机器学习知识点总结(2)——优化器
机器学习知识点总结(2)——优化器
- 前言
- 有监督学习的损失函数
-
- 分类问题中的损失函数
-
- 0-1损失函数
- Hinge损失函数
- Logistic损失函数
- 交叉熵损失函数
- 回归问题中的损失函数
-
- 平方损失函数
- 绝对损失函数
- Huber损失函数
- 机器学习中常用的优化算法
-
- 凸优化基本概念
- 参考链接
前言
机器学习算法 = 模型表征 + 模型评估 + 优化算法,其中,优化算法所做的事就是在模型表征空间中找到模型评估指标最好的模型。不同的优化算法对应的模型表征和评估指标不尽相同。比如:
- 支持向量机对应的模型表征和评估指标为线性分类模型和最大间隔;
- 逻辑回归对应的模型表征和评估指标为线性分类模型和交叉熵。
机器学习界有一群炼丹师,他们每天的日常是:拿出药材(数据),架起八卦炉(模型),点着三味真火(优化算法),就咬着蒲扇等着丹药的出炉了。不过,当过厨子的都知道,同样的食材,同样的菜谱,但火候不一样了,这出来的口味可是千差万别。火小了夹生,火大了易糊,火不匀则半生半糊。
机器学习也是一样,模型优化算法的选择直接关系到最终模型的性能。有时候效果不好,未必是特征的问题或者模型设计的问题,很可能就是优化算法的问题。
说到优化算法,入门级必从SGD学起,老司机则会告诉你更好的还有AdaGrad/AdaDelta,或者直接无脑用Adam。可是看看学术界的最新paper,却发现一众大神还在用着入门级的SGD,最多加个Moment或者Nesterov ,还经常会黑一下Adam。比如 UC Berkeley的一篇论文《The Marginal Value of Adaptive Gradient Methods in Machine Learning》在Conclusion中写道:
Despite the fact that our experimental evidence demonstrates that adaptive methods are not advantageous for machine learning, the Adam algorithm remains incredibly popular. We are not sure exactly as to why ……
有监督学习的损失函数
机器学习算法的关键一环是模型评估,而损失函数定义了模型的评估指标。可以说,没有损失函数就无法求解模型参数。不同的损失函数优化难度不同,最终得到的模型参数也不同,针对具体的问题需要选取合适的损失函数。
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
在有监督学习中,损失函数刻画了模型和训练样本的匹配程度。假设训练样本的形式为 ( x i , y i ) (x_{i},y_{i}) (xi,yi),其中, x i ∈ X x_{i}\in X xi∈X表示第 i i i个样本点的特征, y i ∈ Y y_{i}\in Y yi∈Y表示该样本点的标签。参数为 θ \theta θ的模型可以表示为函数 f ( ∙ , θ ) f(\bullet,\theta) f(∙,θ) : X :X :X → \to → Y Y Y ,模型关于第 i i i样本点的输出为 f ( x i , θ ) f(x_{i},\theta) f(xi,θ)。
分类问题中的损失函数
为了刻画模型输出与样本标签的匹配程度,定义损失函数 L ( ∙ , ∙ L(\bullet,\bullet L(∙,∙) : : : Y × Y Y×Y Y×Y → \to → R R R, L ( f ( x i , θ ) , y i ) L(f(x_i,\theta),y_i) L(f(xi,θ),yi)越小,表明模型在该样本点匹配得越好。
0-1损失函数
对于二分类问题, Y = { − 1 , 1 } Y=\lbrace-1,1 \rbrace Y={ −1,1},我们希望 s i g n f ( x i , θ ) = y i signf(x_i,\theta)=y_i signf(xi,θ)=yi,最自然的损失函数为0-1损失,即
(1) L 0 − 1 ( f , y ) = 1 f y ≤ 0 L_{0-1}(f,y)=1_{fy \leq 0} \tag{1} L0−1(f,y)=1fy≤0(1)
其中, 1 p 1_p 1p为指示函数(Indicator Function),当且仅当P为真时取值为1,否则取值为0。该损失函数能直观地刻画分类的错误率,但是由于其非凸、非光滑的特点,使得算法很难直接对该函数进行优化。
Hinge损失函数
0-1损失函数的一个代理损失函数为Hinge损失函数:
(2) L h i n g e ( f , y ) = m a x { 0 , 1 − f y } L_{hinge}(f,y)=max\lbrace0,1-fy\rbrace \tag{2} Lhinge(f,y)=max{ 0,1−fy}(2)
Hinge损失函数是0-1损失函数相对紧的凸上界,且当 f y ≥ 1 fy \geq 1 fy≥1时,该函数不对其做任何惩罚。由于Hinge损失在 f y = 1 fy=1 fy=1处不可导,因此不能用梯度下降法进行优化,而是用次梯度下降法(Subgra-
dient Descent Method)。
Logistic损失函数
0-1损失函数的另一个代理损失函数为Logistic损失函数:
(3) L L o g i s t i c ( f , y ) = l o g 2 ( 1 + e x p ( − f y ) ) L_{Logistic}(f,y)=log_2(1+exp(-fy)) \tag{3} LLogistic(f,y)=log2(1+exp(−fy))(3)
Logistic损失函数也是0-1损失函数的凸上界,且该函数处处光滑,因此可以用梯度下降法进行优化。但是,该损失函数对所有的样本点都有所惩罚,因此对异常值相对更敏感一些。
交叉熵损失函数
当预测值 f ∈ [ − 1 , 1 ] f\in[-1,1] f∈[−1,1]时, 另一个常用的代理损失函数为交叉熵(Cross Entroy)损失函数:
(4) L c r o s s e n t r o y ( f , y ) = − l o g 2 ( 1 + f y 2 ) L_{crossentroy}(f,y)=-log_2(\frac{1+fy}{2}) \tag{4} Lcrossentroy(f,y)=−log2(21+fy)(4)
交叉熵损失函数也是0-1损失函数的光滑凸上界。这四种损失函数的曲线如下图所示:

源码如下:
import numpy as np
import math
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 5))
x = np.linspace(start=-2, stop=3,num =1001,dtype=np.float)
x1=np.linspace(start=-1, stop=1,num =21,dtype=np.float)
logi = np.log(1 + np.exp(-x))/math.log(2)
cross_entropy = -np.log2((1+x1)/2)
boost = np.exp(-x)
y_01 = x < 0
y_hinge = 1.0 - x
y_hinge[y_hinge < 0] = 0
#S_values = [x=3]
plt.plot(x, logi, 'r-', mec='k', label='Logistic Loss', lw=2)
plt.plot(x, y_01, 'g-', mec='k', label='0/1 Loss', lw=2)
plt.plot(x, y_hinge, 'b-',mec='k', label='Hinge Loss', lw=2)
#plt.plot(x, boost, 'm--',mec='k', label='Adaboost Loss',lw=2)
plt.plot(x1, cross_entropy, 'k--',mec='k', label='Cross_entropy Loss',lw=2)
plt.vlines(-1, 0,5,colors = "k", linestyles = "dashed")
plt.vlines(1, 0,5,colors = "k", linestyles = "dashed")
plt.grid(True, ls='--')
plt.legend(loc='upper right')
plt.title('损失函数')
plt.show()
回归问题中的损失函数
对于回归问题, Y = R Y=R Y=R,我们希望 f ( x i , θ ) ≈ y i f(x_i,\theta) \approx y_i f(xi,θ)≈yi,常用的损失函数包括如下:
平方损失函数
(5) L s q u r e ( f , y ) = ( f − y ) 2 L_{squre}(f,y)=(f-y)^2 \tag{5} Lsqure(f,y)=(f−y)2(5)
平方损失函数时光滑函数,能够用梯度下降法来进行优化。然而,当预测值距离真实值越远时,平方损失函数的惩罚力度越大,因此它对异常类比较敏感。
绝对损失函数
为了解决平方损失函数对异常类比较敏感的问题,可采用绝对损失函数:
(6) L a b s o u l t e ( f , y ) = ∣ f − y ∣ L_{absoulte}(f,y)= \vert{f-y}\vert \tag{6} Labsoulte(f,y)=∣f−y∣(6)
绝对损失函数相当于在做中值回归,相比做均值回归的平方损失函数,绝对损失函数对异常点更鲁棒一些。但是,绝对损失函数在 f = y f=y f=y处无法求导数。
Huber损失函数
综合考虑可导性和对异常点的鲁棒性,可以采用Huber损失函数:
(7) L H u b e r ( f , y ) = { ( f − y ) 2 , ∣ f − y ∣ 2 ≤ δ 2 δ ∣ f − y ∣ − δ 2 , ∣ f − y ∣ > δ L_{Huber}(f,y)=\left\{\begin{matrix} (f-y)^2, &\vert{f-y}\vert^2\leq \delta \\ 2\delta\vert{f-y}\vert-\delta^2,& \vert{f-y}\vert \gt \delta \end{matrix}\right.\tag{7} LHuber(f,y)={ (f−y)2,2δ∣f−y∣−δ2,∣f−y∣2≤δ∣f−y∣>δ(7)
Huber损失函数在 ∣ f − y ∣ \vert{f-y}\vert ∣f−y∣较小时为平方损失,在 ∣ f − y ∣ \vert{f-y}\vert ∣f−y∣较大时为线性损失,处处可导,且对异常点鲁棒。这三种损失函数的曲线如图2所示:
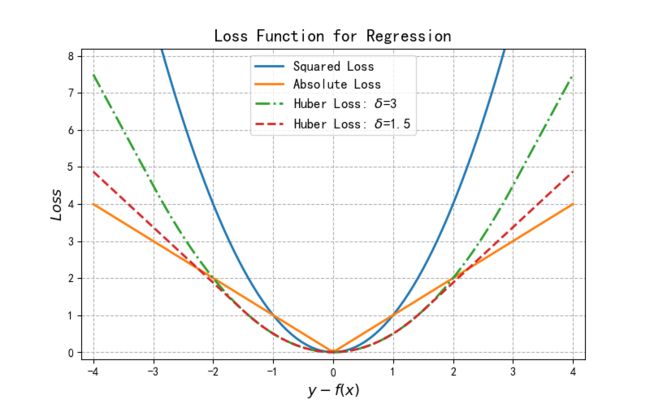
源码如下:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 5))
def huber(res, delta):
res = abs(res)
return (res<=delta)*(res**2/2) + (res>delta)*(delta*res-delta**2/2)
plt.axis([-4.2,4.2,-0.2,8.2])
x = np.linspace(-4,4,100)
plt.plot(x, x**2, label="Squared Loss", lw=2)
plt.plot(x,np.where(x>=0,x,-x), label="Absolute Loss", lw=2)
plt.plot(x,huber(x, 3), label="Huber Loss: $\delta$={}".format(3),lw=2, linestyle="-.")
plt.plot(x,huber(x, 1.5), label="Huber Loss: $\delta$={}".format(1.5),lw=2,linestyle="--")
plt.grid(True, ls='--')
plt.legend(loc='upper center', fontsize=12)
plt.xlabel("$y-f(x)$",fontsize=13)
plt.ylabel("$Loss$",fontsize=13)
plt.title("Loss Function for Regression",fontsize=15)
机器学习中常用的优化算法
参考链接:Optimization for Deep Learning Highlights in 2017
大部分机器学习模型的参数估计问题都可以写成优化问题。机器学习模型不同,损失函数不同,对应的优化问题也各不相同。了解优化问腿的形式和特点,能帮助我们更有效地求解问题,得到模型参数,从而达到学习的目的。
凸优化基本概念
凸函数定义:函数 L ( ⋅ ) L(\cdot) L(⋅)是凸函数当且仅当对定义域中的任意两点 x , y x,y x,y和任意实数 λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ∈[0,1]总有:
(8) L ( λ x + ( 1 − λ ) y ) ≤ λ L ( x ) + ( 1 − λ ) L ( y ) L(\lambda x+(1-\lambda)y)\leq\lambda L(x)+(1-\lambda)L(y) \tag{8} L(λx+(1−λ)y)≤λL(x)+(1−λ)L(y)(8)
该不等式的一个直观解释是,凸函数曲面上任意两点连接而成的线段,其上的任意一点都不会处于该函数曲面的下方,如下图所示:
参考链接
1.https://zhuanlan.zhihu.com/p/58883095