浏览器网络相关:
OSI的七层模型、TCP/IP四层模型
- TCP的三次握手(为什么要三次握手,一次呢?四次挥手是什么?)
- 输入URL到页面加载完成需要哪几步?
- TCP和UDP的区别
- 报文
- HTTP的特点?(快速灵活,为什么用http不用其他的?)
- HTTP有哪些方法?常用有哪些?
- get和post的区别是什么?
- options的作用?
- HTTP状态码?
- http1和http2的区别?
- 讲出至少五种解决跨域的办法,jsonp(写一个简易jsonp),CORS
- jsonp的优缺点?
- http和https的区别
- http缓存都有哪些,强缓存和协商缓存有什么区别
- localStorage 与 sessionStorage 与cookie的区别总结
- 什么是同源策略,为什么出现跨域问题?请求方式,域名和端口不同
- 什么是事件委托,事件捕获
- DNS缓存,原理
- WebSocket属于什么(简单应用API),原理
OSI的七层模型、TCP/IP四层模型
- TCP的三次握手(为什么是三次握手,一次呢?四次挥手是什么?)
- 输入URL到页面加载完成需要哪几步?
- TCP和UDP的区别
- OSI的七层模型:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
- TCP/IP:网络接口层/链路层、网络互联层、传输层、应用层。
1.1 TCP三次握手
https://www.jianshu.com/p/f1b3decb07f8
- 客户端向服务器发送SYN包,等待服务器确认;
- 服务器收到SYN包,需要确认后向客户端发起一个SYN包;
- 客户端收到服务器的SYN+ACK包后则向服务器发起确认包,完成三次握手。
为什么不能一次或两次?
因为客户端和服务器都要做好发送数据的准备后,才能建立通信。防止了服务器端的一直等待而浪费资源。
tcp是一个全双工的协议,意思是客户端和服务端之间的通信可以同时来回流动,为了保证通信的可靠性以及确定对方能收到自己的请求,tcp采用半关闭原则,意思是在收到一个请求后必须发送回复请求,只通信一次或者两次无法确定对方是否收到请求
- 1.1 四次挥手其性质为终止协议
- TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送。
- 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
- 服务器关闭客户端的连接,发送一个FIN给客户端。
- 客户端发回ACK报文确认,并将确认序号设置为收到序号加1。
保证数据接收完整。
1.2 输入URL到页面加载完成需要哪几步?
- 输入网址URL
- 是url还是字符串 搜索引擎
- 缓存机制,判断本地是否有缓存,
- 没有缓存,DNS解析(解析得到IP),https建立TLS连接
- 解析的时候,服务器负载均衡
- TCP连接(三次握手)
- 发送http请求(请求方法,get、post)
- 接受响应,判断状态码选择处理方式(返回http状态码)
- 判断缓存
- 解码
- 渲染
- 连接结束(四次挥手)
- 下载html dom树,下载css OM树,结合rander树
参考:https://zhuanlan.zhihu.com/p/34288735
https://mp.weixin.qq.com/s?__...
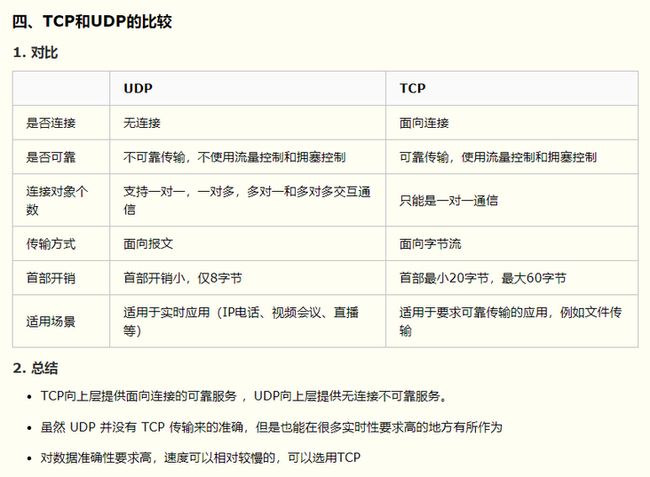
1.3 TCP和UDP的区别
- TCP:一对一;面向连接;面向字节流;传输大量数据;速度慢;(web开发,http)
- 优点:可靠,通过TCP连接传输的数据无差错、不丢失、不重复,并且能够按序到达。
- UDP:一对多;面向非连接(发送数据前不需要建立连接);面向报文;传输少量数据,速度快;(应用:直播,视频,应用程序)
- 缺点:不保证交付可靠,丢包。
报文
1. 请求报文(发送请求的报文):
- 请求头Request Headers:
- Accept :请求报文可通过一个“Accept”报文头属性告诉服务端 客户端接受什么类型的响应。
- Cookie :客户端的Cookie就是通过这个报文头属性传给服务端的哦!
- Referer :表示这个请求是从哪个URL过来的
- Cache-Control :对缓存进行控制,如一个请求希望响应返回的内容在客户端要被缓存一年,或不希望被缓存就可以通过这个报文头达到目的。
- 请求行:
- HTTP方法,get/post请求
- HTTP协议
- 请求体:
2. 响应报文(服务端相应的报文)
状态行,响应首部,内容实体,
HTTP协议的主要特点?(快速灵活,为什么用http不用其他的?)
http是超文本传输协议,应用层协议的一种,应用层协议:DNS、FTP、SMTP、HTTP、SNMP、Telnet。
特点:简单快速灵活,属于应用层的面向对象的协议,基于TCP的可靠传输。
http是不保存状态的协议(无状态协议)
HTTP有哪些方法?常用有哪些?
- GET(获取)
- POST(传输)
- PUT(更新)
- DELETE(删除)
- HEAD(获取报文首部)
- OPTIONS(询问)
- CONNECT
get和post的区别是什么?
- 数据类型:get只接受ASCII字符,而post没有限制,允许二进制。
- 前进/后退:get在浏览器回退/刷新时是无害的,而post会再次提交请求。
- 请求长度:get长度取决于浏览器窗口的长度,post长度不限制
- 缓存:get能被缓存,post不能。
- 请求次数:get请求一次(请求头请求体一起发送),post请求两次(先发送请求头,等100 continue,然后再发送请求体,连着发送)。
- 安全性:post比get 更安全,因为GET参数直接暴露在URL上,POST参数在HTTP消https息主体中,而且不会被保存在浏览器历史或 web 服务器日志中,。
- 编码格式:post支持多种编码格式 gbk utf-8
- GET产生一个TCP数据包,浏览器会把http header 和 data 一并发送
- POST产生两个TCP数据包(除了FireFox)先发送header,浏览器响应100 continue,浏览器再发送data
specification : 相关的RFC,
options的作用?
- 检测服务器所支持的请求方法
- CORS中的预检请求(检测某个接口是否支持跨域)
HTTP状态码,http响应,信息响应?
- 1开头:接受继续处理,(100 continue)
- 2开头:表示成功 (200成功并返回 201已创建 202接收 203成功未授权 204成功无内容)
- 3开头:重定向(301永久重定向,302临时重定向,304有缓存不用更新)
- 4开头:客户端错误(400语法错误,403禁止被访问,没有权限,404资源页面不存在)
- 5开头:服务端错误(500后端服务器挂了,501服务器不支持无法处理,502网关错误,后台建立连接超时,503服务器内部错误,504后台未建立连接超时,505不支持http协议版本)

https://mp.weixin.qq.com/s?__...
URI 一个资源文件的不同辨表示方法
- URI:统一资源标识符
- URL:统一资源定位符
- URN:统一资源名称
串行连接 持久连接 管道化持久连接 HTTP2.0多路复用
- 串行连接: http1.0版本,每次发请求都要建立新的TCP连接,每次通信后都要断开TCP连接。
- 持久连接:http1.1,连段没有提出断开连接,则保持持久TCP连接。
- 管道化持久连接: 不用等待响应返回而发送下个请求并按数据返回响应。
- HTTP2.0多路复用:http2.0
- websocket: HTML5,客户端主动向服务器发请求,建立连接后。
http1和http2的区别? 超文本传输协议
影响一个 HTTP 网络请求的因素主要有两个:带宽和延迟。
浏览器为每个域名最多同时维护6条TCP持久连接。
影响http1.1效率的因素是TCP启动慢,多条TCP竞争带宽,出现队头阻塞的问题,为了解决这个问题,http2采用通过引进二进制分帧层,多路复用,服务器推送,头部压缩。
1)在HTTP 1.0中,客户端的每次请求都要求建立一次单独的连接,在处理完本次请求后,就自动释放连接。
2)在HTTP 1.1中则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。采用了keep-alive。
http1的主要问题:
- 第一个原因,TCP 的慢启动,因为三次握手。
- 第二个原因,同时开启了多条 TCP 连接,那么这些连接会相互竞争固定的带宽。
- 第三个原因,HTTP/1.1 队头阻塞的问题,只有一个TCP管道。
http1.1:
增加了持久连接;
浏览器每个域名同时维护6个TCP持久连接。
缺点:对带宽的利用率不强,(每秒最大发送接收的字节数)
http2:
- 解决方案:要解决一个域名只使用一个TCP 长连接和消除队头阻塞问题。
- 优点:可以设置请求的优先级,支持服务器推送,大幅度的提升了 web 性能。
- 问题:队头阻塞无法解决,丢包率增加()
区别:http2采用通过引入二进制分帧层,
- 多路复用机制(MultiPlexing):在TLS层,增加一个二进制分帧层,
TLS协议是会话层的安全传输协议,
即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
- 新的二进制格式(Binary Format),将请求分帧传输,可以进行二进制分帧层,HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
二进制分帧层:分段带ID传输。
- 头部压缩,对请求头和响应头进行压缩,减小体积。
- 服务器推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
- 设置请求的优先级:
- HTTP2的持久连接和管线化:
http3:
HTTP3:基于UDP协议推出一个QUIC协议,
在UDP基础上新增多路复用,0-RTT,使用TLS1.3加密,流量控制,有序交付,重传等。
- 避免包阻塞:
- 快速重启会话:
什么是浏览器同源策略?为什么会出现跨域问题?(请求方式,域名和端口不同)
- 一种安全策略,保护本地数据,为了防止XSS、CSFR等攻击。
- 同源的定义:协议(请求方式)、域名、端口相同。因为存在浏览器同源策略,所以才会有跨域问题。
- 同源策略分为两种:
DOM 同源策略:禁止对不同源页面 DOM 进行操作。这里主要场景是 iframe 跨域的情况,不同域名的 iframe 是限制互相访问的。
XMLHttpRequest 同源策略:禁止使用 XHR 对象向不同源的服务器地址发起 HTTP 请求。
浏览器同源策略:https://www.cnblogs.com/laixiangran/p/9064769.html
了解预检请求嘛?
- 跨域是指一个域下的文档或脚本试图去请求另一个域下的资源
- 防止XSS、CSFR等攻击, 协议+域名+端口不同
- jsonp; 跨域资源共享(CORS)(Access control); 服务器正向代理等
预检请求: 需预检的请求要求必须首先使用 OPTIONS 方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。"预检请求“的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响
代理服务器
代理服务器:客户端和服务端之间的中间商,可以作为缓存服务器。
- 正向代理:
- 反向代理:
- 反向代理解决跨域问题:两个服务器之间通信。
本地服务器在浏览器向本地服务发起请求》本地代理转发》目标服务器》响应数据后通过代理伪装成本地服务器请求的返回值》浏览器接收到目标服务器的数据
- vue的proxyTable的作用,解决跨域问题。怎么实现。
与服务器联调的时候 vue.config.js, proxy设置请求反向代理
缓存服务器:频繁访问网络内容。提高访问速度。浏览器和原服务器之间的中间服务器。
解决跨域的办法,常用:
jsonp 跨域:
jsonp 跨域通过script的src获取callback请求资源进行文件的传输,然后返回一个函数调用;
- 优点:兼容性好(兼容IE)
- 缺点:只支持get一种请求,不是官方API,容易受到xss攻击。
- 原理:script的src属性默认支持跨域
跨域资源共享(CORS):修改响应头
- 跨域资源共享(CORS)允许浏览器跨源服务器,需要浏览器和服务器同时支持,需要在服务器上配置Access-Control-Allow-Origon。
*不能带cookie
- 简单请求:请求方式:get、post、head
- 非简单请求:先发一次预检请求(options):put、delete
options是预检请求,在真正的请求发送出去之前,浏览器会先发送一个options请求向服务询问此接口是否允许我访问
浏览器在当前真实请求是非简单请求且跨域的情况下会发起options预检请求
与JSONP相比:
- JSONP只支持get请求,cors支持所有请求(get、post);
- JSONP支持性好,兼容老版本浏览器。
参考:http://www.ruanyifeng.com/blog/2016/04/cors.html
hash: window.location
hash:location.hash + iframe;
postMessage:
postMessage()方法允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本档、多窗口、跨域消息传递。
Awindow.postMessage(data,origin)
A窗口向B窗口发送请求:Awindow.postMessage('data','http://B.com')
WebSocket协议跨域:
WebSocket协议跨域:HTML5一种新的持久化协议,用于H5聊天,即时线上跨域。
实时聊天,基于TCP协议,短轮询,浪费带宽,
长轮询,
http单向数据流,websocket链接客户端和服务器,在ws里
scoket.io
WebSocket心跳检测
不常用:
nginx反向代理接口跨域:
同源策略是浏览器的安全策略,不是HTTP协议的一部分。服务器端调用HTTP接口只是使用HTTP协议,不会执行JS脚本,不需要同源策略,也就不存在跨越问题
document.domain + iframe跨域:
两个页面都通过js强制设置document.domain为基础主域,就实现了同域.但是仅限主域相同,子域不同的跨域应用场景
http和https的区别
http:因为http是无状态,明文传输的,容易造成中间人攻击,所以在http协议中加入安全层,加入SSL/TLS安全层,增加加密/解密的方式,相比http协议更安全。
SSL/TLS安全层:对发起 HTTP 请求的数据进行加密操作和对接收到HTTP 的内容进行解密操作。
TLS/SSL 的功能实现主要依赖于三类基本算法:散列函数 、对称加密和非对称加密散列函数 ,散列算法,MD5
RSA算法
https:安全,请求时间长,加载慢,花钱,证书
https安全性:
- 对称加密:加密和解密使用的密钥是相同的
- 传输方式:
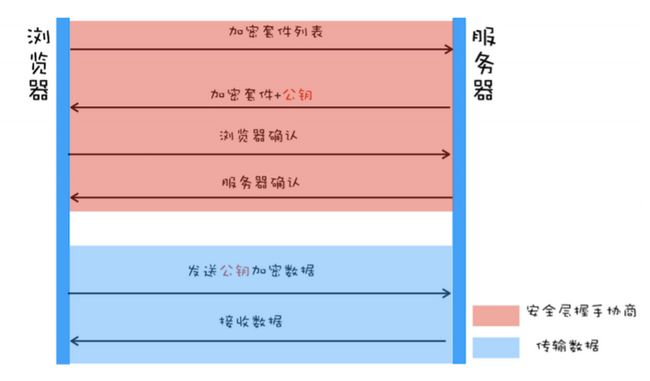
浏览器:发送加密套件列表和一个随机数 client-random,
服务器:从加密套件列表中选取一个加密套件,还会生成一个随机数 service-random,并将service-random 和加密套件列表返回给浏览器。最后浏览器和服务器分别返回确认消息。
- 缺点:容易被破解

- 非对称加密:A、B两把密钥,公钥,私钥
缺点:效率低,影响速度,无法保证服务器到浏览器的安全
- 对称加密+非对称加密:用非对称加密的方式 传输 对称加密里的密钥,
非对称加密使用时,生成pre-master(两个随机数计算)。
优点:速度快+安全。

- 添加数字证书(消费):向CA证书机构申请数字证书,包含数字签名,非对称加密的公钥和个人信息。
证书的作用:一个是通过数字证书向浏览器证明服务器的身份,另一个是数字证书里面包含了服务器公钥。
证书也有公钥和私钥。证书加密一次,
CA证书用公钥,hash值,。
加密套件列表:客户端支持的加密和非对称加密的方式

- 浏览器如何验证数字证书
- 有了 CA 签名过的数字证书,当浏览器向服务器发出请求时,服务器会返回数字证书给浏览器。浏览器接收到数字证书之后,会对数字证书进行验证。
- 首先浏览器读取证书中相关的明文信息,采用 CA 签名时相同的 Hash 函数来计算并得到信息摘要 A;然后再利用对应 CA 的公钥解密签名数据,得到信息摘要 B;对比信息摘要 A 和信息摘要 B,如果一致,则可以确认证书是合法的,
- 即证明了这个服务器是极客时间的;同时浏览器还会验证证书相关的域名信息、有效时间等信息。
- 区别:
- HTTP 的URL 以http:// 开头,而HTTPS 的URL 以https:// 开头
- HTTP 是不安全的,而 HTTPS 是安全的
- HTTP 标准端口是80 ,而 HTTPS 的标准端口是443
- 在OSI 网络模型中,HTTP工作于应用层,而HTTPS 的安全传输机制工作在传输层
- HTTP 无法加密,而HTTPS 对传输的数据进行加密
- HTTP无需证书,而HTTPS 需要CA机构wosign的颁发的SSL证书
https是如何加密的?
密钥传输的过程,服务器做了什么事?浏览器做了什么事?密钥怎么传的?对称加密要怎么传?数字证书怎么校验?
常见加密算法有哪些?
浏览器缓存,强缓存和协商缓存有什么区别
https://mp.weixin.qq.com/s/Wvc0lkLpgyEW_u7bbMdvpQ
缓存位置:
- service worker:浏览器背后的独立线程,一般缓存
- memory chache:内存中的缓存,计算机内存
- Disk Cache:硬盘中的内存,速度慢
- Push Cache:推送缓存,http2,只在session中存在
- 缓存过程:
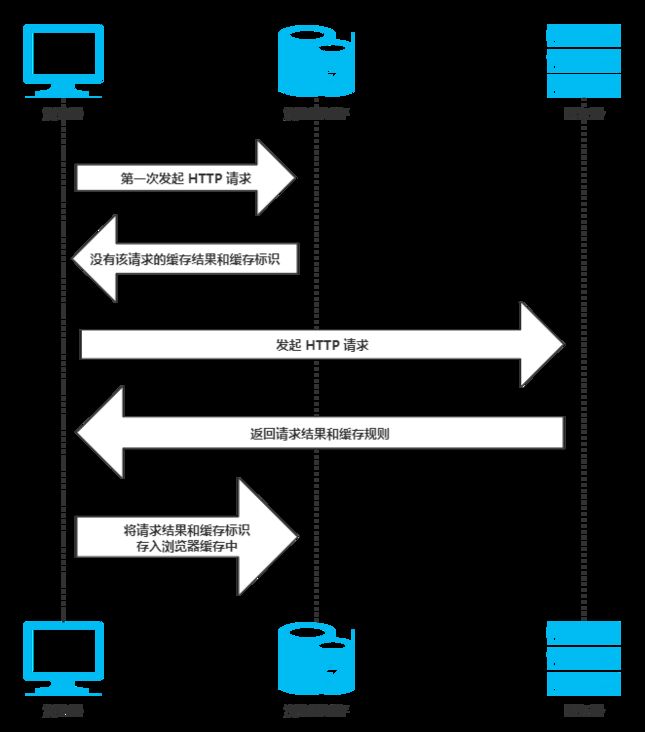
- 缓存机制:
- 缓存机制分为:强缓存和协商缓存
- 区别:是否发送请求,强缓存不发送请求,协商缓存至少发送一次请求。
- 优先级: Cache-Control > expires > Etag > Last-Modified
强缓存(本地缓存):不用跟服务器进行通信
- 缓存字段:Expires和Cache-Control
- Expires:绝对时间,资源失效的时间,
- Cache-Control:相对时间,资源缓存的最大有效时间
- Cache-Control的 max-age 优先级高于 Expires
协商缓存:由服务器来决定是否使用缓存,至少和服务器有一次通信
- 缓存字段:Last-Modified和ETag发送到服务器,确认资源是否更新。
- Last-Modified 表示本地文件最后修改日期
- ETag 是个标识,修没修改
- 判断是否过期,先走etags(http1生成的),再走Last-Modified。 ETag 优先级比 Last-Modified 高。
页面怎么进行强缓存和协商缓存?
如果缓存过期了,我们就可以使用协商缓存来解决问题。协商缓存需要请求,如果缓存有效会返回 304。
协商缓存需要客户端和服务端共同实现,和强缓存一样,也有两种实现方式。
Last-Modified 和 If-Modified-Since
If-Modified-Since 会将 Last-Modified 的值发送给服务器,询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来。

参考:https://zhuanlan.zhihu.com/p/64635421
如果浏览器命中强缓存,则不需要给服务器发请求;而协商缓存最终由服务器来决定是否使用缓存,即客户端与服务器之间存在一次通信。
在 chrome 中强缓存(虽然没有发出真实的 http 请求)的请求状态码返回是 200 (from cache);而协商缓存如果命中走缓存的话,请求的状态码是 304 (not modified)。 不同浏览器的策略不同,在 Fire Fox中,from cache 状态码是 304.
浏览器会获取该缓存资源的 header 中的信息,根据 response header 中的 expires 和 cache-control 来判断是否命中强缓存,如果命中则直接从缓存中获取资源。
如果没有命中强缓存,浏览器就会发送请求到服务器,这次请求会带上 IF-Modified-Since 或者 IF-None-Match, 它们的值分别是第一次请求返回 Last-Modified或者 Etag,由服务器来对比这一对字段来判断是否命中。IF-None-Match是false时 ,则服务器返回 304 状态码,
IF-None-Match是true时,走200
并且不会返回资源内容,浏览器会直接从缓存获取;否则服务器最终会返回资源的实际内容,并更新 header 中的相关缓存字段。


keep-alive:HTTP 长连接
- 是客户端和服务端的一个约定,如果开启 keep-alive,则服务端在返回 response 后不关闭 TCP 连接;同样的,在接收完响应报文后,客户端也不关闭连接,发送下一个 HTTP 请求时会重用该连接。
- http1.0默认关闭的,需要在http头加入"Connection: Keep-Alive”,才能启用Keep-Alive
- http1.0默认开启keep-alive。
- 浏览器默认开启keep-alive,
http缓存都有哪些,
https://juejin.im/post/68449036824551096[](https://juejin.im/post/684490...
- http缓存、websql、indexDB、cookie、localstorage、sessionstorage、application cache、cacheStorage、flash缓存
localStorage 与 sessionStorage 与cookie补充:
https://mp.weixin.qq.com/s?__...
https://zhuanlan.zhihu.com/p/159268611
cookie
localStorage
sessionStorage
存储大小
一般不超过4K
一般为5M
一般为5M
数据有效期
可设置失效时间,默认关闭浏览器失效
永久有效,除了手动清除
关闭页面失效
作用域
所有同源窗口共享
所有同源窗口共享
只在同浏览器共享
易用性
需要自己封装,原生的cookie接口不友好
原生接口可以接受,可以封装来对Object和Array有更好的支持
与服务端通信
每次会随http协议头带过去,cookie保存太多数据会带来性能问题
在请求时使用数据,不参与服务器通信
储存类型string
(补充:cookie通过http协议头带过去的)
indexDB存储大小无上限 储存类型键值对, 不能跨域 时效性
CSRF攻击 跨站请求伪造
https://mp.weixin.qq.com/s?__...
跨站伪造请求
- 概念:攻击者盗用你的身份,以你的名义发送恶意请求,比如:通过陌生连接,诱导用户点击。
CSRF如何产生的?
- 用户信息存在cookie中,黑客通过储存token
- 如何防止CSRF攻击?
- 在服务端做处理,尽量使用post请求,加入验证码,验证Referer
- 使用Cookie的SameSite属性:strict、lax(相对宽松)、none
- 验证来源地址:origin(不包含路径信息)和refer
- 加入CSRF token:
- 判断请求的来源:检测Referer(并不安全,Referer可以被更改)
- CSRF自动防御策略:同源检测(Origin 和 Referer 验证)。
- CSRF主动防御措施:Token验证 或者 双重Cookie验证 以及配合Samesite Cookie。
- 保证页面的幂等性,后端接口不要在GET页面中做用户操作。
判断origin,没有再判断验证refer字段,请求。
Origin Header
Referer Header
但是Origin在以下两种情况下并不存在:
IE11同源策略: 302重定向:
XSS攻击 跨站脚本攻击
XSS(Cross-Site Scripting,跨站脚本攻击)是一种代码注入攻击。攻击者在目标网站上注入恶意代码,当被攻击者登陆网站时就会执行这些恶意代码,这些脚本可以读取 cookie,session tokens,或者其它敏感的网站信息,对用户进行钓鱼欺诈,甚至发起蠕虫攻击等。
XSS 的本质是:恶意代码未经过滤,与网站正常的代码混在一起;浏览器无法分辨哪些脚本是可信的,导致恶意脚本被执行。由于直接在用户的终端执行,恶意代码能够直接获取用户的信息,利用这些信息冒充用户向网站发起攻击者定义的请求。
类型:
- 反射型XSS:通过 URL 传递参数,当用户点击一个恶意链接,或者提交一个表单,或者进入一个恶意网站时,注入脚本进入被攻击者的网站。Web服务器将注入脚本,比如一个错误信息,搜索结果等,未进行过滤直接返回到用户的浏览器上。
- 如何防御:转义对url的查询参数进行转义后再输出到页面。
- DOM 型 XSS:html,前端代码不规范。
- 如何防御:转义图片链接。
- 存储型XSS:数据库,将恶意代码提交到目标网站的数据库中。
- 如何防御:服务器接收到数据,在存储到数据库之前,进行转义/过滤、
- SQL 注入:
如何让预防xss攻击?
- 服务端过滤做验证,在服务端使用 HTTP的 Content-Security-Policy 头部来指定策略,或者在前端设置 meta 标签;
- 服务端设置 CSP:开启白名单
- 后端设置HttpOnly:HttpOnly解决的是XSS后的Cookie劫持攻击,只能降低受损范围
- 对输入的内容和长度做限制:只能增加 XSS 攻击的难度。
jsonp过滤同域的代码有漏洞
点击劫持
点击劫持:攻击者将需要攻击的网站通过iframe嵌入自己的网页中,诱导用户点击,隐藏了一个透明的iframe,用外层假页面诱导用户点击。
防御办法:
- deny
- frame busting
- 使用X-Frame-Options协议头:微软提供,用来防御利用iframe嵌套的点击劫持攻击
- same origin:同源下的iframe
- allow-from-origin:
中间人攻击
https对称加密,非对称加密,混合加密,证书最为有效防止中间人攻击。
https://blog.csdn.net/oZhuZhiYuan/article/details/106650944
cookie session token,为什么能通过cookie攻击,不能通过token攻击
https://mp.weixin.qq.com/s/diaE6WkB_UJxjuhLS9E20Q
- cookie存在浏览器 session存在服务器 token明文传输,没有固定存放的地方
- cookie不是很安全,session更安全。cookie容易被攻击。
- 设置cookie时间过期,使用session-destory销毁对话。
- 发送请求时会带cookie,不会自动带token
- token存储在cookie中,token可以防御 csrf攻击
- xss攻击

- token如何进行加密?

垃圾回收
V8 实现了准确式 GC,GC 算法采用了分代式垃圾回收机制。因此,V8 将内存(堆)分为新生代和老生代两部分。
新生代:
- 存活时间短,使用 Scavenge GC 算法
- 内存空间:from空间和to空间。
- 三次折叠继续使用的放在老生代里
- 清理的过程:对象区域和空闲区域进行翻转。
- 新声明放在对象区,使用频率比较低的放在空闲区
老生代:
- 存活时间长且数量多,使用:标记清除算法和标记压缩算法。
- to空间(占比大小超过25%),标记整理算法。
- 对象树形结构,根据引用指向 被调用的对象 没有被标记的会被清除。
- 空间不连续的会整合。
怎么解决全停顿?
- 垃圾清理走的主线程,清理垃圾会造成卡顿,为了防止卡顿,会将垃圾分为很多份清理。逐渐插在主线程内。
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时
让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称
为增量标记(Incremental Marking)算法。
跨标签页通讯

内存泄漏

1.全局变量引起
2.闭包
3.dom清空,事件没有清除
4.子元素存在引用
子元素还存在引用时,先把子元素释放再释放父元素,否则父元素无法释放。
被遗忘的计时器
如何避免内存泄漏
1.ESLint 检测代码检查非期望的全局变量。
2.使用闭包的时候,得知道闭包了什么对象,还有引用闭包的对象何时清除闭包。最好可以避免写出复杂的闭包,因为复杂的闭包引起的内存泄漏,如果没有打印内存快照的话,是很难看出来的。
3.绑定事件的时候,一定得在恰当的时候清除事件。在编写一个类的时候,推荐使用 init 函数对类的事件监听进行绑定和资源申请,然后 destroy 函数对事件和占用资源进行释放。
全局变量 没有被声明
无法被回收 属于内存泄漏
没有释放的内存
- 事件冒泡、事件捕获、事件委托: https://www.jianshu.com/p/9c279d7330c6