五十六、HBase的优化
当一个组件到了优化部分的时候,基本上这个组件的内容就到了结尾部分了,本文我们给HBase收收尾,来讲一下HBase的优化。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
一、HBase的高可用
二、预分区
2.1 使用命令行添加预分区
2.2 使用JavaAPI添加预分区
2.2.1 代码实现
2.2.2 测试
三、RowKey设计
四、参数调优
一、HBase的高可用
在HBase中HMaster负责监控Region Server的生命周期,均衡Region Server的负载,如果HMaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对HMaster的高可用配置。这里需要注意的是,如果HMaster挂掉,HBase集群只是会进入不健康的状态,说明并不是所有的操作都用得到HMaster。下面一起来看一下怎样配置HBase的高可用。
1、关闭HBase集群
bin/stop-hbase.sh2、在HBase的conf目录下创建备用Master文件,并将备用节点添加到文件中。

3、将配置文件分发到其他节点
xsync backup-masters4、启动HBase集群,在浏览器中打开页面查看是否生效。
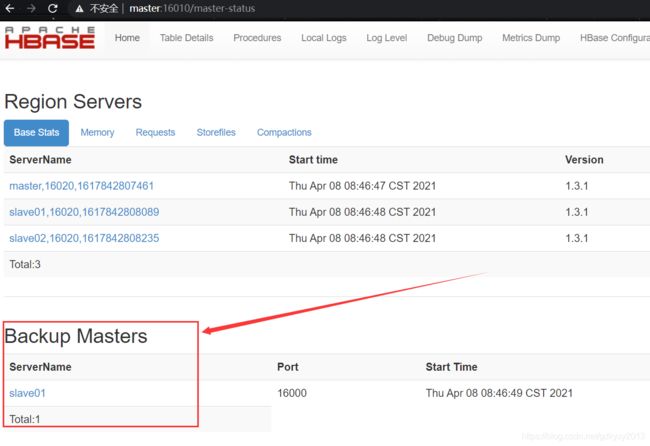
我们试着杀死master节点的HMaster,看看slave01节点的HMaster是否生效:
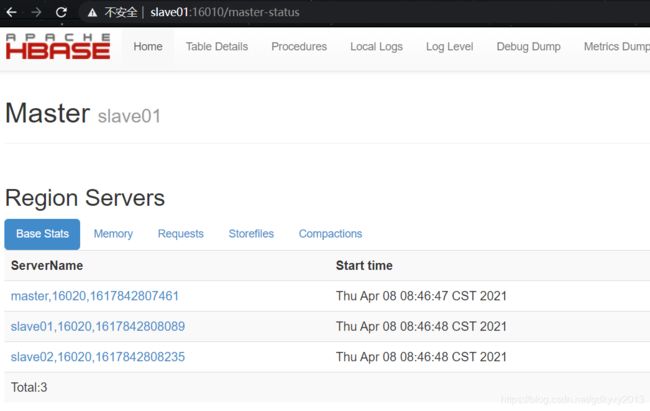
说明高可用已经生效,我们的配置没有问题。
二、预分区
每一个Region维护着startRowKey与endRowKey,如果加入的数据符合某个Region维护的rowkey范围,则该数据交给这个Region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。
2.1 使用命令行添加预分区
1、手动设定预分区
create 'emp','info','partition1',SPLITS => ['1000','2000','3000','4000']
2、生成16进制序列预分区
create 'emp2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
3、按照文件中的规则预分区
创建文件,并添加分区内容,如下所示:
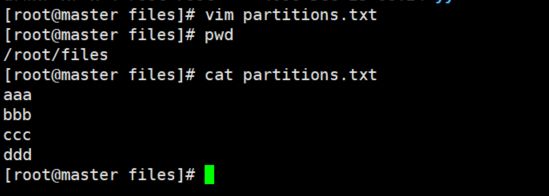
create 'emp3','partition3',SPLITS_FILE => '/root/files/partitions.txt'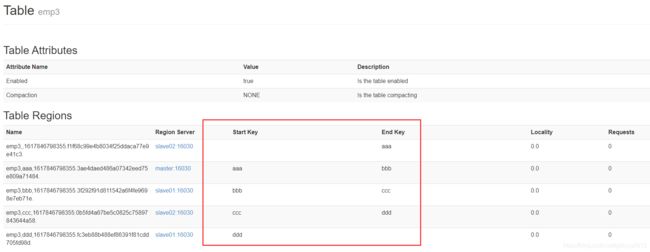
2.2 使用JavaAPI添加预分区
2.2.1 代码实现
package com.xzw.hbase_partitions;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2021/4/8 10:06
* @desc: 使用代码的方式创建HBase预分区
* @modifier:
* @modified_date:
* @desc:
*/
public class HBasePartitionsAPI {
/**
* 生成分区号
*
* @param rowkey 初始rowkey
* @param regionCount 分区数
* @return 返回生成的分区号
*/
public static String genRegionNum(String rowkey, int regionCount) {
int regionNum;
int hash = rowkey.hashCode();
if (regionCount > 0 && (regionCount & (regionCount - 1)) == 0) {
// 2 n
regionNum = hash & (regionCount - 1);
} else {
regionNum = hash % regionCount;
}
return regionNum + "_" + rowkey;
}
/**
* 生成分区键
*
* @param regionCount 分区数
* @return
*/
public static byte[][] genRegionKeys(int regionCount) {
byte[][] bytes = new byte[regionCount - 1][];
for (int i = 0; i < regionCount - 1; i++) {
bytes[i] = Bytes.toBytes(i + "|");
}
return bytes;
}
public static void main(String[] args) throws IOException {
//1、创建配置对象,获取HBase连接
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "master,slave01,slave02");
conf.set("hbase.zookeeper.property.clientPort", "2181");
//2、获取HBase连接对象
Connection conn = ConnectionFactory.createConnection(conf);
//3、获取操作对象
Admin admin = conn.getAdmin();
//4、创建表,同时增加预分区
HTableDescriptor emp_api = new HTableDescriptor(TableName.valueOf("emp_api"));
HColumnDescriptor info = new HColumnDescriptor("info");
emp_api.addFamily(info);
byte[][] bytes = genRegionKeys(3);
admin.createTable(emp_api, bytes);//创建表的时候添加预分区
//5、增加数据
String rowkey = "xzw";
String rk = genRegionNum(rowkey, 3);
Put put = new Put(Bytes.toBytes(rk));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("loc"), Bytes.toBytes("qd"));
Table table = conn.getTable(TableName.valueOf("emp_api"));
table.put(put);
}
}
2.2.2 测试
运行代码发现已经创建预分区:

数据也按照预期插入到了HBase中:

三、RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。造成数据倾斜的原因可能有以下几个:
1、HBase的中的数据是按照字典序排序的,当大量连续的rowkey集中写在个别的region,各个region之间数据分布不均衡。
2、创建表时没有提前预分区,创建的表默认只有一个region,大量的数据写入当前region。
3、创建表已经提前预分区,但是设计的rowkey没有规律可循。
可以通过以下几个方法解决数据倾斜问题:
1、随机数+业务主键,如果想让最近的数据快速get到,可以将时间戳加上。
2、Rowkey设计越短越好,不要超过10~100个字节。
3、映射regionNo,这样既可以让数据均匀分布到各个region中,同时可以根据startkey和endkey可以get到同一批数据。
Rowkey设计时需要遵循三大原则:
1、唯一性原则
rowkey在设计上保证其唯一性。rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
2、长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。建议越短越好,不要超过16个字节,原因如下:数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
3、散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
(1)加盐:如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
(2)哈希:哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
(3)反转:第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题。
(4)时间戳反转:一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用Long.Max_Value-timestamp追加到key的末尾,例如[key][reverse_timestamp] ,[key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计[userId反转][Long.Max_Value-timestamp],在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转][000000000000],stopRow是[userId反转][Long.Max_Value-timestamp]。如果需要查询某段时间的操作记录,startRow是[user反转][Long.Max_Value-起始时间],stopRow是[userId反转][Long.Max_Value-结束时间]。
四、参数调优
1、允许在HDFS的文件中追加内容
hdfs-site.xml、hbase-site.xml
属性:dfs.support.append
解释:开启HDFS追加同步,可以优秀的配合HBase的数据同步和持久化。默认值为true。2、优化DataNode允许的最大文件打开数
hdfs-site.xml
属性:dfs.datanode.max.transfer.threads
解释:HBase一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,设置为4096或者更高。默认值:4096。3、优化延迟高的数据操作的等待时间
hdfs-site.xml
属性:dfs.image.transfer.timeout
解释:如果对于某一次数据操作来讲,延迟非常高,socket需要等待更长的时间,建议把该值设置为更大的值(默认60000毫秒),以确保socket不会被timeout掉。4、优化数据的写入效率
mapred-site.xml
属性:
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec或者其他压缩方式。5、设置RPC监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count
解释:默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。6、优化HStore文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize
解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。7、优化hbase客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer
解释:用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。8、指定scan.next扫描HBase所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching
解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。9、flush、compact、split机制
当MemStore达到阈值,将Memstore中的数据Flush进Storefile。compact机制则是把flush出来的小文件合并成大的Storefile文件。split则是当Region达到阈值,会把过大的Region一分为二。
涉及属性:
hbase.hregion.memstore.flush.size:134217728这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.upperLimit:0.4
hbase.regionserver.global.memstore.lowerLimit:0.38当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于lowerLimit。
以上就是本文的所有内容,比较简单。你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题~