前言
掉进水里你不会淹死,待在水里你才会淹死,只有不断学习才不会被前沿淘汰,以下面试题希望对你们有帮助!
什么是面向对象?谈谈你对面向对象的理解
答:在程序设计中有面向过程和面向对象,C语言是面向过程的,就是一步一步的非常清楚,比较直接高效,而java是面向对象的,更易于重复使用、扩展和维护。
面向过程只会思考这个事情(问题)本身
面向对象要将一个事情解拆成一个一个的模块
面向对象三大特性:
封装、继承、多态
封装的意义:
内部细节对外部调用透明,外部调用无需修改或者关心内部实现
比如:ORM框架 操作数据库,我们不需要关心链接是如何建立的、sql是如何执行的,只须要引入mybatis,调方法即可
继承:
继承基类的方法,并做出自己的改变和扩展
将共性的方法或属性写在父类,而不需要自己再定义,只需要扩展自己的个性化 就有点像AOP面向切面编程一样 在不改变源码的基础上添加一些新的功能, 继承也是在继承了父类的所有方法和属性上 子类可以优化父类的方法和扩展自己的方法
多态:
多态和继承其实是一脉相承的 多态有一个条件:要有继承 要重写父类的方法 父类引用指向子类对象
多态的用法 : 父类类型 变量名 = new 子类对象; 变量名.方法名() ; 调用的方法是子类对象的方法 这就是多态 但是多态有一个弊端 无法调用子类自己特有的功能 就是子类对象的方法必须是在父类中有
也就是重写了父类的方法才能被调用 (方法重写)
JAVA虚拟机(重点)

JAVA语言有一个非常牛B的特性 就是跨平台 代码一次编写到处运行

跨平台特性实现:使用JVM(虚拟机)实现 字节码文件都会放到jvm里面去运行 针对不同的平台 会生成不同的代码 java虚拟机帮我们做到的
java虚拟机是JDK的一个组成部分
java虚拟机由那些部分组成:
由三大部分组成 :
1:类装载子系统
2:运行时数据区(内存模型(重点)) 包含堆 栈(线程) 本地方法栈 方法区(元空间) 程序技术器
3:字节码执行引xin

栈(线程): 官网叫(虚拟机栈) 而我自己想叫它线程栈,为什么呢?只要一个线程开始运行 java虚拟机就会给这个线程分配它一块自己的专属内存空间 这个内存空间就叫做线程栈 !为什么分配这个空间?因为在这个线程运行过程中需要内存空间去存放一些变量 那么就是放到这个线程栈的
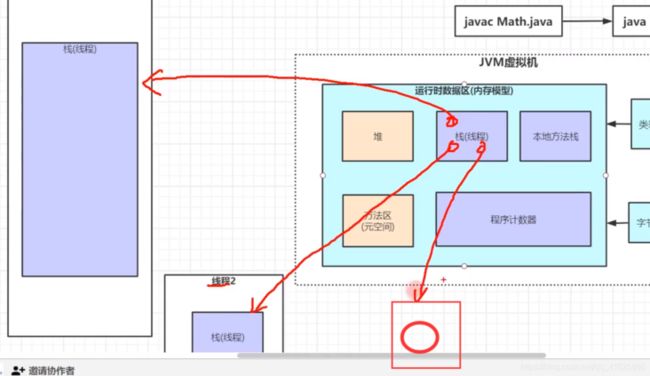
栈帧内存空间:就是线程栈内部为每个方法分配的一个内存空间 这个内存空间用来存放这个方法内的局部变量 这就叫(栈帧)!

数据结构里面有个叫栈的数据结构 有个非常重要的特性FILO 先进后出
线程栈内部放栈帧的数据结构就是FILO结构 先进后出 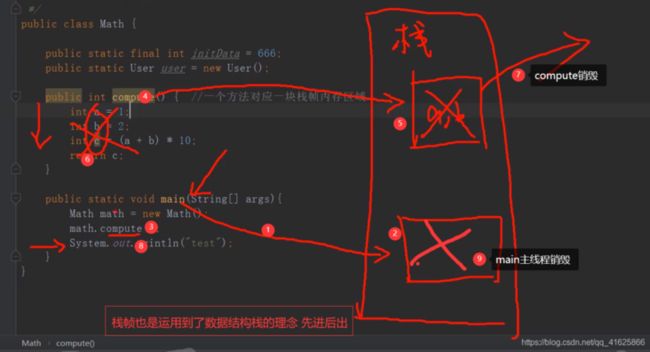
先调用的方法后结束 后调用的方法先结束 也就是先调用的方法后释放内存资源 后调用的方法先释放内存资源
java jvm虚拟机赋值步骤

将JAVA文件编译后的class文件转换为方便阅读的源码: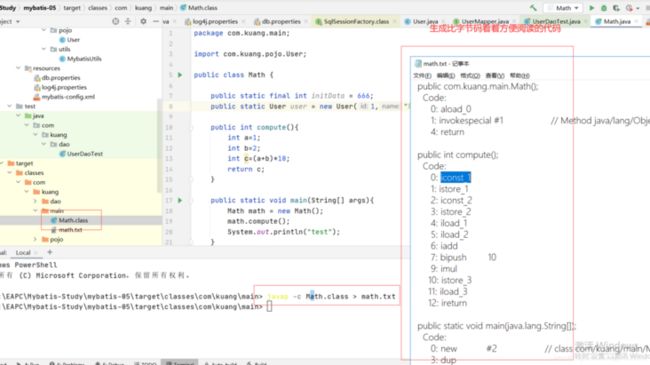
栈帧内的操作数栈操作步骤:

程序计数器:
当前在内存中执行的代码行 字节代码行号从0开始
用处: 多线程 当前线程正在运行时 一个比当前线程优先级高的线程开始执行了 那么当前线程就会被挂起 后面开始执行的时候就通过这个程序计数器的行号开始执行
程序计数器的值由字节码执行引擎来进行修改 因为字节码执行引擎指向着Math.class和程序计数器 当Math.class每行代码执行完毕时都会修改程序计数器的值
局部变量:
就是一个局部变量表 放当前局部的变量
操作数栈:
放操作数的 +-*/操作运算的 临时存放的一块内容空间

动态链接:
源码 牵扯到C语言和C++ 把一些符号引用转换为直接引用
符号引用:方法名称 括号啊 在JVM里面都有一个名称 叫符号 当程序真正运行到一行代码的时候 就将这些符号引用转换为直接引用
通过动态链接在方法区(元空间)找到那些要执行的代码
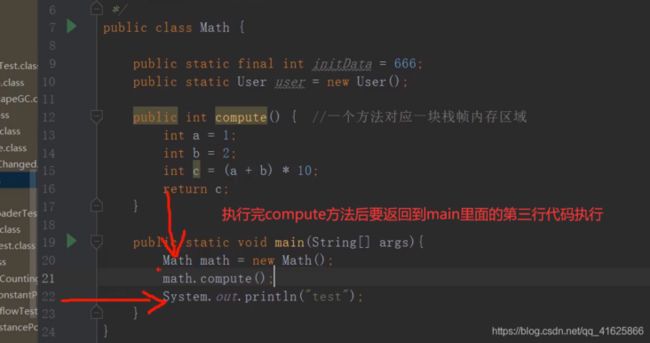
方法出口:
就是compute方法执行完毕后知道返回到main主函数的第几行代码去继续执行
对象是放在堆区域的

栈和堆的关系就是栈里面的内存地址通过指针指向堆里相对应的对象
方法区放:常量+静态变量+类信息

不管是栈里面的对象还是方法区里的静态对象 都是通过内存地址指针指向堆里对应的对象 堆里就是存放对象的 不管是静态还是非静态的 只要是对象都会存放在堆里 让其它地方通过内存地址指针到对应的对象
方法区类信息 字节码的一些信息会加载到方法区内部
本地方法栈:本地方法分配内存空间 native (nei ti wu) 修饰的方法叫本地方法 本地方法:底层是C和C++实现的 这个本地方法肯定有要运行的东西嘛 所以就需要分配一个内存空间
堆:由年轻代和老年代构成 老年代占3分之2 年轻代占3分之1

如果一个对象被minor gc(ma lr GC)干了15次还没有被干掉 那么这个对象会被移到老年代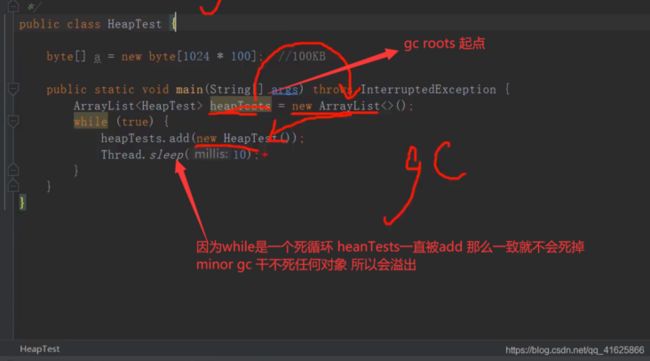
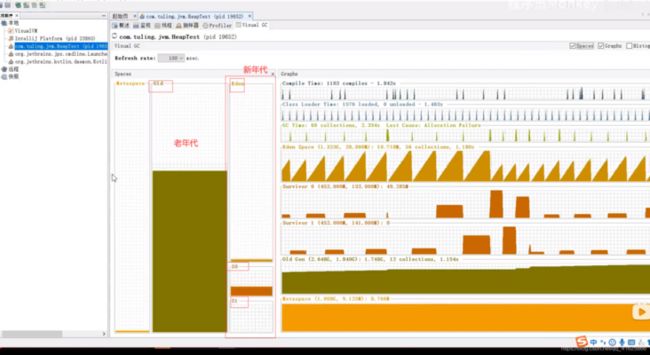
补充:
完整对象包含:对象头、实例数据

JAVA虚拟机调优:
调优工具 阿里开源工具: Arthas(啊 sr 死) JDK自带的:Visual GC
JDK、JRE、JVM三者区别和联系
JDK:java开发工具 提供给开发人员来使用的
JRE:java运行时环境 提供给运行java程序的用户来使用的 谁需要运行java程序就需要安装JRE
JVM:虚拟机 解析class文件 解析成机器码(二进制)让操作系统可以执行
是class文件是可以到处运行的 并不是JVM可以到处运行 JVM是将当前class文件解析成当前操作系统能识别的机器码

==和equals的区别
在java中有两块很重要的内存 栈和堆 堆是存对象 栈是存值
String s = new String() String ss = new String() s=“123” ss = “123”
boolean b = s == s?true:false; b的值为false 因为s和ss在堆里开辟了不同的内存空间
boolean b = s.equals(ss) b的值为true 因为equals重写了方法 只是比较了两个字符串的内容 没有进行对象比较 只是比较了值 所以可以理解equals就是比较的值
int a = 1 int b = 1
boolean b = a==b ?true:false; b的值为true 因为a和b都是在栈中 并且值都是1 所以结果为true
来一道题:
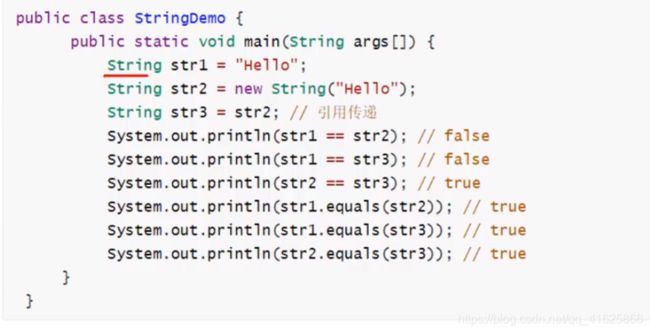
解析:
str1==str2 false 因为str1和str2 使用== 比较的是栈中的值 栈中str1 str2 都存放的是不同的内存地址 是存放在堆中的对象 所以它们的内存对象值不同 所以返回为false
str2==str3 同理
str2==str3 true 因为str3 直接通过赋值运算符取得了str2在栈中的内存地址值 所以str3和str2的内存地址值是一摸一样的 都指向的是堆里的那个对象
str1.equals(str2) true equals 对比的是内容 内容都是Hello 肯定都是true
简述final作用



为什么局部内部类和匿名内部类只能访问局部final变量?


自己的理解:final声明的变量只是为了局部生成的匿名类或者内部类调用时这个值是一致的 就是面向对象的思想
重载和重写的区别
重载:发生在同一个类中,方法名必须相同,参数类型不同,个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
重写:发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private则子类就不能重写该方法
接口和抽象类的区别
抽象类只能继承一个,接口可以实现多个
抽象类可以存在普通成员函数,而接口中只能存在public abstract方法 接口里面只能是抽象的方法
抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的
初级程序员答:
抽象类除了有抽象方法还有实现了的方法也就是普通成员函数 而接口不可以 接口里面的方法必须全部是抽象的
在我们的抽象类中成员变量是可以有多种类型的 而接口中的成员变量只能是public static final类型的 接口中的成员变量默认都是常量
抽象类是单继承 而接口是可以多实现的
中级程序员答、高级程序员答:
接口的设计目的:它只对类能够提供那些方法 至于这个方法怎么实现的 它不管
抽象类的设计目的:代码服用 不同的类具有相同的行为 有共性的东西 这个时候就可以把这些共同的东西抽取出来写入道抽象类中 可以有抽象方法 也可以有已经实现了的方法
抽象类包含并实现子类的通用特性
抽象类是对类本质的抽象 表达的是is a的关系 比如 BMW is a Car 如果用BMW继承Car类 就代表BMW是Car
而接口是对行为的抽象 表达的是like a的关系 是类似 不是直接就是 Bird like a Aircraft Aircraft 接口有一个飞的方法 Bird就可以去实现Aircraft接口里的飞的方法
但是Bird(小鸟)不是一个Aircraft(飞行器) 因为Aircraft(飞行器)接口里面有飞的方法 所以Bird小鸟可以去实现Aircraft接口飞的方法
使用场景:
当你关注一个事务的本质的时候,用抽象类
当你关注一个操作的时候,用接口
抽象类的功能要远超过接口 抽象类可以有实现的方法 也可以有未实现的方法 但是定义抽象类的代价比较高 抽象类只能实现一个 接口会降低难度:接口可以实现多个
List和Set:List是有序的 可重复的 可以使用迭代器和下表读取存入的值 set是无需的 不可重复的 只能使用迭代器读取存入的值
hashcode和equals:
如果两个对象相等,那么hashcode一定也是相同的
两个对象相等,对两个对象分别调用equals方法都返回true
ArrayList和LinkedList的区别:
ArrayList是基于动态数组的 亮点在于扩容机制 老数组和新数组 当使用ArrayList开辟了一个能容纳10个值的数组时想插入第11个值的话 那么扩容机制就来了
扩容机制原理:就是新数组和老数组 开辟一个比老数组要长的新数组 将老数组的值CP到新数组中并将新插入的值插入到新数组中 这就是扩容机制也就是动态数组的机制
它更利于插入不利于查询 但是 如果将ArrayList使用的恰当是可以比LinkedList性能要好的 它可以通过下标和迭代器访问存入的值
LinkedList是基于链表的 它利于插入不利于查询 只能使用迭代器访问存入的值 不能通过下标 而且不推荐使用for循环来遍历 因为LinkedList是基于链表的 如果使用for循环去访问存入的值 那么每读取一个值都会从链表链一次 效率可想而知有多低
HashMap和HashTable的区别?及底层原理
HashMap是线程不安全的 HashTable是线程安全的 因为HashTable为里面的每个方法都添加了锁 而HashMap没有 它们两的方法都差不多 但是HashTable效率低 HashMap效率高 可以根据不同的业务来选择使用
HashMap基于动态数组实现
HashTable基于链表实现
Thread、Runable的区别
实现Runable 或者继承Thread si wei dr Thread实现了Runable Thread和Runable的实质是继承关系 ,没有可比性,Thread是单继承但是Runable是多实现
最后
在文章的最后作者为大家整理了很多资料!包括java核心知识点+全套架构师学习资料和视频+一线大厂面试宝典+面试简历模板+阿里美团网易腾讯小米爱奇艺快手哔哩哔哩面试题+Spring源码合集+Java架构实战电子书等等!
全部免费分享给大家,有需要的朋友欢迎关注公众号:前程有光,领取!