Kafka监控工具汇总
对于大数据集群来说,监控功能是非常必要的,通过日志判断故障低效,我们需要完整的指标来帮我们管理Kafka集群。本文讨论Kafka的监控以及一些常用的第三方监控工具。
一、Kafka Monitoring
首先介绍kafka的监控原理,第三方工具也是通过这些来进行监控的,我们也可以自己去是实现监控,官网关于监控的文档地址如下:
http://kafka.apache.org/documentation/#monitoring](http://kafka.apache.org/documentation/#monitoring)
kafka使用Yammer Metrics进行监控,Yammer Metrics是一个java的监控库。
kafka默认有很多的监控指标,默认都使用JMX接口远程访问,具体方法是在启动broker和clients之前设置JMX_PORT:
JMX_PORT=9997 bin/kafka-server-start.sh config/server.properties
Kafka的每个监控指标都是以JMX MBEAN的形式定义的,MBEAN是一个被管理的资源实例。
我们可以使用Jconsole (Java Monitoring and Management Console),一种基于JMX的可视化监视、管理工具。
来可视化监控的结果:

图2 Jconsole
随后在Mbean下可以找到各种kafka的指标。
Mbean的命名规范是 kafka.xxx:type=xxx,xxx=xxx
主要分为以下几类:
(监控指标较多,这里只截取部分,具体请查看官方文档)
Graphing and Alerting 监控:
kafka.server为服务器相关,kafka.network为网络相关。
| Description | Mbean name | Normal value |
|---|---|---|
| Message in rate | kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec | |
| Byte in rate from clients | kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec | |
| Byte in rate from other brokers | kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesInPerSec | |
| Request rate | kafka.network:type=RequestMetrics,name=RequestsPerSec,request={Produce|FetchConsumer|FetchFollower} | |
| Error rate | kafka.network:type=RequestMetrics,name=ErrorsPerSec,request=([-.\w]+),error=([-.\w]+) | Number of errors in responses counted per-request-type, per-error-code. If a response contains multiple errors, all are counted. error=NONE indicates successful responses. |
Common monitoring metrics for producer/consumer/connect/streams监控:
kafka运行过程中的监控。
| Metric/Attribute name | Description | Mbean name |
|---|---|---|
| connection-close-rate | Connections closed per second in the window. | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| connection-close-total | Total connections closed in the window. | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
Common Per-broker metrics for producer/consumer/connect/streams监控:
每一个broker的监控。
| Metric/Attribute name | Description | Mbean name |
|---|---|---|
| outgoing-byte-rate | The average number of outgoing bytes sent per second for a node. | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| outgoing-byte-total | The total number of outgoing bytes sent for a node. | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
Producer监控:
producer调用过程中的监控。
| Metric/Attribute name | Description | Mbean name |
|---|---|---|
| waiting-threads | The number of user threads blocked waiting for buffer memory to enqueue their records. | kafka.producer:type=producer-metrics,client-id=([-.\w]+) |
| buffer-total-bytes | The maximum amount of buffer memory the client can use (whether or not it is currently used). | kafka.producer:type=producer-metrics,client-id=([-.\w]+) |
| buffer-available-bytes | The total amount of buffer memory that is not being used (either unallocated or in the free list). | kafka.producer:type=producer-metrics,client-id=([-.\w]+) |
| bufferpool-wait-time | The fraction of time an appender waits for space allocation. | kafka.producer:type=producer-metrics,client-id=([-.\w]+) |
Consumer监控:
consumer调用过程中的监控。
| Metric/Attribute name | Description | Mbean name |
|---|---|---|
| commit-latency-avg | The average time taken for a commit request | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| commit-latency-max | The max time taken for a commit request | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| commit-rate | The number of commit calls per second | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| commit-total | The total number of commit calls | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
Connect监控:
| Attribute name | Description | |
|---|---|---|
| connector-count | The number of connectors run in this worker. | |
| connector-startup-attempts-total | The total number of connector startups that this worker has attempted. |
Streams 监控:
| Metric/Attribute name | Description | Mbean name |
|---|---|---|
| commit-latency-avg | The average execution time in ms for committing, across all running tasks of this thread. | kafka.streams:type=stream-metrics,client-id=([-.\w]+) |
| commit-latency-max | The maximum execution time in ms for committing across all running tasks of this thread. | kafka.streams:type=stream-metrics,client-id=([-.\w]+) |
| poll-latency-avg | The average execution time in ms for polling, across all running tasks of this thread. | kafka.streams:type=stream-metrics,client-id=([-.\w]+) |
这些指标涵盖了我们使用kafka过程中的各种情况,还有kafka.log记录日志信息。每一个Mbean下都有具体的参数。
通过这些参数,比如出站进站速率,ISR变化速率,Producer端的batch大小,线程数,Consumer端的延时大小,流速等等,当然我们也要关注JVM,还有OS层面的监控,这些都有通用的工具,这里不做赘述。
kafka的监控原理已经基本了解,其他第三方监控工具也大部分是在这个层面进行的完善,下面来介绍几款主流的监控工具。
二、JmxTool
JmxTool并不是一个框架,而是Kafka默认提供的一个工具,用于实时查看JMX监控指标。。
打开终端进入到Kafka安装目录下,输入命令bin/kafka-run-class.sh kafka.tools.JmxTool便可以得到JmxTool工具的帮助信息。
比如我们要监控入站速率,可以输入命令:
bin/kafka-run-class.sh kafka.tools.JmxTool --object-name kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec --jmx-url service:jmx:rmi:///jndi/rmi://:9997/jmxrmi --date-format "YYYY-MM-dd HH:mm:ss" --attributes FifteenMinuteRate --reporting-interval 5000
BytesInPerSec的值每5秒会打印在控制台上:
>kafka_2.12-2.0.0 rrd$ bin/kafka-run-class.sh kafka.tools.JmxTool --object-name kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec --jmx-url service:jmx:rmi:///jndi/rmi://:9997/jmxrmi --date-format "YYYY-MM-dd HH:mm:ss" --attributes FifteenMinuteRate --reporting-interval 5000
Trying to connect to JMX url: service:jmx:rmi:///jndi/rmi://:9997/jmxrmi.
"time","kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec:FifteenMinuteRate"
2018-08-10 14:52:15,784224.2587058166
2018-08-10 14:52:20,1003401.2319497257
2018-08-10 14:52:25,1125080.6160773218
2018-08-10 14:52:30,1593394.1860063889
三、Kafka-Manager
雅虎公司2015年开源的kafka监控框架,使用scala编写。github地址如下:https://github.com/yahoo/kafka-manager
使用条件:
- Kafka 0.8.. or 0.9.. or 0.10.. or 0.11..
- Java 8+
下载kafka-manager
配置:conf/application.conf
kafka-manager.zkhosts="my.zookeeper.host.com:2181,other.zookeeper.host.com:2181"
部署:这里要用到sbt部署
./sbt clean dist
启动:
bin/kafka-manager
指定端口:
$ bin/kafka-manager -Dconfig.file=/path/to/application.conf -Dhttp.port=8080
权限:
$ bin/kafka-manager -Djava.security.auth.login.config=/path/to/my-jaas.conf
随后访问local host:8080
就可以看到监控页面了:
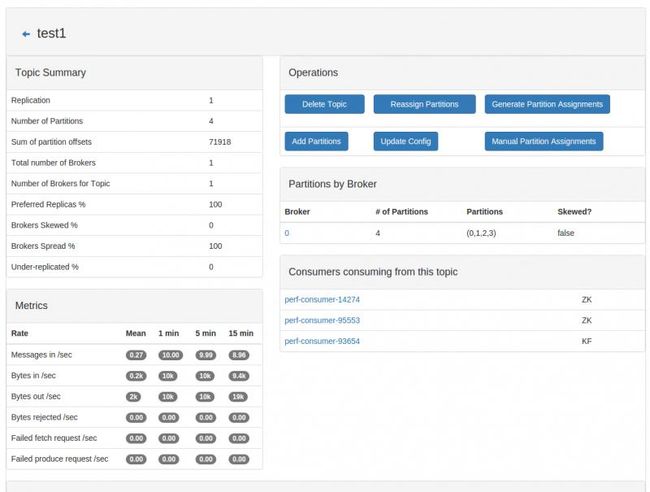
图 topic
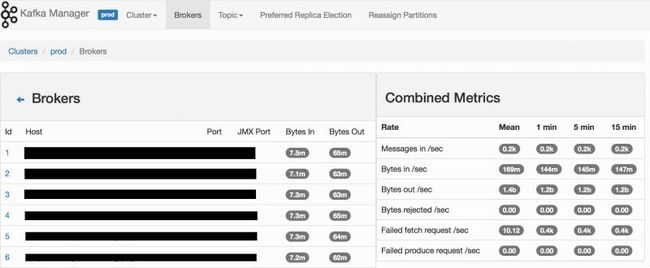
图 broker
页面非常的简洁,也有很多丰富的功能,开源免费,推荐使用,只是目前版本支持到Kafka 0.8.. or 0.9.. or 0.10.. or 0.11,需要特别注意。
四、kafka-monitor
linkin开源的kafka监控框架,github地址如下:https://github.com/linkedin/kafka-monitor
基于 Gradle 2.0以上版本,支持java 7和java 8.
支持kafka从0.8-2.0,用户可根据需求下载不同分支即可。
使用:
编译:
$ git clone https://github.com/linkedin/kafka-monitor.git
$ cd kafka-monitor
$ ./gradlew jar
修改配置:config/kafka-monitor.properties
"zookeeper.connect" = "localhost:2181"
启动:
$ ./bin/kafka-monitor-start.sh config/kafka-monitor.properties
单集群启动:
$ ./bin/single-cluster-monitor.sh --topic test --broker-list localhost:9092 --zookeeper localhost:2181
多集群启动:
$ ./bin/kafka-monitor-start.sh config/multi-cluster-monitor.properties
随后访问localhost:8080 看到监控页面
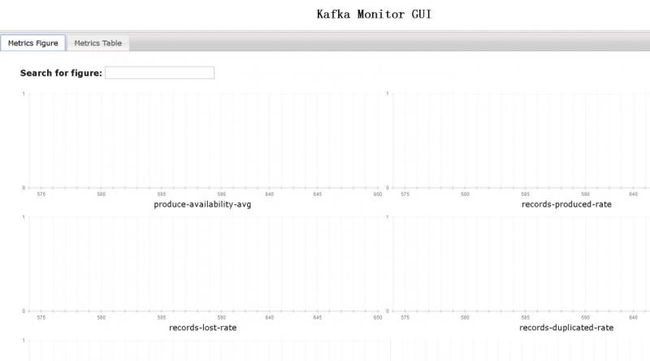
图 kafkamonitor
同时我们还可以通过http请求查询其他指标:
curl localhost:8778/jolokia/read/kmf.services:type=produce-service,name=*/produce-availability-avg
总体来说,他的web功能比较简单,用户使用不多,http功能很有用,支持版本较多。
五、Kafka Offset Monitor
官网地址http://quantifind.github.io/KafkaOffsetMonitor/
github地址 https://github.com/quantifind/KafkaOffsetMonitor
使用:下载以后执行
java -cp KafkaOffsetMonitor-assembly-0.3.0.jar:kafka-offset-monitor-another-db-reporter.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk zk-server1,zk-server2 \
--port 8080 \
--refresh 10.seconds \
--retain 2.days
--pluginsArgs anotherDbHost=host1,anotherDbPort=555
随后查看localhost:8080

图 offsetmonitor1

图offsetmonitor2
这个项目更关注于对offset的监控,页面很丰富,但是15年以后不再更新,无法支持最新版本kafka。继续维护的版本地址如下https://github.com/Morningstar/kafka-offset-monitor。
六、Cruise-control
linkin于2017年8月开源了cruise-control框架,用于监控大规模集群,包括一系列的运维功能,据称在linkedin有着两万多台的kafka集群,项目还在持续更新中。
项目github地址:https://github.com/linkedin/cruise-control
使用:
下载
git clone https://github.com/linkedin/cruise-control.git && cd cruise-control/
编译
./gradlew jar
修改 config/cruisecontrol.properties
bootstrap.servers zookeeper.connect
启动:
./gradlew jar copyDependantLibs
./kafka-cruise-control-start.sh [-jars PATH_TO_YOUR_JAR_1,PATH_TO_YOUR_JAR_2] config/cruisecontrol.properties [port]
启动后访问:
http://localhost:9090/kafkacruisecontrol/state
没有页面,所有都是用rest api的形式提供的。
接口列表如下:https://github.com/linkedin/cruise-control/wiki/REST-APIs
这个框架灵活性很大,用户可以根据自己的情况来获取各种指标优化自己的集群。
七、Doctorkafka
DoctorKafka是Pinterest 开源 Kafka 集群自愈和工作负载均衡工具。
Pinterest 是一个进行图片分享的社交站点。他们使用 Kafka 作为中心化的消息传输工具,用于数据摄取、流处理等场景。随着用户数量的增加,Kafka 集群也越来越庞大,对它的管理日趋复杂,并变成了运维团队的沉重负担,因此他们研发了 Kafka 集群自愈和工作负载均衡工具 DoctorKafka,最近他们已经在 GitHub 上将该项目开源。
使用:
下载:
git clone [git-repo-url] doctorkafka
cd doctorkafka
编译:
mvn package -pl kafkastats -am
启动:
java -server \
-Dlog4j.configurationFile=file:./log4j2.xml \
-cp lib/*:kafkastats-0.2.4.8.jar \
com.pinterest.doctorkafka.stats.KafkaStatsMain \
-broker 127.0.0.1 \
-jmxport 9999 \
-topic brokerstats \
-zookeeper zookeeper001:2181/cluster1 \
-uptimeinseconds 3600 \
-pollingintervalinseconds 60 \
-ostrichport 2051 \
-tsdhostport localhost:18126 \
-kafka_config /etc/kafka/server.properties \
-producer_config /etc/kafka/producer.properties \
-primary_network_ifacename eth0
页面如下:
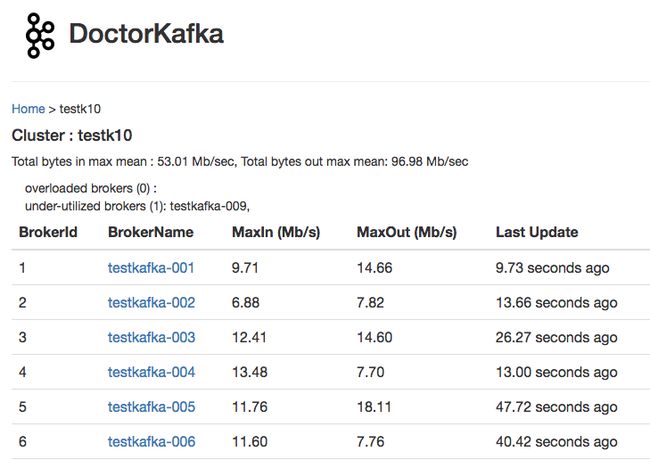
图dockerkafka
DoctorKafka 在启动之后,会阶段性地检查每个集群的状态。当探测到 broker 出现故障时,它会将故障 broker 的工作负载转移给有足够带宽的 broker。如果在集群中没有足够的资源进行重分配的话,它会发出告警。属于一个自动维护集群健康的框架。
八、Burrow
Burrow是LinkedIn开源的一款专门监控consumer lag的框架。
github地址如下:https://github.com/linkedin/Burrow
使用Burrow监控kafka, 不需要预先设置lag的阈值, 他完全是基于消费过程的动态评估
Burrow支持读取kafka topic和,zookeeper两种方式的offset,对于新老版本kafka都可以很好支持
Burrow支持http, email类型的报警
Burrow默认只提供HTTP接口(HTTP endpoint),数据为json格式,没有web UI。
安装使用:
$ Clone github.com/linkedin/Burrow to a directory outside of $GOPATH. Alternatively, you can export GO111MODULE=on to enable Go module.
$ cd to the source directory.
$ go mod tidy
$ go install
示例:
列出所有监控的Kafka集群
curl -s http://localhost:8000/v3/kafka |jq
{
"error": false,
"message": "cluster list returned",
"clusters": [
"kafka",
"kafka"
],
"request": {
"url": "/v3/kafka",
"host": "kafka"
}
}
其他的框架,还有kafka-web-console:https://github.com/claudemamo/kafka-web-console
kafkat:https://github.com/airbnb/kafkat
capillary:https://github.com/keenlabs/capillary
chaperone:https://github.com/uber/chaperone
还有很多,但是我们要结合自己的kafka版本情况进行选择。