ ssh-copy-id whx@hadoop101
whx@hadoop101's password:
Now try logging into the machine, with "ssh 'whx@hadoop101'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[whx@hadoop102 ~]$ ssh hadoop101
Last login: Tue Jan 26 16:54:29 2021 from 192.168.1.10
[whx@hadoop101 ~]$ exit
logout
Connection to hadoop101 closed.
[whx@hadoop102 ~]$
[whx@hadoop102 .ssh]$ ssh-copy-id whx@hadoop102
whx@hadoop102's password:
Now try logging into the machine, with "ssh 'whx@hadoop102'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[whx@hadoop102 ~]$ ssh hadoop102
Last login: Tue Jan 26 17:58:27 2021 from 192.168.1.10
[whx@hadoop102 ~]$ exit
logout
Connection to hadoop102 closed.
[whx@hadoop102 ~]$
[whx@hadoop102 .ssh]$ ssh-copy-id whx@hadoop103
whx@hadoop103's password:
Now try logging into the machine, with "ssh 'whx@hadoop103'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[whx@hadoop102 ~]$ ssh hadoop103
Last login: Tue Jan 26 16:29:38 2021 from hadoop101
[whx@hadoop102 ~]$ exit
logout
Connection to hadoop103 closed.
[whx@hadoop102 ~]$
3、配置非登录状态的环境变量
3.1 Login Shell登录脚本的执行顺序:【注:仅适用于 bash shell】
Login Shell:是指登录时,需要提供用户名密码的shell,如:su – user1 , 图形登录, ctrl+alt+F2-6进入的登录界面。这种Login shell 执行脚本的顺序:
- /etc/profile 【全局profile文件;它定义了LoginUser的 PATH, USER, LOGNAME(登录使用者帐号)】
- /etc/profile.d/目录下的脚本
- ~/.bash_profile 【搜索命令的路径 ——————- 登录级别 环境变量配置文件 】
- ~/.bashrc 【存储用户设定的别名和函数 ———- shell级别 环境变量配置文件】
- /etc/bashrc 【全局bashrc文件; 它主要定义一些 Function 和 Alias;更改/etc/bashrc会影响到所有用户,由root用户管理。】
- 例如:在hadoop101虚拟机上通过ssh hadoop102登陆hadoop102虚拟机,会自动读取/etc/profile环境变量文件中定义的所有的变量
- 因为java的/opt/module/jdk1.8.0_121/bin/jps命令已经配置到了/etc/profile环境变量中,
- 所以可以直接执行jps命令,
[whx@hadoop101 ~]$ ssh hadoop102
Last login: Tue Jan 26 20:53:59 2021 from hadoop101
[whx@hadoop102 ~]$ jps
3626 Jps
[whx@hadoop102 ~]$
3.2 Non-Login shell登录脚本的执行顺序:【注:仅适用于 bash shell】
Non-Login shell:登录终端后,使用ssh 登录 其他机器! 非登录shell指的是,不需要输入用户名密码的shell,如图形下 右键terminal,或ctrl+shift+T打开的shell。这种Non-Login shell 执行登录脚本的顺序:
- ~/.bashrc
- /etc/bashrc
- /etc/profile.d/目录下的脚本
- 例如:在hadoop102虚拟机上通过ssh hadoop101 jps 直接执行hadoop101虚拟机上的jps命令,
- 不会自动读取hadoop101虚拟机上的/etc/profile环境变量文件
- 而java的/opt/module/jdk1.8.0_121/bin/jps命令是配置到在/etc/profile环境变量中的
- 所以会失败
[whx@hadoop102 ~]$ ssh hadoop101 jps
bash: jps: command not found
[whx@hadoop102 ~]$
3.3 让Non-Login shell登录脚本也执行/etc/profile环境变量的方法
- 在虚拟机上的~/.bashrc文件中引入/etc/profile环境变量即可
- 如果在使用命令时,我们需要使用/etc/profile定义的一些变量,需要在目标机器的对应的用户的家目录 /home/.bashrc中添加以下代码
source /etc/profile - 如果不在 /home/.bashrc文件中添加以上代码,在执行start-all.sh | stop-all.sh 这些Hadoop群起脚本时一定会报错!
[whx@hadoop101 ~]$ ls
Desktop Documents Downloads Music Pictures Public Templates Videos
[whx@hadoop101 ~]$ ll -la
total 164
drwx------. 27 whx whx 4096 Jan 26 17:58 .
drwxr-xr-x. 3 root root 4096 Jan 26 11:03 ..
drwxrwxr-x. 2 whx whx 4096 Jan 26 11:17 .abrt
-rw-------. 1 whx whx 2928 Jan 26 20:54 .bash_history
-rw-r--r--. 1 whx whx 18 May 11 2016 .bash_logout
-rw-r--r--. 1 whx whx 176 May 11 2016 .bash_profile
-rw-r--r--. 1 whx whx 124 May 11 2016 .bashrc
drwxr-xr-x. 3 whx whx 4096 Jan 26 11:52 .cache
drwxr-xr-x. 5 whx whx 4096 Jan 26 11:17 .config
drwx------. 3 whx whx 4096 Jan 26 11:17 .dbus
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Desktop
drwxr-xr-x. 2 whx whx 4096 Jan 26 12:00 Documents
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Downloads
-rw-------. 1 whx whx 16 Jan 26 11:17 .esd_auth
drwx------. 4 whx whx 4096 Jan 26 14:42 .gconf
drwx------. 2 whx whx 4096 Jan 26 14:57 .gconfd
drwxr-xr-x. 6 whx whx 4096 Jan 26 11:52 .gnome2
drwx------. 2 whx whx 4096 Jan 26 11:52 .gnome2_private
drwxrwxr-x. 3 whx whx 4096 Jan 26 11:17 .gnote
drwx------. 2 whx whx 4096 Jan 26 14:42 .gnupg
-rw-rw-r--. 1 whx whx 127 Jan 26 14:42 .gtk-bookmarks
drwx------. 2 whx whx 4096 Jan 26 11:17 .gvfs
-rw-------. 1 whx whx 930 Jan 26 14:42 .ICEauthority
-rw-r--r--. 1 whx whx 631 Jan 26 14:42 .imsettings.log
drwxr-xr-x. 3 whx whx 4096 Jan 26 11:17 .local
drwxr-xr-x. 5 whx whx 4096 Jan 26 11:52 .mozilla
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Music
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 .nautilus
drwxrwxr-x. 2 whx whx 4096 Jan 26 11:55 .oracle_jre_usage
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Pictures
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Public
drwx------. 2 whx whx 4096 Jan 26 11:17 .pulse
-rw-------. 1 whx whx 256 Jan 26 11:17 .pulse-cookie
drwx------. 2 whx whx 4096 Jan 26 16:28 .ssh
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Templates
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:17 Videos
-rw-------. 1 whx whx 1193 Jan 26 17:58 .viminfo
-rw-------. 1 whx whx 110 Jan 26 17:58 .Xauthority
-rw-------. 1 whx whx 2722 Jan 26 14:57 .xsession-errors
-rw-------. 1 whx whx 4407 Jan 26 12:27 .xsession-errors.old
[whx@hadoop101 ~]$
[whx@hadoop101 ~]$ vim .bashrc
在文件尾部添加 “source /etc/profile” :
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific aliases and functions
source /etc/profile
在hadoop102虚拟机上通过ssh hadoop101 jps 再次直接执行hadoop101虚拟机上的jps命令,成功。
[whx@hadoop102 ~]$ ssh hadoop102 jps
3655 Jps
[whx@hadoop102 ~]$
4、编写 “集群分发文件” 脚本:xsync.sh
-
scp(安全拷贝):全量复制
scp -r 源文件用户名A@主机名1:path1 目标文件用户名B@主机名2:path2-r: 递归,复制目录 如果从本机执行读取或写入,用户名B@主机名2:可以省略! 在主机1上,使用A用户读取path1的文件,再使用用户B登录到主机2,在主机2的path2路径执行写入! 要求: 用户名A@主机名1 对path1有读权限 用户名B@主机名2 对path2有写权限 -
rsync (远程同步):可以只同步变化的文件(对比文件的修改时间)!增量同步!
rsync -rvlt path1 目标文件用户名B@主机名2:path2-r: 递归,复制目录 -v: 显示复制的过程 -l: 同步软连接 -t: 基于文件的修改时间进行对比,只同步修改时间不同的文件 只能将本机的文件同步到其他机器! 注意: rsync -rvlt path1 目标文件用户名B@主机名2:path2 path1是个目录,目录以/结尾,只会同步目录中的内容,不会同步目录本身! path1是个目录,目录不以/结尾,同步目录中的内容,也会同步目录本身! -
编写同步脚本xsync:将当前机器的文件,同步到集群所有机器的相同路径下!
hadoop102:/A/a , 执行脚本后,将此文件同步到集群中所有机器的 /A/a 用户在使用xsync时,只需要传入要同步的文件即可 xysnc a 不管a是一个相对路径还是绝对路径,都需要将a转换为绝对路径! 文件的绝对路径: 父路径: dirpath=$(cd `dirname /home/atguigu/hi`; pwd -P) 文件名: filename=`basename hi` 核心命令: for(()) do rsync -rvlt path1 done
在Linux系统中的vim编辑器中编写,如果用window系统编写后直接上传,会出问题。doc下的文本内容格式和unix下的格式有所不同,比如dos文件传输到unix系统时,会在每行的结尾多一个^M结束符。
在第二台Linux虚拟机hadoop102的/home/whx目录中创建xsync.sh脚本
#!/bin/bash
#校验参数是否合法
#"$#"功能:获取所有输入参数个数,用于循环
if(($#==0))
then
echo 请输入要分发的文件!
exit;
fi
#获取分发文件的绝对路径
dirpath=$(cd `dirname $1`; pwd -P)
filename=`basename $1`
echo 要分发的文件的路径是:$dirpath/$filename
#循环执行rsync分发文件到集群的每一台机器
# for((i=101;i<=103;i++))
for i in 101 103
do
echo -------------------------hadoop$i-------------------------
rsync -rvlt $dirpath/$filename whx@hadoop$i:$dirpath
done
在 /home/whx 目录中创建一个bin文件夹,将xsync.sh脚本移动到/home/whx/bin文件夹中
[whx@hadoop102 ~]$ mkdir bin
[whx@hadoop102 ~]$ ls
bin Desktop Documents Downloads Music Pictures Public Templates Videos xsync.sh
[whx@hadoop102 ~]$ mv xsync.sh bin/
[whx@hadoop102 ~]$ ls
bin Desktop Documents Downloads Music Pictures Public Templates Videos
[whx@hadoop102 ~]$ cd bin
[whx@hadoop102 bin]$ ls
xsync.sh
[whx@hadoop102 bin]$ echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/opt/module/jdk1.8.0_121/bin:/opt/module/hadoop-2.7.2/bin:/opt/module/hadoop-2.7.2/sbin:/home/whx/bin
[whx@hadoop101 bin]$
/home/whx/bin路径是默认在环境变量中的,不需要再次添加
修改xsync.sh文件夹的权限
[whx@hadoop102 bin]$ chmod u+x xsync.sh
[whx@hadoop102 bin]$ ll
total 4
-rwxrw-r--. 1 whx whx 553 Jan 26 19:45 xsync.sh
[whx@hadoop102 bin]$
此时xsync.sh脚本就可以作为全局变量来使用了
5、编写 “集群统一执行命令” 脚本:xcall.sh
在/home/whx/bin目录下创建xcall.sh文件
#!/bin/bash
#在集群的所有机器上批量执行同一条命令
if(($#==0))
then
echo 请输入您要操作的命令!
exit
fi
echo 要执行的命令是$*
#循环执行此命令
for((i=101;i<=103;i++))
do
echo ----------------------------hadoop$i----------------------------------
ssh hadoop$i $*
done
修改xcall.sh文件夹的权限
[whx@hadoop102 bin]$ chmod u+x xcall.sh
[whx@hadoop102 bin]$ ll
total 8
-rwxrw-r--. 1 whx whx 336 Jan 26 21:38 xcall.sh
-rwxrw-r--. 1 whx whx 553 Jan 26 19:45 xsync.sh
[whx@hadoop102 bin]$
此时xcall.sh脚本就可以作为全局变量来使用了
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
4275 NameNode
4798 Jps
----------------------------hadoop102----------------------------------
3831 Jps
----------------------------hadoop103----------------------------------
3535 Jps
[whx@hadoop102 ~]$
三、在第二台Linux虚拟机hadoop102(作为主节点)中搭建Hadoop运行环境
1、在/opt目录下创建文件夹
1.1 在/opt目录下创建module、soft文件夹
[whx@hadoop102 opt]$ sudo mkdir module
[whx@hadoop102 opt]$ sudo mkdir soft
1.2 chown修改module、soft文件夹的所有者
[whx@hadoop102 opt]$ sudo chown whx:whx /opt/module /opt/soft
[whx@hadoop102 opt]$ ll
total 12
drwxr-xr-x. 4 whx whx 4096 Jan 26 11:52 module
drwxr-xr-x. 2 root root 4096 Mar 26 2015 rh
drwxr-xr-x. 2 whx whx 4096 Jan 26 11:51 soft
[whx@hadoop102 opt]$
2、安装JDK
2.1 卸载现有JDK
查询是否安装Java软件:
[whx@hadoop102 opt]$ rpm -qa | grep java
查看JDK安装路径:
[atguigu@hadoop102 ~]$ which java
如果安装的版本低于1.7,卸载该JDK:
[atguigu@hadoop102 opt]$ sudo rpm -e java软件包安装路径
2.2 将JDK用ftp或其他方法将JDK压缩包导入到opt目录下面的soft文件夹下面
[whx@hadoop102 soft]$ ll
total 371980
-rwxrwxr-x. 1 whx whx 197657687 Jan 26 11:51 hadoop-2.7.2.tar.gz
-rwxrwxrwx. 1 whx whx 183246769 Oct 31 02:34 jdk-8u121-linux-x64.tar.gz
[whx@hadoop102 soft]$
2.3 解压JDK到/opt/module目录下
[whx@hadoop102 soft]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
[whx@hadoop102 module]$ ll
total 8
drwxr-xr-x. 11 whx whx 4096 Jan 26 12:07 hadoop-2.7.2
drwxr-xr-x. 8 whx whx 4096 Dec 13 2016 jdk1.8.0_121
[whx@hadoop102 module]$
2.4 配置JDK环境变量
先获取JDK路径
[whx@hadoop102 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
打开/etc/profile环境变量文件
[whx@hadoop102 soft]$ sudo vi /etc/profile
在环境变量profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
保存后退出
:wq
让修改后的环境变量文件生效
[whx@hadoop102 jdk1.8.0_144]$ source /etc/profile
2.5 测试JDK是否安装成功
[whx@hadoop102 jdk1.8.0_144]# java -version
java version "1.8.0_144"
注意:重启(如果java -version可以用就不用重启)
[whx@hadoop102 jdk1.8.0_144]$ sync
[whx@hadoop102 jdk1.8.0_144]$ sudo reboot
3、安装Hadoop
3.1 用ftp或其他方法将Hadoop压缩包导入到opt目录下面的soft文件夹下面
[whx@hadoop102 soft]$ ll
total 371980
-rwxrwxr-x. 1 whx whx 197657687 Jan 26 11:51 hadoop-2.7.2.tar.gz
-rwxrwxrwx. 1 whx whx 183246769 Oct 31 02:34 jdk-8u121-linux-x64.tar.gz
[whx@hadoop102 soft]$
3.2 解压Hadoop安装文件到/opt/module下面
[whx@hadoop102 soft]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
[whx@hadoop102 module]$ ll
total 8
drwxr-xr-x. 11 whx whx 4096 Jan 26 12:07 hadoop-2.7.2
drwxr-xr-x. 8 whx whx 4096 Dec 13 2016 jdk1.8.0_121
[whx@hadoop102 module]$
3.3 将Hadoop添加到环境变量
获取Hadoop安装路径
[whx@hadoop101 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
打开/etc/profile环境变量文件
[whx@hadoop102 hadoop-2.7.2]$ sudo vi /etc/profile
在profile文件末尾添加Hadoop路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存后退出
:wq
让修改后的环境变量文件生效
[whx@hadoop102 jdk1.8.0_144]$ source /etc/profile
3.4 Hadoop目录结构
[whx@hadoop102 hadoop-2.7.2]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 sbin
drwxr-xr-x. 4 atguigu atguigu 4096 5月 22 2017 share
Hadoop重要目录:
- bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- sbin目录:存放启动或停止Hadoop相关服务的脚本
- share目录:存放Hadoop的依赖jar包、文档、和官方案例
4、配置Hadoop自定义配置文件来覆盖默认配置文件
在Hadoop自定义配置文件中进行进程规划,进程规划的原则:
- 核心进程尽量分散(比如NameNode、ResourceManager不要在同一台节点服务器上)
- 同质进程尽量分散(比如NameNode、SecondaryNameNode不要在同一台节点服务器上)

4.1 core-site.xml
$HADOOP_HOME/etc/hadoop/core-site.xml(/opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml)
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<!--告知NameNode在哪个机器,NameNode使用哪个端口号接收客户端和DataNode的RPC请求,端口号可以任意,只要不被占用-->
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
4.2 hdfs-site.xml
$HADOOP_HOME/etc/hadoop/hdfs-site.xml(/opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml)
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--副本数量:默认为3(不配置此property时,默认为3)-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
<!--
默认情况下,SecondaryNameNode每隔一小时执行一次。
自定义设置:一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
-->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
<!--NameNode多目录配置:NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。实际应用中要把目录要在不同的磁盘上-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
</configuration>
4.3 yarn-site.xml
$HADOOP_HOME/etc/hadoop/yarn-site.xml(/opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml)
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
</configuration>
4.4 mapred-site.xml
$HADOOP_HOME/etc/hadoop/mapred-site.xml(/opt/module/hadoop-2.7.2/etc/hadoop/mapred-site.xml)
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
四、通过“集群分发文件” 脚本xsync.sh进行文件分发
1、在其他虚拟机上创建/opt/module、/opt/soft 文件夹并修改所有者
[whx@hadoop101 opt]$ sudo mkdir module
[whx@hadoop101 opt]$ sudo mkdir soft
[whx@hadoop101 opt]$ sudo chown whx:whx /opt/module /opt/soft
[whx@hadoop103 opt]$ sudo mkdir module
[whx@hadoop103 opt]$ sudo mkdir soft
[whx@hadoop103 opt]$ sudo chown whx:whx /opt/module /opt/soft
2、在hadoop102虚拟机上给其他虚拟机分发jdk、hadoop程序
[whx@hadoop102 ~]$ ls
Desktop Documents Downloads Music Pictures Public Templates Videos xsync.sh
[whx@hadoop102 ~]$ bash xsync.sh /opt/module/jdk1.8.0_121/
[whx@hadoop102 ~]$ bash xsync.sh /opt/module/hadoop-2.7.2/
3、配置其他虚拟机的jdk、Hadoop环境变量
在环境变量/etc/profile文件末尾添加jdk、Hadoop路径
JAVA_HOME=/opt/module/jdk1.8.0_121
HADOOP_HOME=/opt/module/hadoop-2.7.2
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME HADOOP_HOME PATH
让修改后的环境变量文件生效
[whx@hadoop101 ~]$ source /etc/profile
[whx@hadoop103 ~]$ source /etc/profile
五、分模块独立启动Hadoop
1、启动HDFS数据存储模块(Hadoop Distributed File System)
1.1 格式化Namenode(在namenode所在节点:hadoop101节点)
如果集群是第一次启动,需要格式化NameNode;只需要Hadoop初始启动时格式化一次
- 需要在Namenode所配置的节点(Linux服务器)进行格式化,
- 不要使用xcall.sh在所有节点上批量执行格式化命令,只在Namenode所配置的节点(Linux服务器)进行格式化。
[whx@hadoop101 hadoop-2.7.2]$ hadoop namenode -format
格式化NameNode的目的:
- 开启Hadoop集群后,所有节点会生成/opt/module/hadoop-2.7.2/data/temp目录
- 在/opt/module/hadoop-2.7.2/data/temp目录中生成一些文件(比如:fsimage_0000000000000000000)
[whx@hadoop101 hadoop-2.7.2]$ tree data
data
└── tmp
├── dfs
│ ├── data
│ │ ├── current
│ │ │ ├── BP-475823910-192.168.1.101-1611761928496
│ │ │ │ ├── current
│ │ │ │ │ ├── dfsUsed
│ │ │ │ │ ├── finalized
│ │ │ │ │ ├── rbw
│ │ │ │ │ └── VERSION
│ │ │ │ ├── scanner.cursor
│ │ │ │ └── tmp
│ │ │ └── VERSION
│ │ └── in_use.lock
│ ├── name1
│ │ ├── current
│ │ │ ├── edits_0000000000000000001-0000000000000000002
│ │ │ ├── edits_0000000000000000003-0000000000000000003
│ │ │ ├── edits_0000000000000000004-0000000000000000005
│ │ │ ├── edits_inprogress_0000000000000000006
│ │ │ ├── fsimage_0000000000000000002
│ │ │ ├── fsimage_0000000000000000002.md5
│ │ │ ├── fsimage_0000000000000000005
│ │ │ ├── fsimage_0000000000000000005.md5
│ │ │ ├── seen_txid
│ │ │ └── VERSION
│ │ └── in_use.lock
│ └── name2
│ ├── current
│ │ ├── edits_0000000000000000001-0000000000000000002
│ │ ├── edits_0000000000000000003-0000000000000000003
│ │ ├── edits_0000000000000000004-0000000000000000005
│ │ ├── edits_inprogress_0000000000000000006
│ │ ├── fsimage_0000000000000000002
│ │ ├── fsimage_0000000000000000002.md5
│ │ ├── fsimage_0000000000000000005
│ │ ├── fsimage_0000000000000000005.md5
│ │ ├── seen_txid
│ │ └── VERSION
│ └── in_use.lock
└── nm-local-dir
├── filecache
├── nmPrivate
└── usercache
17 directories, 27 files
[whx@hadoop101 hadoop-2.7.2]$
其中的name1与name2为元数据保存位置,两者内容相同。实际项目中name1与name2的位置应该放在不同的磁盘上,防止磁盘损坏而无法完全恢复元数据(Secondarynamenode虽然可以恢复,但不一定能全部恢复,取决于Secondarynamenode保存namenode的元数据后namenode是否又继续新添加数据与否)。
1.2 在配置的不同节点“分别”启动namenode、datanode、secondarynamenode
1.2.1 启动namenode(在namenode所在节点:hadoop101节点)
hadoop的自定义配置文件配置core-site.xml指定Hadoop的namenode(名称节点主机)为hadoop101节点
[whx@hadoop101 ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-namenode-hadoop101.out
[whx@hadoop101 ~]$ jps
5190 Jps
5115 NameNode
[whx@hadoop101 ~]$
1.2.2 启动datanode(在所有节点)
在xcall.sh脚本所在的节点(hadoop102 )使用xcall.sh统一启动所有节点的datanode
[whx@hadoop102 ~]$ xcall.sh hadoop-daemon.sh start datanode
要执行的命令是hadoop-daemon.sh start datanode
----------------------------hadoop101----------------------------------
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop101.out
----------------------------hadoop102----------------------------------
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop102.out
----------------------------hadoop103----------------------------------
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop103.out
[whx@hadoop102 ~]$
测试:
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
5041 Jps
4275 NameNode
4951 DataNode
----------------------------hadoop102----------------------------------
3946 DataNode
4030 Jps
----------------------------hadoop103----------------------------------
3650 DataNode
3734 Jps
[whx@hadoop102 ~]$
1.2.3 启动secondarynamenode(在secondarynamenode所在节点:hadoop103节点)
hadoop的自定义配置文件配置hdfs-site.xml指定Hadoop的secondarynamenode(辅助名称节点主机)为hadoop103节点
[whx@hadoop103 ~]$ hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-secondarynamenode-hadoop103.out
[whx@hadoop103 ~]$ jps
3650 DataNode
3834 Jps
3788 SecondaryNameNode
[whx@hadoop103 ~]$
测试:
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
5238 Jps
4951 DataNode
5115 NameNode
----------------------------hadoop102----------------------------------
4096 Jps
3946 DataNode
----------------------------hadoop103----------------------------------
3650 DataNode
3883 Jps
3788 SecondaryNameNode
[whx@hadoop102 ~]$
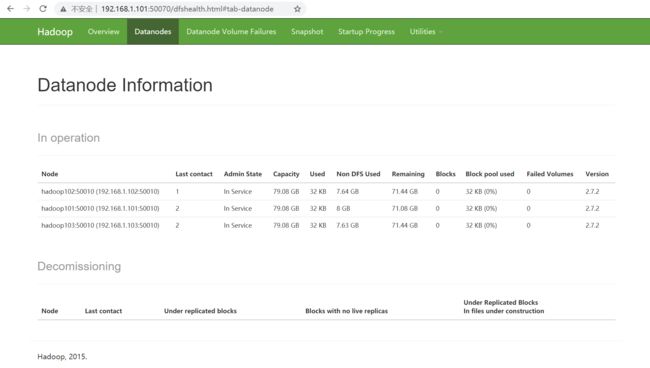
在Web界面 http://192.168.1.101:50070/ 查看HDFS的启动状态:
1.3 测试HDFS数据存储模块
为了测试方便,可以将HDFS数据存储系统的根目录权限设置为777,任何用户都可以进行读写操作
[whx@hadoop101 ~]$ hadoop fs -chmod -R 777 /
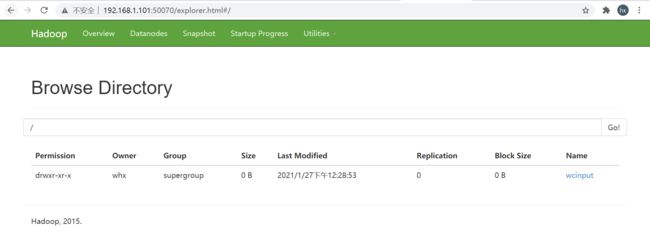
1.3.1 在HDFS中创建目录(任意节点都可以)
[whx@hadoop102 ~]$ hadoop fs -mkdir /wcinput
[whx@hadoop102 ~]$
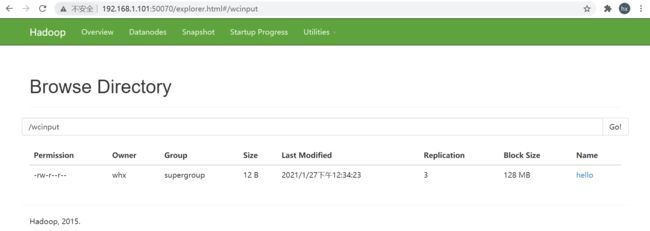
1.3.2 向HDFS上传文件(任意节点都可以)
[whx@hadoop101 ~]$ hadoop fs -put /home/whx/Documents/hello /wcinput
[whx@hadoop101 ~]$
2、启动YARN资源调度模块
2.1 启动 resourcemanager (在resourcemanager所在hadoop102节点)
hadoop的自定义配置文件配置 yarn-site.xml 指定Hadoop的resourcemanager为hadoop101节点,所以要在hadoop101节点启动YARN
[whx@hadoop102 ~]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-resourcemanager-hadoop102.out
[whx@hadoop102 ~]$
2.2 启动 nodemanager (在所有节点)
在xcall.sh脚本所在的节点(hadoop102 )使用xcall.sh统一启动所有节点的nodemanager
[whx@hadoop102 ~]$ xcall.sh yarn-daemon.sh start nodemanager
要执行的命令是yarn-daemon.sh start nodemanager
----------------------------hadoop101----------------------------------
starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop101.out
----------------------------hadoop102----------------------------------
starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop102.out
----------------------------hadoop103----------------------------------
starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop103.out
[whx@hadoop102 ~]$
在xcall.sh脚本所在的节点(hadoop101 )使用xcall.sh jps检测各个节点的启动情况:
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
3009 NameNode
3138 ResourceManager
3314 NodeManager
3144 DataNode
3437 Jps
----------------------------hadoop102----------------------------------
3000 DataNode
3406 NodeManager
3525 Jps
----------------------------hadoop103----------------------------------
3108 SecondaryNameNode
3009 DataNode
3242 NodeManager
3363 Jps
[whx@hadoop102 ~]$
在Web界面 http://192.168.1.102:8088/ 查看YARN模块的启动状态:

2.3 测试YARN资源调度模块
[whx@hadoop101 mapreduce]$ cd /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/
[whx@hadoop101 mapreduce]$ ls
hadoop-mapreduce-client-app-2.7.2.jar hadoop-mapreduce-client-core-2.7.2.jar hadoop-mapreduce-client-hs-plugins-2.7.2.jar hadoop-mapreduce-client-jobclient-2.7.2-tests.jar hadoop-mapreduce-examples-2.7.2.jar lib-examples
hadoop-mapreduce-client-common-2.7.2.jar hadoop-mapreduce-client-hs-2.7.2.jar hadoop-mapreduce-client-jobclient-2.7.2.jar hadoop-mapreduce-client-shuffle-2.7.2.jar lib sources
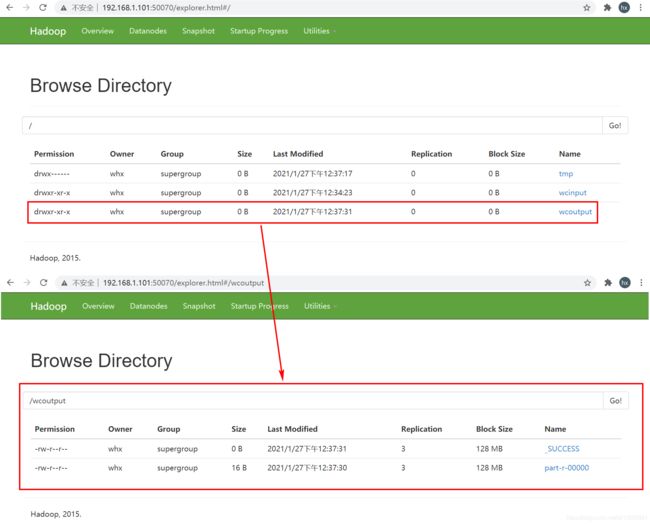
[whx@hadoop101 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /wcoutput
21/01/27 12:37:16 INFO client.RMProxy: Connecting to ResourceManager at hadoop102/192.168.1.102:8032
21/01/27 12:37:17 INFO input.FileInputFormat: Total input paths to process : 1
21/01/27 12:37:17 INFO mapreduce.JobSubmitter: number of splits:1
21/01/27 12:37:17 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1611721007039_0001
21/01/27 12:37:18 INFO impl.YarnClientImpl: Submitted application application_1611721007039_0001
21/01/27 12:37:18 INFO mapreduce.Job: The url to track the job: http://hadoop102:8088/proxy/application_1611721007039_0001/
21/01/27 12:37:18 INFO mapreduce.Job: Running job: job_1611721007039_0001
21/01/27 12:37:24 INFO mapreduce.Job: Job job_1611721007039_0001 running in uber mode : false
21/01/27 12:37:24 INFO mapreduce.Job: map 0% reduce 0%
21/01/27 12:37:28 INFO mapreduce.Job: map 100% reduce 0%
21/01/27 12:37:32 INFO mapreduce.Job: map 100% reduce 100%
21/01/27 12:37:32 INFO mapreduce.Job: Job job_1611721007039_0001 completed successfully
21/01/27 12:37:32 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=30
FILE: Number of bytes written=234931
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=112
HDFS: Number of bytes written=16
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2073
Total time spent by all reduces in occupied slots (ms)=1545
Total time spent by all map tasks (ms)=2073
Total time spent by all reduce tasks (ms)=1545
Total vcore-milliseconds taken by all map tasks=2073
Total vcore-milliseconds taken by all reduce tasks=1545
Total megabyte-milliseconds taken by all map tasks=2122752
Total megabyte-milliseconds taken by all reduce tasks=1582080
Map-Reduce Framework
Map input records=1
Map output records=2
Map output bytes=20
Map output materialized bytes=30
Input split bytes=100
Combine input records=2
Combine output records=2
Reduce input groups=2
Reduce shuffle bytes=30
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=97
CPU time spent (ms)=1110
Physical memory (bytes) snapshot=435863552
Virtual memory (bytes) snapshot=4188192768
Total committed heap usage (bytes)=320864256
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=12
File Output Format Counters
Bytes Written=16
[whx@hadoop101 mapreduce]$
运行进程监控:

运行结果:
六、群起Hadoop集群
- 群起脚本的原理是获取集群中所有的节点的主机名,默认读取当前机器 HADOOP_HOME/etc/hadoop/slaves,获取集群中所有的节点的主机名
- 在执行群起时,默认读取当前节点机器 $HADOOP_HOME/etc/hadoop/slaves文件中,当前集群配置的主机名
- 一个集群中,每台机器的时间必须保证是同步的!
- 主要借助linux的ntp服务执行和远程时间服务器的时间同步!
- 保证当前机器的ntp服务是开机自启动!chkconfig --list ntpd
- 使用 “ntpdate -u 时间服务器的地址” 命令同步时间,或写一个定时脚本每隔一段时间同步一次来保证整个集群的时间是同步的。
- 循环执行 ssh 主机名 hadoop-daemon.sh start xxx
- 前提是确保当前节点机器到其他节点,已经配置了ssh免密登录
- 前提是确保集群中所有节点的当前用户的 /home/.bashrc中,已经配置source /etc/profile
- 注意: start-all.sh时,其实分别调用了start-dfs.sh和start-yarn.sh
- start-dfs.sh可以在集群的任意一台机器使用!可以启动HDFS中的所有进程!
- start-yarn.sh在集群的非resourcemanager所在的机器使用,不会启动resourcemanager!
- 建议:
- 只需要配置resourcemanager所在机器到其他机器的SSH免密登录!
- 都在resourcemanager所在的机器执行群起和群停脚本!
- xsync.sh群发脚本和xcall.sh批量命名脚本只放在resourcemanager所在的机器即可!
1、 配置slaves文件(在resourcemanager所在主节点hadoop102配置)
[whx@hadoop102 hadoop-2.7.2]$ cd /opt/module/hadoop-2.7.2/etc/hadoop/
[whx@hadoop102 hadoop]$ ll
total 152
-rw-r--r--. 1 whx whx 4436 May 22 2017 capacity-scheduler.xml
-rw-r--r--. 1 whx whx 1335 May 22 2017 configuration.xsl
-rw-r--r--. 1 whx whx 318 May 22 2017 container-executor.cfg
-rw-r--r--. 1 whx whx 1179 Jan 26 20:20 core-site.xml
-rw-r--r--. 1 whx whx 3670 May 22 2017 hadoop-env.cmd
-rw-r--r--. 1 whx whx 4224 May 22 2017 hadoop-env.sh
-rw-r--r--. 1 whx whx 2598 May 22 2017 hadoop-metrics2.properties
-rw-r--r--. 1 whx whx 2490 May 22 2017 hadoop-metrics.properties
-rw-r--r--. 1 whx whx 9683 May 22 2017 hadoop-policy.xml
-rw-r--r--. 1 whx whx 1085 Jan 26 20:18 hdfs-site.xml
-rw-r--r--. 1 whx whx 1449 May 22 2017 httpfs-env.sh
-rw-r--r--. 1 whx whx 1657 May 22 2017 httpfs-log4j.properties
-rw-r--r--. 1 whx whx 21 May 22 2017 httpfs-signature.secret
-rw-r--r--. 1 whx whx 620 May 22 2017 httpfs-site.xml
-rw-r--r--. 1 whx whx 3518 May 22 2017 kms-acls.xml
-rw-r--r--. 1 whx whx 1527 May 22 2017 kms-env.sh
-rw-r--r--. 1 whx whx 1631 May 22 2017 kms-log4j.properties
-rw-r--r--. 1 whx whx 5511 May 22 2017 kms-site.xml
-rw-r--r--. 1 whx whx 11237 May 22 2017 log4j.properties
-rw-r--r--. 1 whx whx 951 May 22 2017 mapred-env.cmd
-rw-r--r--. 1 whx whx 1383 May 22 2017 mapred-env.sh
-rw-r--r--. 1 whx whx 4113 May 22 2017 mapred-queues.xml.template
-rw-r--r--. 1 whx whx 842 Jan 26 12:49 mapred-site.xml
-rw-r--r--. 1 whx whx 10 May 22 2017 slaves
-rw-r--r--. 1 whx whx 2316 May 22 2017 ssl-client.xml.example
-rw-r--r--. 1 whx whx 2268 May 22 2017 ssl-server.xml.example
-rw-r--r--. 1 whx whx 2250 May 22 2017 yarn-env.cmd
-rw-r--r--. 1 whx whx 4567 May 22 2017 yarn-env.sh
-rw-r--r--. 1 whx whx 967 Jan 26 20:19 yarn-site.xml
[whx@hadoop102 hadoop]$ vim slaves
将slaves文件的默认内容
localhost
改为:
hadoop101
hadoop102
hadoop103
注意:slaves文件中不能有空格、空行
2、测试模块群起集群命令
所有群起命令都在/opt/module/hadoop-2.7.2/sbin文件夹目录下:
[whx@hadoop102 ~]$ cd /opt/module/hadoop-2.7.2/sbin
[whx@hadoop102 sbin]$ ll
total 120
-rwxr-xr-x. 1 whx whx 2752 May 22 2017 distribute-exclude.sh
-rwxr-xr-x. 1 whx whx 6452 May 22 2017 hadoop-daemon.sh
-rwxr-xr-x. 1 whx whx 1360 May 22 2017 hadoop-daemons.sh
-rwxr-xr-x. 1 whx whx 1640 May 22 2017 hdfs-config.cmd
-rwxr-xr-x. 1 whx whx 1427 May 22 2017 hdfs-config.sh
-rwxr-xr-x. 1 whx whx 2291 May 22 2017 httpfs.sh
-rwxr-xr-x. 1 whx whx 3128 May 22 2017 kms.sh
-rwxr-xr-x. 1 whx whx 4080 May 22 2017 mr-jobhistory-daemon.sh
-rwxr-xr-x. 1 whx whx 1648 May 22 2017 refresh-namenodes.sh
-rwxr-xr-x. 1 whx whx 2145 May 22 2017 slaves.sh
-rwxr-xr-x. 1 whx whx 1779 May 22 2017 start-all.cmd
-rwxr-xr-x. 1 whx whx 1471 May 22 2017 start-all.sh
-rwxr-xr-x. 1 whx whx 1128 May 22 2017 start-balancer.sh
-rwxr-xr-x. 1 whx whx 1401 May 22 2017 start-dfs.cmd
-rwxr-xr-x. 1 whx whx 3734 May 22 2017 start-dfs.sh
-rwxr-xr-x. 1 whx whx 1357 May 22 2017 start-secure-dns.sh
-rwxr-xr-x. 1 whx whx 1571 May 22 2017 start-yarn.cmd
-rwxr-xr-x. 1 whx whx 1347 May 22 2017 start-yarn.sh
-rwxr-xr-x. 1 whx whx 1770 May 22 2017 stop-all.cmd
-rwxr-xr-x. 1 whx whx 1462 May 22 2017 stop-all.sh
-rwxr-xr-x. 1 whx whx 1179 May 22 2017 stop-balancer.sh
-rwxr-xr-x. 1 whx whx 1455 May 22 2017 stop-dfs.cmd
-rwxr-xr-x. 1 whx whx 3206 May 22 2017 stop-dfs.sh
-rwxr-xr-x. 1 whx whx 1340 May 22 2017 stop-secure-dns.sh
-rwxr-xr-x. 1 whx whx 1642 May 22 2017 stop-yarn.cmd
-rwxr-xr-x. 1 whx whx 1340 May 22 2017 stop-yarn.sh
-rwxr-xr-x. 1 whx whx 4295 May 22 2017 yarn-daemon.sh
-rwxr-xr-x. 1 whx whx 1353 May 22 2017 yarn-daemons.sh
[whx@hadoop102 sbin]$
2.1 测试HDFS数据存储模块群起脚本start-dfs.sh、stop-dfs.sh(在所有节点都可以)
[whx@hadoop102 sbin]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
6735 Jps
----------------------------hadoop102----------------------------------
5299 Jps
----------------------------hadoop103----------------------------------
4774 Jps
[whx@hadoop102 sbin]$ start-dfs.sh
Starting namenodes on [hadoop101]
hadoop101: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-namenode-hadoop101.out
hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop102.out
hadoop101: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop101.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop103.out
Starting secondary namenodes [hadoop103]
hadoop103: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-secondarynamenode-hadoop103.out
[whx@hadoop101 sbin]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
7282 Jps
6901 NameNode
7053 DataNode
----------------------------hadoop102----------------------------------
5381 DataNode
5463 Jps
----------------------------hadoop103----------------------------------
4980 SecondaryNameNode
5030 Jps
4856 DataNode
[whx@hadoop101 sbin]$ stop-dfs.sh
Stopping namenodes on [hadoop101]
hadoop101: stopping namenode
hadoop101: stopping datanode
hadoop102: stopping datanode
hadoop103: stopping datanode
Stopping secondary namenodes [hadoop103]
hadoop103: stopping secondarynamenode
[whx@hadoop101 sbin]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
7672 Jps
----------------------------hadoop102----------------------------------
5546 Jps
----------------------------hadoop103----------------------------------
5157 Jps
[whx@hadoop101 sbin]$
2.2 测试YARN资源调度模块群起脚本start-yarn.sh、stop-yarn.sh(只能在resourcemanager所在主节点hadoop102)
[whx@hadoop102 data]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
7346 Jps
----------------------------hadoop102----------------------------------
8130 Jps
----------------------------hadoop103----------------------------------
6295 Jps
[whx@hadoop102 data]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-resourcemanager-hadoop102.out
hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop103.out
hadoop101: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop101.out
hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop102.out
[whx@hadoop102 data]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
7571 Jps
7433 NodeManager
----------------------------hadoop102----------------------------------
8210 ResourceManager
8516 NodeManager
8664 Jps
----------------------------hadoop103----------------------------------
6517 Jps
6382 NodeManager
[whx@hadoop102 data]$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
hadoop101: stopping nodemanager
hadoop103: stopping nodemanager
hadoop102: stopping nodemanager
no proxyserver to stop
[whx@hadoop102 data]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
7664 Jps
----------------------------hadoop102----------------------------------
8860 Jps
----------------------------hadoop103----------------------------------
6610 Jps
[whx@hadoop102 data]$
3、测试Hadoop集群群起命令start-all.sh、stop-all.sh(只能在resourcemanager所在主节点hadoop102)
[whx@hadoop102 data]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
7766 Jps
----------------------------hadoop102----------------------------------
8946 Jps
----------------------------hadoop103----------------------------------
6688 Jps
[whx@hadoop102 data]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [hadoop101]
hadoop101: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-namenode-hadoop101.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop103.out
hadoop101: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop101.out
hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop102.out
Starting secondary namenodes [hadoop103]
hadoop103: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-secondarynamenode-hadoop103.out
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-resourcemanager-hadoop102.out
hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop102.out
hadoop101: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop101.out
hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop103.out
[whx@hadoop102 data]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
8098 NodeManager
7848 NameNode
8233 Jps
7966 DataNode
----------------------------hadoop102----------------------------------
9424 ResourceManager
9730 NodeManager
9878 Jps
9158 DataNode
----------------------------hadoop103----------------------------------
6993 NodeManager
6770 DataNode
7128 Jps
6895 SecondaryNameNode
[whx@hadoop102 data]$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [hadoop101]
hadoop101: stopping namenode
hadoop102: stopping datanode
hadoop103: stopping datanode
hadoop101: stopping datanode
Stopping secondary namenodes [hadoop103]
hadoop103: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
hadoop102: stopping nodemanager
hadoop101: stopping nodemanager
hadoop103: stopping nodemanager
no proxyserver to stop
[whx@hadoop102 data]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
8409 Jps
----------------------------hadoop102----------------------------------
10385 Jps
----------------------------hadoop103----------------------------------
7304 Jps
[whx@hadoop102 data]$
七、配置HDFS-HA集群(手动故障转移机制)
1、配置文件
1.1 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://whxNamenodeClustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.7.2/data/tmpvalue>
property>
configuration>
1.2 配置hdfs-site.xml
HDFS-HA集群中不需要再配置Hadoop辅助名称(Secondarynamenode)节点主机
<configuration>
<property>
<name>dfs.nameservicesname>
<value>whxNamenodeClustervalue>
property>
<property>
<name>dfs.ha.namenodes.whxNamenodeClustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.whxNamenodeCluster.nn1name>
<value>hadoop101:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.whxNamenodeCluster.nn2name>
<value>hadoop102:9000value>
property>
<property>
<name>dfs.namenode.http-address.whxNamenodeCluster.nn1name>
<value>hadoop101:50070value>
property>
<property>
<name>dfs.namenode.http-address.whxNamenodeCluster.nn2name>
<value>hadoop102:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/whxNamenodeClustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/module/hadoop-2.7.2/data/whxJournalnodevalue>
property>
<property>
<name>dfs.permissions.enablename>
<value>falsevalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2value>
property>
configuration>
2、启动HDFS-HA集群
2.1 在hadoop102主节点上,启动所有节点的journalnode服务(hadoop102已经配置了slaves文件)
[whx@hadoop102 ~]$ hadoop-daemon.sh start journalnode
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
6106 JournalNode
6799 Jps
----------------------------hadoop102----------------------------------
5681 JournalNode
6292 Jps
----------------------------hadoop103----------------------------------
4743 JournalNode
5103 Jps
[whx@hadoop102 ~]$
2.2 在nn1节点上,格式化NameNode
[whx@hadoop101 ~]$ hadoop namenode -format
2.3 在nn2节点上,同步nn1的元数据信息
[whx@hadoop102 ~]$ hdfs namenode -bootstrapStandby
21/01/29 22:12:44 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop102/192.168.1.102
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 2.7.2
STARTUP_MSG: classpath = /opt/module/hadoop-2.7.2/etc/hadoop:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/activation-1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-httpclient-3.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/curator-framework-2.7.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jettison-1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/zookeeper-3.4.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jetty-util-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-logging-1.1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/avro-1.7.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/mockito-all-1.8.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/stax-api-1.0-2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jersey-json-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jsp-api-2.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jersey-core-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jersey-server-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-cli-1.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/httpclient-4.2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-digester-1.8.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/curator-client-2.7.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/gson-2.2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jetty-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-net-3.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/xz-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-math3-3.1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/asm-3.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/hadoop-auth-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/paranamer-2.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jsch-0.1.42.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/guava-11.0.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-io-2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/junit-4.11.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/hamcrest-core-1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-collections-3.2.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-lang-2.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/httpcore-4.2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-configuration-1.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jsr305-3.0.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/servlet-api-2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-codec-1.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/xmlenc-0.52.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/hadoop-annotations-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jets3t-0.9.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-compress-1.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2-tests.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-nfs-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/asm-3.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/guava-11.0.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-io-2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2-tests.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/activation-1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/aopalliance-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jettison-1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-json-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/guice-3.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-core-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-server-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-cli-1.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jetty-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/xz-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/asm-3.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/guava-11.0.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-io-2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-lang-2.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/servlet-api-2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-codec-1.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-client-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/javax.inject-1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-api-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-registry-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-client-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-common-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-common-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/guice-3.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/xz-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/asm-3.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/junit-4.11.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/javax.inject-1.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar:/opt/module/hadoop-2.7.2/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2017-05-22T10:49Z
STARTUP_MSG: java = 1.8.0_121
************************************************************/
21/01/29 22:12:44 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
21/01/29 22:12:44 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: whxNamenodeCluster
Other Namenode ID: nn1
Other NN's HTTP address: http://hadoop101:50070
Other NN's IPC address: hadoop101/192.168.1.101:9000
Namespace ID: 2051055539
Block pool ID: BP-1991091767-192.168.1.101-1611929439385
Cluster ID: CID-47cd1b30-1c8a-43c3-9b06-fa74a7786904
Layout version: -63
isUpgradeFinalized: true
=====================================================
21/01/29 22:12:45 INFO common.Storage: Storage directory /opt/module/hadoop-2.7.2/data/tmp/dfs/name1 has been successfully formatted.
21/01/29 22:12:45 INFO common.Storage: Storage directory /opt/module/hadoop-2.7.2/data/tmp/dfs/name2 has been successfully formatted.
21/01/29 22:12:45 INFO namenode.TransferFsImage: Opening connection to http://hadoop101:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:2051055539:0:CID-47cd1b30-1c8a-43c3-9b06-fa74a7786904
21/01/29 22:12:45 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds
21/01/29 22:12:45 INFO namenode.TransferFsImage: Transfer took 0.01s at 0.00 KB/s
21/01/29 22:12:45 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 350 bytes.
21/01/29 22:12:45 INFO util.ExitUtil: Exiting with status 0
21/01/29 22:12:45 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop102/192.168.1.102
************************************************************/
[whx@hadoop102 ~]$
2.3 启动nn1节点、nn2节点的namenode
[whx@hadoop101 ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-namenode-hadoop101.out
[whx@hadoop101 ~]$ jps
6609 Jps
6530 NameNode
6106 JournalNode
[whx@hadoop101 ~]$
[whx@hadoop102 ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-namenode-hadoop102.out
[whx@hadoop102 ~]$ jps
5681 JournalNode
6422 Jps
6343 NameNode
[whx@hadoop102 ~]$
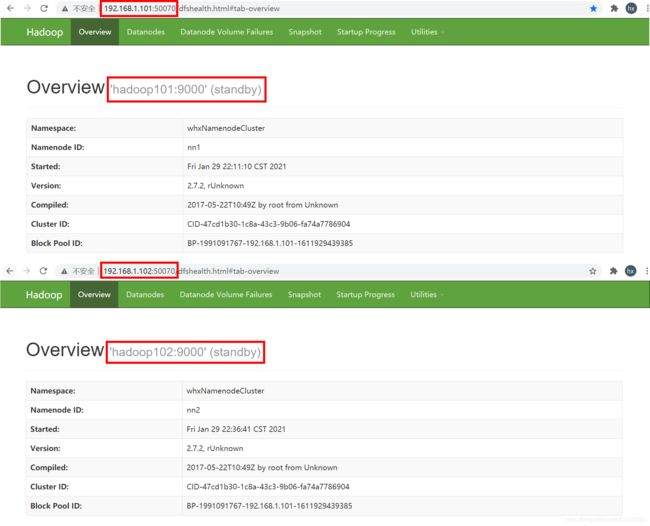
2.5 将[nn1]切换为Active状态,并查看是否Active
只有active状态的 namenode 才能接受客户端的读写请求,standby状态的 namenode 不能接受客户端的读写请求。
[whx@hadoop102 ~]$ hdfs haadmin -transitionToActive nn1
[whx@hadoop102 ~]$ hdfs haadmin -getServiceState nn1
active
[whx@hadoop102 ~]$
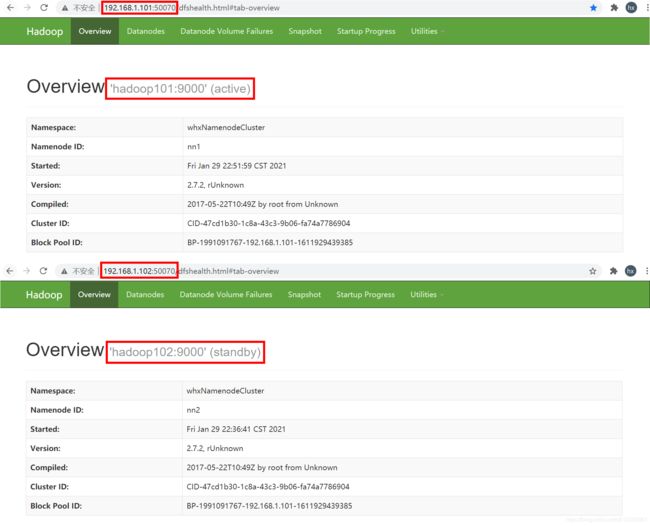
2.6 将[nn1]由Active状态切换为Standby状态
[whx@hadoop102 ~]$ hdfs haadmin
Usage: haadmin
[-transitionToActive [--forceactive] <serviceId>]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help <command>]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
[whx@hadoop102 ~]$ hdfs haadmin -transitionToStandby nn1
[whx@hadoop102 ~]$ hdfs haadmin -getServiceState nn1
standby
[whx@hadoop102 ~]$
2.6 在主节点nn2上,启动所有datanode(主节点nn2上配置了slaves文件)
[whx@hadoop102 ~]$ hadoop-daemons.sh start datanode
hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop102.out
hadoop101: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop101.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop103.out
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
7602 Jps
6530 NameNode
6106 JournalNode
7517 DataNode
----------------------------hadoop102----------------------------------
5681 JournalNode
6644 DataNode
6343 NameNode
6730 Jps
----------------------------hadoop103----------------------------------
4743 JournalNode
5259 DataNode
5342 Jps
[whx@hadoop102 ~]$
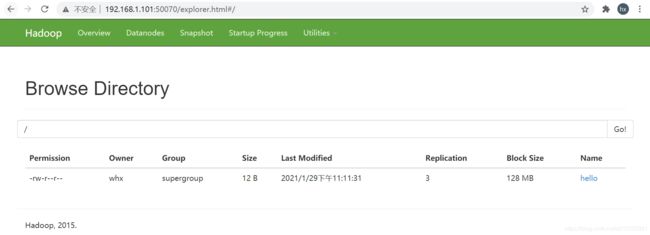
2.7 向HDFS上传文件
[whx@hadoop102 Documents]$ hadoop fs -put /home/whx/Documents/hello /
[whx@hadoop102 Documents]$
2.8 所有Journalnode节点的数据对比
通过对比可以发现,所有Journalnode节点的数据都是一样的
2.8.1 [nn1]节点的data目录
[whx@hadoop101 whxJournalnode]$ tree
.
└── whxNamenodeCluster
├── current
│ ├── committed-txid
│ ├── edits_0000000000000000001-0000000000000000002
│ ├── edits_0000000000000000003-0000000000000000004
│ ├── edits_0000000000000000005-0000000000000000005
│ ├── edits_0000000000000000006-0000000000000000007
│ ├── edits_0000000000000000008-0000000000000000009
│ ├── edits_0000000000000000010-0000000000000000011
│ ├── edits_0000000000000000012-0000000000000000013
│ ├── edits_0000000000000000014-0000000000000000015
│ ├── edits_0000000000000000016-0000000000000000025
│ ├── edits_0000000000000000026-0000000000000000027
│ ├── edits_0000000000000000028-0000000000000000029
│ ├── edits_0000000000000000030-0000000000000000031
│ ├── edits_0000000000000000032-0000000000000000033
│ ├── edits_0000000000000000034-0000000000000000035
│ ├── edits_inprogress_0000000000000000036
│ ├── last-promised-epoch
│ ├── last-writer-epoch
│ ├── paxos
│ └── VERSION
└── in_use.lock
3 directories, 20 files
[whx@hadoop101 whxJournalnode]$
2.8.2 [nn2]节点的data目录
[whx@hadoop102 whxJournalnode]$ tree
.
└── whxNamenodeCluster
├── current
│ ├── committed-txid
│ ├── edits_0000000000000000001-0000000000000000002
│ ├── edits_0000000000000000003-0000000000000000004
│ ├── edits_0000000000000000005-0000000000000000005
│ ├── edits_0000000000000000006-0000000000000000007
│ ├── edits_0000000000000000008-0000000000000000009
│ ├── edits_0000000000000000010-0000000000000000011
│ ├── edits_0000000000000000012-0000000000000000013
│ ├── edits_0000000000000000014-0000000000000000015
│ ├── edits_0000000000000000016-0000000000000000025
│ ├── edits_0000000000000000026-0000000000000000027
│ ├── edits_0000000000000000028-0000000000000000029
│ ├── edits_0000000000000000030-0000000000000000031
│ ├── edits_0000000000000000032-0000000000000000033
│ ├── edits_0000000000000000034-0000000000000000035
│ ├── edits_inprogress_0000000000000000036
│ ├── last-promised-epoch
│ ├── last-writer-epoch
│ ├── paxos
│ └── VERSION
└── in_use.lock
3 directories, 20 files
[whx@hadoop102 whxJournalnode]$
2.8.3 [nn3]节点的data目录
[whx@hadoop103 whxJournalnode]$ tree
.
└── whxNamenodeCluster
├── current
│ ├── committed-txid
│ ├── edits_0000000000000000001-0000000000000000002
│ ├── edits_0000000000000000003-0000000000000000004
│ ├── edits_0000000000000000005-0000000000000000005
│ ├── edits_0000000000000000006-0000000000000000007
│ ├── edits_0000000000000000008-0000000000000000009
│ ├── edits_0000000000000000010-0000000000000000011
│ ├── edits_0000000000000000012-0000000000000000013
│ ├── edits_0000000000000000014-0000000000000000015
│ ├── edits_0000000000000000016-0000000000000000025
│ ├── edits_0000000000000000026-0000000000000000027
│ ├── edits_0000000000000000028-0000000000000000029
│ ├── edits_0000000000000000030-0000000000000000031
│ ├── edits_0000000000000000032-0000000000000000033
│ ├── edits_0000000000000000034-0000000000000000035
│ ├── edits_0000000000000000036-0000000000000000037
│ ├── edits_inprogress_0000000000000000038
│ ├── last-promised-epoch
│ ├── last-writer-epoch
│ ├── paxos
│ └── VERSION
└── in_use.lock
3 directories, 21 files
[whx@hadoop103 whxJournalnode]$
八、配置HDFS-HA集群(自动故障转移机制)-基于Zookeeper
Zookeeper分布式安装部署
1、配置文件的修改
1.1 在hdfs-site.xml中增加
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/whx/.ssh/id_rsavalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.whxNamenodeClustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
修改后变为:
<configuration>
<property>
<name>dfs.nameservicesname>
<value>whxNamenodeClustervalue>
property>
<property>
<name>dfs.ha.namenodes.whxNamenodeClustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.whxNamenodeCluster.nn1name>
<value>hadoop101:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.whxNamenodeCluster.nn2name>
<value>hadoop102:9000value>
property>
<property>
<name>dfs.namenode.http-address.whxNamenodeCluster.nn1name>
<value>hadoop101:50070value>
property>
<property>
<name>dfs.namenode.http-address.whxNamenodeCluster.nn2name>
<value>hadoop102:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/whxNamenodeClustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/module/hadoop-2.7.2/data/whxJournalnodevalue>
property>
<property>
<name>dfs.permissions.enablename>
<value>falsevalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/whx/.ssh/id_rsavalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.whxNamenodeClustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2value>
property>
configuration>
确保所配置的Namenode之间可以相互免密登陆。因为配置的Namenode为hadoop101、hadoop102,所以hadoop101、hadoop102之间需要相互可以免密登陆。由于之前只设置了hadoop102对hadoop101、hadoop103的免密登陆,所以还要设置一下hadoop101对hadoop102的免密登陆。
1.2 在core-site.xml文件中增加
<property>
<name>ha.zookeeper.quorumname>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181value>
property>
修改后变为:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://whxNamenodeClustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.7.2/data/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181value>
property>
configuration>
2、分发修改后的配置文件
[whx@hadoop102 hadoop]$ xsync.sh core-site.xml
要分发的文件的路径是:/opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
-------------------------hadoop101-------------------------
sending incremental file list
core-site.xml
sent 659 bytes received 43 bytes 468.00 bytes/sec
total size is 1276 speedup is 1.82
-------------------------hadoop102-------------------------
sending incremental file list
sent 36 bytes received 12 bytes 96.00 bytes/sec
total size is 1276 speedup is 26.58
-------------------------hadoop103-------------------------
sending incremental file list
core-site.xml
sent 659 bytes received 43 bytes 1404.00 bytes/sec
total size is 1276 speedup is 1.82
[whx@hadoop102 hadoop]$
[whx@hadoop102 hadoop]$ xsync.sh hdfs-site.xml
要分发的文件的路径是:/opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
-------------------------hadoop101-------------------------
sending incremental file list
hdfs-site.xml
sent 2292 bytes received 67 bytes 1572.67 bytes/sec
total size is 3692 speedup is 1.57
-------------------------hadoop102-------------------------
sending incremental file list
sent 36 bytes received 12 bytes 96.00 bytes/sec
total size is 3692 speedup is 76.92
-------------------------hadoop103-------------------------
sending incremental file list
hdfs-site.xml
sent 2292 bytes received 67 bytes 4718.00 bytes/sec
total size is 3692 speedup is 1.57
[whx@hadoop102 hadoop]$
3、启动HDFS-HA集群
3.1 先关闭所有HDFS服务
[whx@hadoop102 ~]$ stop-dfs.sh
3.2 启动Zookeeper集群
[whx@hadoop102 hadoop]$ xcall.sh /opt/module/zookeeper-3.4.10/bin/zkServer.sh start
要执行的命令是/opt/module/zookeeper-3.4.10/bin/zkServer.sh start
----------------------------hadoop101----------------------------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
----------------------------hadoop102----------------------------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
----------------------------hadoop103----------------------------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[whx@hadoop102 hadoop]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
3126 QuorumPeerMain
3160 Jps
----------------------------hadoop102----------------------------------
3426 QuorumPeerMain
3470 Jps
----------------------------hadoop103----------------------------------
3066 QuorumPeerMain
3100 Jps
[whx@hadoop102 hadoop]$
此时通过zkCli.sh进入Zookeeper客户端查看,可以看到根节点没有hadoop-ha目录
[whx@hadoop103 ~]$ /opt/module/zookeeper-3.4.10/bin/zkCli.sh -server hadoop103:2181
[zk: hadoop103:2181(CONNECTED) 1] ls /
[zookeeper]
3.3 初始化HA在Zookeeper中状态,格式化:
[whx@hadoop102 hadoop]$ hdfs zkfc -formatZK
21/01/30 11:26:26 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at hadoop102/192.168.1.102:9000
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:host.name=hadoop102
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_121
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:java.home=/opt/module/jdk1.8.0_121/jre
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:java.class.path=/opt/module/hadoop-2.7.2/etc/hadoop:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/activation-1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-httpclient-3.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/curator-framework-2.7.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jettison-1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/zookeeper-3.4.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jetty-util-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-logging-1.1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/avro-1.7.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/mockito-all-1.8.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/stax-api-1.0-2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jersey-json-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jsp-api-2.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jersey-core-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jersey-server-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-cli-1.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/httpclient-4.2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-digester-1.8.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/curator-client-2.7.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/gson-2.2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jetty-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-net-3.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/xz-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-math3-3.1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/asm-3.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/hadoop-auth-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/paranamer-2.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jsch-0.1.42.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/guava-11.0.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-io-2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/junit-4.11.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/hamcrest-core-1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-collections-3.2.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-lang-2.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/httpcore-4.2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-configuration-1.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jsr305-3.0.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/servlet-api-2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-codec-1.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/xmlenc-0.52.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/hadoop-annotations-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jets3t-0.9.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-compress-1.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2-tests.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-nfs-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/asm-3.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/guava-11.0.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-io-2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2-tests.jar:/opt/module/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/activation-1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/aopalliance-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jettison-1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-json-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/guice-3.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-core-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-server-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-cli-1.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jetty-6.1.26.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/xz-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/asm-3.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/guava-11.0.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-io-2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-lang-2.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/servlet-api-2.5.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-codec-1.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-client-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/javax.inject-1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-api-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-registry-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-client-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-common-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-common-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/guice-3.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/xz-1.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/asm-3.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/junit-4.11.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/javax.inject-1.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar:/opt/module/hadoop-2.7.2/contrib/capacity-scheduler/*.jar
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/opt/module/hadoop-2.7.2/lib/native
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:os.version=2.6.32-642.el6.x86_64
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:user.name=whx
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:user.home=/home/whx
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Client environment:user.dir=/opt/module/hadoop-2.7.2/etc/hadoop
21/01/30 11:26:26 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=hadoop101:2181,hadoop102:2181,hadoop103:2181 sessionTimeout=5000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@436813f3
21/01/30 11:26:26 INFO zookeeper.ClientCnxn: Opening socket connection to server hadoop102/192.168.1.102:2181. Will not attempt to authenticate using SASL (unknown error)
21/01/30 11:26:26 INFO zookeeper.ClientCnxn: Socket connection established to hadoop102/192.168.1.102:2181, initiating session
21/01/30 11:26:26 INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop102/192.168.1.102:2181, sessionid = 0x6677514fceb90000, negotiated timeout = 5000
21/01/30 11:26:26 INFO ha.ActiveStandbyElector: Session connected.
21/01/30 11:26:27 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/whxNamenodeCluster in ZK.
21/01/30 11:26:27 INFO zookeeper.ZooKeeper: Session: 0x6677514fceb90000 closed
21/01/30 11:26:27 INFO zookeeper.ClientCnxn: EventThread shut down
[whx@hadoop102 hadoop]$
此时通过zkCli.sh进入Zookeeper客户端查看,可以看到根节点出现一个hadoop-ha目录
[whx@hadoop103 ~]$ /opt/module/zookeeper-3.4.10/bin/zkCli.sh -server hadoop103:2181
[zk: hadoop103:2181(CONNECTED) 2] ls /
[zookeeper, hadoop-ha]
[zk: hadoop103:2181(CONNECTED) 3] ls /hadoop-ha
[whxNamenodeCluster]
[zk: hadoop103:2181(CONNECTED) 4] ls /hadoop-ha/whxNamenodeCluster
[]
3.4 群起HDFS服务
[whx@hadoop102 ~]$ start-dfs.sh
Starting namenodes on [hadoop101 hadoop102]
hadoop102: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-namenode-hadoop102.out
hadoop101: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-namenode-hadoop101.out
hadoop101: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop101.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop103.out
hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop102.out
Starting journal nodes [hadoop101 hadoop102 hadoop103]
hadoop101: starting journalnode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-journalnode-hadoop101.out
hadoop102: starting journalnode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-journalnode-hadoop102.out
hadoop103: starting journalnode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-journalnode-hadoop103.out
Starting ZK Failover Controllers on NN hosts [hadoop101 hadoop102]
hadoop102: starting zkfc, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-zkfc-hadoop102.out
hadoop101: starting zkfc, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-zkfc-hadoop101.out
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
3650 DataNode
3762 JournalNode
3556 NameNode
3126 QuorumPeerMain
3958 Jps
3901 DFSZKFailoverController
----------------------------hadoop102----------------------------------
4240 DFSZKFailoverController
3809 DataNode
3426 QuorumPeerMain
3683 NameNode
4318 Jps
4031 JournalNode
----------------------------hadoop103----------------------------------
3233 DataNode
3345 JournalNode
3155 ZooKeeperMain
3066 QuorumPeerMain
3419 Jps
[whx@hadoop102 ~]$
在各个NameNode节点上启动DFSZKFailoverController,先在哪台机器启动,哪个机器的NameNode就是Active NameNode。
处于Active状态的Namenode节点有一个DFSZKFailoverController进程。
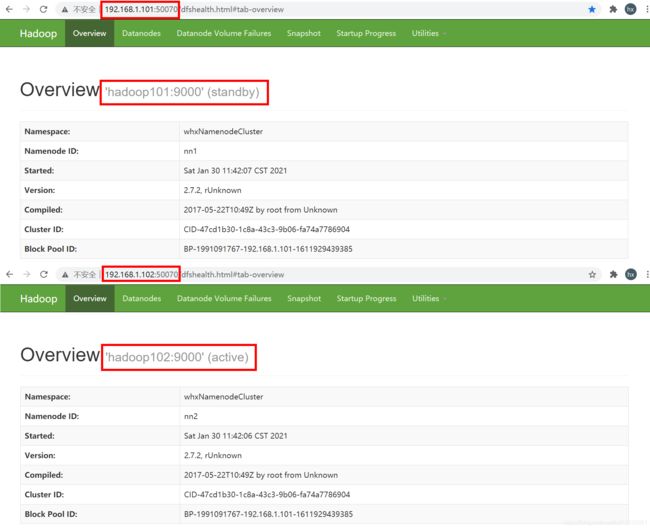
此时通过zkCli.sh进入Zookeeper客户端查看,可以看到/hadoop-ha/whxNamenodeCluster下出现了两个文件夹:ActiveBreadCrumb、ActiveStandbyElectorLock,通过get命令也可以看到此时hadoop102上的Namenode节点处于Active状态。
[whx@hadoop103 ~]$ /opt/module/zookeeper-3.4.10/bin/zkCli.sh -server hadoop103:2181
[zk: hadoop103:2181(CONNECTED) 9] ls /hadoop-ha/whxNamenodeCluster
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: hadoop103:2181(CONNECTED) 10] get /hadoop-ha/whxNamenodeCluster/ActiveStandbyElectorLock
whxNamenodeClusternn2 hadoop102 �F(�>
cZxid = 0x100000007
ctime = Sat Jan 30 11:42:21 CST 2021
mZxid = 0x100000007
mtime = Sat Jan 30 11:42:21 CST 2021
pZxid = 0x100000007
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x6777514fceef0001
dataLength = 42
numChildren = 0
[zk: hadoop103:2181(CONNECTED) 12]
4、模拟集群HDFS故障转移
让处于Active状态的hadoop102节点的namenode进程挂掉
[whx@hadoop102 ~]$ jps
4240 DFSZKFailoverController
3809 DataNode
4529 Jps
3426 QuorumPeerMain
3683 NameNode
4031 JournalNode
[whx@hadoop102 ~]$ kill -9 3683
[whx@hadoop102 ~]$
此时再通过zkCli.sh进入Zookeeper客户端,通过get命令查看此时处于Active状态的Namenode变为hadoop101节点。
[zk: hadoop103:2181(CONNECTED) 12] get /hadoop-ha/whxNamenodeCluster/ActiveStandbyElectorLock
whxNamenodeClusternn1 hadoop101 �F(�>
cZxid = 0x10000000c
ctime = Sat Jan 30 12:15:40 CST 2021
mZxid = 0x10000000c
mtime = Sat Jan 30 12:15:40 CST 2021
pZxid = 0x10000000c
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x6577514fceb90000
dataLength = 42
numChildren = 0
[zk: hadoop103:2181(CONNECTED) 13]
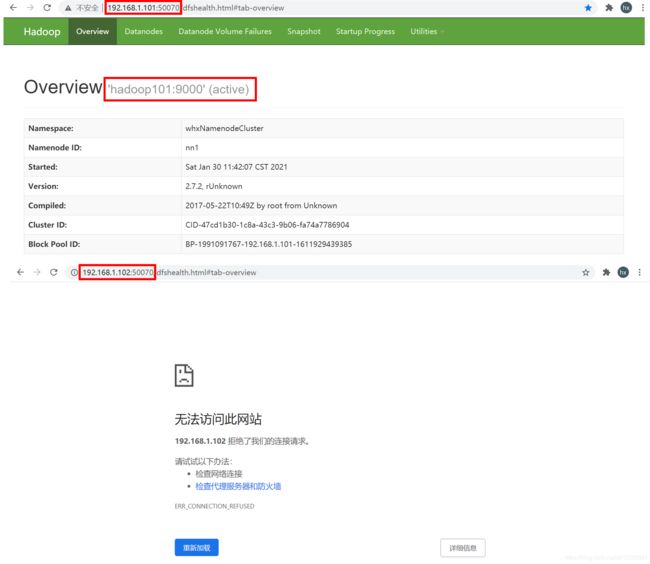
九、配置YARN-HA集群(自动故障转移机制)
1、yarn-site.xml配置文件的修改
<?xml version="1.0"?>
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
</configuration>
修改为
<?xml version="1.0"?>
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!-- 集群中resourcemanager节点都有哪些 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定rm1节点所在机器 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop102</value>
</property>
<!-- 指定rm2节点所在机器 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop103</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
<!--启用HA自动故障转移-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
2、分发修改后的yarn-site.xml配置文件
[whx@hadoop102 hadoop]$ xsync.sh yarn-site.xml
要分发的文件的路径是:/opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml
-------------------------hadoop101-------------------------
sending incremental file list
yarn-site.xml
sent 2285 bytes received 43 bytes 4656.00 bytes/sec
total size is 2206 speedup is 0.95
-------------------------hadoop102-------------------------
sending incremental file list
sent 36 bytes received 12 bytes 32.00 bytes/sec
total size is 2206 speedup is 45.96
-------------------------hadoop103-------------------------
sending incremental file list
yarn-site.xml
sent 2285 bytes received 43 bytes 4656.00 bytes/sec
total size is 2206 speedup is 0.95
[whx@hadoop102 hadoop]$
3、启动YARN-HA集群
- 在hadoop102中执行start-yarn.sh,启动本节点的ResourceManager以及集群中所有节点的NodeManager;
- 在hadoop102服务器中执行start-yarn.sh,不能启动其他配置了resourcemanager的服务器的ResourceManager,其他服务器的ResourceManager需要去各自服务器去各自启动;
在hadoop102中执行start-yarn.sh
[whx@hadoop102 hadoop]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-resourcemanager-hadoop102.out
hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop103.out
hadoop101: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop101.out
hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-nodemanager-hadoop102.out
[whx@hadoop102 hadoop]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
3650 DataNode
3762 JournalNode
3556 NameNode
4501 NodeManager
3126 QuorumPeerMain
4615 Jps
3901 DFSZKFailoverController
----------------------------hadoop102----------------------------------
4240 DFSZKFailoverController
3809 DataNode
3426 QuorumPeerMain
5172 Jps
4743 ResourceManager
4871 NodeManager
4031 JournalNode
----------------------------hadoop103----------------------------------
3233 DataNode
3345 JournalNode
3155 ZooKeeperMain
3875 NodeManager
3989 Jps
3066 QuorumPeerMain
[whx@hadoop102 hadoop]$
在hadoop103中执行start-yarn.sh
[whx@hadoop103 ~]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-resourcemanager-hadoop103.out
[whx@hadoop103 ~]$
[whx@hadoop102 hadoop]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
4657 Jps
3650 DataNode
3762 JournalNode
3556 NameNode
4501 NodeManager
3126 QuorumPeerMain
3901 DFSZKFailoverController
----------------------------hadoop102----------------------------------
4240 DFSZKFailoverController
3809 DataNode
5218 Jps
3426 QuorumPeerMain
4743 ResourceManager
4871 NodeManager
4031 JournalNode
----------------------------hadoop103----------------------------------
4049 ResourceManager
3233 DataNode
3345 JournalNode
3875 NodeManager
3066 QuorumPeerMain
4109 Jps
[whx@hadoop102 hadoop]$
由于hadoop102节点先开启的yarn,所以hadoop102节点的yarn为Active状态,hadoop103节点的yarn为Standby状态
在浏览器输入:http://192.168.1.102:8088/ 进入hadoop102节点的yarn界面

在浏览器输入:http://192.168.1.103:8088/ ,重定向到 hadoop102节点的yarn界面

4、模拟集群YARN故障转移
[whx@hadoop102 hadoop]$ jps
4240 DFSZKFailoverController
3809 DataNode
3426 QuorumPeerMain
5268 Jps
4743 ResourceManager
4871 NodeManager
4031 JournalNode
[whx@hadoop102 hadoop]$ kill -9 4743
[whx@hadoop102 hadoop]$
此时再通过浏览器输入:http://192.168.1.102:8088/ ,则无法进入hadoop102节点的yarn界面
通过浏览器输入:http://192.168.1.103:8088/ ,则进入hadoop103节点的yarn界面

如果再次将hadoop102 的ResourceManager进程开启,hadoop102 的ResourceManager进程只能处于Standby状态。
[whx@hadoop102 hadoop]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-whx-resourcemanager-hadoop102.out
[whx@hadoop102 hadoop]$
在浏览器输入:http://192.168.1.102:8088/ ,会重定向到 hadoop103节点的yarn界面
十、配置Hadoop集群支持snappy压缩
上传支持snappy压缩的hadoop jar包到 /ojpt/soft 目录,在此目录解压缩,支持snappy压缩的hadoop jar包的lib/native目录里会有和snappy项目的文件
[whx@hadoop102 lib]$ cd native/
[whx@hadoop102 native]$ ll
total 5188
-rw-r--r--. 1 whx whx 1210260 Sep 1 2017 libhadoop.a
-rw-r--r--. 1 whx whx 1487268 Sep 1 2017 libhadooppipes.a
lrwxrwxrwx. 1 whx whx 18 Jan 31 10:42 libhadoop.so -> libhadoop.so.1.0.0
-rwxr-xr-x. 1 whx whx 716316 Sep 1 2017 libhadoop.so.1.0.0
-rw-r--r--. 1 whx whx 582048 Sep 1 2017 libhadooputils.a
-rw-r--r--. 1 whx whx 364860 Sep 1 2017 libhdfs.a
lrwxrwxrwx. 1 whx whx 16 Jan 31 10:42 libhdfs.so -> libhdfs.so.0.0.0
-rwxr-xr-x. 1 whx whx 229113 Sep 1 2017 libhdfs.so.0.0.0
-rw-r--r--. 1 whx whx 472950 Sep 1 2017 libsnappy.a
-rwxr-xr-x. 1 whx whx 955 Sep 1 2017 libsnappy.la
lrwxrwxrwx. 1 whx whx 18 Jan 31 10:42 libsnappy.so -> libsnappy.so.1.3.0
lrwxrwxrwx. 1 whx whx 18 Jan 31 10:42 libsnappy.so.1 -> libsnappy.so.1.3.0
-rwxr-xr-x. 1 whx whx 228177 Sep 1 2017 libsnappy.so.1.3.0
[whx@hadoop102 native]$
删除原来hadoop集群里所有节点上的hadoop安装目录里的lib目录,将支持snappy压缩的hadoop jar包里的lib文件夹替代原来hadoop集群里所有节点上的hadoop安装目录里的lib目录即可。
参考资料:
深入讲解大数据的各种知识