爬取三联生活周刊新闻(进阶版)
Python结构化爬虫
- 结构化爬虫,按搜索爬取网页
-
- 背景
- 网站详情
- 源代码
- 输出结果
结构化爬虫,按搜索爬取网页
背景
本次的内容是在上一篇文章内容的延伸,在上一篇文章中,我们讲到了爬取某一篇新闻的内容,并且格式化输出该新闻的标题、日期、作者、内容等信息。可点击下方超链接查看↓↓↓
爬取三联生活周刊网站新闻
今天我们要通过选择我们想要的主题,按搜索爬取网页,搜索三联生活周刊中特定的栏目,并且结构化爬取网页上首页的所有新闻,并且输出。
网站详情
三联生活周刊网址
http://www.lifeweek.com.cn/
我们可以现在网页上搜索主题内容,看一下网址的变化情况:

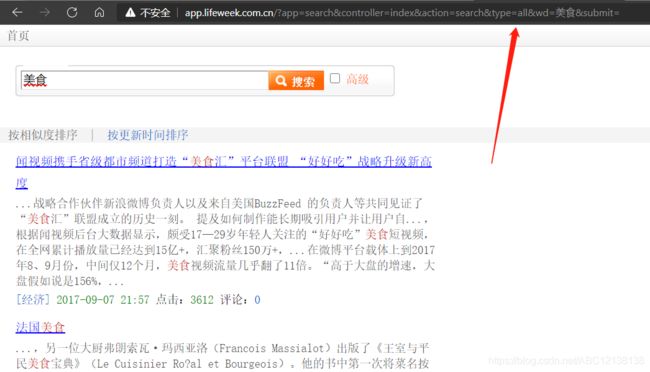
像这里,我搜索的主题是美食,我们来看一下此时的url变化情况,
http://app.lifeweek.com.cn/?app=search&controller=index&action=search&type=all&wd=美食&submit=
url上会自动加上我们搜索的主题文字。此时,我有一个大胆的想法,如果我直接将这个网址复制了,在代码中通过随时修改主题内容,那是不是就可以随时快速获取我想要的新闻了?
灵机一动,那就开干吧!
首先
先分析一下网页中每条新闻的链接所处的位置,老规矩,按F12进入我们开发者选项查看对应的源代码;
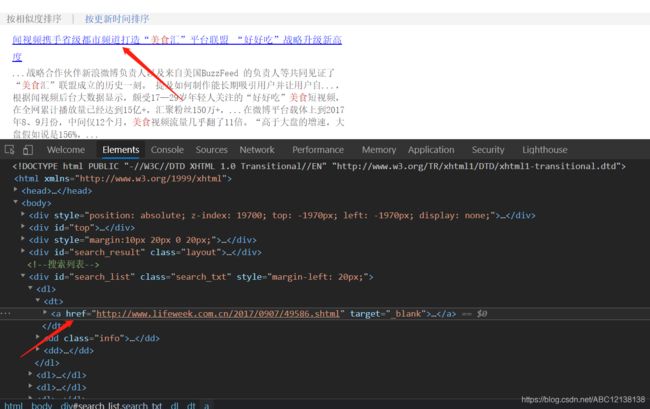
这里我只列举了第一个新闻在源代码中链接的位置,其他的你们也可以对应的看看。
那要如何提取出首页中所有的链接呢,这里我用到了css选择器,这个是关于网站页面内容搜索的,代码如下:
a = bs.select('div#search_list dl dt a')
该语句的意思是,在源代码中,id=search_list 的div标签下,空格代表向下取子标签,那这里就是 dl 标签 的 dt 子标签,再向下取 a 子标签 。
大家可以对应源代码看一次,这里空格的向下去子标签是搜索 div标签 下所有对应的子标签哦,详细的CSS选择器内容大家可以自行查找资料,或者与我探讨。
源代码
import requests
from bs4 import BeautifulSoup
#定义内容类
class Content:
def __init__(self, topic, url, title, body, infor):
self.topic = topic
self.url = url
self.title = title
self.body = body
self.infor = infor
def print(self):
print("New article found for topic: {}".format(self.topic))
print("URL: {}".format(self.url))
print("Title: {}".format(self.title))
print("Date & Author: {}".format(self.infor))
print("Body: {}".format(self.body))
class Website:
"""
描述网站结构的信息
name 是Lifeweek,三联生活周刊
url 为官网http://www.lifeweek.com.cn
searchUrl 是我们要加主题进行搜索的网址,http://app.lifeweek.com.cn/?app=search&controller=index&action=search&type=all&wd=
resultListing 为我们搜索首页所有链接的CSS选择器语句 'div#search_list dl dt a'
absoluterUrl 是判断我们爬取到的网址是不是完整的网址
剩下几个就是进入每一个新闻链接中要爬取对应内容的位置了
"""
def __init__(self, name, url, searchUrl, resultListing,
resultUrl, absoluterUrl, titleTag, bodyTag, information):
self.name = name
self.url = url
self.searchUrl = searchUrl
self.resultListing = resultListing
self.resultUrl = resultUrl
self.absoluterUrl = absoluterUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
self.information = information
#定义一个爬虫类
class Crawler:
def getPage(self, url): #获取网页信息
#编写一个异常处理
try:
req = requests.get(url)
req.encoding = 'utf-8'
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector): #爬取我们想要的对应内容
childObj = pageObj.select(selector)
# print(childObj)
if childObj is not None and len(childObj) > 0: #当爬取到的内容不为空,并且长度大于0时,将他们用换行连接起来
return "\n".join(line.text for line in childObj)
return ""
def search(self, topic, site):
"""
根据主题搜索网站并记录所以找到的页面
"""
url = site.searchUrl + topic
#按照标准,URL只允许一部分ASCII字符,其他字符(如汉字)是不符合标准的,
#我们的链接网址可能存在汉字的情况,此时就要进行编码。
url = requests.utils.quote(url, safe = ':/?=&')
bs = self.getPage(url)
#获取首页所有新闻的url链接
searchResults = bs.select(site.resultListing)
# print(searchResults)
#分别进入每一个链接中,获取新闻内容
for result in searchResults:
print("\n")
url = result.attrs['href']
#检查一下是相对url还是绝对url
if(site.absoluterUrl):
bs = self.getPage(url)
# print("绝对URL")
else:
bs = self.getPage(site.url + url)
# print("相对URL")
if (bs is None):
print("something was wrong with that page or URL. Skipping")
return
#爬取相对应的内容
title = self.safeGet(bs, site.titleTag)
body = self.safeGet(bs, site.bodyTag)
infor = self.safeGet(bs, site.information)
# if title != '' and body != '':
content = Content(topic, url, title, body, infor)
content.print()
crawler = Crawler()
#结构化爬虫,将需要爬取的网站以及对应的内容添加到一个数组中,如果有多个爬取需求,可以添加多个数组,方便快捷,
#即使是不会爬虫的新手,也可以根据对饮的内容,批量添加
siteData = [['Lifeweek', 'http://www.lifeweek.com.cn/',
'http://app.lifeweek.com.cn/?app=search&controller=index&action=search&type=all&wd=',
'div#search_list dl dt a', 'a', True, 'h1', 'p', 'h5']]
sites = []
for row in siteData:
sites.append(Website(row[0], row[1], row[2], row[3], row[4], row[5], row[6], row[7], row[8]))
topics = "美食" #可根据个人的意愿,选择要爬取的主题,你也可以选择科学、体育等栏目
print("CETTING INFO ABOUT : " + topics)
for targetSite in sites:
crawler.search(topics, targetSite)
最后在这里我教大家一个快速获取CSS选择器语句的方法,在源代码中,将鼠标定位到要获取标签的地方,点击鼠标右键,选择copy,再选择copy selector,这是浏览器自动帮我们整理好的select语句,如果用的是其他选择器,也可以根据对应的语法要求copy xpath等等。
输出结果


一个页面是会显示11个新闻的,我这样只截取了部分内容,大家可以自行运行看看。
有什么问题也可以和我探讨一下!!!
拜~~