前言
本文记录学习爬取淘宝网站上各品类下的销量最高的商品数据代码实现过程,涉及使用selenium库中的webdriver操作GOOGLE浏览器进行登陆、搜索、点击按销量从高到底排序、获取页面内容并使用beautiful库解析的过程。
一、基本环境配置
python版本:python 3.8.3
编辑器:anaconda3下的spyder
浏览器版本:Google Chrome 87.0.4280.88
浏览器驱动器:本文通过selenium中的webdriver驱动浏览器模拟人的点击行为爬取信息的,因为还需要下载浏览器对应版本的驱动器,谷歌驱动器下载地址:
https://npm.taobao.org/mirrors/chromedriver
这个地址下有各类版本的驱动器,找到自己版本下的谷歌驱动器(我自己下载的版本是/87.0.4280.20),下载放置到谷歌的目录下,并将该路径添加到环境变量即可
二、使用步骤
1.引入库
代码如下(示例):
from bs4 import BeautifulSoup
from selenium import webdriver
#ActionChain是用来实现一些基础的自动化操作:比如鼠标移动、鼠标点击等,ActionChains可以实现一步操作多个步骤
from selenium.webdriver import ActionChains
import PIL
from PIL import Image
import time
import base64 #Base64编码是从二进制到字符的过程
import threading
import pandas as pd
主要库的作用:
BeautifulSoup:可以从HTML或XML文件中提取数据的python库,能够通过喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,本文主要用该库对webriver爬到的网页数据进行解析,获取想要的数据内容,具体介绍可以参照如下网址:
https://beautifulsoup.readthedocs.io/zh_CN/latest/
selenium.webdriver:一般python爬取网页数据时使用的是urllib中的urlopen方法,返回网页对象,并使用read方法获取url的html内容,然后再使用beautifulsoup结合正则表达式抓取某个标签内容,urlopen还可以实现带着登陆后的cookies访问网站内容而免去每次都要登陆的烦恼;但是urllib的局限处在于只能获取网页的静态html内容,网页中的动态内容是不包含在静态html中的,所以有的时候抓取的网站html信息与我们实际在网站中看到的html信息不一致。selenium模块可以获取动态网页生成的内容。
Image:Image.open()可以打开文件夹中的图片,本文用来打开下载至本地的淘宝登陆二维码,通过扫描打开大的图片二维码可以实现淘宝扫码登陆。
time:本文中通过使用time.sleep()方法可实现暂时休眠功能,防止访问速度过快被识别出为爬虫。
2.实际案例
登陆淘宝:
def login_first(self):
#淘宝首页链接 一开始使用https时request.get返回status_code为502
#pageview_url = 'http://www.taobao.com/?spm=a1z02.1.1581860521.1.CPoW0X' 类属性中已经定义
#PhantomJS与Chrome的差别在于Chrome可以启动浏览器,观察到代码操作的每一个步骤进行的页面操作PhantomJS模拟一个虚拟浏览器,即在不打开浏览器的前提下对浏览器进行操作
#driver = webdriver.PhantomJS()
#driver = webdriver.Chrome() 类属性中已经定义
#在get()步加载时间会很长 不知道是不是网络的问题,所以限制加载20秒以后停止加载
self.driver.set_page_load_timeout(40)
self.driver.set_script_timeout(40)
try:
self.driver.get(self.pagelogin_url)
except:
print("页面加载太慢,停止加载,继续下一步操作")
self.driver.execute_script("window.stop()")
#此处需要设置等待,不然再页面缓存完之前就执行以下语句会导致找不到元素
time.sleep(40)
#找到登陆按钮并点击
#原本在获取cookies后通过request库带着cookies访问需要登陆才可访问的页面,但是对于webdriver没有作用
#wedriver元素定位的各种方法https://www.cnblogs.com/yufeihlf/p/5717291.html
#网页自动化最基本的要求就是先定位到各个元素,然后才能对各元素进行操作(输入、点击、清除、提交等)
#XPath是一种XML文档中定位元素的语言。该定位方式也是比较常用的定位方式
#8.1通过属性定位元素 find_element_by_xpath("//标签名[@属性='属性值']")
#可能的属性:id、class、name、maxlength
#通过标签名定位属性:所有input标签元素find_element_by_xpath("//input")
#通过父子定位属性:所有input标签元素find_element_by_xpath("//span/input")
#通过元素内容定位:find_element_by_xpath("//p[contains(text(),'京公网')]")
#获取id="login"的标签下第一个div//’表示从任意节点搜索不必从根节点一节一节
#如何找到对应按钮或者页面的xpath内容:检查页面,点击左上角箭头标志,
#然后点击目标内容,会自动定位到Elements中该内容的标签属性,右键COPY Xpath即可
#self.driver.find_element_by_xpath('//*[@class="btn-login ml1 tb-bg weight"]').click()
#time.sleep(40)
#下行代码的目的:查找二维码登陆的源代码点击使用二维码登陆
try:
#找到二维码登陆对应的属性并点击二维码登陆
driver_data=self.driver.find_element_by_xpath('//*[@id="login"]/div[1]/i').click()
except:
pass
#通常需要停顿几秒钟,不然会被检测到是爬虫
#等待网页缓冲
time.sleep(20)
# 执行JS获得canvas的二维码
#.通过tag_name定位元素
JS = 'return document.getElementsByTagName("canvas")[0].toDataURL("image/png");'
im_info = self.driver.execute_script(JS) # 执行JS获取图片信息
im_base64 = im_info.split(',')[1] #拿到base64编码的图片信息
im_bytes = base64.b64decode(im_base64) #转为bytes类型
time.sleep(2)
with open('E:/学习‘/login.png','wb') as f:
#生成二维码保存
f.write(im_bytes)
f.close()
#打开二维码图片,需要手动扫描二维码登陆
t = threading.Thread(target=self.opening,args=('E:/学习‘/login.png',))
t.start()
print("Logining...Please sweep the code!\n")
#获取登陆后的Cookie(只看到用户名,没有看到账号和密码)
while(True):
c = self.driver.get_cookies()
if len(c) > 20: #登陆成功获取到cookies
cookies = {}
#下面隐藏是因为对cookies只保留了name和value以后只能用于request,不能用于webdriver的add_cookies作用不然会报错InvalidCookieDomainException
#for i in range(len(c)):
#cookies[c[i]['name']] = c[i]['value']
self.driver.close()
print("Login in successfully!\n")
#return cookies
return c
time.sleep(10)
执行上述代码已经完成淘宝登陆并且跳转到了我的淘宝页面
从我的淘宝跳转到淘宝首页:
def my_split(self,s, seps):
"""split移除多个字符"""
res = [s]
for sep in seps:
t = []
list(map(lambda ss: t.extend(ss.split(sep)), res))
res = t
return res
def is_Chinese(self,word):
"""判断是否中文"""
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
def get_Cates(self):
"""登陆后默认跳转到我的页面,该段代码用户跳转到淘宝首页并且获取淘宝所有商品类别"""
#以上步骤已经实现淘宝登陆,并且进入到我的页面,点击淘宝网首页,跳转到首页
time.sleep(10)
#查看源代码确定"淘宝网首页"的按钮对应的属性,使用click进行点击
self.driver.find_element_by_xpath('//*[@class="site-nav-menu site-nav-home"]').click()
#跳转到首页后首先获取淘宝页面左边栏的所有品类
#检测到淘宝为动态JS,使用request库获取网页信息会与网页检查出来的数据不一致,所以需要用selenium包。
#辨别网页静态动态的方法:https://www.jianshu.com/p/236fc043db0b
#查看源码定位目标内容(即品类栏目)所对应的属性class
driver_data = self.driver.find_element_by_xpath('//*[@class="screen-outer clearfix"]')
html_doc = self.driver.page_source
#driver.quit()
#利用beautifulSoup解析网页源代码
soup = BeautifulSoup(html_doc, "lxml")
#找到淘宝主页中所有的主题,对应的class可通过查看class的范围确定
cate_list=[]
soup_data_list = soup.find("div",attrs={'class':'service J_Service'})
#获取源代码中的文本信息,即淘宝所有的物品主题
#通过自定义的split函数获取移除非法字符后的中文字符
list_tuple = list(("\n","\\","\ue62e","/","\t"," "," "," "))
cate_list=self.my_split(soup_data_list.text,list_tuple)
#使用自定义的is_Chinese函数仅保留中文文本
keep_select = []
#cate_list_final=[]
for i in cate_list:
keep_select = self.is_Chinese(i)
if keep_select:
self.cate_list_final.append(i)
time.sleep(10)
return self.cate_list_final
执行上述代码已经完成获取淘宝页面所有品类名称
在搜索框中输入要搜索的品类,点击搜索,点击销量排序按钮,获取页面内容进行解析:
def search_Taobao(self,cate):
print("正在搜索的品类是:%s"%cate)
#点击淘宝网首页跳转到首页页面,不管是在我的首页和各类别搜索下的首页,需要点击跳回淘宝网首页的class不变,所以把点击首页的代码放在这里"
time.sleep(10)
#在首页搜索栏输入需要搜索的内容,并点击搜索
#一个输入框两个input,两个input重叠的情况,先单点value提示字的input后,才会显示真正要输入框的input,这时再向这个input输值
#首先需要点击搜索框'//*[@class="search-combobox-input-wrap"]',使得其为可交互状态
self.driver.find_element_by_xpath('//*[@class="search-combobox-input-wrap"]').click()
#再找到输入搜索框的class名,输入要搜索的内容,找到搜索对应的class点击搜索
driver_input_data = self.driver.find_element_by_xpath('//*[@class="search-combobox-input"]')
#填写需要搜索的品类 不知道为什么 带着cookies这一步还是需要登陆
#driver_input_data.send_keys('女装')
driver_input_data.send_keys(cate)
#停顿3秒,否则速度过快会被识别出为爬虫
time.sleep(8)
#查找页面上”搜索“的按钮
try:
submit = self.driver.find_element_by_xpath('//*[@class="search-button"]')
submit.click()
except :
pass
time.sleep(5)
def get_Catinfo(self,cate):
#self.login_first()
time.sleep(20)
self.search_Taobao(cate)
#登陆后进入了对应搜索品类的页面,获取按销量降序后的第一页的商品信息
time.sleep(50)
#查找到按销量排序的元素,并进行点击得到降序排列的商品信息
submit_order = self.driver.find_element_by_xpath('//*[@class="J_Ajax link "]')
submit_order.click()
time.sleep(5)
#获取整个页面源码
html_doc = self.driver.page_source
#通过页面源码获取各个商品的必要信息
soup= BeautifulSoup(html_doc,"lxml")
shop_data_list = soup.find('div',class_="grid g-clearfix").find_all_next('div',class_="items")
for shop_data in shop_data_list:
#不同的信息分布在以下两个不同的class下
shop_data_a = shop_data.find_all("div",class_="ctx-box J_MouseEneterLeave J_IconMoreNew")
shop_data_b = shop_data.find_all("div",class_="pic-box J_MouseEneterLeave J_PicBox")
for goods_contents_b in shop_data_b:
#另起一列为爬取的商品类别
self.shop_cate_list.append(cate)
#0.获取商品名称
goods_name = goods_contents_b.find("div",class_="pic").find_all("img",class_="J_ItemPic img")[0]["alt"]
self.goods_name_list.append(goods_name)
#0.获取商品图片
goods_pic = goods_contents_b.find("div",class_="pic").find_all("img",class_="J_ItemPic img")[0]["src"]
self.goods_pic_list.append(goods_pic)
for goods_contents_a in shop_data_a:
#2.获取商品价格trace-price
goods_price = goods_contents_a.find_all("a",class_="J_ClickStat")[0]["trace-price"]
self.goods_price_list.append(goods_price)
#goods_price = goods_contents_a.find("div",class_="price g_price g_price-highlight")
#goods_price_list.append(goods_price)
#1.获取商品销量
goods_salenum = goods_contents_a.find("div",class_="deal-cnt")
self.goods_salenum_list.append(goods_salenum)
#2.获取商品id
goods_id = goods_contents_a.find_all("a",class_="J_ClickStat")[0]["data-nid"]
self.goods_id_list.append(goods_id)
#2.获取商品链接
goods_href = goods_contents_a.find_all("a",class_="J_ClickStat")[0]["href"]
self.goods_href_list.append(goods_href)
#2.获取店铺名称
goods_store = goods_contents_a.find("a",class_="shopname J_MouseEneterLeave J_ShopInfo").contents[3]
#goods_store = goods_contents.find_all("span",class_="dsrs")
self.goods_store_list.append(goods_store)
#4.获取店铺地址
goods_address = goods_contents_a.find("div",class_="location").contents
self.goods_address_list.append(goods_address)
#爬取结果整理成dataframe形式
for j in range(min(
len(self.goods_name_list),len(self.goods_id_list),len(self.goods_price_list)
,len(self.goods_salenum_list),len(self.goods_pic_list),len(self.goods_href_list)
,len(self.goods_store_list),len(self.goods_address_list)
)
):
self.data.append([self.shop_cate_list[j],self.goods_name_list[j],self.goods_id_list[j],self.goods_price_list[j]
,self.goods_salenum_list[j],self.goods_pic_list[j],self.goods_href_list[j]
,self.goods_store_list[j],self.goods_address_list[j]
])
#out_df = pd.DataFrame(self.data,columns=['goods_name'
# ,'goods_id'
# ,'goods_price'
# ,'goods_salenum'
# ,'goods_pic'
# ,'goods_href'
# ,'goods_store'
# ,'goods_address'])
#self.Back_Homepage()
#如果不休眠的话可能会碰到页面还没来得及加载就点击造成点击错误
time.sleep(20)
self.driver.find_element_by_xpath('//*[@class="site-nav-menu site-nav-home"]').click()
return self.data
执行上述代码已完成搜索各品类按销量降序排序后第一页的商品信息
三、如何定位网页内容标签与属性?
上文为利用selenium爬虫淘宝品类TOP销量数据的源码,但爬取数据其实最终要的内容在于如何定位网页中需要获取的内容的标签和属性,我通过腾讯视频中爬虫视频介绍的方法介绍如下:
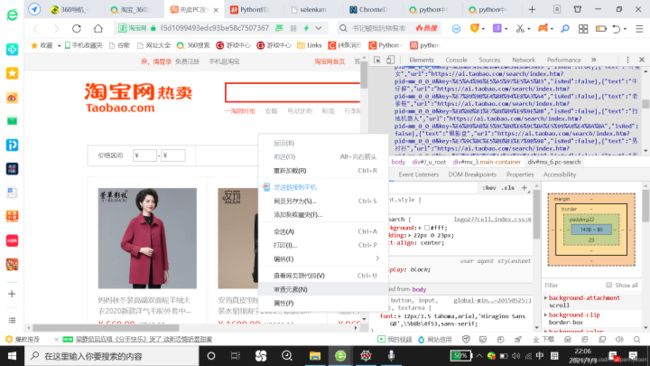
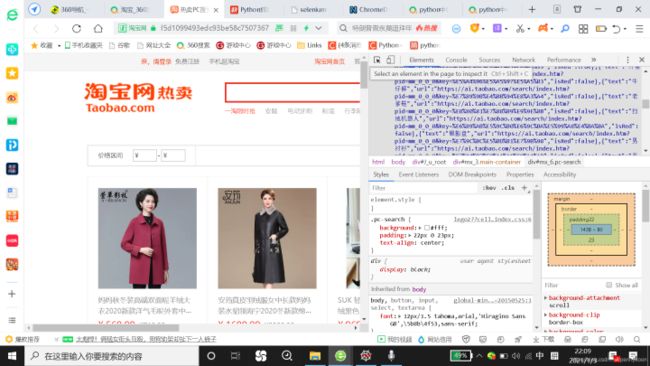
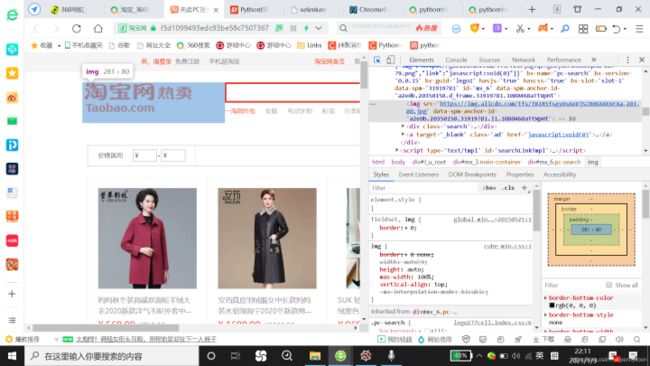
1.在网页中单击右键,点击审查元素(或者检查),点击后右上角出现该页面对应的属性信息,单击检查信息中左上角的箭头(Elements左边,会显示select
an element in the page to inspect it),然后点击网页中任意一个地方即可定位到对应的属性;
后话
本文以获取淘宝各品类销量作为实际案例作为爬虫的练习,但是在爬虫过程中对于HTML的结构、webdriver定位元素的方法、beautifulsoup定位元素、正则表达式的使用的方法还没有一个完整的概念,后续会将这部分内容梳理以下。
近期有很多朋友通过私信咨询有关Python学习问题。为便于交流,点击蓝色自己加入讨论解答资源基地