搜狗微信文章爬虫
最近因为搜狗微信进行了升级,导致公司的爬虫失去作用,然后其他同事又都有工作,于是乎这个任务就交给了我这个“菜鸟程序员”,因为之前没有写过爬虫相关的代码,Python也是工作后才现学的,导致为此纠结了好长时间。今天特意做个总结。
爬虫出现问题,首先确定问题来源,是数据爬取过程中出现问题还是就没爬取到数据(爬取的网站改版,网站反扒,ip被封等等),确定了问题才能针对的行进行解决。
此次搜狗微信文章爬虫失败,是由于搜狗微信端进行了反扒升级
1. 对微信文章的请求进行了再次构造
2. 由之前的广度变为深度爬虫(本人简单理解,有误请指出)
微信文章请求再次构造
列表页显示的链接
![]()
fiddler抓包过程中得到的链接
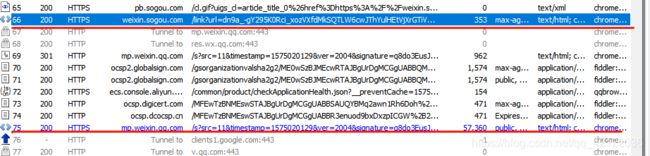
第一条红线是我们进入列表页后,在页面上得到的链接转换后的链接,点击其对应的标题我们进入微信文章页面,这是我们的链接就编程第二条红线所表示的。我们将列表页得到的链接,与第一条红线的链接进行对比。
/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS4XR14LbUFy5kOb5wudY7Vchbjx5-aT6Y1qXa8Fplpd9Ygh6C8KK-nFR8l4k8ClGtYqMlHhRDaqO9V9cidpqa221fr7WKVz9DOD9C3cHjUBts9TXllwG5_TveqOr92UZo6HkPfvlSdBaxVHXlJSc9uKqJ3To8vN1HzNbRUfLwWDdhHN9zYnmZLC0bP2W9N0lK-43EWecxUrMK99QhRlIdlRe0WC6Sbi7DA..&type=2&query=%E6%9D%8E%E7%8E%B0
/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS4XR14LbUFy5kOb5wudY7Vchbjx5-aT6Y1qXa8Fplpd94YPe0SHAQfV2xXTrnG-w63P4UB2rziqRgEoiSBWVhmYRYvK-1rmyJ8wMuHv7KnE6qvX5gX52s5ZokFSFrG0HIIReWBGWoM3dmLsZ-Lno0TDUTlV9ZAPriUBshZO34mLYC34-z6rcm0O5Kj3zN07cGpbRfbko4ypR4ZyKPGexM8D1AfaFW2DefQ..&type=2&query=%E6%9D%8E%E7%8E%B0&k=1&h=f
能清楚的看到后者比前者多了&k=1&h=f,这部分是在列表页中的中实现的。

当鼠标点击 a 标签对应的标题时,对其对应的链接进行此处理,得到一个相当于加密后的链接,然后在fiddler中我们可以发现正是这个链接的请求返回了一个对应微信文章的链接。

但我们直接发送这个链接的时候,会出现 这种情况
这时候我们就要考虑是否是微信端进行了反扒,或者是其他,然后我们通过正常方式进入微信文章页面,发现正常进入的情况下,该请求的请求头 ,cookie等信息一应俱全。OK,那我们就把这些信息都加上。

从fiddler中我们能够发现我们缺少了什么,但是这其中这么多参数,是必须都得加上么,当然不是,不过这就需要我们去测试了。最终我发现要想得到最后的文章链接,发送/link?url这个请求时,请求头,cookie中的SNUID,与Referer这三个参数缺一不可,请求头让你模拟浏览器发送请求,避免被反扒直接干掉,剩下两个参数就是用来突破反扒让我们能够成功获取信息的。

噢噢噢噢微信又改了那么点东西。在前面加了一个这,无聊
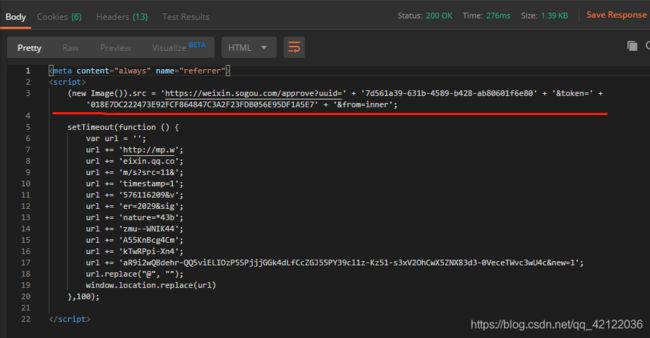
请求头与Referer我们可以直接得到,但cookie的获取就要我们去找了,然后我们能够发现搜狗微信的其他同级域名与列表页的Cookie中的SNUID与我们需要的SNUID参数是相同的,将这个三个参数添加入请求的header中,发送请求。这样我们就能够轻松的获取到微信文章的连接了。另外,为了避免被微信端封禁ip,最好使用代理,但最好不要使用开放代理,亲测,效果极差,私密代理效果比较好。我之前就因为使用的开发代理导致爬取效果极差,还找不到问题。


核心代码: (2019-12-20更新)
# coding: utf-8
import requests
import traceback
import random
import re
import time
from collections import deque
import MySQLdb
# 忽略SSL证书验证
requests.packages.urllib3.disable_warnings()
# 请求头随机
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/61.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
]
Headers = {
"Host": "weixin.sogou.com",
"Connection": "close",
"Upgrade-Insecure-Requests": "1",
"Referer": "https://weixin.sogou.com/weixin",
}
class DbConnection(object):
def __init__(self):
# 当前类的实例
self.conn = None
def open(self):
child = type(self) # child --->
print(child)
if self.conn is None:
self.conn = MySQLdb.connect(
host=child.host,
port=child.port,
user=child.user,
passwd=child.passwd,
db=child.db,
charset="utf8"
)
return self.conn
class DbBi(DbConnection):
host = '127.0.0.1'
port = 3306
user = 'root'
passwd = 'xxxx'
db = 'workcarl'
def get_proxy():
for i in range(20):
print "get proxy try time:", i + 1
proxy_url = requests.get(
"xxxx" # 代理api 高匿 https 推荐 快代理或蘑菇代理
).text
if proxy_url.find('code') > 0:
time.sleep(10)
continue
proxy = {"https": "https://%s" % proxy_url.replace(' ', '')}
try:
res = requests.get("https://www.baidu.com/", proxies=proxy, timeout=3)
print proxy
print res.status_code
return proxy
except:
time.sleep(5)
continue
return None
# 请求发送时必须得带上
def get_snuid(proxy, ua):
first_urls = [
"https://weixin.sogou.com/weixin?type=2&query=%E7%8E%8B%E6%BA%90",
"https://weixin.sogou.com/weixin?type=2&query=%E6%9C%B1%E4%B8%80%E9%BE%99",
"https://weixin.sogou.com/weixin?type=2&query=%E7%8E%8B%E4%B8%80%E5%8D%9A",
"https://weixin.sogou.com/weixin?type=2&query=%E8%82%96%E6%88%98",
"https://weixin.sogou.com/weixin?type=2&query=%E8%B5%B5%E4%B8%BD%E9%A2%96"
]
headers = {'User-Agent': ua}
url = random.choice(first_urls)
rst = requests.get(url=url, proxies=proxy, headers=headers)
pattern = r'SNUID=(.*?);'
# snuid为发送请求时必带参数
snuid = re.findall(pattern, str(rst.headers))
return snuid
# 获取临时链接
def get_real_url(url, proxy):
try:
snuid = get_snuid(proxy, random.choice(user_agents))
if snuid != None and len(snuid) > 0:
time.sleep(0.5)
Headers['User-Agent'] = random.choice(user_agents)
Headers['Cookie'] = "SNUID={}".format(snuid[0])
requests.packages.urllib3.disable_warnings()
res = requests.get(url, headers=Headers, proxies=proxy, timeout=5, verify=False)
url_text = re.findall("\'(\S+?)\';", res.text, re.S)
base_url = ''.join(url_text)
i = base_url.find("http://mp.weixin.qq.com")
if i > 0:
res.close()
article_url = base_url[i:len(base_url)]
print article_url
return article_url
else:
return None
else:
print 'get snuid is none'
return None
except Exception, e:
print str(e.message)
print(time.strftime('%Y-%m-%d %H:%M:%S'))
return None
# 拿到中转链接 link?url=......
def getFirst_url():
conn = DbBi().open()
cursor = conn.cursor()
cursor.execute("SET NAMES utf8")
# 根据微信文章发布时间查过去三小时内最新发布的
sql = "select * from wechat_search_texts where crawled_at > DATE_SUB(now(), INTERVAL 3 HOUR) and article_time > DATE_SUB(DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00'), INTERVAL 6 Hour)"
try:
cursor.execute(sql)
conn.commit()
dataset = cursor.fetchall()
except:
traceback.print_exc()
conn.rollback()
conn.close()
return dataset
# 烦人的单双引号
def baoli(cc):
sc = cc.replace("'", "\\\'").replace('"', '\\\"')
return sc
# 保存获取到的微信文章临时链接
def ins_new_url(wechat):
conn = DbBi().open()
cursor = conn.cursor()
cursor.execute("SET NAMES utf8")
sql = """
replace into wechat_new_texts (code,article_time,author,summary,title,url,sort)
values ('%s','%s','%s','%s','%s','%s', %s)
""" % (wechat[1], wechat[2], baoli(wechat[3]), baoli(wechat[4]), baoli(wechat[5]), wechat[6], wechat[8])
try:
cursor.execute(sql)
except:
traceback.print_exc()
try:
conn.commit()
except:
traceback.print_exc()
conn.rollback()
conn.close()
# 统计代理 ip 可用次数
def ins_ip_count(proxy, count):
conn = DbBi().open()
cursor = conn.cursor()
cursor.execute("SET NAMES utf8")
sql = """
insert into proxy_count (proxy,count)
values('%s', '%s')
""" % (proxy, count)
try:
cursor.execute(sql)
except:
traceback.print_exc()
try:
conn.commit()
except:
traceback.print_exc()
conn.rollback()
conn.close()
def del_before():
conn = DbBi().open()
cursor = conn.cursor()
cursor.execute("SET NAMES utf8")
sql = """
delete from wechat_new_texts where crawled_at < DATE_SUB(now(), INTERVAL 12 HOUR);
"""
try:
cursor.execute(sql)
conn.commit()
except:
traceback.print_exc()
conn.rollback()
conn.close()
if __name__ == '__main__':
wechats = list(getFirst_url())
if len(wechats) == 0:
print "当前无需要处理的链接"
else:
proxy = get_proxy()
if proxy is None:
proxy = get_proxy()
count = 0
wechat_queue = deque(wechats)
while len(wechat_queue) >= 1:
wechat = list(wechat_queue.popleft())
wechat.append(0)
try:
before_wechat = wechat
i = wechat[6].index("&code")
wechat[1] = wechat[6][i + 6:len(wechat[6])]
wechat[6] = wechat[6][:i]
real_url = get_real_url(wechat[6], proxy)
# 用以记录代理ip可用次数
ip = str(proxy['https'].encode(encoding='UTF-8'))
if real_url != None:
wechat[6] = real_url.encode('utf8')
count += 1
ins_new_url(wechat)
if len(wechats) == 1:
ins_ip_count(ip, count)
else:
if wechat[9] < 2:
before_wechat[9] += 1 # 每个链接两次机会获取
wechat_queue.append(tuple(before_wechat))
ins_ip_count(ip, count)
count = 0
proxy = get_proxy()
continue
else:
continue
except Exception, e:
print str(e.message)
continue
# del_before()