爬取广州天气并格式化输出
爬取广州天气情况
- 爬取广州未来七天天气情况,并格式化输出
-
- 网页情况
- 网页源代码
- 代码
- 输出结果
爬取广州未来七天天气情况,并格式化输出
网页情况
网页链接:http://www.weather.com.cn/weather/101280101.shtml
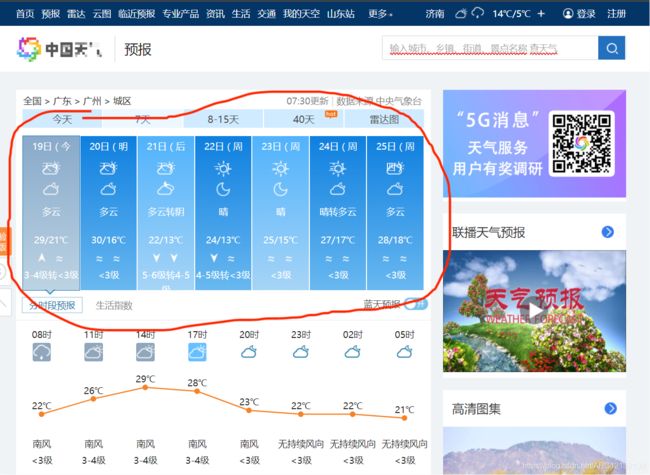
对于红圈内的天气情况,爬取并格式化输出。
网页源代码
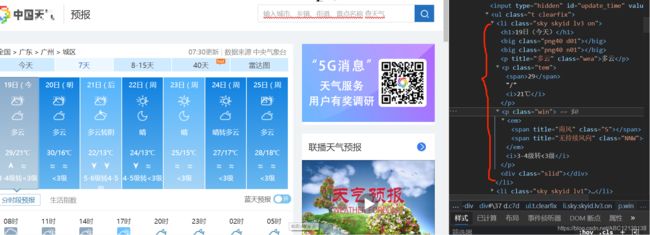
按F12进入开发者选项,查看网页源代码,定位到要爬取天气对应的源码位置。
代码
下面展示完整代码。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
import re
html = urlopen("http://www.weather.com.cn/weather/101280101.shtml")
bs = BeautifulSoup(html,'html.parser')
try:
def li(cl):
a = []
for i in cl:
a.append(i.text.strip())
return a
date = bs.find_all("h1")[:7] #日期
wea = bs.find_all("p",class_="wea") #天气情况
tem = bs.find_all("p",class_="tem") #气温
win = bs.find_all("p",class_="win") #风级
n = []
for i in win:
n.append(i.find('span', class_ = re.compile('N'))['title']) #风向
# print(n)
tplt = "{:8}\t{:8}\t{:10}\t{:10}\t{:10}" #格式化输出
for i in range(7):
print(tplt.format(li(date)[i],li(wea)[i],li(tem)[i],n[i],li(win)[i]),chr(12288))
#chr(12288)指的是按照中文空格缩进
print("爬取成功!!!")
except:
print("爬取错误!!!")
输出结果

结束!