简介
DataLoader 是facebook推出的一款通用工具,可为传统应用层与持久层之间提供一款缓存和批处理的操作。JS、Java、Ruby、Go等主流语言都有开源三方库支持。尤其在Graphql兴起后,DataLoader被广泛地应用于解决N+1查询问题。
机制
DataLoader的实现原理很简单:就是把每一次load推迟到nextTick中集中处理。在现实开发中其主要有两点应用:
- 批处理操作
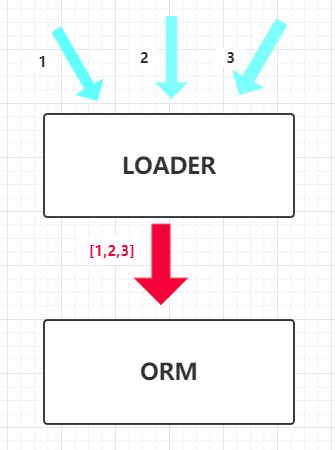
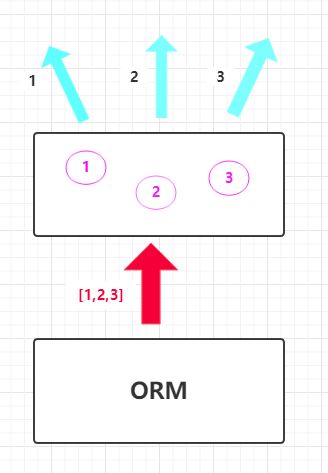
- 内存级别的缓存
案例
以下以nodejs中调用dynamoose api为例具体介绍一下DataLoader在dynamodb查询时的一些使用方法。
批处理 (Batching)
先看一下传统DAO设计实现中的模版方法。我们通过name来获取user的信息。
// #UserDao.ts
import {ModelConstructor} from 'dynamoose';
import {DataSchema, userModel} from './User.schema';
export default class UserDao {
private readonly model: ModelConstructor;
constructor() {
this.model = userModel; //Dynamoose user schema model
}
public getUser(name: string) {
console.log('Get user:', name);
return this.model.get(name);
}
}
当我们调用getUser方法时:
import UserDao from './UserDao';
async function run(user) {
const users = await Promise.all([
user.getUser('Garlic'),
user.getUser('Onion'),
]);
console.log('return:', users);
}
run(new UserDao());
打印结果是:
Get user: Garlic
Get user: Onion
return: [ Model-user { name: 'Garlic' }, Model-user { name: 'Onion' } ]
显然,dynamodb被访问了两次。再看一下使用DataLoader后的情况。
// #UserLoader.ts
import Dataloader = require('dataloader');
import {DataSchema, userModel} from './User.schema';
const BatchLoadFn = (names: [string]) => {
console.log('Get Keys:', names);
return userModel.batchGet(names);
};
export default class UserLoader {
private readonly loader: Dataloader;
constructor() {
this.loader = new Dataloader(BatchLoadFn);
}
public getUser(name: string) {
return this.loader.load(name);
}
}
DataLoader初始化时必须传入一个BatchLoadFn,在dataloader/index.d.ts里找到如下定义:
type BatchLoadFn = (keys: K[]) => Promise>;
BatchLoadFn的参数是数组且返回是个包在Promise里的数组。因此可以直接调用dynamoose的batchGet方法。
再次调用上述的run方法
async function run(user) {
const users = await Promise.all([
user.getUser('Garlic'),
user.getUser('Onion'),
]);
console.log('return:', users);
}
run(new UserLoader());
看一下输出结果:
Get Keys: [ 'Garlic', 'Onion' ]
return: [ Model-user { name: 'Garlic' }, Model-user { name: 'Onion' } ]
返回一样,但是两次get方法被合并成了一次batchGet了。
不过,在使用dynamoose的batchGet的时候,会出现一些奇妙的bug;稍微改动一下getUser的顺序,把Garlic和Onion换一下。
async function run(user) {
const users = await Promise.all([
user.getUser('Onion'),
user.getUser('Garlic'),
]);
console.log('return:', users);
}
返回变成了:
# run(new UserDao());
Get user: Onion
Get user: Garlic
return: [ Model-user { name: 'Onion' }, Model-user { name: 'Garlic' } ]
---
# run(new UserLoader());
Get Keys: [ 'Onion', 'Garlic' ]
return: [ Model-user { name: 'Garlic' }, Model-user { name: 'Onion' } ]
userLoader返回的内容错了,先返回了Garlic,后返回Onion。这个是很多NoSql数据库搜索算法共通的问题。
改动一下BatchLoadFn,将batchGet的返回结果按name排序。
const BatchLoadFn: any = (names: [string]) => {
console.log('Get Keys:', names);
return userModel.batchGet(names)
.then((users) => {
const usersByKey: object = users.reduce(
(acc, user) => Object.assign(acc, {[user.name]: user}), {});
return names.map((name) => usersByKey[name]);
});
};
OK,这下输出正常了。
Get Keys: [ 'Onion', 'Garlic' ]
return: [ Model-user { name: 'Onion' }, Model-user { name: 'Garlic' } ]
缓存
async function run(user) {
const users = await Promise.all([
user.getUser('Onion'),
user.getUser('Onion'),
]);
console.log('return:', users);
}
设想一下,如果两次getUser都是Onoin会怎么样?
Get Keys: [ 'Onion' ]
return: [ Model-user { name: 'Onion' }, Model-user { name: 'Onion' } ]
结果是一次getUser后,DataLoader会把数据缓存到内存里,下一次get相同的User时,就不会再调用BatchLoadFn了。事实上,DataLoader缓存的是Promise。如下:
assert(user.getUser('Onion') === user.getUser('Onion')) // true
Dataloader在默认机制下是启动cache的,也可以选择关闭cache。
new Dataloader(BatchLoadFn, {cache: false});
//duplicated keys in batchGet may occur error.
在出错或是更新时也可调用clear方法清除cache。
public getUser(name: string) {
return this.loader.load(name)
.catch((e) => {
this.loader.clear(name);
return e;
});
}
此外,在初始化Dataloader时可以自定义cache策略:new DataLoader(batchLoadFn [, options])
| Option Key | Type | Default | Description |
|---|---|---|---|
| cache | Boolean | true |
设置为false则停用cache |
| cacheKeyFn | Function | key => key |
cacheKeyFn返回只能是string或number, 如key为object,可设为key => JSON.stringify(key) |
| cacheMap | Object | new Map() |
自定义cache算法, 如DataloaderCacheLru |
API
DataLoader并不是一个超级工具,代码也只有300多行,而且相当部分是注释。它只提供了5个API,基本只能完成loadByKey相关的操作。
load(key: K): Promise
; loadMany(keys: K[]): Promise
clear(key: K): DataLoader
clearAll(): DataLoader
prime(key: K, value: V): DataLoader
Graphql
DataLoader被广泛应用于Graphql的resolver中,
# Define in graphql type def
type User {
name: String
friends: [User]
}
# Query in front-end
{
user(name: "Onion") {
name
friends {
name
friends {
name
}
}
}
}
# user.resolver.ts
Query: {
user: (root, {name}) => {
return userDao.getUser(name);
}
}
User: {
friends: (root) => {
return Promise.all( root.friends.map( (name) => userDao.getUser(name) ) );
}
}
Onion朋友的朋友中必然有Onion自己。Graphql支持嵌套查询,假如直接调用传统UserDao的getUser方法, 数据库查询单个Onion的次数将会是1+len(friends)。
若将上述代码中的userDao换成userLoader,Onion的数据库访问就只有一次了。这就解决了N+1查询的问题。
Query: {
user: (root, {name}) => {
return userLoader.getUser(name);
}
}
User: {
friends: (root) => {
return Promise.all( root.friends.map( (name) => userLoader.getUser(name) ) );
}
}
小结
今天大体介绍了一下DataLoader的机制和使用方法。在现实开发中我们可以将dataloader专门作为一层架构,对应用层做cache,对数据层做batch。甚至有项目将DataLoader与redis集成(redis-dataloader)。
我参与的其中一个项目在使用DataLoader优化Graphql查询后,DB访问数减少了3/4。尤其是用到DynamoDB这类按查询收费的服务时,DataLoader不仅可以加速前端访问速度,还可以极大地减少后端运维成本。