1. 关系型数据
很多数据分析都会涉及到多个表的操作,通常需要将这些表组合起来才能得到你想要的信息。
多个数据表统称为关系型数据,重要的是它们之间的关系,而不是仅仅单个数据表
dplyr 提供了三类函数用于关系数据:
- 可变连接:将与另一个数据中匹配的列添加到该数据中
-
inner_join(): 内连接 -
left_join(): 左连接 -
right_join(): 右连接 -
full_join(): 全连接
- 过滤连接:根据一个数据中的值是否与另一个数据中的值匹配来过滤这些值
semi_join()anti_join()
- 集合运算:将数据作为集合元素
这些操作类似于数据框操作,像 SQL 查询数据的语句。如果你之前接触过数据库,那么本节的知识应该是得心应手。
1.1 导入模块
library(tidyverse)
library(nycflights13)
2. nycflights13
我们还是使用 nycflights13 包的数据,包含 4 个与 flights 表相关的数据
-
airlines:可以从其缩写代码查询到航空公司的全名
> airlines %>% head(5)
# A tibble: 5 x 2
carrier name
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
-
airports:提供由faa机场代码标识的每个机场的信息
> airports %>% head(5)
# A tibble: 5 x 8
faa name lat lon alt tz dst tzone
1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/New_York
2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/Chicago
3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/Chicago
4 06N Randall Airport 41.4 -74.4 523 -5 A America/New_York
5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/New_York
-
planes:提供有关每架飞机的信息,由其tailnum标识
> planes %>% head(5)
# A tibble: 5 x 9
tailnum year type manufacturer model engines seats speed engine
1 N10156 2004 Fixed wing multi engine EMBRAER EMB-145XR 2 55 NA Turbo-fan
2 N102UW 1998 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 2 182 NA Turbo-fan
3 N103US 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 2 182 NA Turbo-fan
4 N104UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 2 182 NA Turbo-fan
5 N10575 2002 Fixed wing multi engine EMBRAER EMB-145LR 2 55 NA Turbo-fan
-
weather:给出纽约市每个机场每小时的天气
> weather %>% head(5)
# A tibble: 5 x 15
origin year month day hour temp dewp humid wind_dir wind_speed wind_gust precip pressure visib
1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4 NA 0 1012 10
2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06 NA 0 1012. 10
3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5 NA 0 1012. 10
4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7 NA 0 1012. 10
5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7 NA 0 1012. 10
# … with 1 more variable: time_hour
我们以图像的形式显示不同表之间的关系

从图上可以看出,不同表之间通过一些相同的列关联起来,你只需关注感兴趣的表之间的关联。
对于 nycflights13:
-
flights通过单个变量tailnum连接到planes -
flights通过carrier变量与airlines相连 -
flights通过origin和dest变量连接到airports: -
flights通过origin(位置)和year,month,day和hour(时间)连接到weather
2.1 思考练习
- 如果你想绘制每架飞机从出发地到目的地的飞行路线,需要什么变量?需要合并哪些表?
3. 键
用于连接每对表的变量称为键,键是唯一标识观察值的变量(或变量集)。
一般情况下,一个变量就足够标识观察结果。例如,每个 planes 由其 tailnum 唯一标识。
在其他情况下,可能需要多个变量。例如,要识别 weather,需要五个变量:year, month, day, hour 和 origin。
主要包括两种键:
主键:在自己的表中唯一标识每一个观察值。例如,
planes$tailnum就是主键,因为它唯一地标识了planes表中的每架飞机外键:另一个表的主键。例如,
flights$tailnum是一个外键,因为它出现在flights表中,且它使每个航班与唯一的飞机匹配
一个变量既可以是主键,也可以是外键。例如,origin 是 weather 表主键的一部分,也是 airports 表的外键。
主键的值必须是唯一的,所以,为了确保其唯一性,我们可以使用 count() 函数,然后查找 n > 1 的数目
> planes %>%
+ count(tailnum) %>%
+ filter(n > 1)
# A tibble: 0 x 2
# … with 2 variables: tailnum , n
> weather %>%
+ count(year, month, day, hour, origin) %>%
+ filter(n > 1)
# A tibble: 3 x 6
year month day hour origin n
1 2013 11 3 1 EWR 2
2 2013 11 3 1 JFK 2
3 2013 11 3 1 LGA 2
有些表并不会显示的指明哪个是主键,例如,flights 表中的主键是什么?您可能会认为日期加上航班号或机尾编号,但这两个都不是唯一的
> flights %>%
+ count(year, month, day, flight) %>%
+ filter(n > 1)
# A tibble: 29,768 x 5
year month day flight n
1 2013 1 1 1 2
2 2013 1 1 3 2
3 2013 1 1 4 2
4 2013 1 1 11 3
5 2013 1 1 15 2
6 2013 1 1 21 2
7 2013 1 1 27 4
8 2013 1 1 31 2
9 2013 1 1 32 2
10 2013 1 1 35 2
# … with 29,758 more rows
> flights %>%
+ count(year, month, day, tailnum) %>%
+ filter(n > 1)
# A tibble: 64,928 x 5
year month day tailnum n
1 2013 1 1 N0EGMQ 2
2 2013 1 1 N11189 2
3 2013 1 1 N11536 2
4 2013 1 1 N11544 3
5 2013 1 1 N11551 2
6 2013 1 1 N12540 2
7 2013 1 1 N12567 2
8 2013 1 1 N13123 2
9 2013 1 1 N13538 3
10 2013 1 1 N13566 3
# … with 64,918 more rows
在刚开始处理这些数据时,我天真地以为每个航班号每天只使用一次。不幸的是,事实并非如此!
如果一个表缺少主键,那么添加一个带有 mutate() 和 row_number() 的主键有时会很有用,称为代理键。
一个主键和另一个表中的相应外键形成一个关系。关系通常是一对多的,例如,每个航班都只有一架飞机,但每架飞机可以安排许多航班。
在其他一些数据中,您也会看到一对一的关系。你可以把它看作一对多的特例。
您可以使用多对一关系和一对多关系来构建多对多的关系。例如,在这个数据中,航空公司和机场之间有一个多对多的关系:每个航空公司都会在许多机场安排有飞机;每个机场都有许多航空公司。
3.1 思考练习
为
flights添加代理键识别以下数据集中的键:
Lahman::Battingbabynames::babynamesnasaweather::atmosfueleconomy::vehiclesggplot2::diamonds
注:您可能需要安装一些软件包并阅读对应的文档
4. 可变连接
可变连接允许您组合两个表中的变量。它首先通过键匹配观察值,然后将变量从一个表复制到另一个表。
与 mutate() 一样,连接函数会在右边添加变量,因此如果已经有很多变量,则不会打印出新添加的变量
所以,我们会挑选出一些列来进行连接
> flights2 <- flights %>%
+ select(year:day, hour, origin, dest, tailnum, carrier)
> flights2
# A tibble: 336,776 x 8
year month day hour origin dest tailnum carrier
1 2013 1 1 5 EWR IAH N14228 UA
2 2013 1 1 5 LGA IAH N24211 UA
3 2013 1 1 5 JFK MIA N619AA AA
4 2013 1 1 5 JFK BQN N804JB B6
5 2013 1 1 6 LGA ATL N668DN DL
6 2013 1 1 5 EWR ORD N39463 UA
7 2013 1 1 6 EWR FLL N516JB B6
8 2013 1 1 6 LGA IAD N829AS EV
9 2013 1 1 6 JFK MCO N593JB B6
10 2013 1 1 6 LGA ORD N3ALAA AA
# … with 336,766 more rows
假设您要将完整的航空公司名称添加到 flights2 数据中。
您可以使用 left_join() 来组合 airlines 和 flights2 两个数据表
> flights2 %>%
+ select(-origin, -dest) %>%
+ left_join(airlines, by = "carrier")
# A tibble: 336,776 x 7
year month day hour tailnum carrier name
1 2013 1 1 5 N14228 UA United Air Lines Inc.
2 2013 1 1 5 N24211 UA United Air Lines Inc.
3 2013 1 1 5 N619AA AA American Airlines Inc.
4 2013 1 1 5 N804JB B6 JetBlue Airways
5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
6 2013 1 1 5 N39463 UA United Air Lines Inc.
7 2013 1 1 6 N516JB B6 JetBlue Airways
8 2013 1 1 6 N829AS EV ExpressJet Airlines Inc.
9 2013 1 1 6 N593JB B6 JetBlue Airways
10 2013 1 1 6 N3ALAA AA American Airlines Inc.
# … with 336,766 more rows
这个结果将 airlines 表中的 name 添加到了 flights2 后面,这就是为什么我们称这种连接为可变连接的原因。
当然你也可以使用 mutate() 和 R 取子集操作实现同样的功能
> flights2 %>%
+ select(-origin, -dest) %>%
+ mutate(name = airlines$name[match(carrier, airlines$carrier)])
# A tibble: 336,776 x 7
year month day hour tailnum carrier name
1 2013 1 1 5 N14228 UA United Air Lines Inc.
2 2013 1 1 5 N24211 UA United Air Lines Inc.
3 2013 1 1 5 N619AA AA American Airlines Inc.
4 2013 1 1 5 N804JB B6 JetBlue Airways
5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
6 2013 1 1 5 N39463 UA United Air Lines Inc.
7 2013 1 1 6 N516JB B6 JetBlue Airways
8 2013 1 1 6 N829AS EV ExpressJet Airlines Inc.
9 2013 1 1 6 N593JB B6 JetBlue Airways
10 2013 1 1 6 N3ALAA AA American Airlines Inc.
# … with 336,766 more rows
下面我们将详细介绍可变连接的原理
4.1 了解连接
为了帮助理解,我们以图形的方式讲解
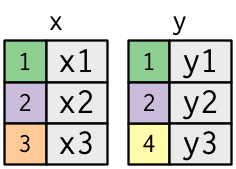
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)
彩色的列表示键:用于匹配表之间的行。灰色列表示为行携带的值列。
连接是将 x 中的每一行连接到 y 中的零行、一行或多行的一种方式。下图将每个能够匹配的位置显示为一对线的交点

在实际连接中,匹配项将用点表示。点数=匹配数=输出中的行数

4.2 内连接
最简单连接类型是内连接,内连接在键相等时匹配连接对应的值
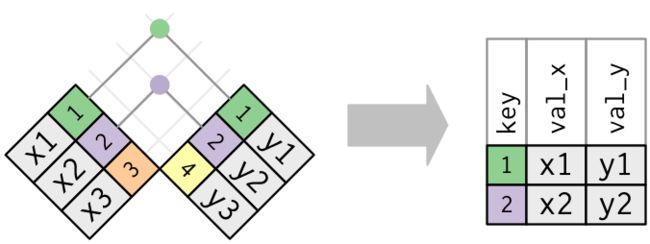
确切地说,这是内部等值连接,因为使用相等运算符来匹配键。由于大多数连接都是等值连接,因此我们通常会删除该规范
内连接的输出是一个新的数据框,其中包含键、x 值和 y 值。我们使用 by 来告诉 dplyr 哪个变量是键
> x %>%
+ inner_join(y, by = "key")
# A tibble: 2 x 3
key val_x val_y
1 1 x1 y1
2 2 x2 y2
内连接的最重要属性是不匹配的行不包含在结果中。
4.3 外连接
内连接使观察结果同时出现在两个表中。外连接保留观察结果,这些观察结果至少出现在一个表中。外部联接有三种类型:
-
left_join: 保留 x 的所有值 -
right_join: 保留 y 的所有值 -
full_join: 保留 x 和 y 的所有值
这些连接会将未匹配的赋值为 NA

其中左连接比较常用,无论何时从另一个表中查找匹配的其他数据,都可以使用此选项,因为即使不存在匹配项,它也会保留原始观测值。
以韦恩图来描述的话,就是

4.4 重复的键
在上面的例子中,所有图都假定键是唯一的。如果键不唯一会发生什么?有以下两种情况
- 只有一个表中存在重复的键。
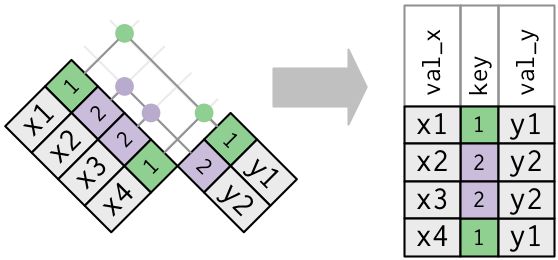
> x <- tribble(
+ ~key, ~val_x,
+ 1, "x1",
+ 2, "x2",
+ 2, "x3",
+ 1, "x4"
+ )
> y <- tribble(
+ ~key, ~val_y,
+ 1, "y1",
+ 2, "y2"
+ )
> left_join(x, y, by = "key")
# A tibble: 4 x 3
key val_x val_y
1 1 x1 y1
2 2 x2 y2
3 2 x3 y2
4 1 x4 y1
- 两个表都有重复的键。
这通常是一个错误,因为在两个表中,键都不能唯一地标识观察值。因此连接之后,会得到所有可能的组合,即笛卡尔乘积

> x <- tribble(
+ ~key, ~val_x,
+ 1, "x1",
+ 2, "x2",
+ 2, "x3",
+ 3, "x4"
+ )
> y <- tribble(
+ ~key, ~val_y,
+ 1, "y1",
+ 2, "y2",
+ 2, "y3",
+ 3, "y4"
+ )
> left_join(x, y, by = "key")
# A tibble: 6 x 3
key val_x val_y
1 1 x1 y1
2 2 x2 y2
3 2 x2 y3
4 2 x3 y2
5 2 x3 y3
6 3 x4 y4
4.5 定义连接的键
到目前为止,两个表始终由单个变量相连,并且该变量在两个表中具有相同的名称,可以通过 by='key' 参数为 by 指定需要连接的列 'key'
- 默认情况下
by=NULL,使用出现在两个表中所有相同的变量,即所谓的自然联接。例如flights和weather两个表具有相同的变量year,month,day,hour和origin
> flights2 %>%
+ left_join(weather) %>%
+ head(3)
Joining, by = c("year", "month", "day", "hour", "origin")
# A tibble: 3 x 18
year month day hour origin dest tailnum carrier temp dewp humid wind_dir wind_speed wind_gust
1 2013 1 1 5 EWR IAH N14228 UA 39.0 28.0 64.4 260 12.7 NA
2 2013 1 1 5 LGA IAH N24211 UA 39.9 25.0 54.8 250 15.0 21.9
3 2013 1 1 5 JFK MIA N619AA AA 39.0 27.0 61.6 260 15.0 NA
# … with 4 more variables: precip , pressure , visib , time_hour
- 设置
by='x',和自然连接类似,但只使用指定的一些公共变量。例如,flights和planes有year变量,但它们的含义不同,因此我们只想通过tailnum连接
> flights2 %>%
+ left_join(planes, by = "tailnum") %>%
+ head(3)
# A tibble: 3 x 16
year.x month day hour origin dest tailnum carrier year.y type manufacturer model engines seats
1 2013 1 1 5 EWR IAH N14228 UA 1999 Fixe… BOEING 737-… 2 149
2 2013 1 1 5 LGA IAH N24211 UA 1998 Fixe… BOEING 737-… 2 149
3 2013 1 1 5 JFK MIA N619AA AA 1990 Fixe… BOEING 757-… 2 178
# … with 2 more variables: speed , engine
注意:两个年份变量在输出中用后缀消除歧义
- 设置命名变量
by=c('a'='b'),这将使表x中的变量a与表y中的变量b相匹配。并将x中的变量将用于输出
例如,如果我们想绘制一张地图,我们需要将航班数据与每个机场位置(纬度和经度)的数据相结合。每个航班都有一个出发地和目的地,因此我们需要指定要加入的机场
> flights2 %>%
+ left_join(airports, c("dest" = "faa")) %>%
+ head(3)
# A tibble: 3 x 15
year month day hour origin dest tailnum carrier name lat lon alt tz dst tzone
1 2013 1 1 5 EWR IAH N14228 UA George Bu… 30.0 -95.3 97 -6 A Americ…
2 2013 1 1 5 LGA IAH N24211 UA George Bu… 30.0 -95.3 97 -6 A Americ…
3 2013 1 1 5 JFK MIA N619AA AA Miami Intl 25.8 -80.3 8 -5 A Americ…
> flights2 %>%
+ left_join(airports, c("origin" = "faa")) %>%
+ head(3)
# A tibble: 3 x 15
year month day hour origin dest tailnum carrier name lat lon alt tz dst tzone
1 2013 1 1 5 EWR IAH N14228 UA Newark L… 40.7 -74.2 18 -5 A America…
2 2013 1 1 5 LGA IAH N24211 UA La Guard… 40.8 -73.9 22 -5 A America…
3 2013 1 1 5 JFK MIA N619AA AA John F K… 40.6 -73.8 13 -5 A America…
>
4.6 思考练习
将
origin和dest的位置(即纬度:lat和经度:lon)添加到flights飞机的年份与其延误之间是否有关系?
哪种天气条件更有可能出现延误?
4.7 其他
这些连接都可以通过 base::merge() 实现
| dplyr | merge |
|---|---|
| inner_join(x, y) | merge(x, y) |
| left_join(x, y) | merge(x, y, all.x = TRUE) |
| right_join(x, y) | merge(x, y, all.y = TRUE) |
| full_join(x, y) | merge(x, y, all.x = TRUE, all.y = TRUE) |
dplyr 动词的优点就是它们可以更清楚地传达您的代码意图。
dplyr 的连接要快得多,而且不会打乱行的顺序。